
作者:GjZero
标签:Python, Keras, 语言模型, 日语
本文约2400字,建议阅读10分钟。
本文介绍了语言模型,并介绍如何用MeCab和Keras实现一个日文的神经网络语言模型。(为什么是日文呢?纯属作者兴趣)
基于神经网络的语言模型
依据Wikepedia,语言模型的定义是“句子们的概率分布”。给定一个长度为m的句子,则可以有概率
P(w_1,...,w_m)
由条件概率公式有
P(w_1,...w_m) = \prod_{i=1}^mP(w_i|w_1,...w_{i-1})
n-gram模型假设,第i个词语的概率分布只和前面固定的n个词有关(Markov性),那么就有
P(w_1,...w_m) = \prod_{i=1}^mP(w_i|w_1,...w_{i-1}) \approx \prod_{i=1}^mP(w_i|w_{i-(n-1)},...,w_{i-1})
所以估计
P(w_1,...w_m)
的任务变成了估计
P(w_i|w_{i-(n-1)},...,w_{i-1})
用传统的统计方法面临着
- 维度灾难(当n变大,存储空间不够)
- n元组并不会在语料库中全部出现
所以这里使用神经网络近似函数
P(w_i|w_{i-(n-1)},...,w_{i-1})
神经网络方法解决了如上两个困难
- 当n变大,神经网络的参数以线性级别增长
- n元组虽然没有全部出现,但词向量可以捕捉到不同的词可能代表的相似的含义
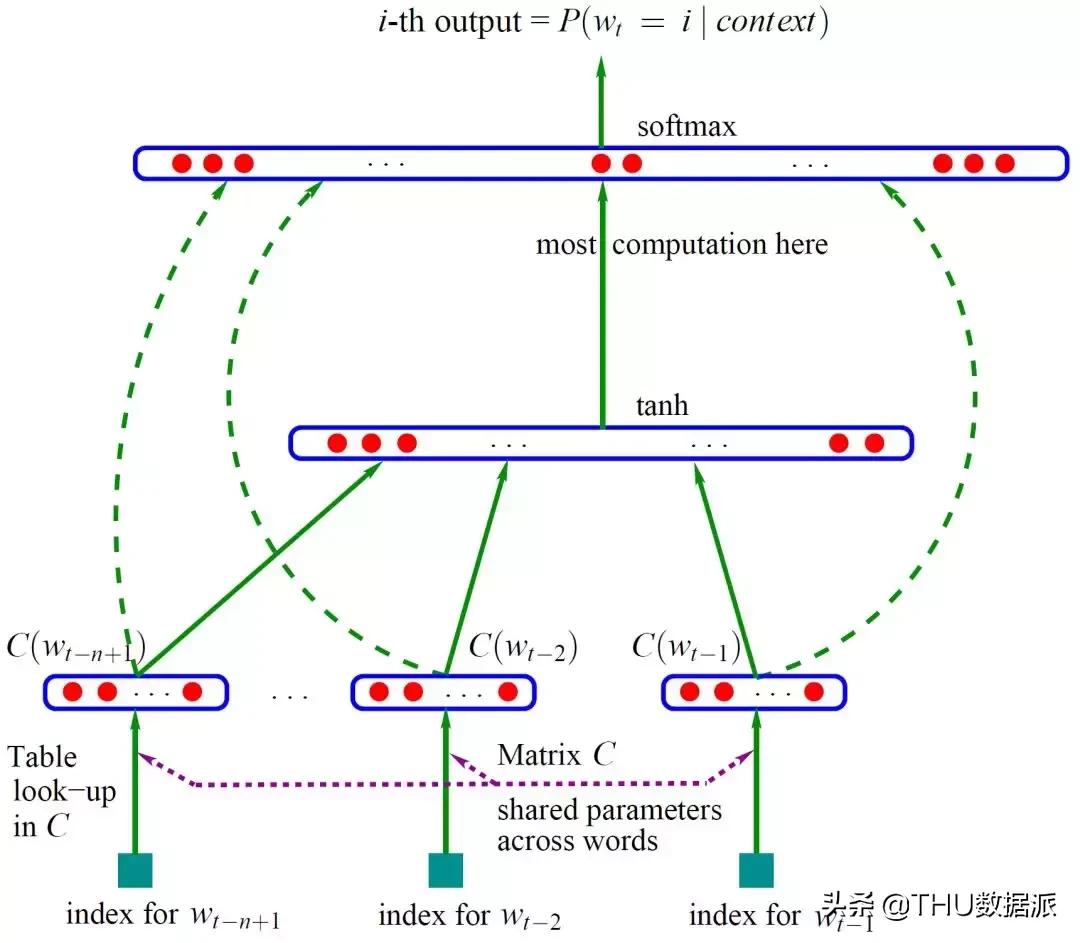
一个传统的基于神经网络的模型结构如下图所示:
用MeCab实现日语分词
MeCab(めかぶ)是一款日语分词工具。Linux用户可以用如下指令安装MeCab:
sudo apt-get install mecab mecab-ipadic-utf8 libmecab-dev swigpip install mecab-python3
MeCab可以对一个句子进行分词,并分析各词的词性。对于句子“すもももももももものうち”有
すもももももももものうちすもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモも 助詞,係助詞,*,*,*,*,も,モ,モもも 名詞,一般,*,*,*,*,もも,モモ,モモも 助詞,係助詞,*,*,*,*,も,モ,モもも 名詞,一般,*,*,*,*,もも,モモ,モモの 助詞,連体化,*,*,*,*,の,ノ,ノうち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS
为了将分析的结果转化为分词结果,可用如下的`mecab_to_text`函数,则会输出“すもも も もも も もも の うち”。
Python
def mecab_to_text(sentence_list):
"""
:param sentence_list: A list of sentences or one single sentence.
:return: A list of segmented sentences.
:note: Use mecab to segment a list of sentences or one single sentence in Japanese.
"""
import MeCab
mecab = MeCab.Tagger("-Ochasen")
single_flag = False
if isinstance(sentence_list, str):
sentence_list = [sentence_list]
single_flag = True
ret_list = []
for sentence in sentence_list:
text_list = []
m = mecab.parseToNode(sentence)
while m:
text_list.append(m.surface)
m = m.next
seg_sentence = " ".join(text_list).strip()
ret_list.append(seg_sentence)
if single_flag:
return ret_list[0]
return ret_list
模型构建
我们需要先构建我们的训练样本,语料库来自日语小说。对语料库中的句子用MeCab进行分词之后,用给定的窗宽k分割出训练集。训练集中的词和词向量进行对应为300维的向量。这样训练集中的每一个x(特征)对应一个(k-1)×300维的矩阵,每一个y(结果)对应一个one-hot的向量。
语料库
语料库是来自于网络上的日语小说,因为版权因素这里不提供*载下**。用什么样的小说并不会太影响我们后续的过程。在这里实现了`load_text`,`make_word_dictionary`,`clear_dictionary`;分别用来读入语料库,从分好词的语料库中生成词典,清理词典中在词向量里没有出现的词。
Python
def load_text(use_length=-1, min_len=10):
start = time.clock()
japanese_text_path = "H:\\Work\\JapaneseModel\\Japanese_book\\"
text_list = []
if use_length == -1:
for file in os.listdir(japanese_text_path):
with open(japanese_text_path + file, ’r’, encoding=’utf-8’) as f:
for line in f.readlines():
line_use = line.strip()
if len(line_use) > min_len:
text_list.append(line_use)
else:
counter = 0
for file in os.listdir(japanese_text_path):
with open(japanese_text_path + file, ’r’, encoding=’utf-8’) as f:
for line in f.readlines():
line_use = line.strip()
if len(line_use) > min_len:
text_list.append(line_use)
counter += 1
if counter == use_length:
print("Japanese text loaded %d lines."%use_length)
elapsed = time.clock() - start
print("Time used:", round(elapsed, 3))
return text_list
print("Japanese text loaded all lines.")
elapsed = time.clock() - start
print("Time used:", round(elapsed, 3))
return text_list
def make_word_dictionary(split_text_list, lower_bound=100):
start = time.clock()
word_dictionary = dict()
for sentence in split_text_list:
sentence_use = sentence.split(" ")
for word in sentence_use:
if not word in word_dictionary:
word_dictionary[word] = 1
else:
word_dictionary[word] += 1
print("Word dictionary established.")
elapsed = time.clock() - start
print("Time used:", round(elapsed, 3))
if lower_bound > 0:
pop_list = []
for word in word_dictionary:
if word_dictionary[word] < lower_bound:
pop_list.append(word)
for word in pop_list:
word_dictionary.pop(word)
word_list = []
for word in word_dictionary:
word_list.append(word)
return word_list
def clear_dictionary(dictionary, embedding_dictionary):
ret_list = []
for word in dictionary:
if word in embedding_dictionary:
ret_list.append(word)
return ret_list
实现了这几个函数以后,就可以用如下的方式读入语料库。
Python
japanese_text = load_text(use_text_length) split_japanese_text = mecab_to_text(japanese_text) dictionary = make_word_dictionary(split_japanese_text, lower_bound=10) dictionary = clear_dictionary(dictionary, embeddings_index)
词向量
我们使用facebook在fastText项目中预训练好的日语300维词向量,*载下**地址点击[这里](https://s3-us-west-1.amazonaws.com/fasttext-vectors/word-vectors-v2/cc.ja.300.vec.gz)。因为该文件的第一行保存了词向量文件的信息,你应该手动删除该行,然后用`load_embedding`函数来读取词向量。
Python
def load_embedding():
start = time.clock()
"""
Total 2000000 words in this embedding file, 300-d. It is float16 type.
The first line is "2000000 300".
You should delete this line.
"""
EMBEDDING_FILE = ’H:\\Work\\cc.ja.300.vec’
def get_coefs(word, *arr): return word, np.asarray(arr, dtype=’float16’)
embeddings_index = dict(get_coefs(*o.strip().split(" ")) for o in open(EMBEDDING_FILE, ’r’, encoding="utf-8"))
elapsed = time.clock() - start
print("Word vectors loaded.")
print("Time used:", round(elapsed, 3))
return embeddings_index
生成训练集
假设我们的窗宽为k,那么我们的训练集由k-1个词组成x_train,由之后连接的词组成y_train。如果k=3,我们语料库中的一个句子为“a bb ccc d”, 其中a、bb、ccc、d分别是4个词。那么我们将这个句子前面连接k-1=2个“space”,结尾连接一个“eol”,扩充为“space space a bb ccc d eof”。这样可以得到如下的训练样本:
x1|x2|y:- | :- | :-space|space|aspace|a|bba|bb|cccbb|ccc|dccc|d|eol
“generate_train”函数实现了上述生成训练集的算法
Python
def generate_train(window, end_index, text_seq): prefix = [0] * (window - 1) suffix = [end_index] x_list = [] y_list = [] for seq in text_seq: if len(seq) > 1: seq_use = prefix + seq + suffix # print(seq_use) for i in range(len(seq_use) - window + 1): x_list.append(seq_use[i: i + window - 1]) y_list.append(seq_use[i + window - 1]) # print(seq_use[i: i + window]) return x_list, y_list
构建神经网络模型
和传统的神经网络语言模型有所不同:先将x映射为词向量,连接双层BiLSTM作为隐藏层,再连接一个Softmax来预测下一个词是什么。在Keras中,实现BiLSTM非常容易。因为`CuDNNLSTM`的实现比`LSTM`要快很多,推荐安装cudnn来使用这个函数。加入了一些`Dropout`层来避免过拟合。
Python
# Model inp = Input(shape=(window - 1,)) x = Embedding(nb_words, 300, trainable = True, weights=[embedding_matrix])(inp) x = Bidirectional(CuDNNLSTM(128, return_sequences=True))(x) x = Dropout(0.1)(x) x = Bidirectional(CuDNNLSTM(128, return_sequences=False))(x) x = Dropout(0.1)(x) x = Dense(128, activation="relu")(x) x = Dropout(0.1)(x) x = Dense(nb_words, activation="softmax")(x) model = Model(inputs=inp, outputs=x) opt = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) model.compile(loss=’categorical_crossentropy’, optimizer=opt, metrics=[’accuracy’]) history = LossHistory() epoch_nb = 80 # 40 is enough batch = 64 model.fit(x_train, y_train, batch_size=batch, epochs=epoch_nb, verbose=1, validation_data=(x_test, y_test), callbacks=[history])
随机生成句子
用`predict_random_sentence`函数来生成随机句子,其中的`reverse_index`保存了从语料库生成的词典中的词和序号的一一对应。若将[0,0,0,0]更改为其他数字,即可生成给定开头的句子。
Python
def predict_random_sentence(new=[0] * (window - 1)): sentence = reverse_index[new[0]] + reverse_index[new[1]] + reverse_index[new[2]] + reverse_index[new[3]] while new[-1] != end_index: prob = model.predict(np.asarray([new]))[0] new_predict = int(random.choices(word_ind, weights=prob)[0]) sentence += reverse_index[new_predict] new = new[1:] + [new_predict] return sentence predict_random_sentence([0,0,0,0])
保存模型
保存模型到本地,以后就可以直接调用,避免重复训练。上文中提到的tokenizer和神经网络模型都需要保存。
Python
with open("../result/tokenizer.pkl", "wb") as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
model.save(’../model/language_model.model’)
效果展示
我们训练了80个epoch,使用了20000句话进行训练,选择的窗宽为5。以下是从日文语言模型中随机生成的一些句子。
’「なんだろう。僕が仕事を休みになり、でもまあ……見てた」’’アグライアはグラスをじっと見つめた。’’それにしても、それを使って、ジークをから表情になって猫のように《さ》がを受けた。’’森そうだ、そんなことか」’’真剣で命をように、そのの人は、辻宮氏はだいたい邸にてあげた《と?》みをうとした。「そんな顔だって今?」’’佳澄ちゃんが……俺とさっきに言わせて下さい。’’沙耶「まあ、沙耶ねえ先に戻ることにになってきます?」’’「最近はどうしてそういうつもりじゃないでしょうね」’
简单的翻译一下生成的句子(日语水平比较烂,可能翻译错了)
’怎么说呢。我虽然下班了,但还是……看到了’
’Agria凝视着玻璃杯’
’即使如此,使用它,Sieg看来像猫一样的表情接受了さ’
’像树林啊,是这样吗’
这句话实在不太通顺……
’佳澄酱,请给我说下刚才的事情’
’沙耶:“嘛,沙耶先回去了啊?”’
’最近为什么不打算这样做了呢’
总体来说,该语言模型可以生成出一些通顺的话语。以上都是从空句子开始生成的,也可以改变生成句子的开头。
项目地址及参考文献
完整的项目代码见
[GitHub]
(https://github.com/GanjinZero/DeepLearningPlayground/tree/master/code/Language%20Model)
[Language_model]
(https://en.wikipedia.org/wiki/Language_model)
[MeCab]
(http://taku910.github.io/mecab/)
[fastText]
(https://github.com/facebookresearch/fastText/blob/master/docs/crawl-vectors.md)
【作者简介】

GjZero,清华大学统计中心博士二年级在读。研究方向是医学信息学中的自然语言处理。兴趣是扑克、麻将等和博弈论有关的运动。
编辑:王菁
校对:林亦霖
— 完 —
关注清华-青岛数据科学研究院官方微信公众平台“THU数据派”及姊妹号“数据派THU”获取更多讲座福利及优质内容。