我们在逛超市时一定发现过两种商品*绑捆**销售的情况,这可能是因为商家想要促销其中的某种商品。比如我们现在想要促销一种比较冷门的商品——芥末(mustard),可以通过将apriori()函数的关联结果(rhs)参数设置为“mustard”,来搜索出rhs中仅包含mustard的关联规则,从而有效地找到mustard的强关联商品,来作为*绑捆**商品。分析代码如下:
>library(arules)
>data("Groceries")
>#仅生成关联结果中含有“芥末”的关联规则
>rules4 <- apriori(Groceries, parameter = list(maxlen=2, supp=0.001,conf=0.1),appearance = list(rhs="mustard",default="lhs"))
>#输出关联规则
> inspect(rules4)
lhs rhs support confidence lift
[1] {mayonnaise} => {mustard} 0.001423488 0.1555556 12.96516
输出结果显示蛋黄酱(mayonnaise)是芥末(mustard)的强关联商品,因此我们可以考虑将它们*绑捆**起来摆放在货架上,并制定一个合适的共同购买价格,从而对两种商品同时产生促销效果。另外,我们还用到了参数maxlen,这里将其设置为2,控制lhs中仅包含一种食品,这是因为在实际的情形中,我们一般仅将两种商品进行*绑捆**,而不是一堆商品。
改变输出结果形式
apriori()和eclat()函数都可以根据需要输出频繁项集(frequent itemsets)等其他形式结果。比如当我们想知道某超市这个月销量最高的商品,或者*绑捆**销售策略在哪些商品簇中作用最明显等,选择输出给定条件下的频繁项集即可。
如下即是就将目标参数设为“frequent itemsets”后的结果。
>#将目标参数设置为“频繁项集”
> itemsets_apr <- apriori(Groceries, parameter = list(supp=0.001,target="frequent itemsets"),control = list(sort=-1))
>#显示所生成频繁项集的个数
> itemsets_apr
set of 13492 itemsets
>#观测前5个频繁项集
> inspect(itemsets_apr[1:5])
items support
[1] {whole milk} 0.2555160
[2] {other vegetables} 0.1934926
[3] {rolls/buns} 0.1839349
[4] {soda} 0.1743772
[5] {yogurt} 0.1395018
如上结果,我们看到以sort参数对项集频率进行降序排序后,销量前5的商品分别为全脂牛奶、蔬菜、面包卷、苏打以及酸奶。
以下我们使用eclat()函数来获取最适合进行*绑捆**销售,或者说相近摆放的5对商品。比如,下面的输出结果中的全脂牛奶和蜂蜜,以及全脂牛奶与苏打水作为共同出现最为频繁的两种商品,则可以考虑采取相邻摆放等营销策略。
>#按照频繁程度排序,输出项数为2的项集
>itemsets_ecl <- eclat(Groceries,parameter = list(minlen=1,maxlen=3,supp=0.001,target="frequent itemsets"),control=list(sort=-1))
>#显示所生成的频繁项集个数
> itemsets_ecl
set of 9969 itemsets
>#观测前5个频繁项集
> inspect(itemsets_ecl[1:5])
items support
[1] {whole milk,honey} 0.001118454
[2] {whole milk,cocoa drinks} 0.001321810
[3] {whole milk,pudding powder} 0.001321810
[4] {tidbits,rolls/buns} 0.001220132
[5] {tidbits,soda} 0.001016777
在itemsets的生成代码中,我们并没有对confidence值进行设置,这里并非选择了取默认值,而是因为频繁项集的产生仅与支持度阈值有关。我们可以尝试改动参数confidence的值,输出结果将不受影响。
关联规则的可视化
我们可以尝试用图形的方式更直观地显示出关联分析结果,这里需要用到arulesViz包。例如:
>library(arules)
>library(arulesViz)
>data("Groceries")
>rules5 <- apriori(Groceries, parameter = list(support=0.002,confidence=0.5))
>rules5
set of 1098 rules
>plot(rules5)

图中的每个点对应于相应的支持度和置信度值,分别由图形的横纵轴显示,且其中关联规则点的颜色深浅由lift值的高低决定。另外也可以通过更改参数设置,来变换横纵轴及颜色条所对应的变量,如:
>plot(rules5, measure=c("support","lift"), shading="confidence")。
从图中可以看出大量规则的参数取值的分布情况,如提升度较高的关联规则的支持度往往较低,支持度与置信度具有明显反相关性等。但不足之处在于,并不能具体得知这些规则对应的是哪些商品,以及它们的关联强度如何等信息。而这一缺陷可通过互动参数(interactive)的设置来弥补。
>plot(rules5, interactive=TRUE)

在这幅互动互动散点图中,我们可以在图上通过两次单击圈定感兴趣的若干个点,在有十字形标示的阴影区中有两个关联规则点被选定,然后单击“inspect”按钮接可以获取选定点的详细信息。
当单击“filter”过滤按钮后,再单击图形右侧lift颜色条中的某处,即可将小于但基础lift值的关联规则点都过滤掉。
另外我们还可以将shading参数设置为“order”来绘制出一种特殊的散点图——Two-key图。例如:
> plot(rules5,shading = "order",control = list(main="Two key plot"))
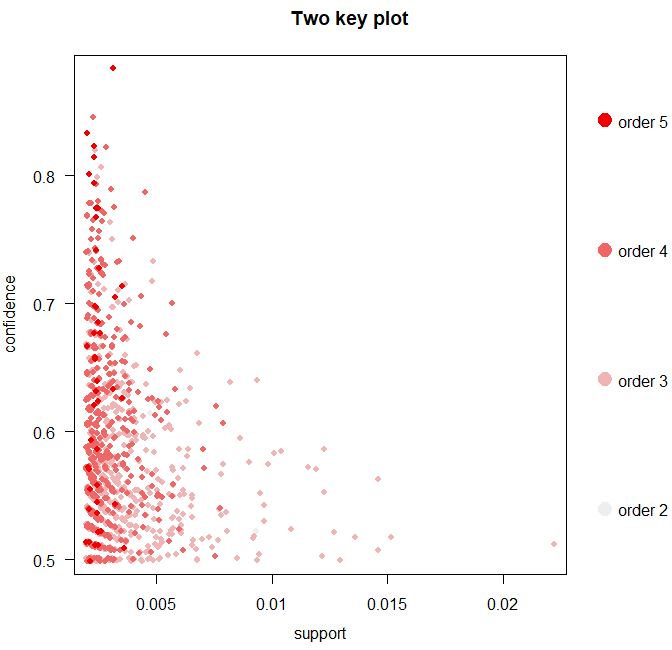
上图中,横纵轴依然为支持度和置信度,而关联规则点的颜色深浅则表示其所代表的关联规则中含有商品的多少,商品种类越多,点的颜色越深。
下面我们将图形类型更改为“grouped”制作分组图,代码如下:
>plot(rules5, method="grouped")
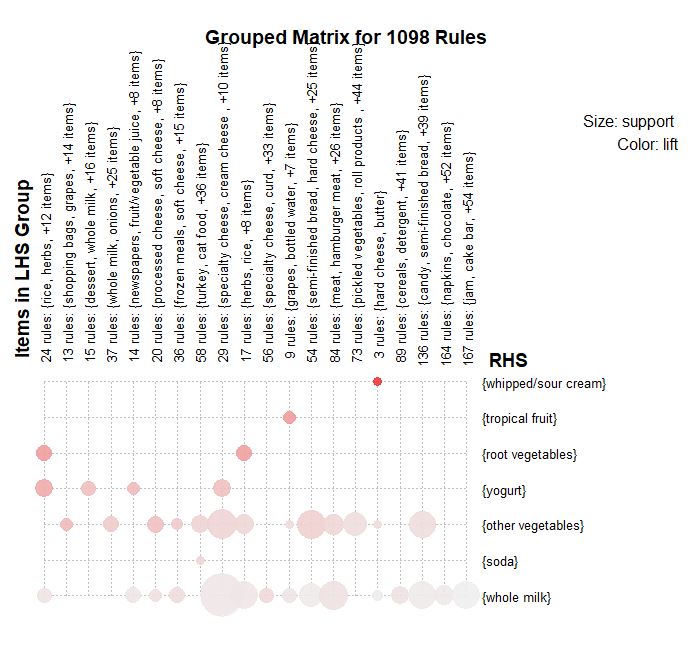
上图中,从list参数来看,关联性最强(圆点颜色最深)的两种商品为黄油(butter)和生/酸奶油(whipped/sour cream);而以support参数来看则是热带水果(tropical fruit)与全脂牛奶(whole milk)关联性最强(圆点尺寸最大)。
关于method参数,还可以更改设置为“matrix”、"matrix3D"、“paracoord”等来生成其他图形类型,例如:
>plot(rules5[1:50], method="matrix", measure="lift")
>plot(rules5[1:50], method="matrix3D", measure="lift")
>plot(rules5[1:50], method="paracoord")