
编辑
然后我们配置历史服务器去,在120上我们配置历史服务器


编辑
把日志收集到120上

编辑
可以看到进入到120的配置文件目录

编辑

编辑
编辑配置文件


编辑
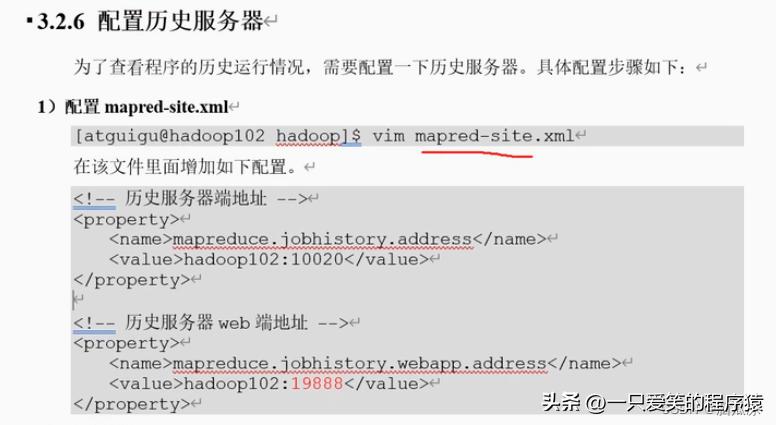
把历史服务器内容填上
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>



编辑
然后保存退出,然后分发一下把,这个配置分发到集群其他机器上


编辑
然后

编辑
在opt/module/hadoop-3.1.3/bin下面有个mapred命令

编辑
用这个启动历史服务器

编辑
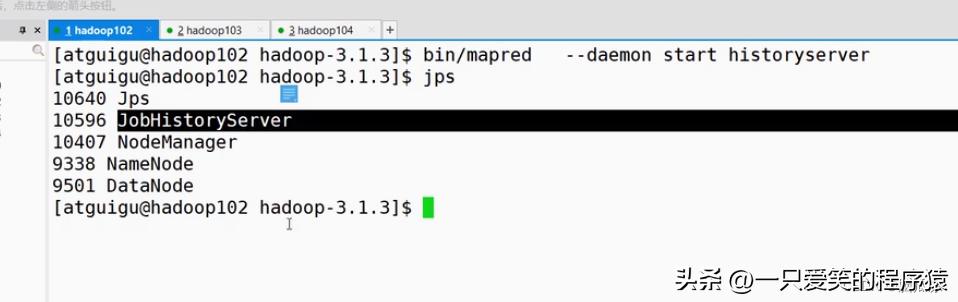
jps一下启动成功了

编辑
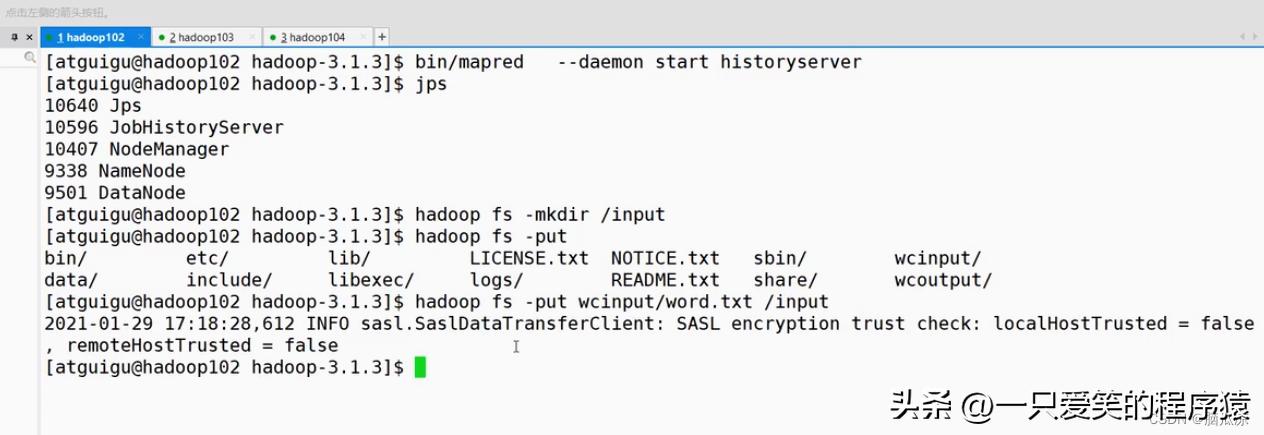
然后我们在hdfs上创建一个input目录,在根目录创建,然后上传一个word.txt文件
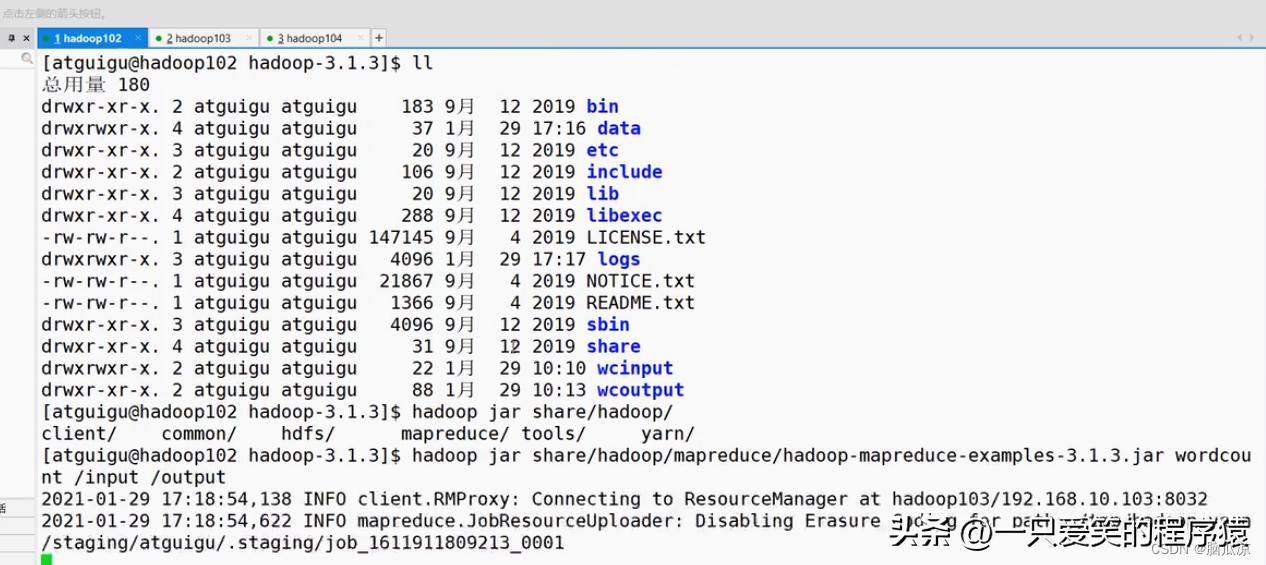

编辑
然后去执行一下wordcount,这个例子程序

编辑
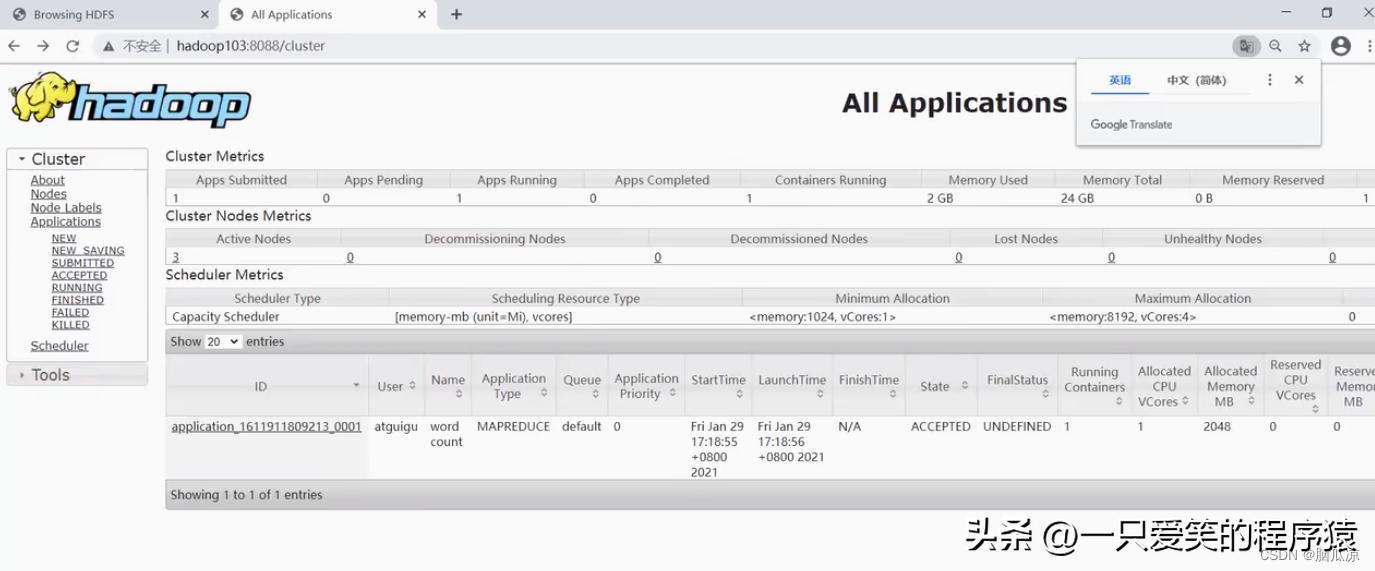
然后去集群监控页面看看

编辑
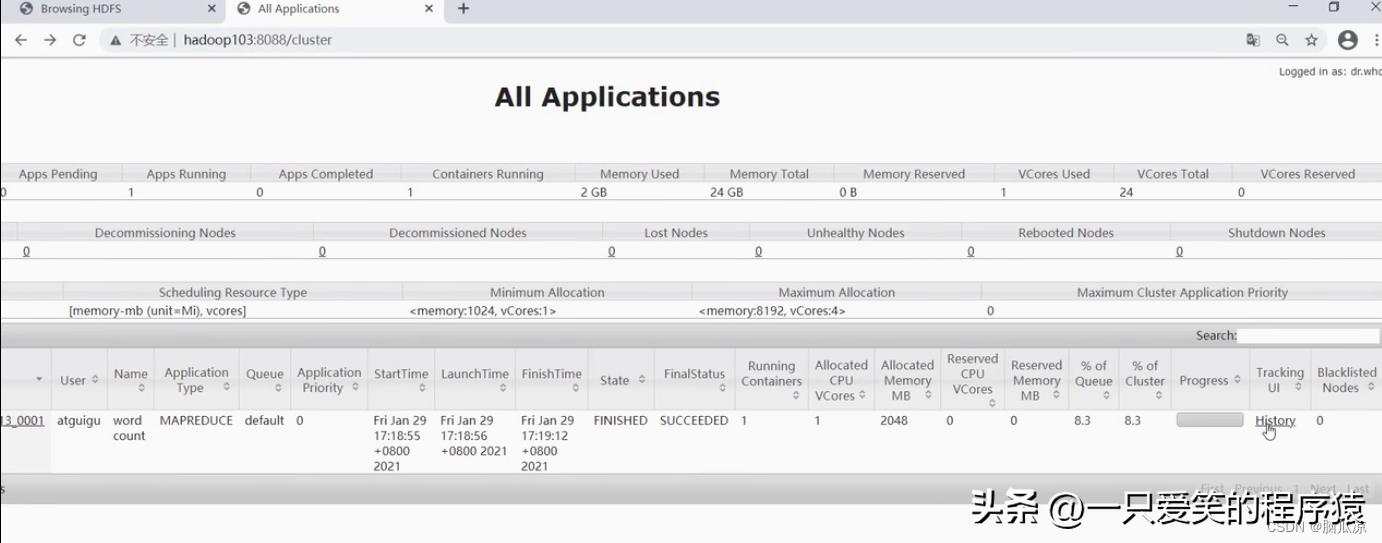
看这个最新的任务,点击history

编辑
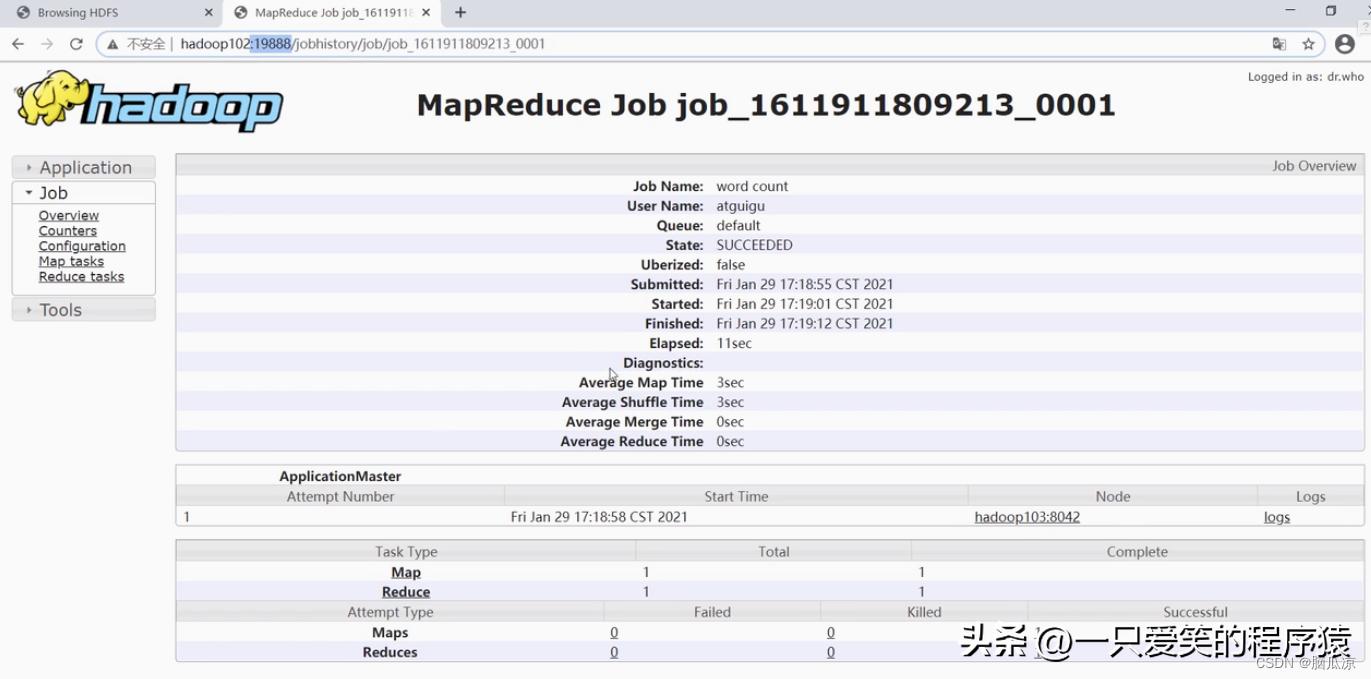
可以看到这个时候自动跳转到了这里19888,这个是我们历史服务器的端口地址
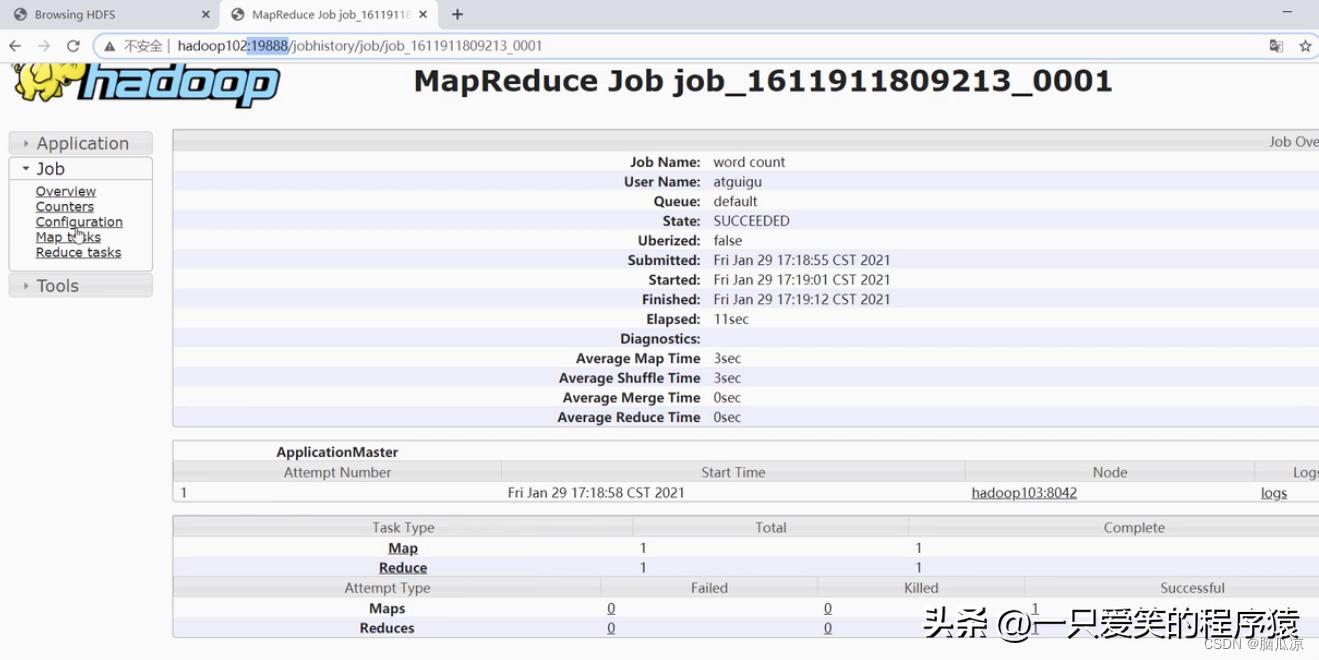

编辑
可以看到执行的过程

编辑
点击左侧的configuration,还可以看到执行的时候的配置

编辑
点进去map可以看到map的内容了.
自己操作一下:

编辑
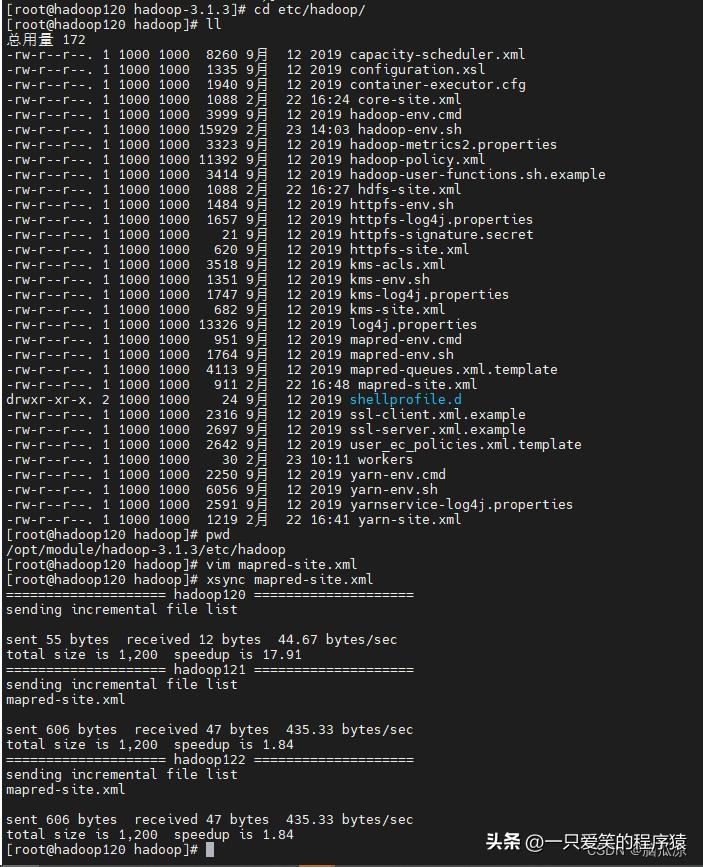
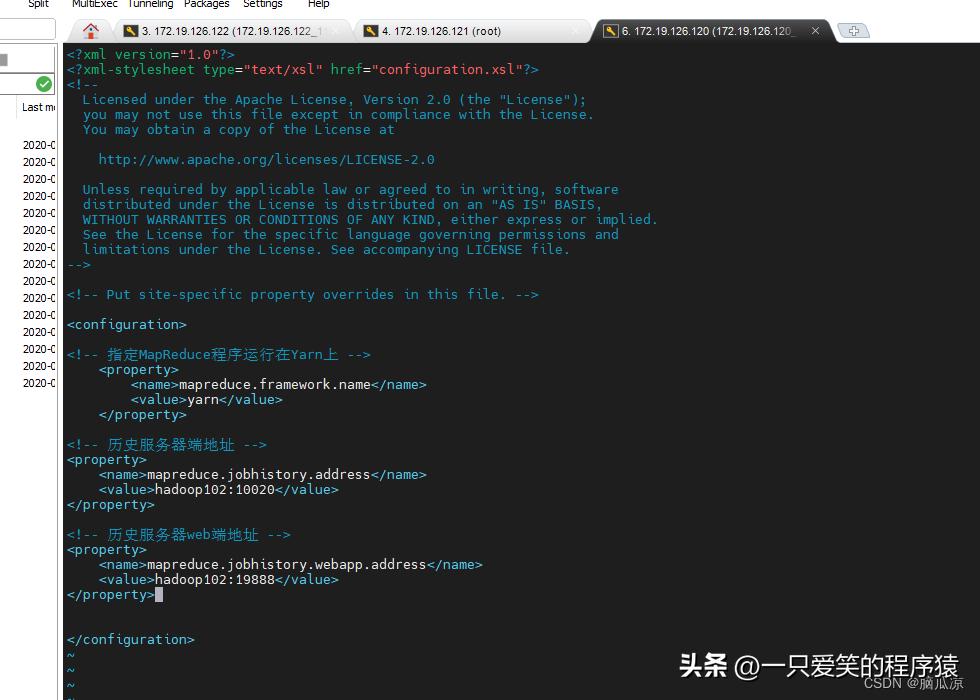
可以看到编辑配置文件,然后配置内容,然后分发就可以了

编辑
看看内容配置内容
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value></property>
<!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value></property>
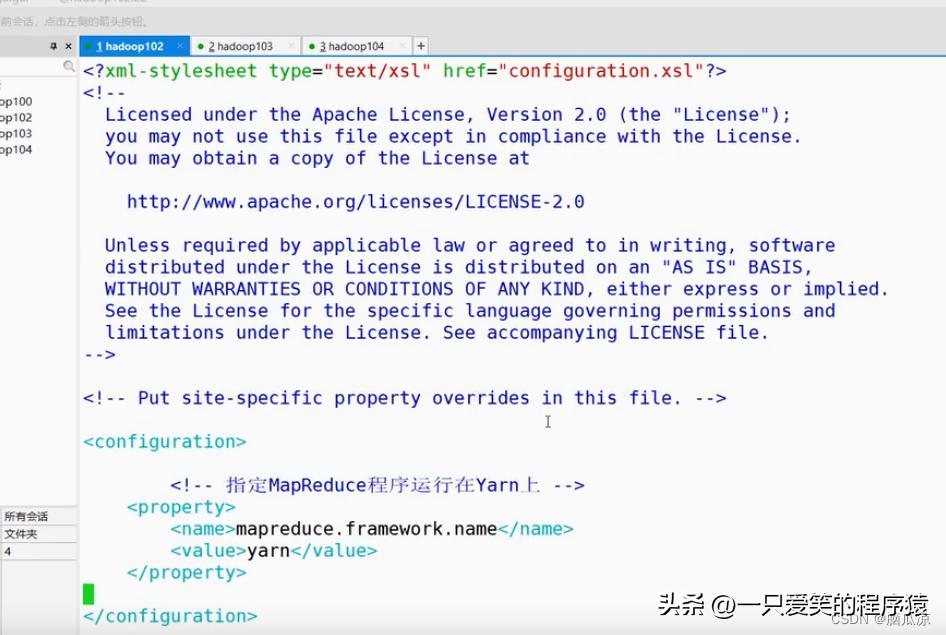
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop120:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop120:19888</value>
</property>
</configuration>
~

这里要知道,这个历史服务器地址,是我们指定的,这里我们指定了120,做为历史服务器,然后120做为历史服务器的web地址.
172.19.126.122 HDFS:SecondaryNameNode DataNode Yarn: NodeManager
172.19.126.121 HDFS:DataNode Yarn: ResourceManager NodeManager
172.19.126.120 HDFS:NameNode DataNode Yarn: NodeManager 历史服务器+历史服务器web地址 19888端口
现在是这样的
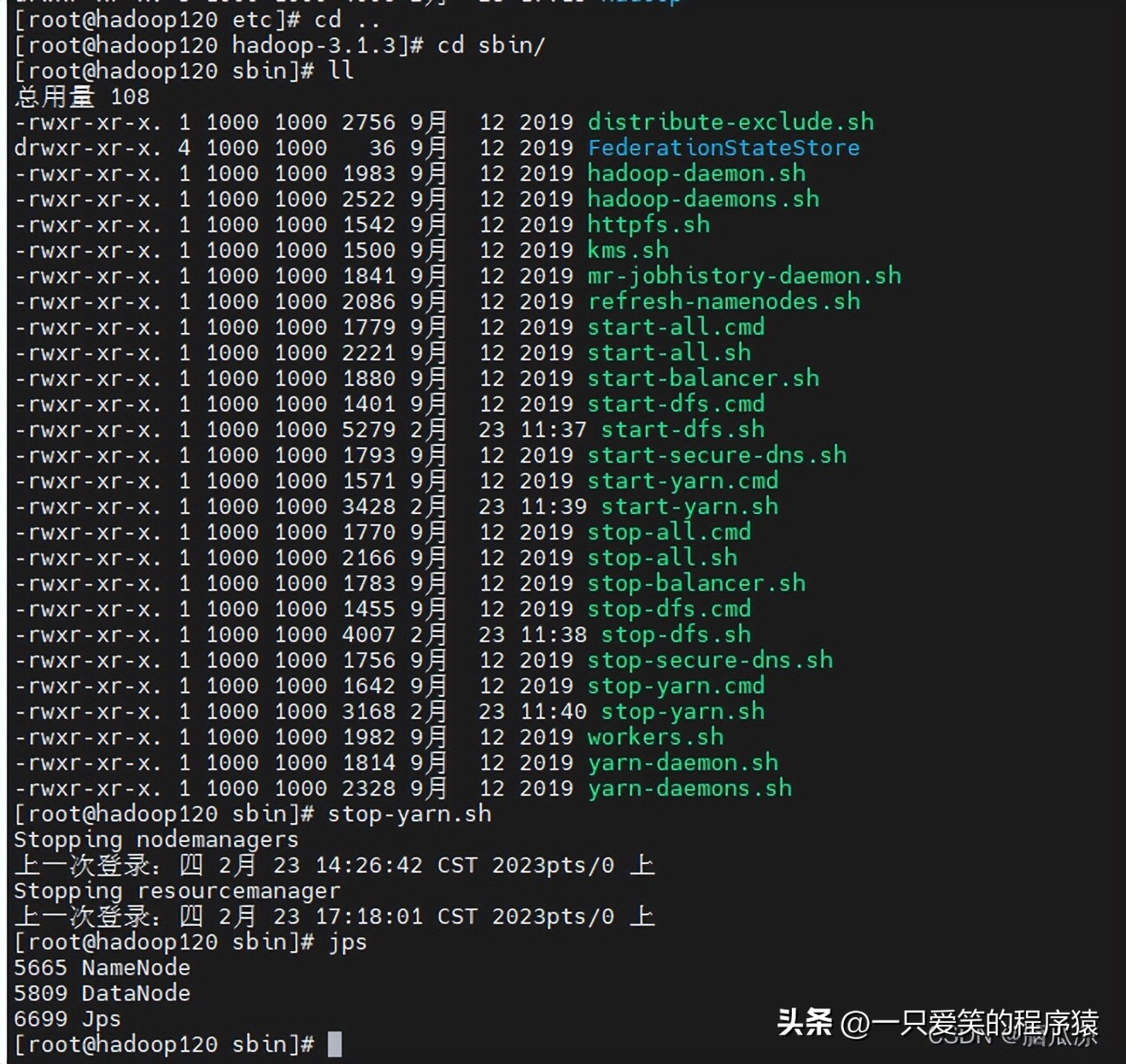
配置好了以后需要重新启动一下yarn,可以看到要走到

编辑
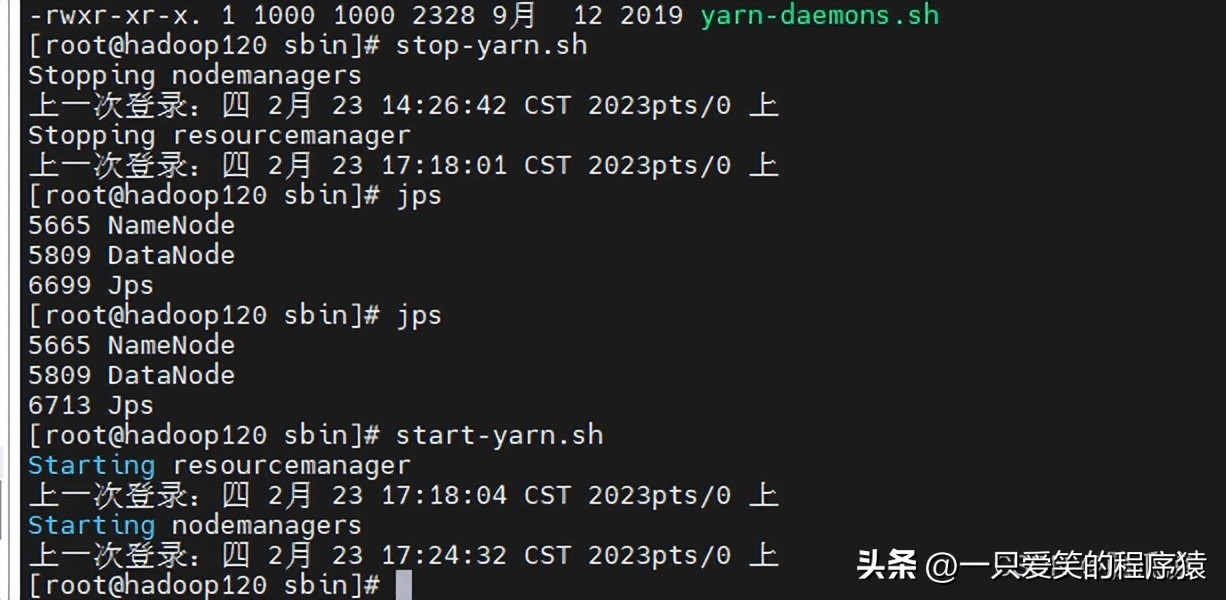
走到/opt/module/hadoop-3.1.3/sbin 里面找到,stop-yarn.sh

编辑
可以看到去重启一下yarn. 注意yarn的话要在,121服务器上去重启,启动关闭哈
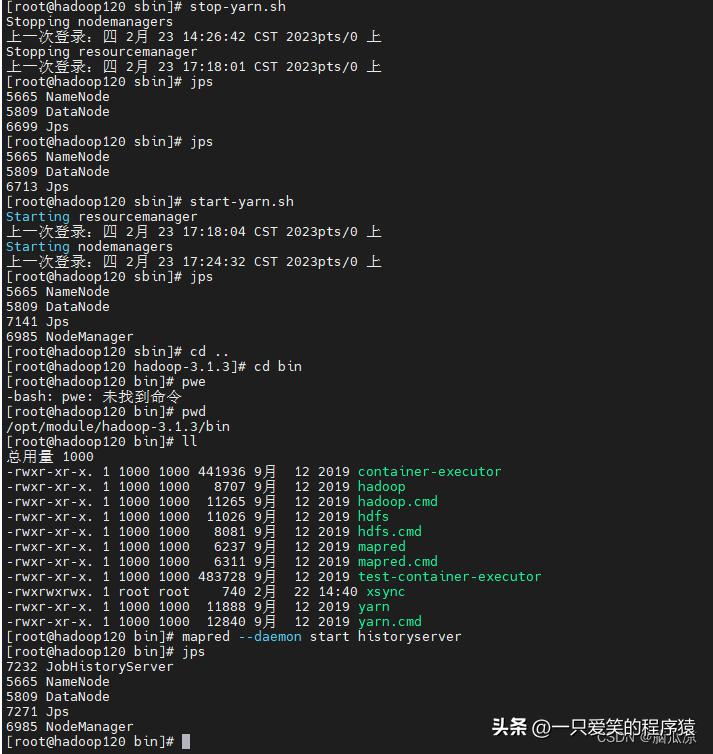
然后,再去启动历史服务器.

编辑
可以看到关闭运行的yarn,然后启动yarn,然后去opt/moudle/hadoop-3.1.3/bin
下面去启动history历史服务器,可以看到启动成功了对吧多了一个JobHistoryServer.
然后我们去验证一下.

编辑
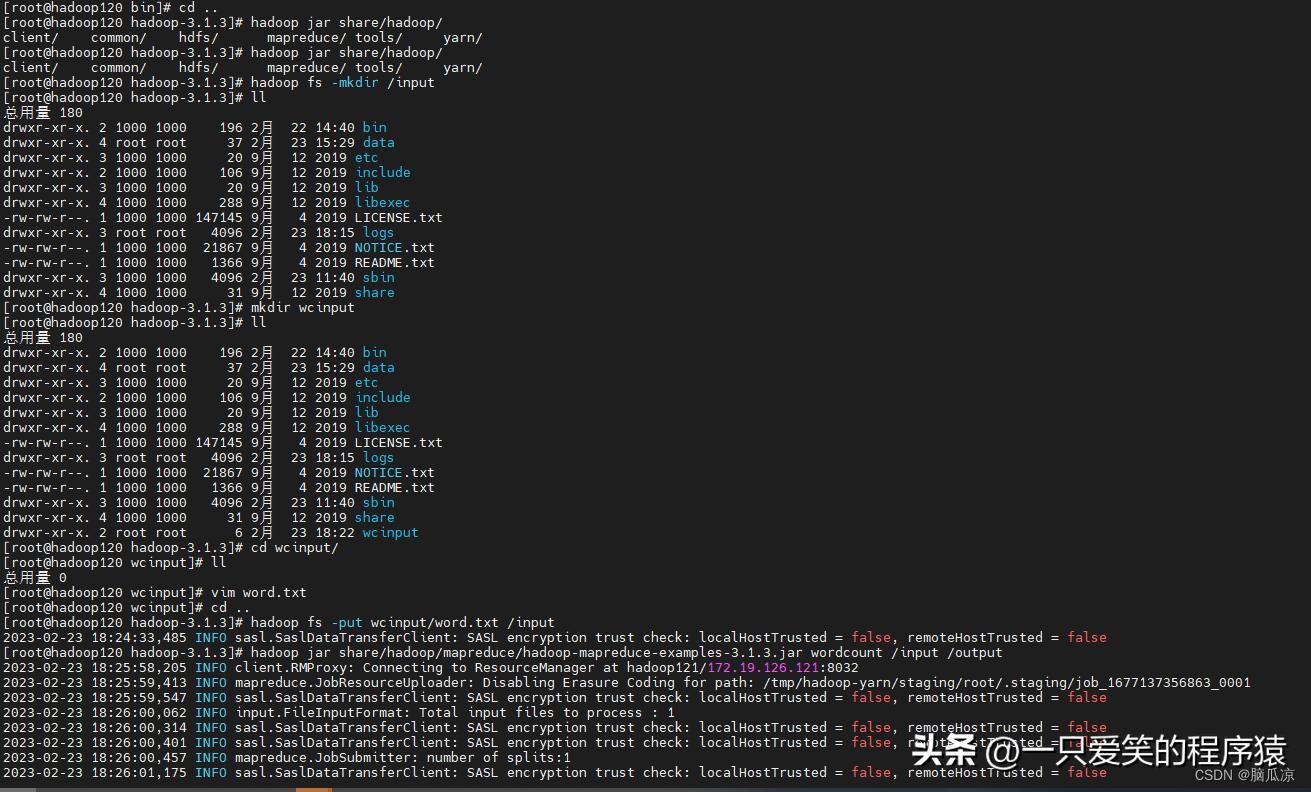
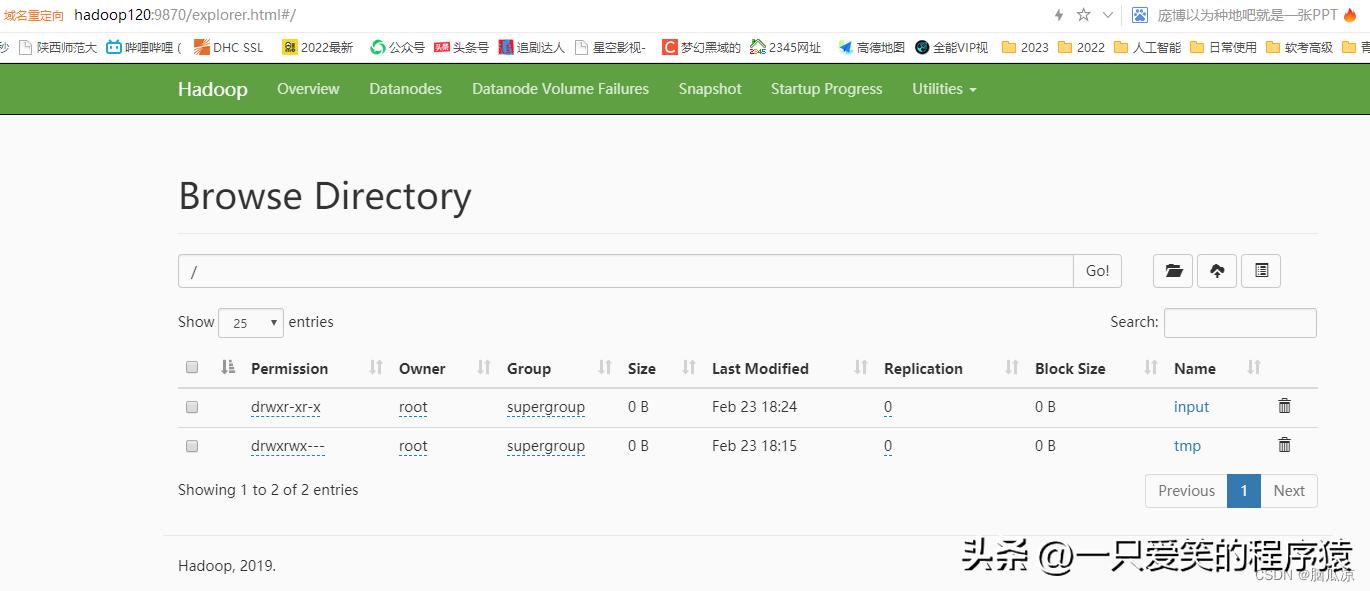
首先创建一个input文件夹在hdfs中
hadoop fs -mkdir /input 这个就是在根目录创建
可以看到我们先在opt/hadoop-3.1.3/目录下创建 mkdir wcinput目录
然后进入cd wcinput目录 然后创建vim word.txt 文件
然后我们写入:
python
java
java
net
测试内容,随便写一写就行,让提供的案例程序去统计单词.
然后执行:hdoop fs -put wcinput/word.txt /input 上传这个文件到dfs的/input目录下
然后我们看看:
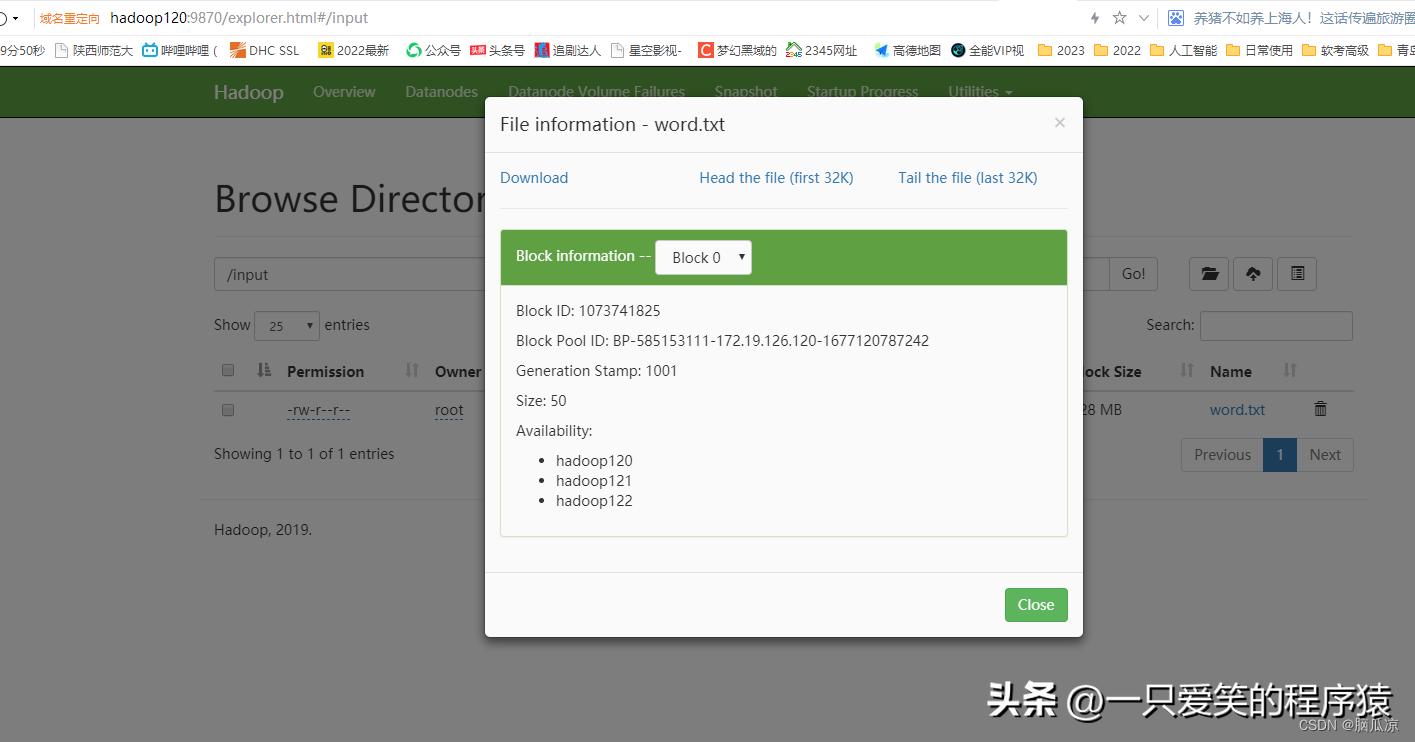

编辑
这个目录下已经有这个文件了.
有这个文件了,然后我们执行
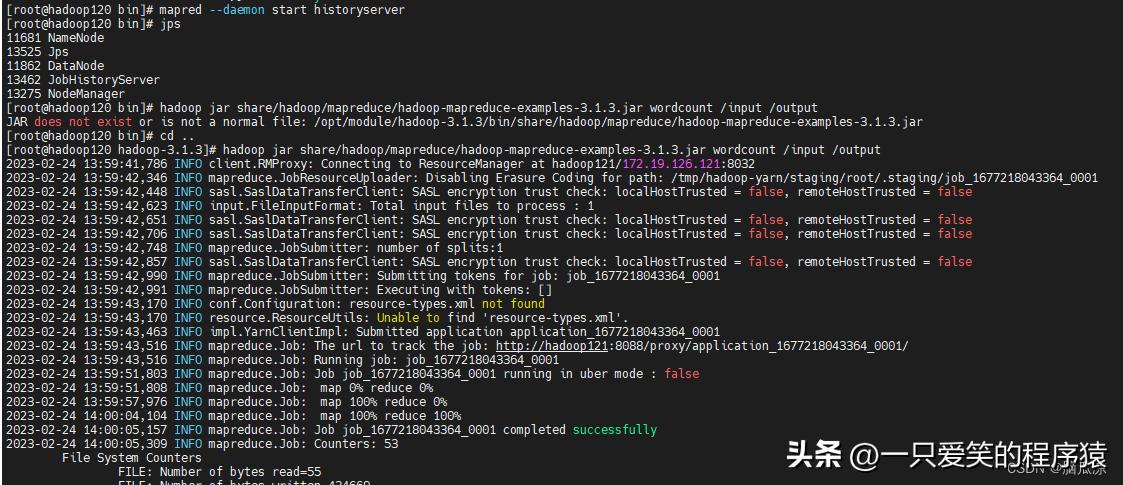
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
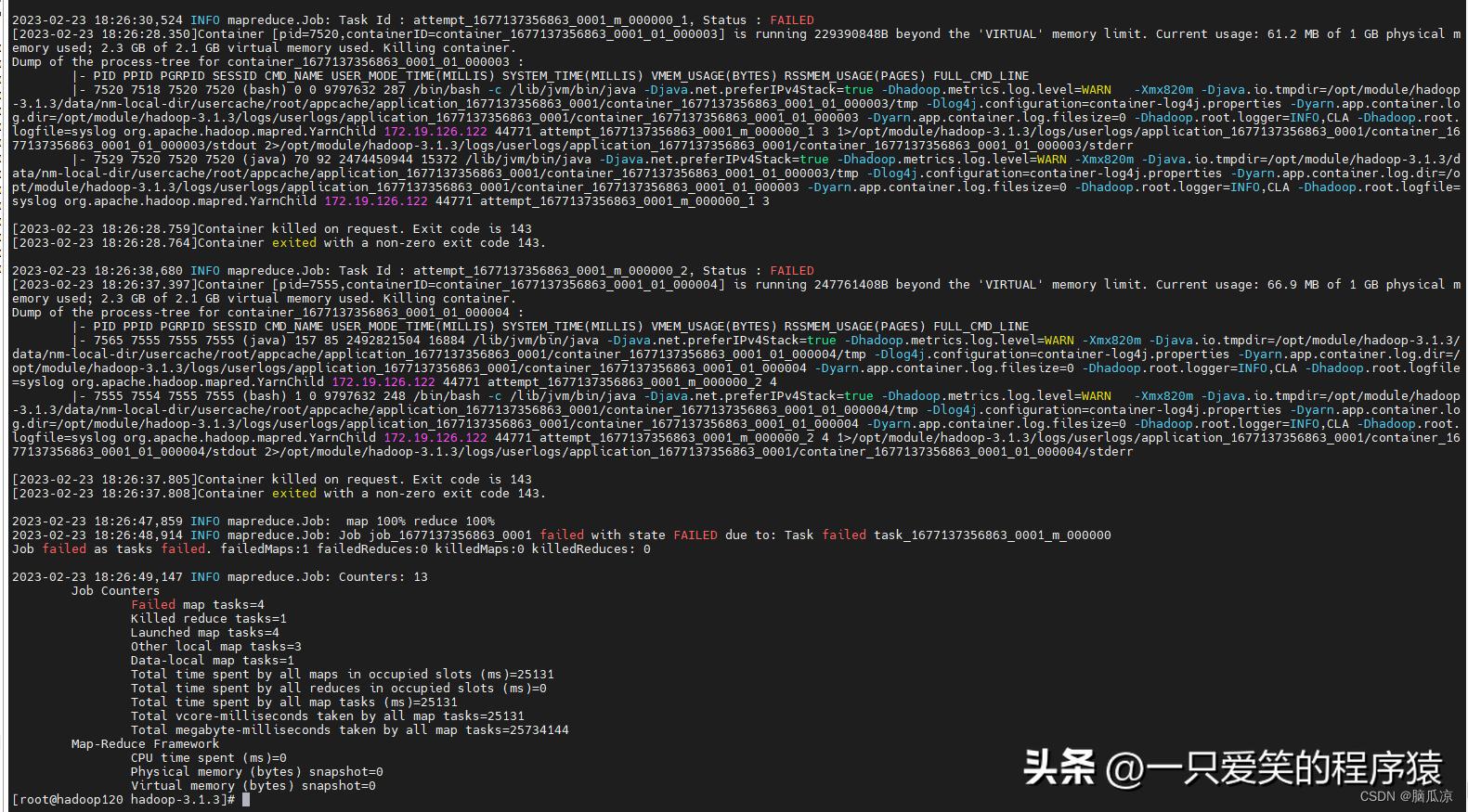

编辑
可以看到,说是报错了...报错了啊...
Container killed on request. Exit code is 143
这个错误
[2026-03-16T01:49:48+00:00.896]Container killed on request. Exit code is 143
[2026-03-16T01:49:48+00:00.908]Container exited with a non-zero exit code 143.
2026-03-16T01:49:48+00:00,524 INFO mapreduce.Job: Task Id : attempt_1677137356863_0001_m_000000_1, Status : FAILED
[2026-03-16T01:49:48+00:00.350]Container [pid=7520,containerID=container_1677137356863_0001_01_000003] is running 229390848B beyond the 'VIRTUAL' memory limit. Current usage: 61.2 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1677137356863_0001_01_000003 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 7520 7518 7520 7520 (bash) 0 0 9797632 287 /bin/bash -c /lib/jvm/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/data/nm-local-dir/usercache/root/appcache/application_1677137356863_0001/container_1677137356863_0001_01_000003/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000003 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 172.19.126.122 44771 attempt_1677137356863_0001_m_000000_1 3 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000003/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000003/stderr
|- 7529 7520 7520 7520 (java) 70 92 2474450944 15372 /lib/jvm/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/data/nm-local-dir/usercache/root/appcache/application_1677137356863_0001/container_1677137356863_0001_01_000003/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000003 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 172.19.126.122 44771 attempt_1677137356863_0001_m_000000_1 3
[2026-03-16T01:49:48+00:00.759]Container killed on request. Exit code is 143
[2026-03-16T01:49:48+00:00.764]Container exited with a non-zero exit code 143.
2026-03-16T01:49:48+00:00,680 INFO mapreduce.Job: Task Id : attempt_1677137356863_0001_m_000000_2, Status : FAILED
[2026-03-16T01:49:48+00:00.397]Container [pid=7555,containerID=container_1677137356863_0001_01_000004] is running 247761408B beyond the 'VIRTUAL' memory limit. Current usage: 66.9 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1677137356863_0001_01_000004 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 7565 7555 7555 7555 (java) 157 85 2492821504 16884 /lib/jvm/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/data/nm-local-dir/usercache/root/appcache/application_1677137356863_0001/container_1677137356863_0001_01_000004/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000004 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 172.19.126.122 44771 attempt_1677137356863_0001_m_000000_2 4
|- 7555 7554 7555 7555 (bash) 1 0 9797632 248 /bin/bash -c /lib/jvm/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/data/nm-local-dir/usercache/root/appcache/application_1677137356863_0001/container_1677137356863_0001_01_000004/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000004 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 172.19.126.122 44771 attempt_1677137356863_0001_m_000000_2 4 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000004/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1677137356863_0001/container_1677137356863_0001_01_000004/stderr
[2026-03-16T01:49:48+00:00.805]Container killed on request. Exit code is 143
[2026-03-16T01:49:48+00:00.808]Container exited with a non-zero exit code 143.
2026-03-16T01:49:48+00:00,859 INFO mapreduce.Job: map 100% reduce 100%
2026-03-16T01:49:48+00:00,914 INFO mapreduce.Job: Job job_1677137356863_0001 failed with state FAILED due to: Task failed task_1677137356863_0001_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0
2026-03-16T01:49:48+00:00,147 INFO mapreduce.Job: Counters: 13
Job Counters
Failed map tasks=4
Killed reduce tasks=1
Launched map tasks=4
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=25131
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=25131
Total vcore-milliseconds taken by all map tasks=25131
Total megabyte-milliseconds taken by all map tasks=25734144
Map-Reduce Framework
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
[root@hadoop120 hadoop-3.1.3]#



编辑


编辑
这个是解决办法
我们修改一下,然后再去重新启动:,这里我们先不配置,我们试试能不能启动,看看默认配置行不行,
因为发现了虚拟机,给配置内存是1GB,太少了,我们改成了4GB,4核心CPU,然后再去试试.先试试行不行.
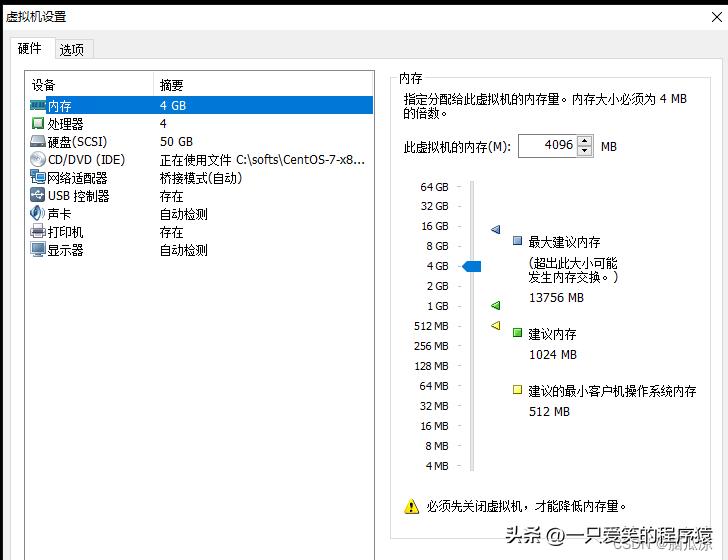

编辑
修改之前首先去改一下虚拟机的配置,这里处理器,给2核心2逻辑核心,一共4 然后内存给4096 4GB,不知道怎么回事
一看分了1GB...三台机器都调整成这样.其实分6G内存也不多...
只要不出错了先这样用着吧.
因为修改了配置,重启了机器,我们在
172.19.126.122 HDFS:SecondaryNameNode DataNode Yarn: NodeManager
172.19.126.121 HDFS:DataNode Yarn: ResourceManager NodeManager
172.19.126.120 HDFS:NameNode DataNode Yarn: NodeManager
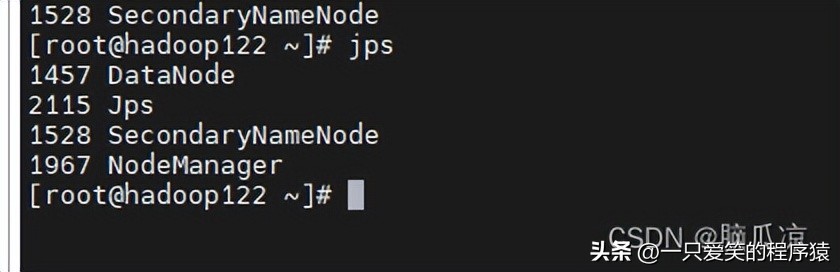
可以看到我们namenode在120上面,所以在120上启动namenodehdfs namenode -format
120:start-dfs.sh121:start-yarn.sh
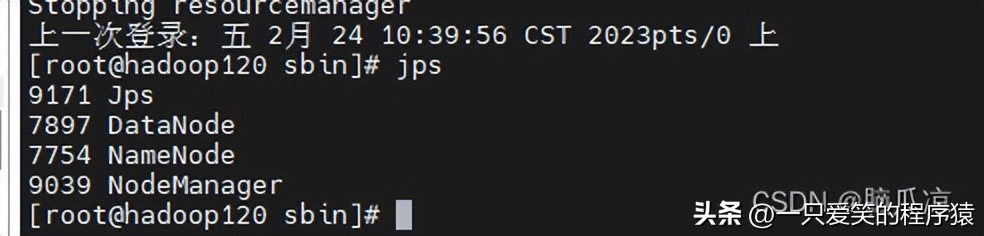
120上再去走到/opt/module/hadoop-3.1.3/sbin 下去执行 start-dfs.sh 启动dfs
然后再去:
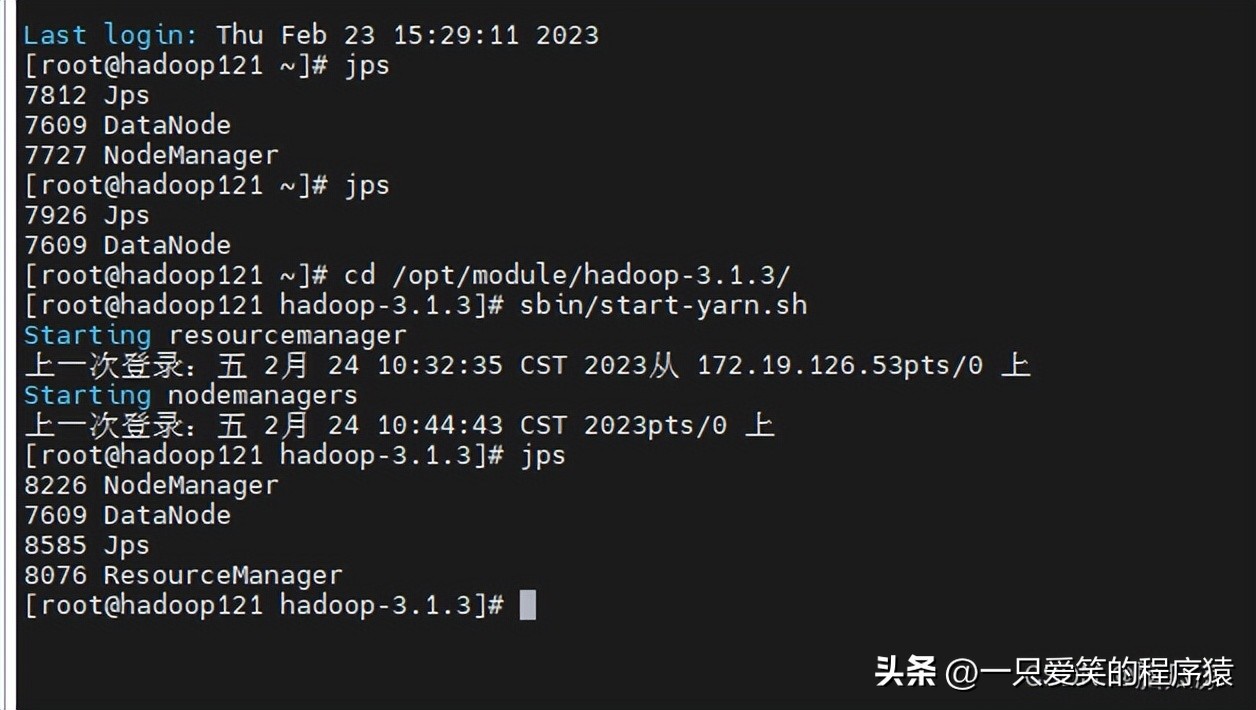
121上执行走到/opt/module/hadoop-3.1.3/sbin 下去执行 start-yarn.sh 启动yarn
然后对比一下:

编辑

编辑

编辑
可以看到启动以后,跟我们计划是一样的,然后我们再去启动.
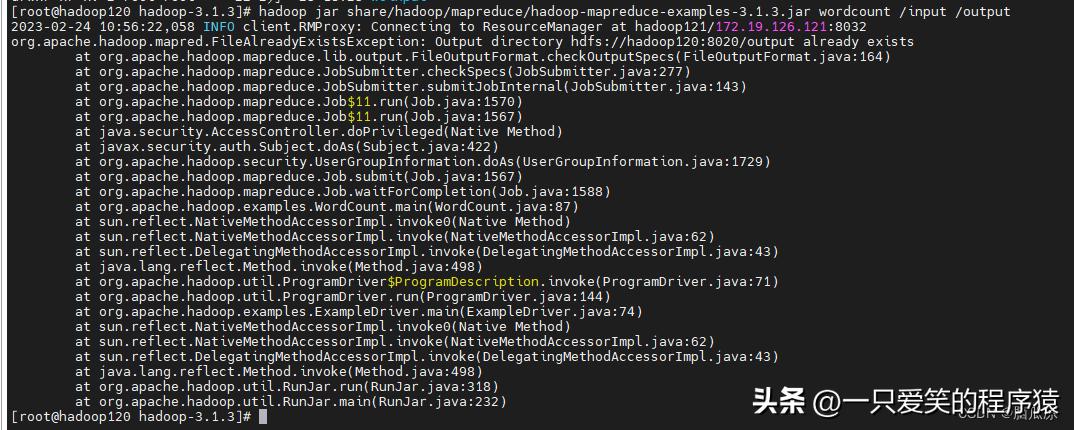
这个测试,在120上测试, 执行

编辑
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
报错,可以看到提示/output目录已经有了,这个时候,我们去删除一下这个目录

编辑
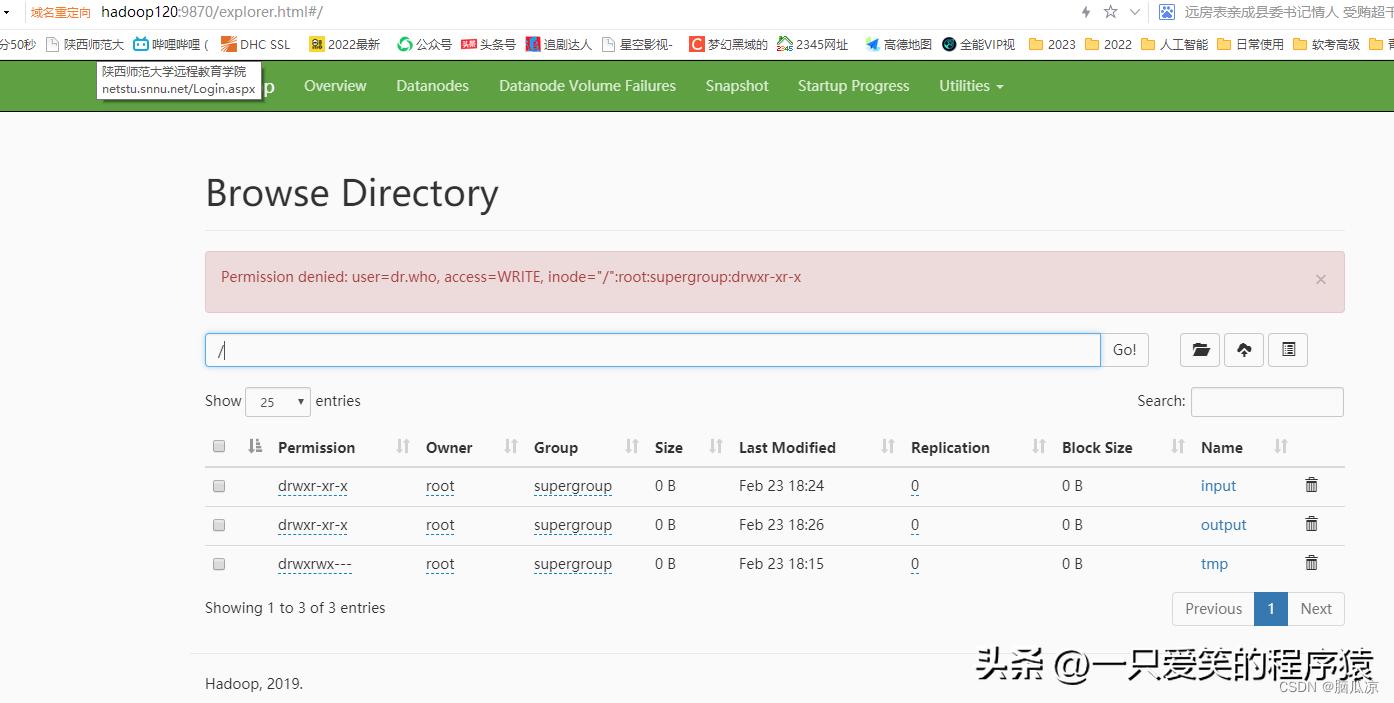

编辑
但是在hdfs上,点击删除按钮报错没有权限.
我们用命令进行删除试试:


编辑
hadoop fs -rm /output
可以看到虽然执行了成功了,但是

编辑
后台显示还有这个文件夹.咋整.
修改这个错误,怎么修改?
Permission denied: user=dr.who, access=WRITE, inode="/":root:supergroup:drwxr-xr-x 这个错误
修改一个配置文件:
首先120上先去关闭:
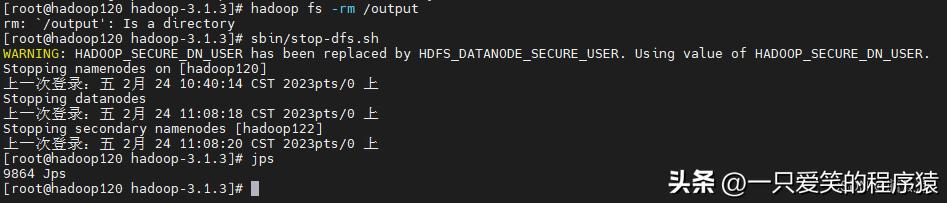

编辑
hdfs,然后121上关闭yarn

编辑
然后去编辑:vim core-site.xml

编辑
首先去走到对应的配置文件目录,然后

编辑
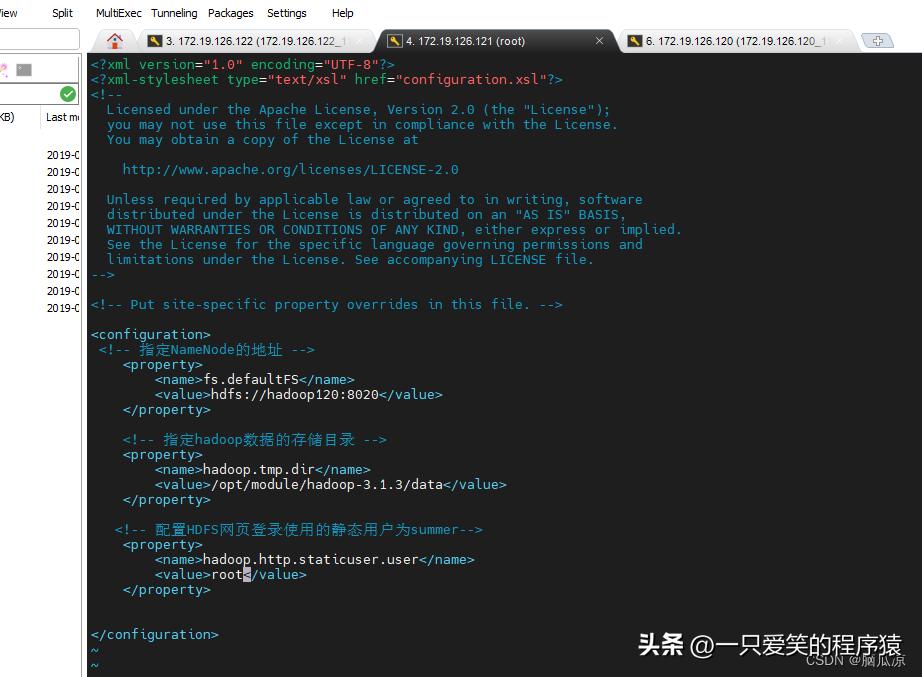
然后添加上对应的静态用户配置,然后保存退出
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop120:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
~

可以看到加上了网页登录使用的静态用户为root,
然后再去把刚修改的文件,分发到集群各个机器上,要注意我这里是从121机器上修改的,
所以要同步到其他集群机器.

编辑
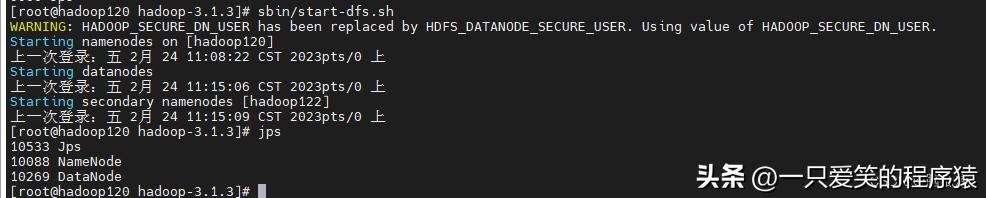
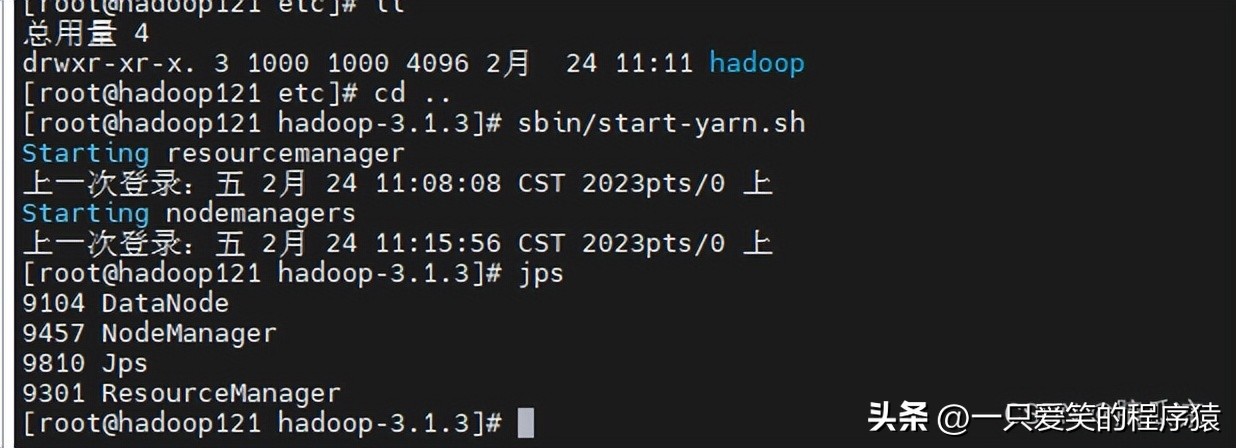
然后再去,120,上启动hdfs,121上启动yarn

编辑

编辑
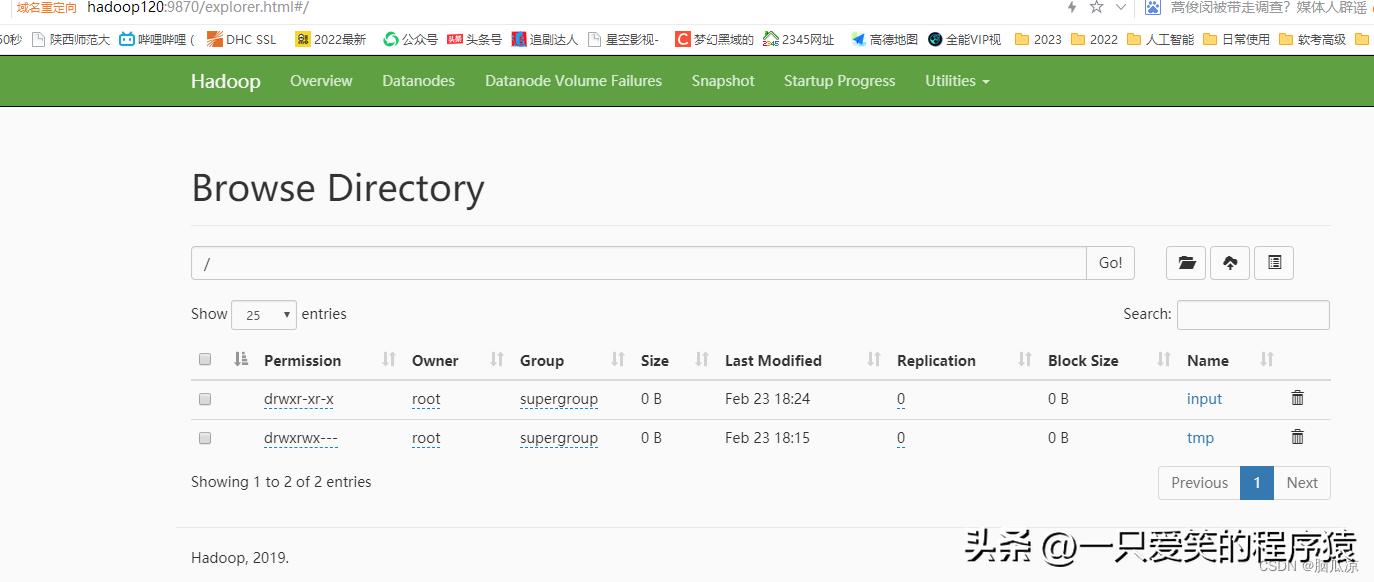
启动以后,然后我们再去试试:

编辑
可以看到这个时候,web网页端的hdfs,就可以直接点击删除按钮删除,output文件夹了
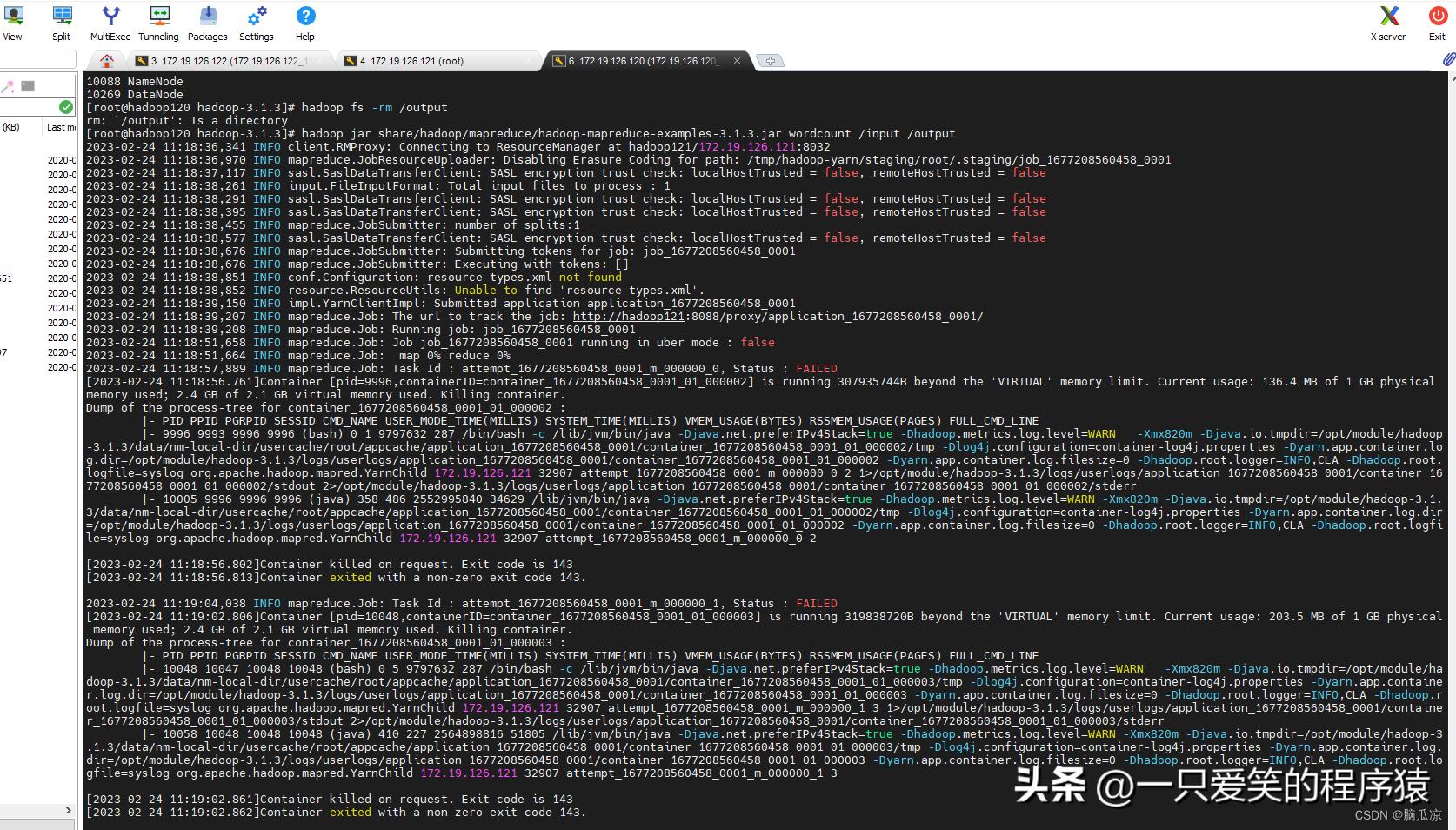
我们再去执行一下那个案例;wordcount
可以看到还是报错,那么就去修改配置把.

编辑
还是报错一样的错误.
内存不够.
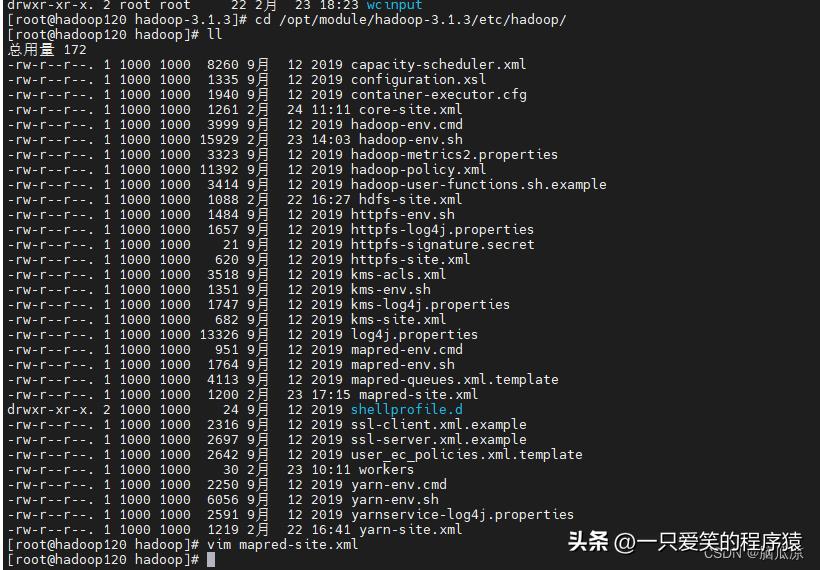
去做一下配置:

编辑
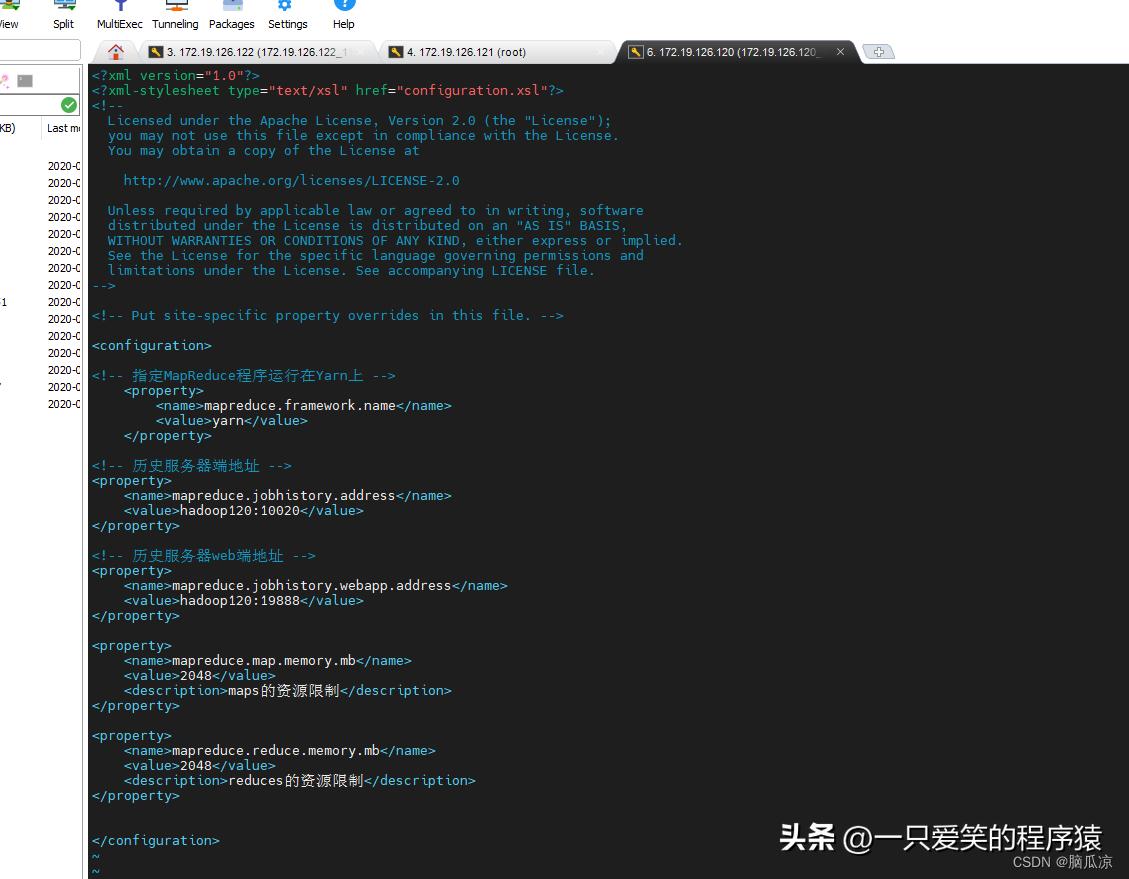
打开对应的配置文件,然后:

编辑
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop120:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop120:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
<description>maps的资源限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
<description>reduces的资源限制</description>
</property>
</configuration>

做好配置,然后保存退出,然后分发配置到,集群各个机器上.

编辑
分发以后


编辑
然后重启一下hdfs,在120上重启hdfs


编辑
在121上重启yarn


编辑


编辑
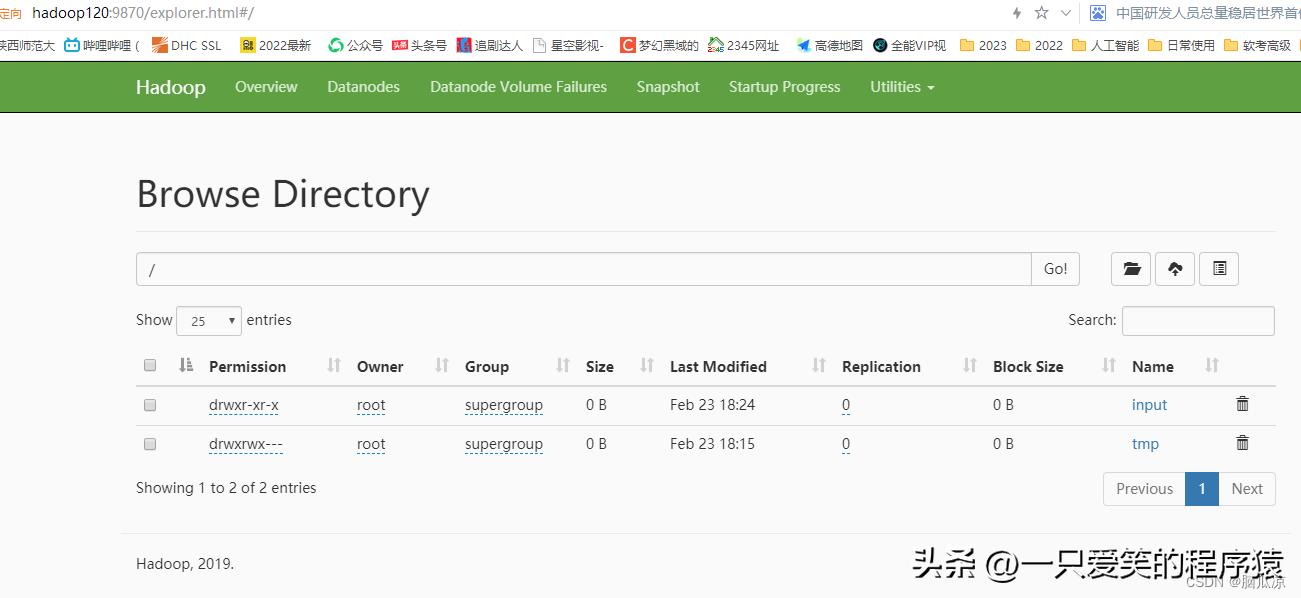
启动以后,

编辑
然后我们删除ouput文件夹,然后再做一下测试
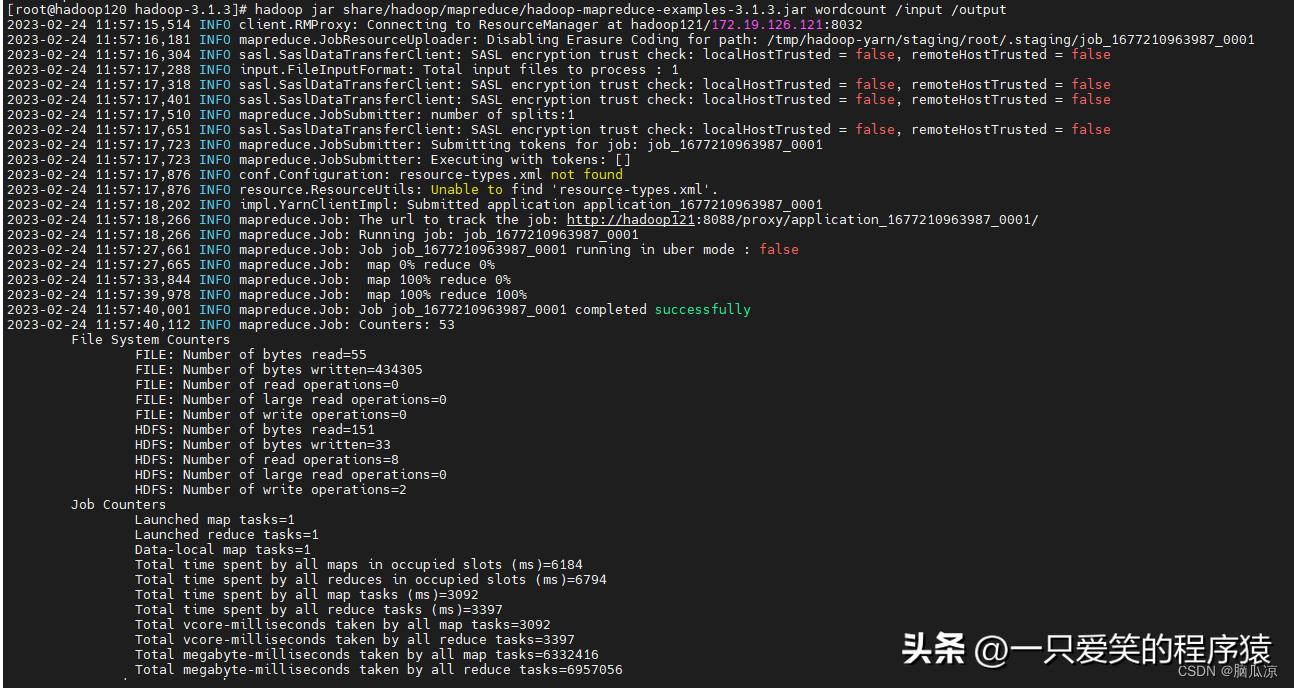

编辑
可以看到成功了,这次
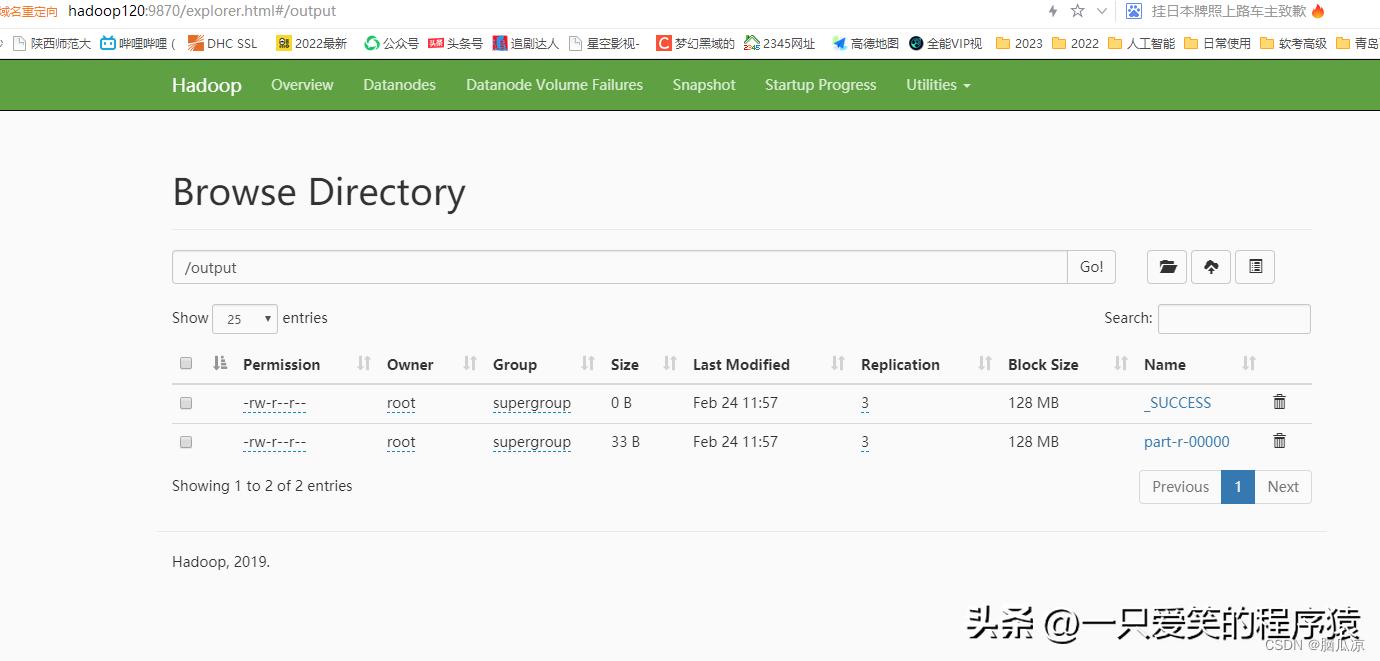

编辑
然后我们去看看,执行以后的结果,*载下**下来结果文件


编辑
看一下没问题对吧.
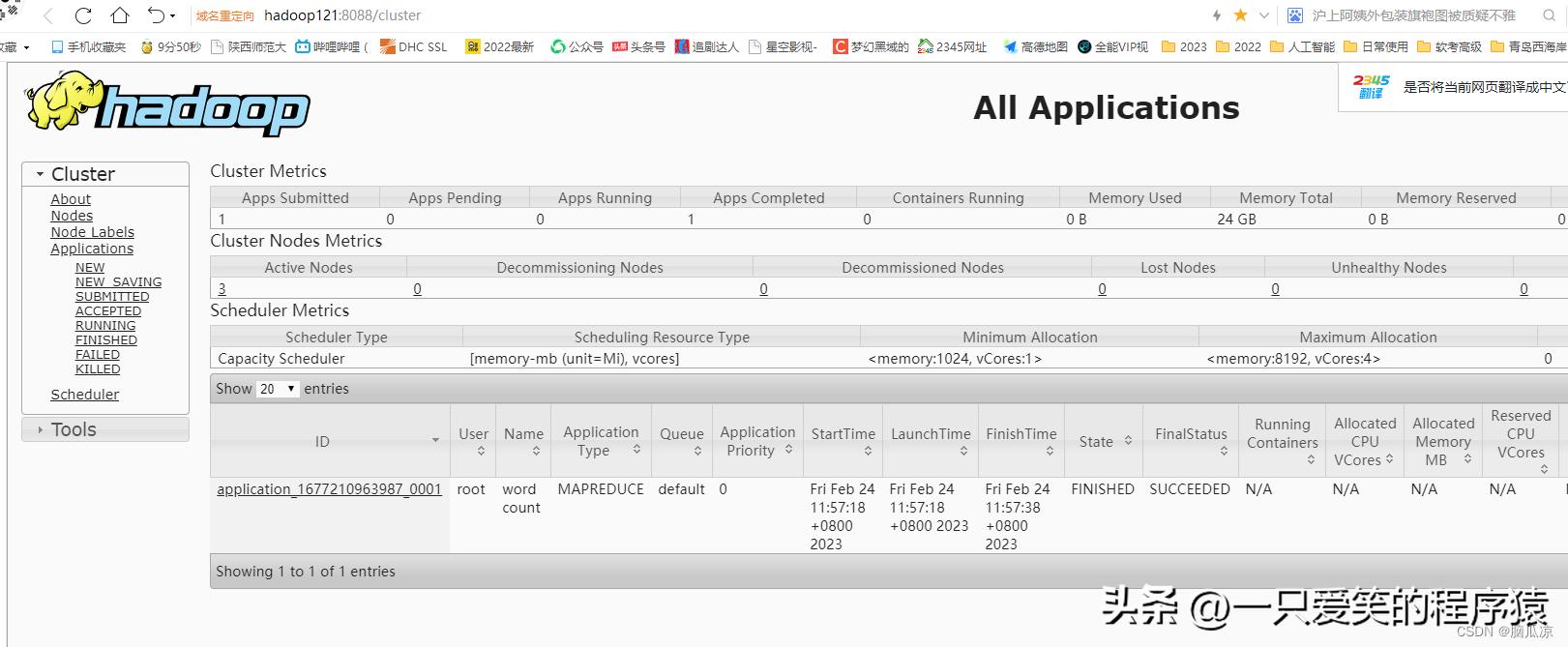

编辑
然后我们去看看历史服务器可以用了吗
然后点击右边的history,可以看到


编辑
打不开,因为还没有启动历史服务器,去启动一下
这里,走到120机器上执行:启动,因为我们配置的120是历史服务器.
[root@hadoop120 hadoop-3.1.3]# cd bin
[root@hadoop120 bin]# ll
总用量 1000
-rwxr-xr-x. 1 1000 1000 441936 9月 12 2019 container-executor
-rwxr-xr-x. 1 1000 1000 8707 9月 12 2019 hadoop
-rwxr-xr-x. 1 1000 1000 11265 9月 12 2019 hadoop.cmd
-rwxr-xr-x. 1 1000 1000 11026 9月 12 2019 hdfs
-rwxr-xr-x. 1 1000 1000 8081 9月 12 2019 hdfs.cmd
-rwxr-xr-x. 1 1000 1000 6237 9月 12 2019 mapred
-rwxr-xr-x. 1 1000 1000 6311 9月 12 2019 mapred.cmd
-rwxr-xr-x. 1 1000 1000 483728 9月 12 2019 test-container-executor
-rwxrwxrwx. 1 root root 740 2月 22 14:40 xsync
-rwxr-xr-x. 1 1000 1000 11888 9月 12 2019 yarn
-rwxr-xr-x. 1 1000 1000 12840 9月 12 2019 yarn.cmd
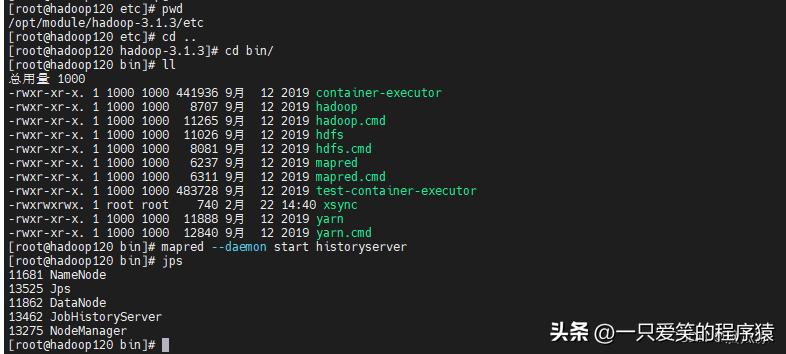
[root@hadoop120 bin]# mapred --daemon start historyserver
[root@hadoop120 bin]# jps
11681 NameNode
12177 NodeManager
12676 Jps
11862 DataNode
12614 JobHistoryServer

启动以后,然后我们删除output文件夹,在hdfs网页端,然后重新执行一下wordcount程序
历史服务器 启动以后,然后我们再去,重新执行一下,wordcount程序,然后看看日志.
这里自己重新执行就可以了

编辑
首先删除掉ouput文件夹,然后:

编辑
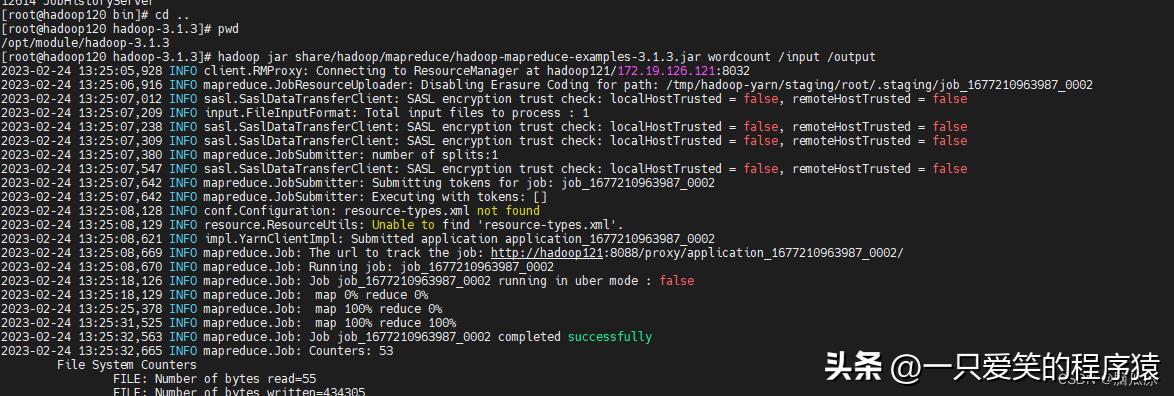
再去执行命令.然后:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
然后去看看日志:
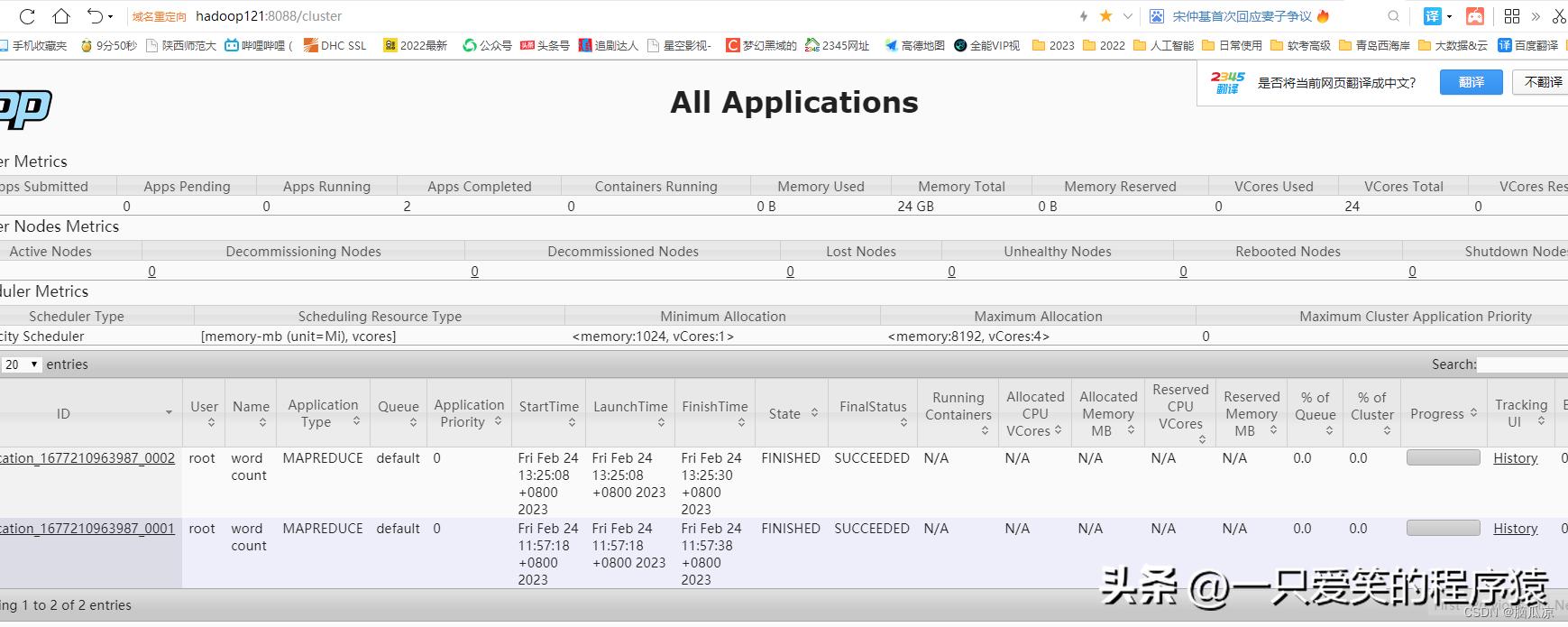

编辑
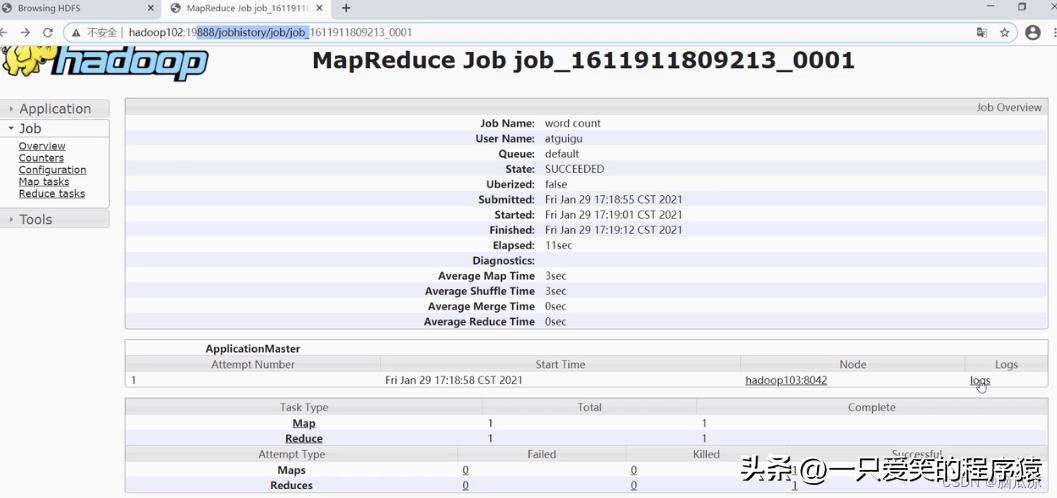
看最上面那个,最新的那个,然后点击history.打开历史看看
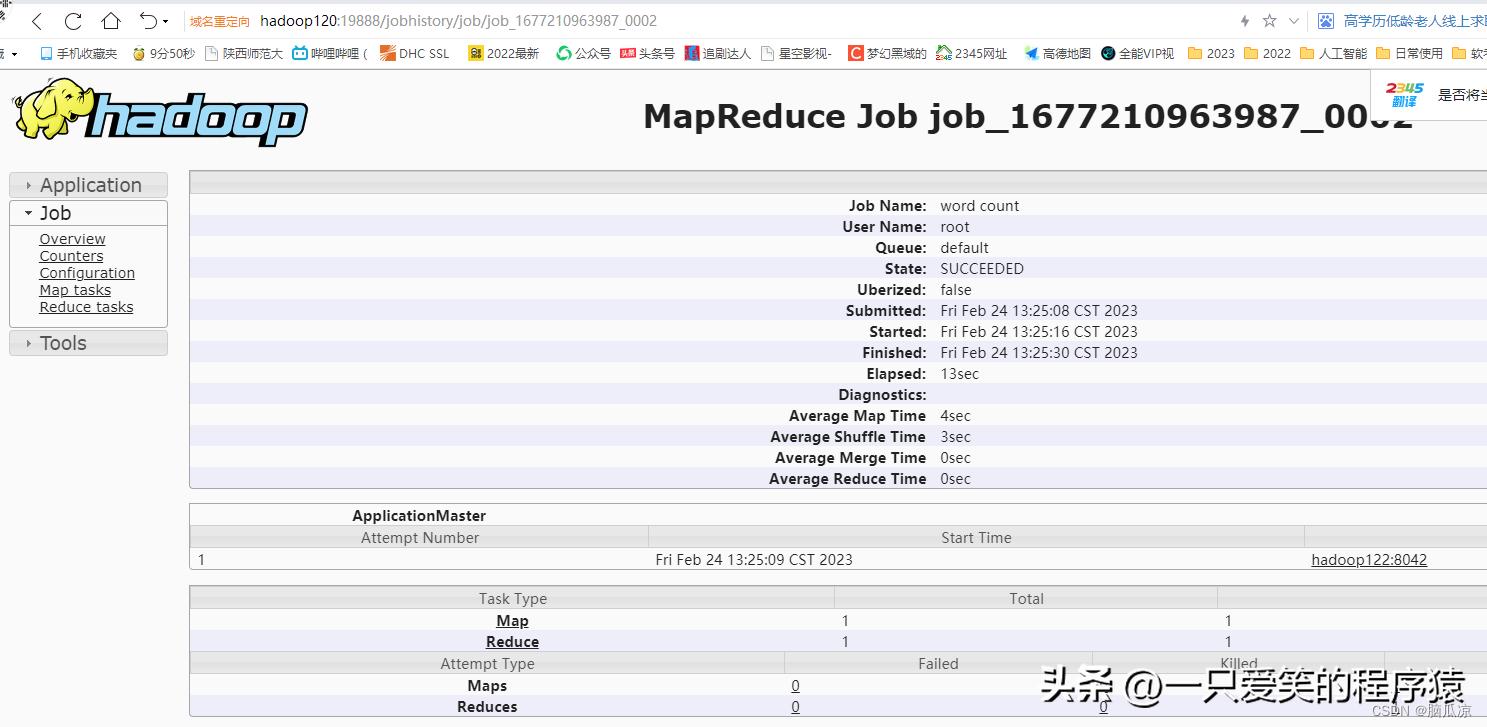

编辑
打开历史可以看到里面有,map reduce了,打开就可以看日志了:
但是打开一看,还是不行:
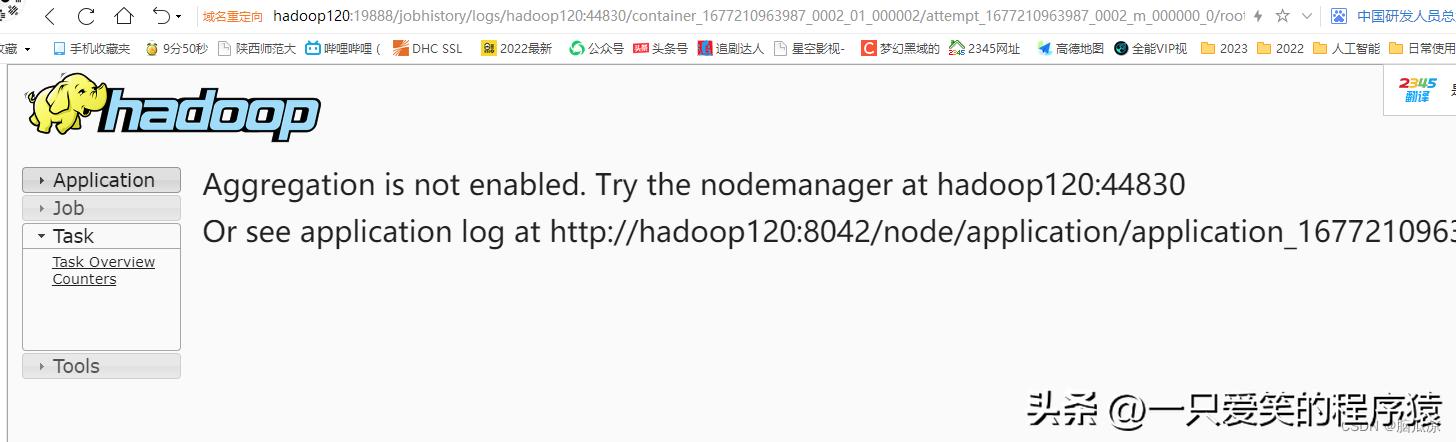

编辑
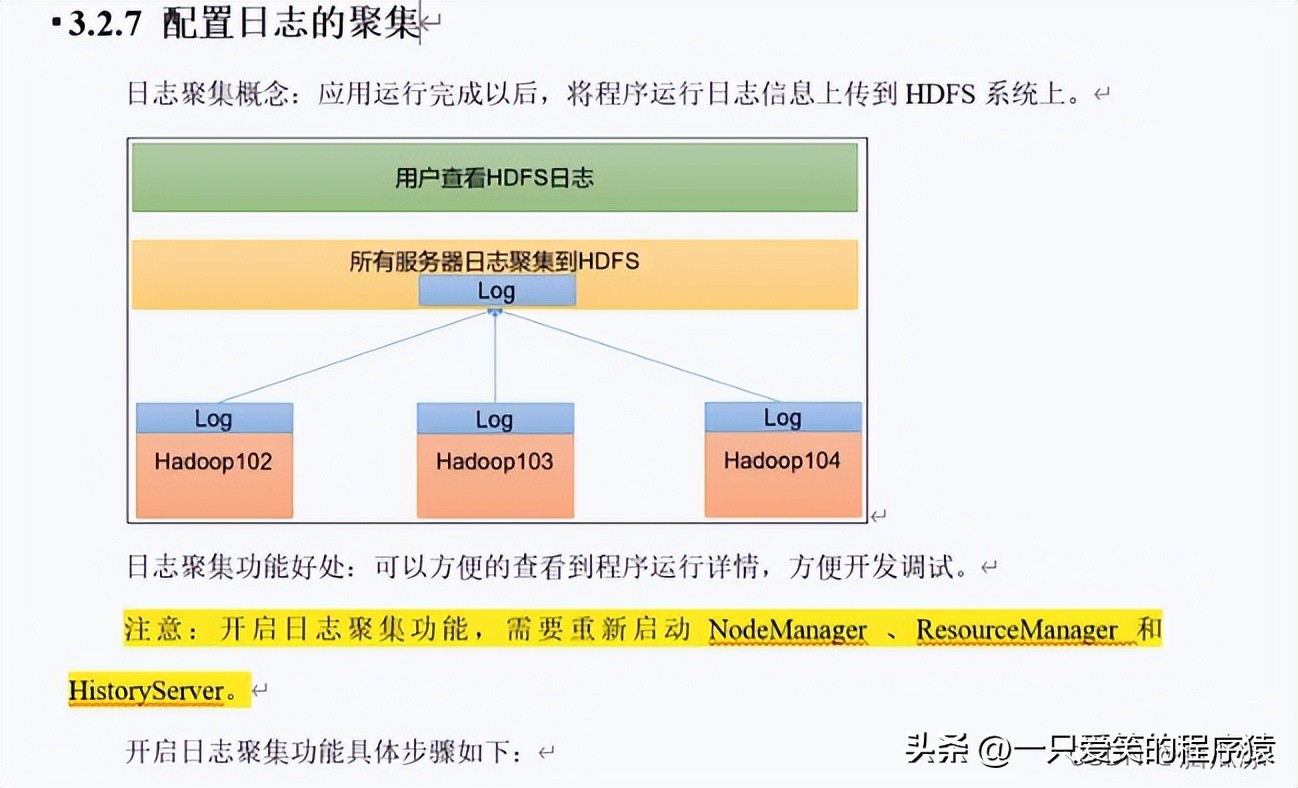
注意这是因为没有配置日志聚集功能,那么好吧....

编辑

编辑

编辑
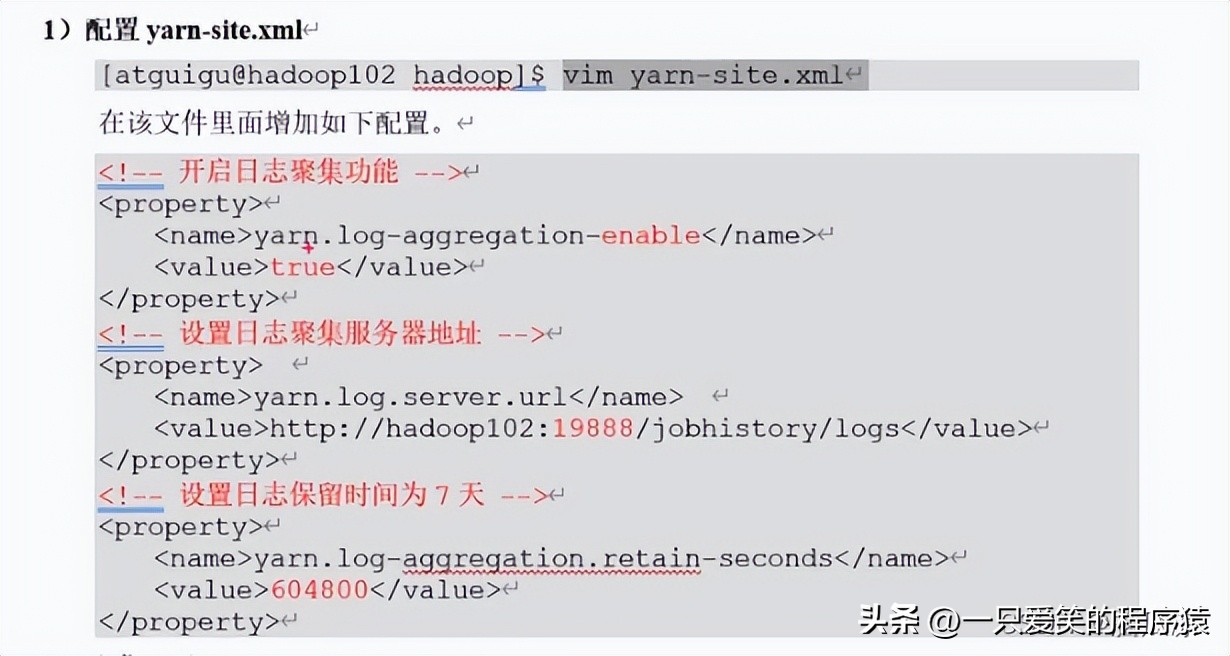
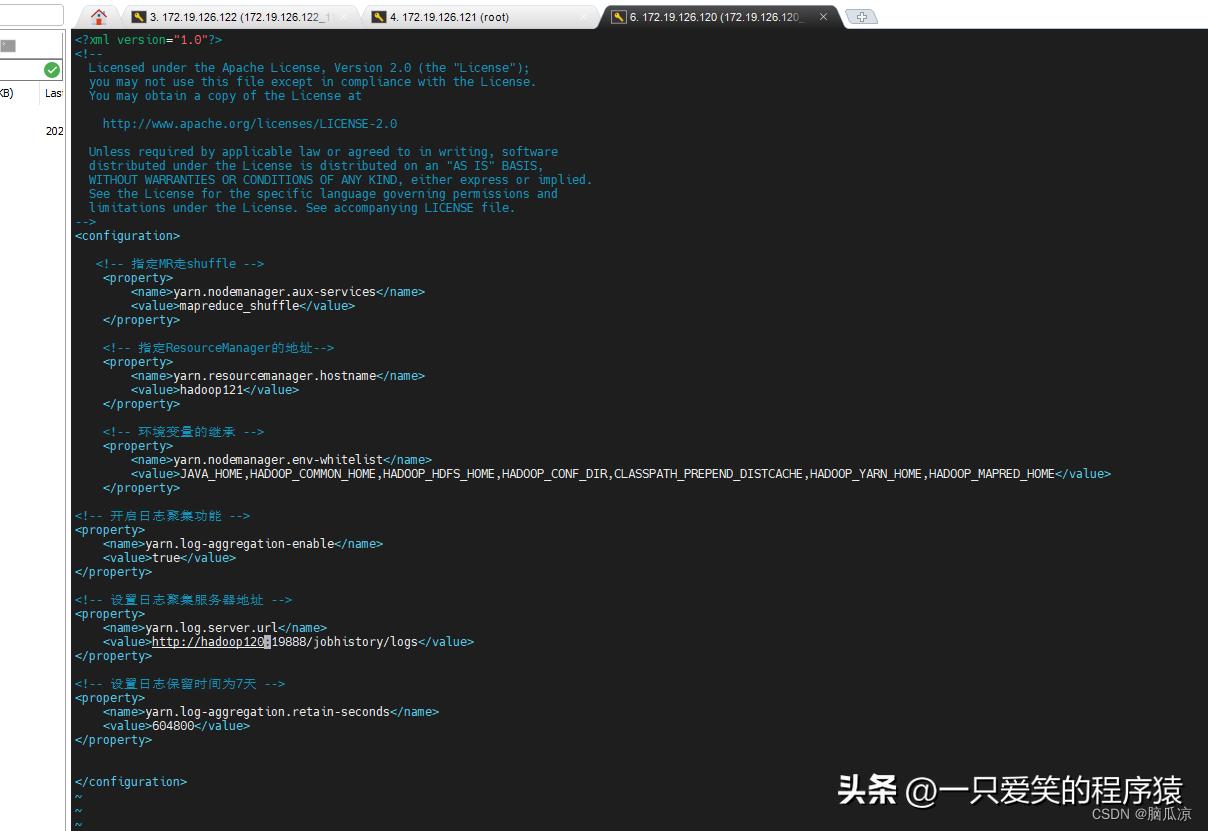
去修改这个yarn-site.xml来开启日志聚集服务


编辑
可以看到我们要配置的这个默认的配置是false对吧,这个
可以从默认配置文件中找,这个我们已经整理好了.这些默认配置文件


编辑
然后我们去配置
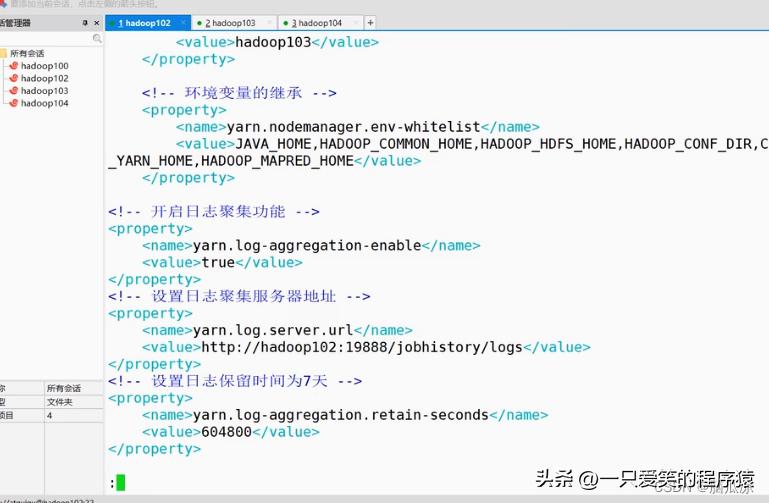

编辑
配置以后保存退出

编辑 .
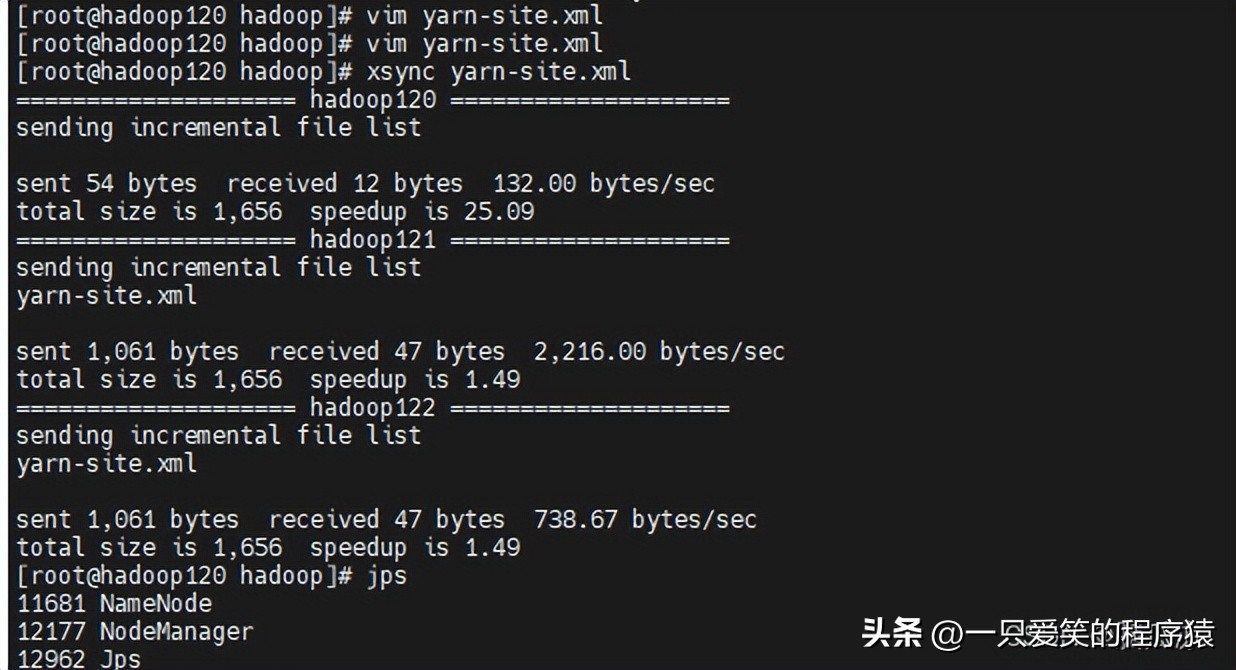
分发到其他机器上去
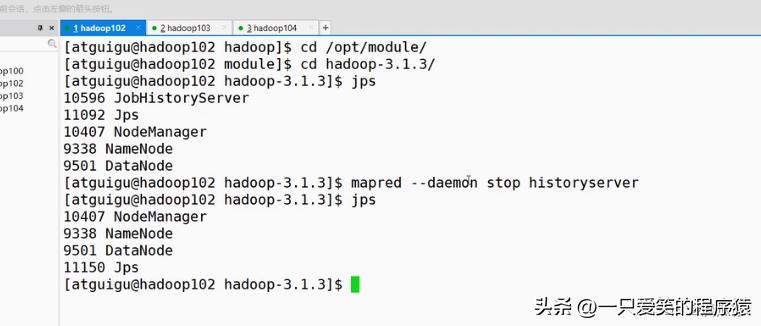

编辑
然后再去关闭历史服务器,然后重启历史服务器
在120上重启对吧,因为配置了120是历史服务器
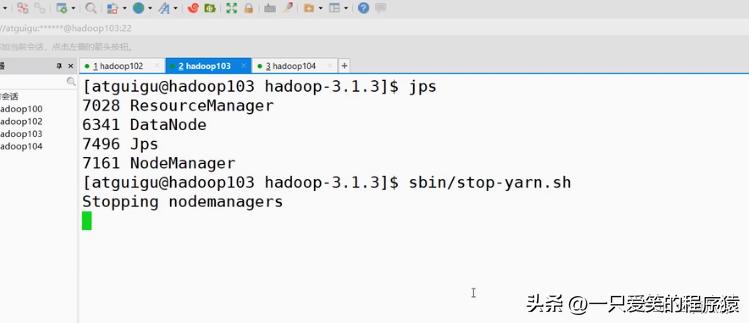

编辑
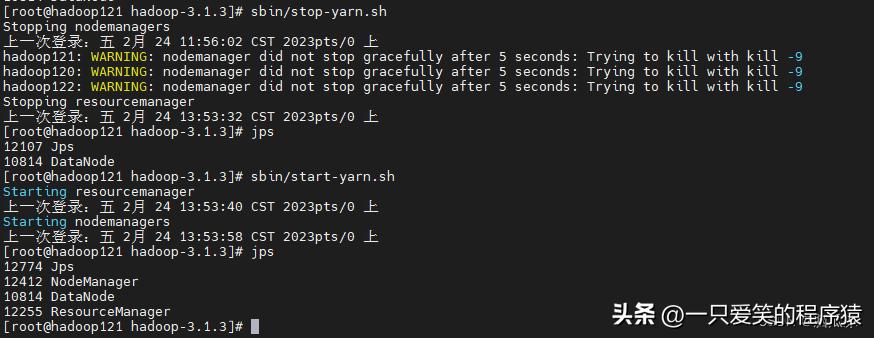
然后重启一下yarn,我们是在121服务器上是resourcemanager对吧
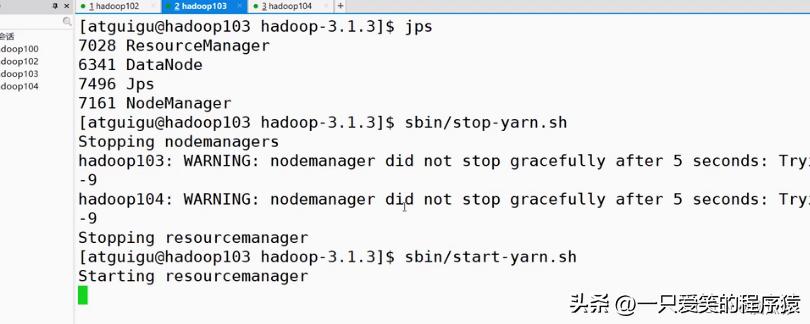

编辑
然后我们请启动yarn
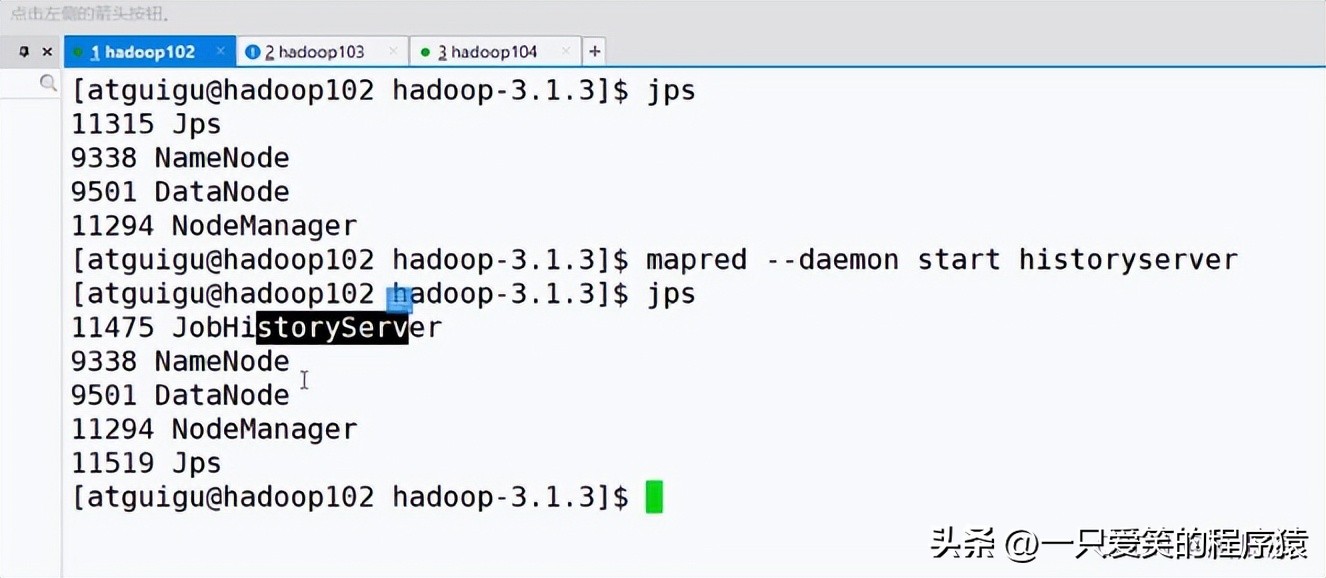

编辑
然后再去启动历史服务器


编辑
然后再执行wordcount程序

编辑
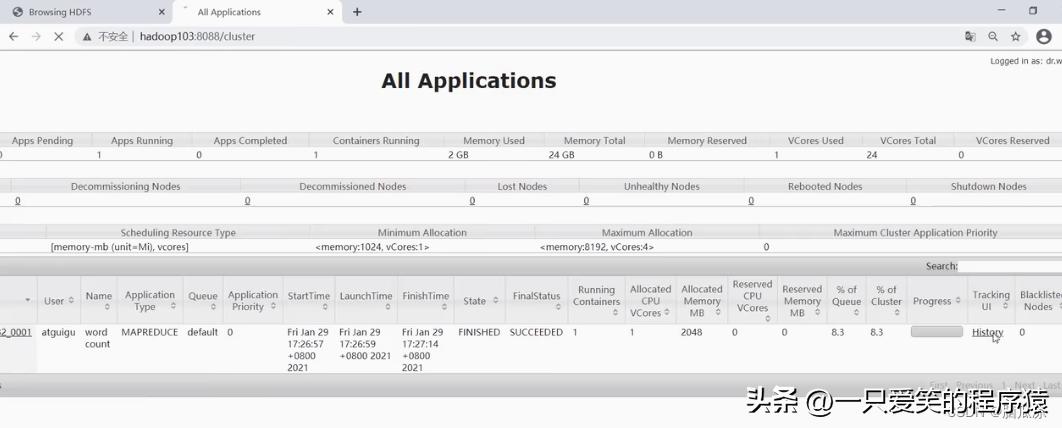
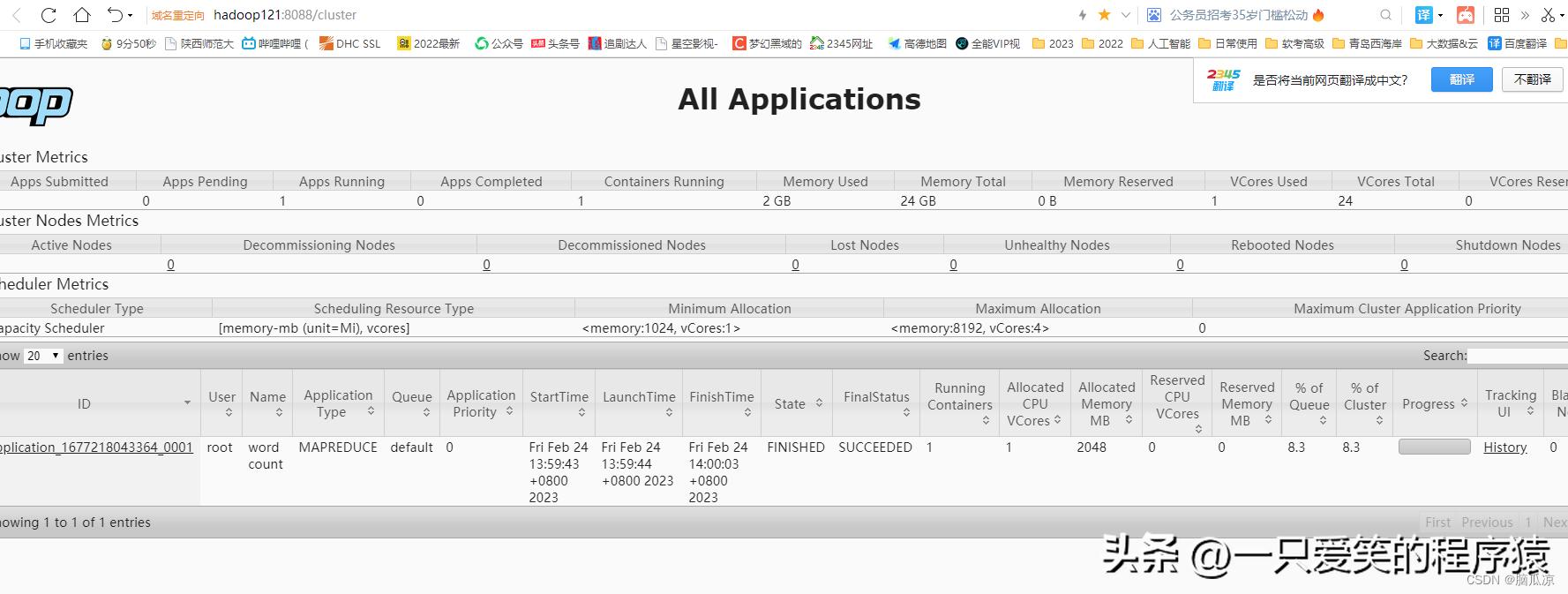
然后去集群监控网页端看看

编辑
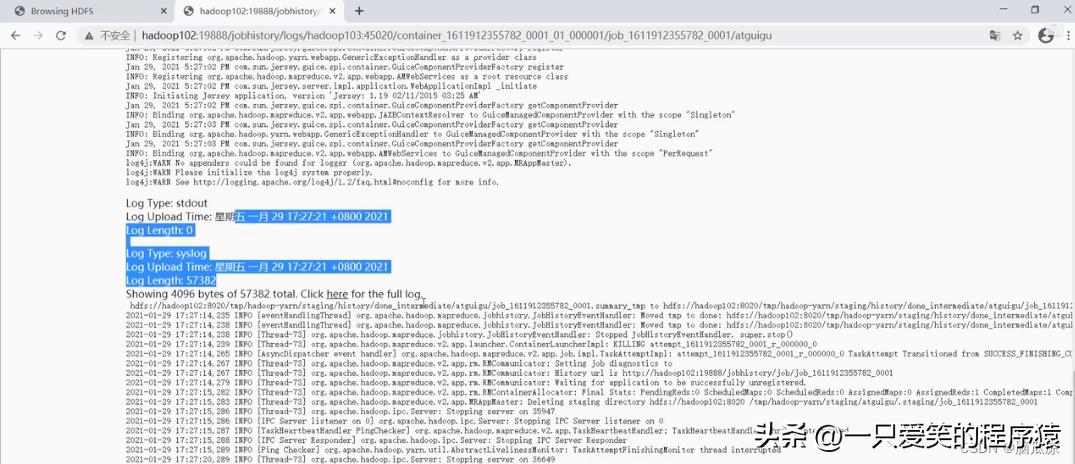
然后再去看详细日志就有了

编辑
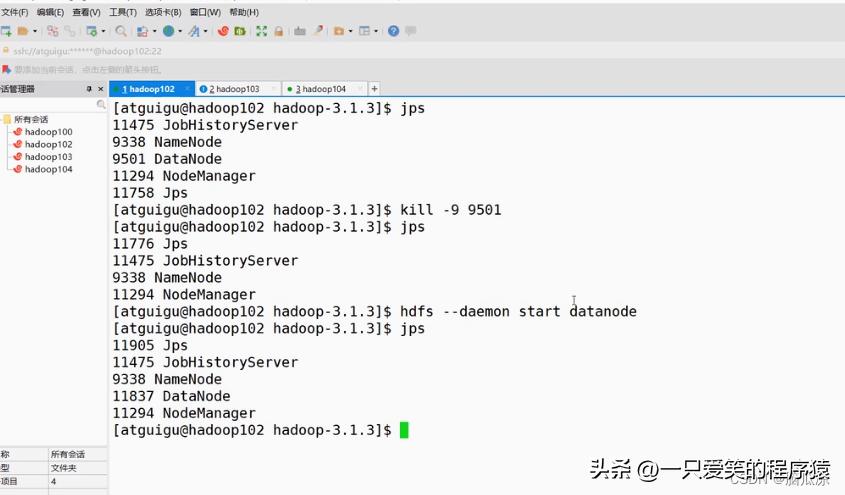
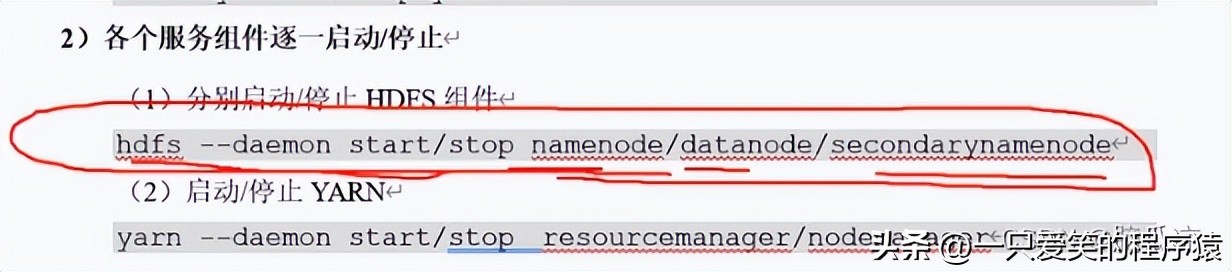
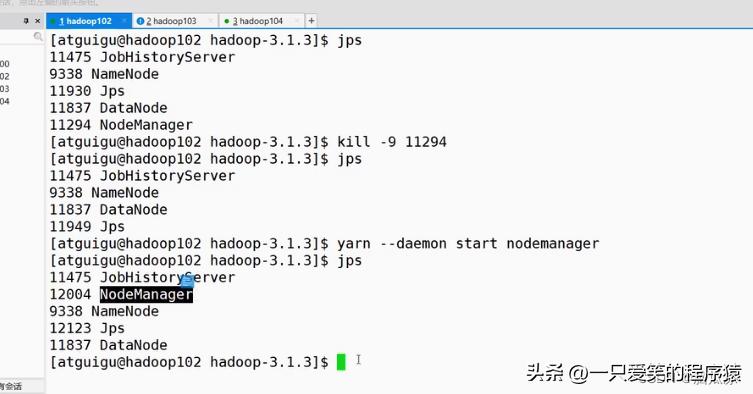
然后我们再去看看怎么样单独启动某个进程,意思就是,我启动的时候,比如上面这个DataNode,我只在102这个机器上启动
如果我们用start-dfs.sh这样启动,是在集群上启动所有的节点,而上面是,单独在这个机器上启动,比如
只有我们这个机器上的DataNode挂掉了,就可以单独启动这一个节点的了.

编辑
然后我们来实际操作一下,首先配置
日志聚集服务器,可以看到在/opt/module/hadoop-3.1.3/etc/hadoop
去编辑yarn-site.xml这个文件

编辑
编辑以后分发到其他机器

编辑
然后重启historyserver,在120上

编辑
然后重启yarn,在121机器上

编辑
然后在120上重启historyserver

编辑
重启以后,然后测试,首先删除以前生成的output文件夹

编辑
然后再去执行wordcount程序,案例程序

编辑
然后执行以后,去看看日志,集群管理器去看看,可以看到最上面的任务,然后找到history,点击
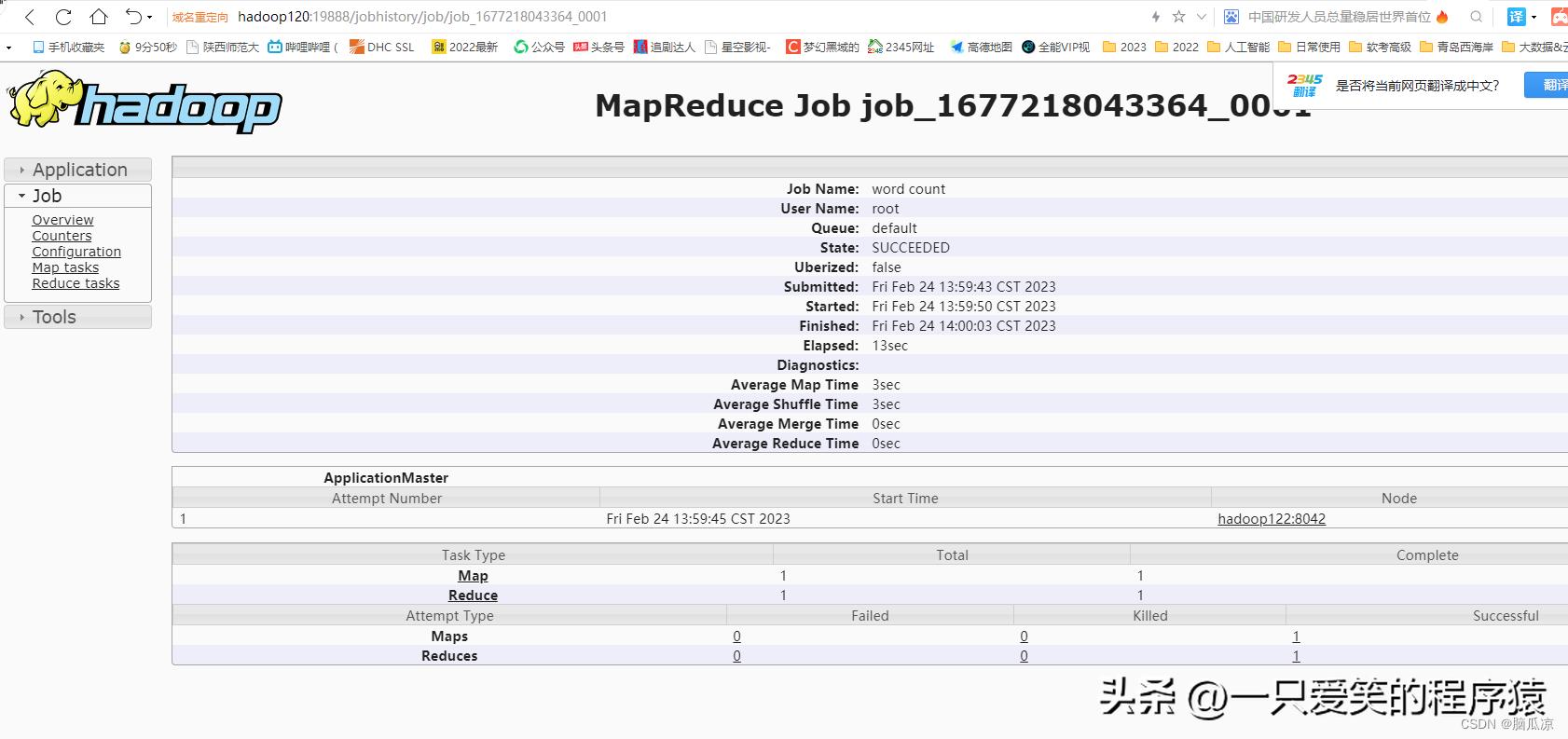

编辑
然后再点击map,或者拉到右边,点击logs
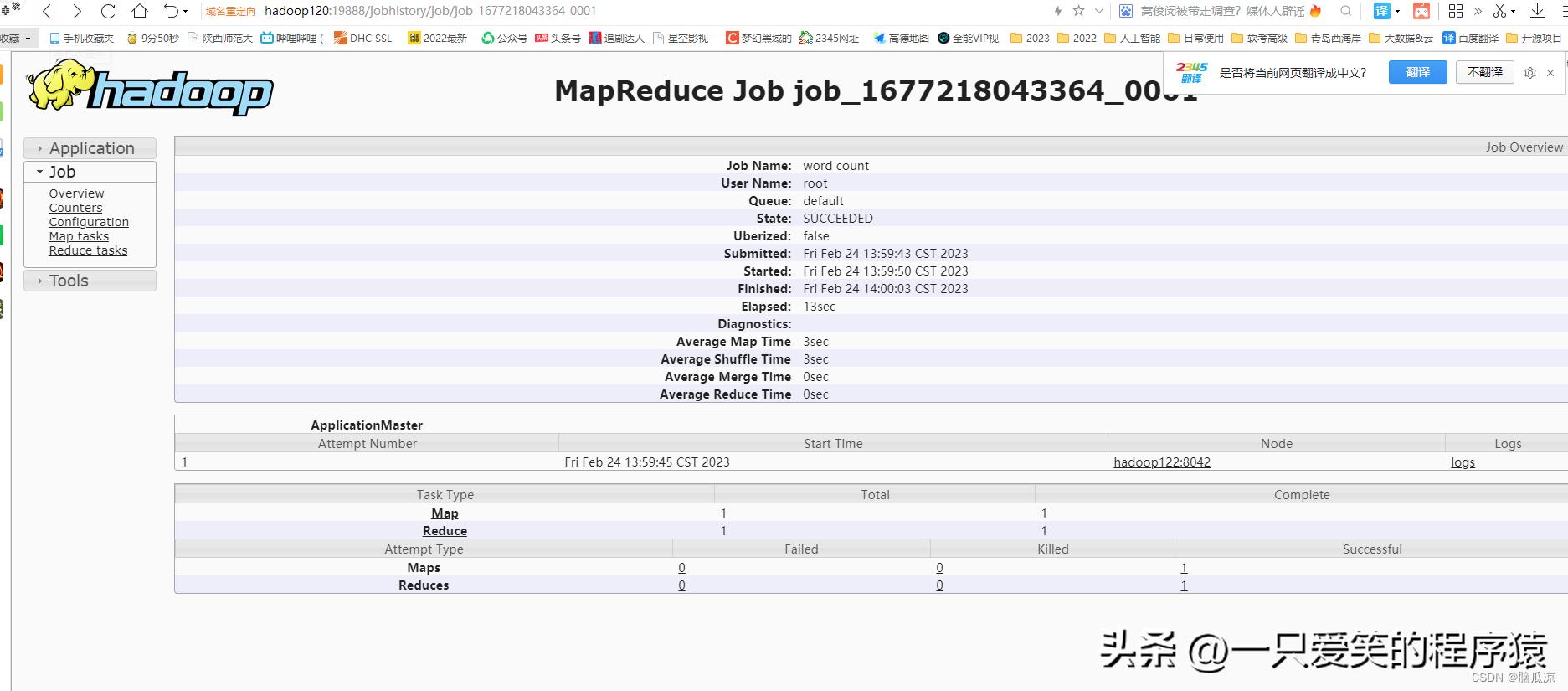

编辑
点击这个logs
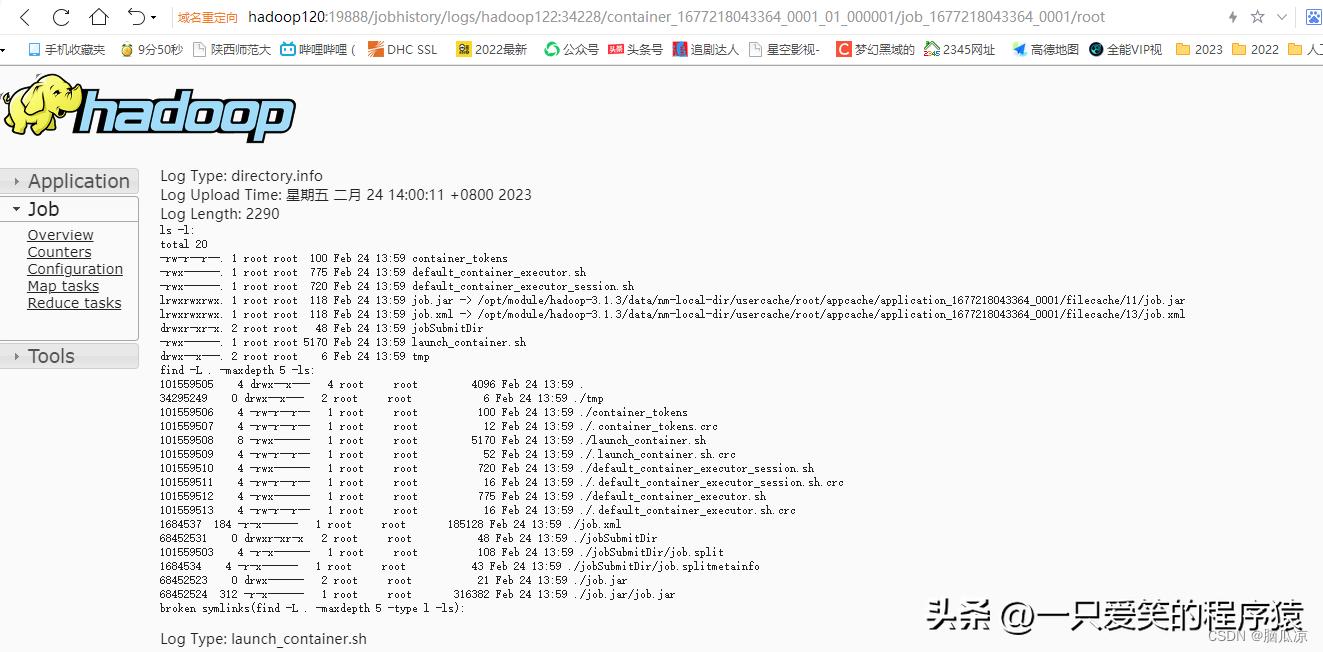

编辑
可以看到日志就可以正常看到了.

编辑
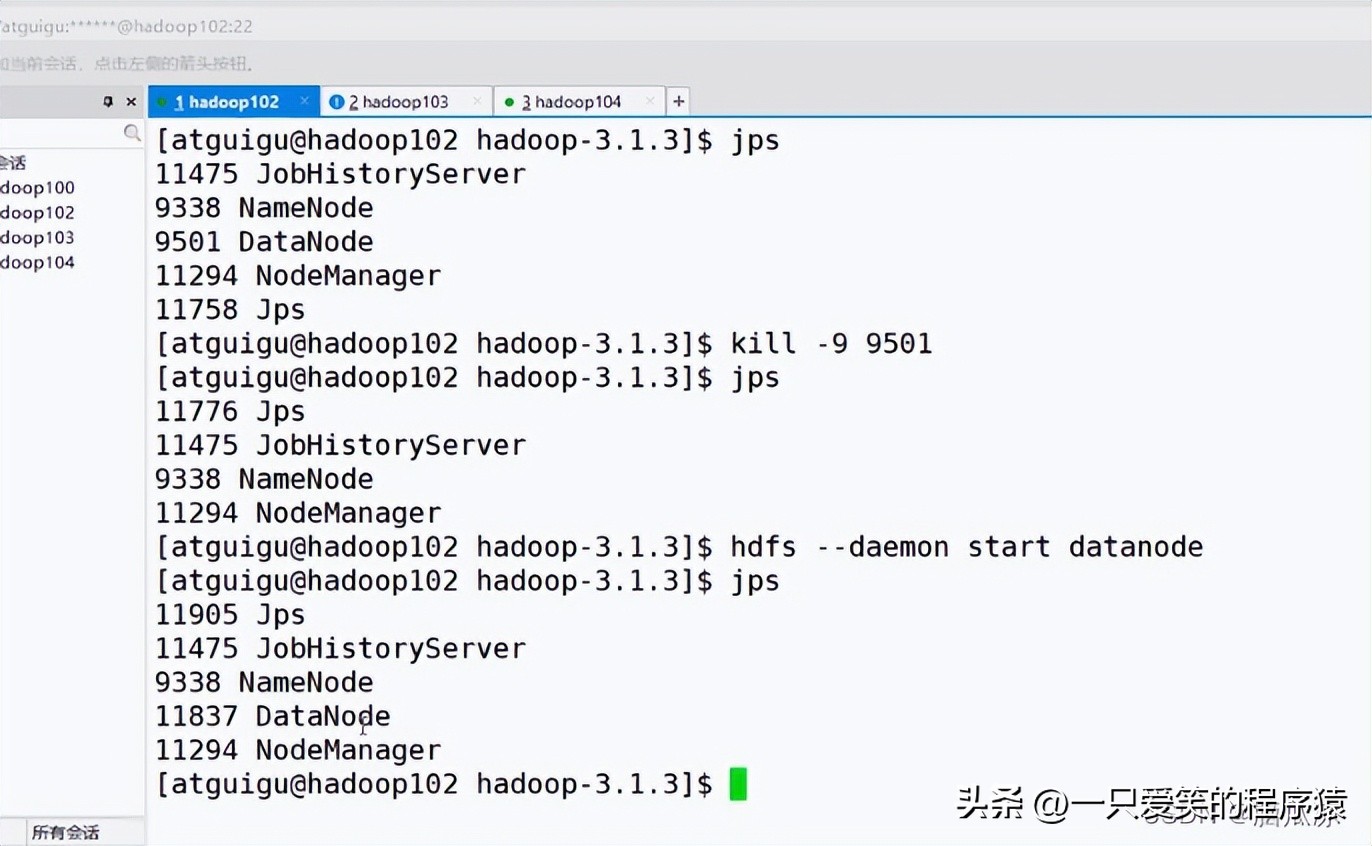
然后我们再看看,如何操作某一台机器,启动某个服务,节点,用
hdfs --daemon start datanode
单独启动这个机器上的datanode节点对吧

编辑

编辑
对于启动nodemanager,要用yarn这个要知道.