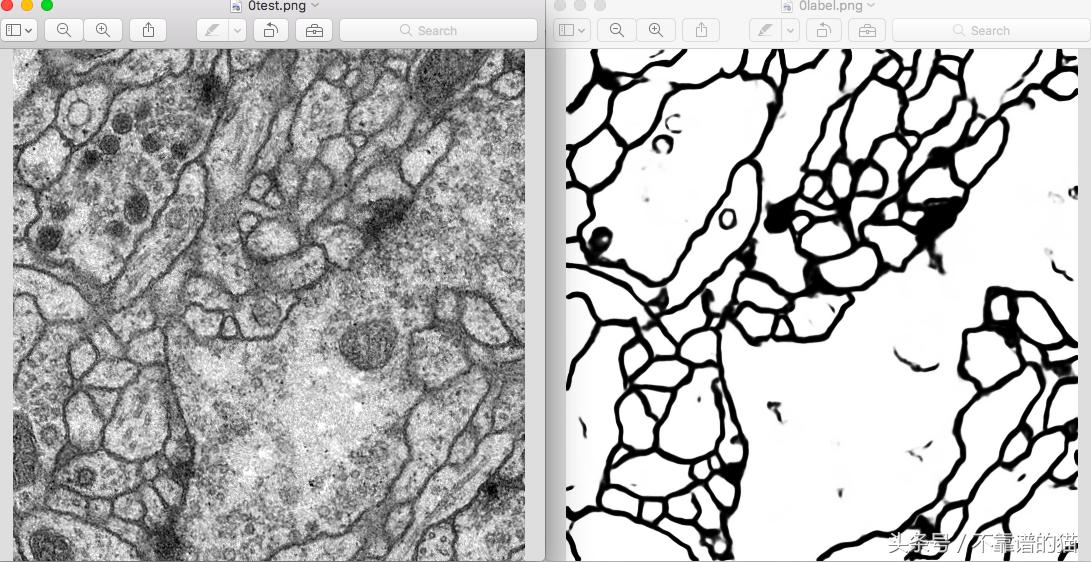
图1:测试图像及其标签(语义分段输出)
为了在一个小型的生物医学数据集上执行语义分割,我果断地尝试使用Keras来揭开U-Net工作的神秘面纱。虽然我的主要重点是对实现进行详细说明,但我也试图包含与理解相关的细节。我的大部分参考文献包括zhixuhao的unet知识库Github和Olaf Ronneberger等人的论文“U-Net:用于生物医学图像分割的卷积网络”。
关于U-Net
U-net体系结构是编码-解码器架构的同义词。它本质上是一个基于FCNs的深度学习框架;它包括两部分:
- 一种类似编码器的收缩路径,通过一个紧凑的特性映射来捕获上下文。
- 一种与解码器类似的对称扩展路径,允许精确定位。这一步是为了保留边界信息(空间信息),尽管在编码器阶段执行下采样和最大池。
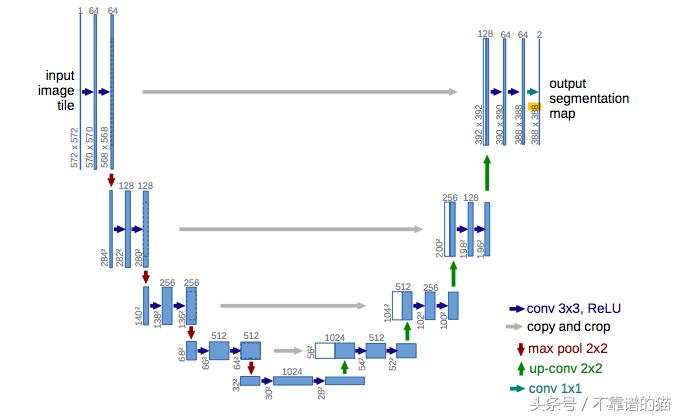
图2:U-Net的体系结构
使用U-Net的优点
- 计算效率
- 可以用一个小的数据集进行训练
- 训练有素的端到端
- 更好的为生物医学应用
语义分割和本地化到底是什么?简单地说,它们是指像素级标签,即图像中的每个像素都有一个类标签。你可以得到分割图,如图1所示。在此之前,生物医学研究人员采用了两种方法:
- 将图像分类为整体(恶性或良性)。
- 将图像分割成小块(patches )并进行分类。
由于增加了数据集的大小,小块(patches )当然比整个图像分类要好,但是,也有一些与相同的缺陷。更小的跨步或有大量重叠的小块(patches )都是,计算密集型的,并导致冗余(重复)信息。其次,上下文信息和本地化之间的良好权衡是至关重要的。小的小块(patches )会丢失上下文信息,而大的小块(patches )会篡改本地化结果。最后,不重叠的小块(patches )会导致上下文信息的丢失。基于先前的观察,编码器解码器架构在union (IoU)值上产生的交集要比向CNN提供每个像素进行分类要高得多。
准备数据集
让我们深入准备您的数据集!
- 将原始数据集和相应的注释划分为两组,即训练和测试(更准确地说,是验证)集。原始图像是RGB格式,而掩码是二进制的(黑白)。
- 将所有图像数据转换为.tif。
- 您将不需要图像类标签或测试集的注释(这不是一个分类问题)。
注意:应该选择图像的大小,这样连续的conv和max-pooling会在每个阶段产生均匀的x和y值(即feature map的宽度和高度)。虽然我的图像是360X360像素,但我将它们的大小调整为256X256。裁剪边界以获得适当的图像大小。裁剪并转换为.tif的Python代码如下:
#Fit the data into a 256*256 format and save it as a .tif file
#@Sukriti Paul
from PIL import Image
from skimage import data, io, filters
import numpy as np
from scipy import ndimage
from matplotlib import pyplot as plt
from sklearn import manifold, datasets
n=10 #number of images
for i in range (1,n+1):
path=str(i)+'.png'
img= io.imread('/Users/sukritipaul/Desktop/D004/test_annotate/'+path)
#Subsection of the image
img=img[52:308,52:308]
print img.shape
path=str(i)+'.tif'
io.imsave('/Users/sukritipaul/Desktop/D004/AlteredDims/tiff_form_test_annotate/'+path,img)
先决条件
- Tensorflow
- Keras > = 1.0
- libtiff(可选)
- OpenCV 3
此外,该代码应该与Python版本2.7-3.5兼容。
训练和数据增强
如果需要,可以旋转、反射和扭曲图像。zhixuhao使用了一个变形方法。仔细遵循以下几个步骤;错过一个步骤会让你发疯好几个小时!为了简单起见,我将培训阶段分为A部分和B部分。
Part A-修改data.py
1、克隆zhixuhao’s的存储库。
$ git clone https://github.com/zhixuhao/unet
2、进入位于训练文件夹内的图像文件夹(../unet/data/train/image)。
3、包括图像文件夹中的训练图像。每个图像都应该是.tif格式,连续命名,从0.tif开始,1.tif ...等等。
4、进入训练文件夹内的标签文件夹(../unet/data/train/label)。包含相应的训练图像注释。每个图像都应该是.tif格式,连续命名,从0.tif开始,1.tif ...等等。标签必须与训练图像集相对应。
5.输入数据文件夹内的测试文件夹(../unet/data/test)。
6. 在数据文件夹(../unet/data/npydata)中创建一个名为npydata的文件夹。让它保持空虚; 已处理的数据集将随后保存在此文件中,作为3 .npy文件。
7.打开unet文件夹中的data.py文件(../unet/data.py)。步骤8,9,10和11指的是您必须在此文件中对RGB图像进行的更改。粗体区域对应于我所做的更改。
8.修改def create_train_data(self),如下所示。
def create_train_data(self):
...
imgdatas = np.ndarray((len(imgs),self.out_rows,self.out_cols,3), dtype=np.uint8)
imglabels = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8)
...
img = load_img(self.data_path + "/" + midname) #Removed grayscale
label = load_img(self.label_path + "/" + midname,grayscale = True)
#Correspond to lines 159-164
9.修改def create_test_data(self),如下所示。
def create_test_data(self):
…
imgdatas = np.ndarray((len(imgs),self.out_rows,self.out_cols,3), dtype=np.uint8)
…
img = load_img(self.test_path + "/" + midname) #Removed grayscale
#Correspond to lines 188 and 191
10.将图像更改为您的训练集的大小。
def doAugmentate(self,img,save_to_dir,save_prefix,batch_size = 1,save_format ='tif',imgnum = 26):#我已经考虑过26个训练图像
11.通过提供正确的路径详细信息修改类dataProcess(object)中的以下内容。我将data_path,label_path,test_path和npy_path更改为正确的路径(对应于我系统中的目录)。您可以尝试在第138行data.py中编辑它们。请看它到npydata文件夹的路径没有错(这是一个常见的错误)。
def __init__(self, out_rows, out_cols, data_path = "/Users/sukritipaul/Dev/newcvtestpy2/unet2/data/train/image", label_path = "/Users/sukritipaul/Dev/newcvtestpy2/unet2/data/train/label", test_path = "/Users/sukritipaul/Dev/newcvtestpy2/unet2/data/test", npy_path = "/Users/sukritipaul/Dev/newcvtestpy2/unet2/data/npydata", img_type = "tif"):
#Corresponds to line 138
12.Run data.py
$python data.py
Part A- 验证
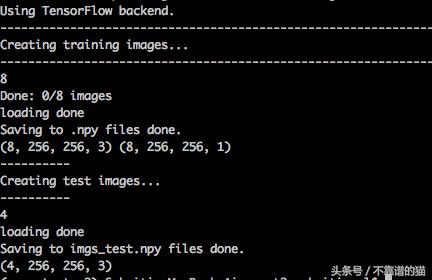
图3:运行data.py时获得的输出
您的输出应该与图3中的输出相匹配。如果您的终端显示' Done:0 / images',那么您的文件并未包含在.npy文件中。检查/ unet / data / npydata中是否包含以下文件:
- imgs_mask_train.npy
- imgs_test.npy
- imgs_train.npy
Wohooo!你完成了数据准备工作:)

Fig4: Result on the ISBI cell tracking challenge-
Part B-修改unet.py
1.在unet文件夹(../ unet / results)中创建一个结果文件夹。如果你在思考为什么你创造了这个,你就会知道为什么,在一瞬间!
2.打开unet.py(../unet/unet.py)
3.编辑以下行中的行数和列数。我的图片尺寸为256X256。
def __init__(self, img_rows = 256, img_cols = 256):
#Corresponds to line 13
4、如以下所示,在get_unet(self)中修改以下3信道输入。
def get_unet(self):
inputs = Input((self.img_rows, self.img_cols,3))
#Corresponds to line 27
5、在train(self)中修改以下行
def train(self):
...
np.save('/Users/sukritipaul/Dev/newcvtestpy2/unet2/results/imgs_mask_test.npy', imgs_mask_test)
...
#Note that the address to the results directory must be provided
##Corresponds to line 164
6.修改def save_img(self),记住结果目录的地址,如步骤4中所指定的那样
def save_img(self):
imgs = np.load('/Users/sukritipaul/Dev/newcvtestpy2/unet2/results/imgs_mask_test.npy') # Use the same address as above
img.save("/Users/sukritipaul/Dev/newcvtestpy2/unet2/results/%d.jpg"%(i)) #Saves the resulting segmented maps in /results
##Corresponds to lines 169 and 173
7.运行unet.py并等待几分钟(根据数据集大小和系统硬件,您的训练时间可能需要几个小时)。
$ python unet.py
Part B-验证
访问/unet/results and viola! !您可以在灰度中找到生成的图像遮罩或分割后的特征映射:)
总之,在65幅训练图像和10幅大小为256X256的验证图像中,我获得了90.71%的总体准确率。