作者 | 徐友聚
编辑 | 向 玉
前两天外媒铺天盖地报道了个大新闻:华盛顿杜勒斯机场的 AI 立功了,帮助警察蜀黍捉到了一名非法入境者。
这些美国记者真是大惊小怪,放在我大天朝,随随便便一个歌星都能完成“七杀”,你啥时候看我们骄傲了?!

美国海关喜提人脸识别 AI
事情是这样的…
就在上个月,作为美国最繁忙机场的华盛顿杜勒斯机场完成了一场历史性的科技升级——他们在海关入口装上了人脸识别系统,大家可以刷脸入关了。

没想到 AI 上班刚刚三天,8 月 23 日,它就碰上了自己职业生涯的最大挑战。
当时,一位黑人小哥哥刚从巴西圣保罗抵达华盛顿,小哥拿了本法国护照,准备刷脸过关进入美国。
刚走到人脸识别机器面前,AI 抬眼一看:护照和眼前明显不是一个人,这小哥难不成有问题?

系统叫来了警察蜀黍。在一波刨根问底搜查后,小哥终于露出了破绽。
千思万虑藏到鞋垫下的真实证件,还是出卖了他——小哥压根不是什么法国人,而是来自同样说法语的刚果共和国。

事情很清楚了,AI 协助抓捕了一位持*证假**件的非法入境者。
美国海关和边境保护局欢天喜地,毕竟他们终于在新技术上跑赢了老对手英国——伦敦警察局识别率 2% 的“脸盲识别”都敢吹,相比之下,我们美帝的 AI 简直堪称模范员工。

光是内部表彰还不够,他们找来了媒体,把 AI 技术树立成了打击犯罪的“英雄”,说要全国应用。
也是该推广一下了,全美将近两万个机场,现在用上 AI 的才 14 个…
人脸识别四部曲
其实说到人脸识别,可以分成前 DL (深度学习)和 DL 时代,两者分水岭是 2014 年 Facebook 提出的 DeepFace ,它不仅让深度学习在人脸识别领域大放光彩,也构建了深度人脸识别中主流的基本框架,其主要的步骤主要有:人脸检测、人脸对齐、人脸特征提取、人脸分类。

我们分步来看~
01
人脸检测
在实际应用中,AI 摄像头捕捉到的画面通常比较杂乱,存在若干张人脸和复杂的背景。而作为人脸识别的第一步,就要各个人脸在其中的区域,并且“画个框框锁定它”。

02
人脸对齐
但此时框住的人脸还无法直接进行特征提取。
低头玩手机的,侧身和同伴讲话的,抬头仰望诗和远方的……

为了降低识别难度,就要把人脸姿态统一校正为最理想的姿态——一张竖直的正脸,校正方法主要分为 2D 校正和 3D 校正两种。
2D校正首先对人脸区域进行截取,然后检测几个基点(如左右眼、鼻尖、左右嘴角共 5 个点)计算人脸的姿态,依此对人脸截图进行旋转,使人脸竖直。
拿小布什举个栗子~
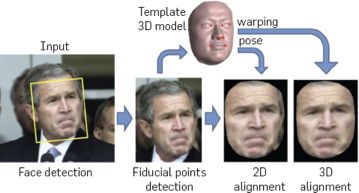
而相较之下,3D 校正则需要检测更多基点(如常见的 67 点),并做 Delaunay 三角化,将通用的 3D 人脸模型与之做匹配,使得各基点的误差最小,将各三角区域的人脸图片贴到 3D 人脸模型上,通过旋转 3D 模型从而获取人脸的下面图像,3D 校正可以有效降低侧脸的识别难度。
03
人脸特征提取
经过前两步,一张对正人脸的图片已经 get~ 接下来,就是对人脸的特点进行描述。
深度学习可以将复杂、冗余的人脸图片转换为一个 1024 维或者其他维数的特征向量,在保留人脸特征信息的同时大量减少了数据量,是十分有效特征提取方法。
由于人脸识别与物体分类任务的相似性(将图片分到不同的 ID/类别),VGGNet / InceptionNet / ResNet 等用于物体分类的网络结构同样广泛适用于人脸识别中。
损失函数的改进是目前人脸识别主要的研究方向之一,相比于物体分类任务,人脸识别需要识别的 ID 数要更多;深度学习是数据驱动的,但获取每个人的大量人脸图片是不现实的,所以人脸识别需要适合的损失函数来提供更好的泛化性能。
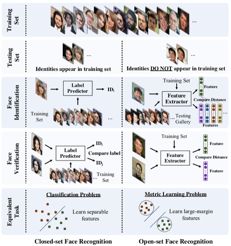
如上图左侧 Closed-set Face Recognition 所示,将用于人脸识别任务的神经网络中使用同一般的分类任务一样的损失函数,最终训练得到的模型可以将特定人物(出现在训练集中)的人脸分开,实现识别的目的。
但各类别在特征空间中分布的较为分散,边界相距较近,如果待识别的是陌生人(未出现在训练集中)的人脸图片,则其特征向量的分布极有可能会和其他若干个不同人脸对应的区域重叠,使得网络不能有效的识别训练集之外的人,网络的实用性较差,这也是 Closed-set 所指的不足。
相比之下,Open-set Face Recognition 则使用不同方法来实现类似度量学习中 margin 的概念,使得同一人的特征向量分布更加紧密,不同人的特征向量分布之间相距更远。由于每个人的特征向量分布区域更小以及margin的存在,使得即便是陌生人脸的特征向量也难和其他人的区域出现重合,从而实现更有效且实用的人脸识别。
目前人脸识别算法损失函数基于以下两个思路进行改进:
- Metric Learning: 直观来看就是让同一个人的特征向量分布在一个小的范围内,不同人的特征向量距离大于margin,如Contrastive Loss, Triplet loss及相关sampling method。
- Margin Based Classification: 由于分类(或者说softmax损失函数)本身已经实现了同一个人的特征向量相互靠近,所以改进的重点是让不同人的特征向量距离大于margin。包含Softmax with Center loss, Sphereface, NormFace, AM-softmax(CosFace)和ArcFace。
在介绍上述算法之前,我们先来了解一下常见的距离或者相似度度量方法~
01
距离和相似度度量
欧氏距离
即2阶范数,可用以下公式计算
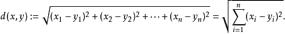
Cosine余弦相似度/向量内积
两个向量间的余弦值可以很容易地通过使用欧几里得点积和量级公式推导
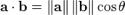
鉴于两个向量的属性, A 和B的余弦相似性θ用一个点积形式来表示其大小,如下所示:
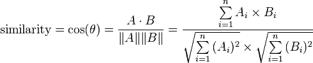
也就是说两个向量的cosine距离就是这两个向量之间的夹角,适合高维度向量的相似度计算。
皮尔逊相关系数
从下面这个公式可知,它其实就是将数据减去其对应均值做cosine相似度计算,所以也叫centered cosine
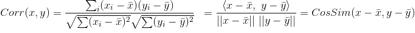
皮尔逊相关系数具有平移不变性和尺度不变性,计算出了两个向量的相关性。当两个变量的标准差都不为零时,相关系数才有定义。
02
Metric Learning
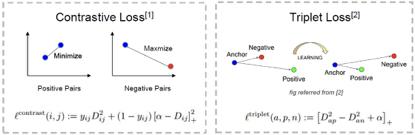
Contrastive Loss
Contrastive Loss本质上是使同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值m。基于这样的insight,DeepID2在训练的时候不是以一张图片为单位了,而是以Image pair为单位,每次输入两张图片,为同一人则verification label为1,不是同一人则label为-1。
Triplet Loss
2015年, Google发表的Facenet是人脸识别领域另一个具有代表的工作,提出了一个绝大部分人脸问题的统一解决框架,即:识别、验证、搜索等问题都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间。为此,Google在DeepID2的基础上,学到更好的feature,抛弃了分类层即Classification Loss,将Contrastive Loss改进为Triplet Loss。
在Triplet loss思想中,输入不再是两张图片(Image Pair),而是三张图片(Triplet),分别为Anchor face, negative face和positive face。Anchor face与positive face为同一人,与negative face为不同人。那么Triplet loss的损失即可表示为:
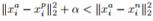
直观解释为:在特征空间里anchor与positive的距离要小于anchor与negative的距离超过一个margin alpha。
但Metric Learning也存在一些问题。比如:
- 需要很长的时间训练
- 模型好坏很依赖训练数据的sample方式,理想的sample方式不仅能提升算法最后的性能,更能略微加快训练速度。
03
Margin Based Classification
Margin Based Classficiation不像在feature层直接计算损失的Metric Learning那样,对feature加直观的强限制,而是依然把人脸识别当classfication任务进行训练,通过对softmax公式的改造,间接实现了对feature层施加margin的限制,使网络最后得到的feature更discriminative。
Sphereface
做为最常见的分类损失 Softmax,其定义如下:

Softmax 不会显式的优化类间和类内距离的,所以通常不会有太好的性能。
为了方便计算,我们让 bias=0,全联接的 WX 可以表示为:
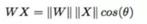
θ 表示 W 和 X 的夹角,归一化 W 后:
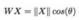
对特定的 X,|| X || 是确定的,所以这时 Softmax 优化的其实就是 cos 值,或ß者说他们的夹角 θ。

图a、b是用原始softmax损失函数训练出来的特征,图c、d是归一化的特征。不难发现在softmax的特征从角度上来看有latent分布。
W 归一化后,改进后的损失函数为:
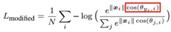
为了保证最大类内距离还要小于最小类间距离,所以引入了margin的思想,这跟triples loss里面引入margin alpha的思想是一致的:
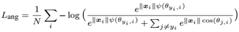
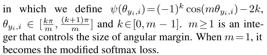
由此得到上图中e、f的所示结果,同一ID对应的特征向量聚集的更加紧密,两类中心的角度间距更大,且存在较大的margin。
Normface
在测试阶段,sphereface通过特征间的余弦值来衡量相似性。但在训练阶段,sphereface优化特征与类中心的角度乘上一个特征的长度,优化的方向还有一部分是去增大特征的长度。Normface的核心思想就出来了:为何在训练的时候不把特征也做归一化处理?相应的损失函数如下:
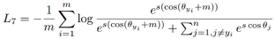
其中W是归一化的权重,f_i是归一化的特征,两个点积就是角度余弦值
M-softmax/CosFace
Normface用特征归一化解决了sphereface训练和测试不一致的问题。但是却没有了margin的意味。AM-softmax可以说是在Normface的基础上引入了margin。损失函数:
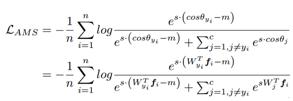
其中这里的权重和特征向量都是归一化的。 直观上来看,cos(θ)-m比cos(θ)更小,即相同距离下,样本到其标记类别的损失比到其他做任意类别损失更大,所以损失函数值比Normface里的更大,因此有了margin的感觉。m是一个超参数,控制惩罚的力度,m越大,惩罚越强。作者推荐m=0.35。这里引入margin的方式比Sphereface中的明显,没有很多需要调参的超参数,更容易复现。
ArcFace
与AM-softmax相比,区别在于Arcface引入margin的方式不同,损失函数:
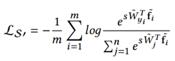
注意m是在余弦里面。该方法中margin直接加在需要优化的角度变量上,相比其他方法更加直接。文章指出基于上式优化得到的特征间的边界更为优越,具有更强的几何解释。
04
人脸分类
通过上述方式训练得到需要的神经网络后,就可以方便地计算出人脸的特征向量了。之后就是使用不同的算法对其进行分类,从而适应不同的应用场景。
常见的算法主要有以下几种:
- 基于cosine/欧氏距离的:
- 最近邻 适用于identification
- 阈值比较 适用于verification
- SVM等适用于小样本分类的经典分类器
- metric learning
- sparse-representation-based classifier (SRC) 相比SVM更适用于不平衡数据集
等等,你的脸丢了………
话说回来,美国人对 AI 刷脸技术不感冒,一方面原因是技术实力很尴尬——之前有机构对亚马逊的人脸识别技术 Rekognition 做过测试,533 名国会议员中有 28 个都被 AI 认成了犯罪分子。

更主要的,则是出于对隐私安全的忧虑。几乎每一次政府的推广行为,都会引起舆论的民众的争议。
他们担心这项技术会成为泄露隐私的帮凶,这些面部信息何去何从,能否得到妥善的管理,如果管理不当而招致信息泄露,那么用户的个人隐私就无异于处在“裸奔”状态。
试想一下,如果有人通过 3D 打印等技术手段来复制你的脸,进而完成各种交易……后果不堪设想。
不过,还是那句话,技术本身是没有原罪的。如何从管理层面引导技术发展走向则需要政府、企业、个人等多面的共同努力。

比如欧洲监管机构,就在今年 5 月生效的《通用数据保护条例》中规定:包括“脸纹”在内的生物信息属于其所有者,使用这些信息需要征得本人同意。
看来大数据和人工智能时代,我们要看好的不仅有钱包和手机,还要自己的脸…

参考文献:
[1] Y. Sun, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. CoRR, abs/1406.4773, 2014.
[2] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In Proc. CVPR, 2015.
[3] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017
[4] F. Wang, W. Liu, H. Liu, and J. Cheng. Additive margin softmax for face verification. In arXiv:1801.05599, 2018.
[5] CosFace: Large Margin Cosine Loss for Deep Face Recognition
[6] Deng, J., Guo, J., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: Arxiv preprint. 2018