不知不觉今年的520就过去了,祝没有脱单的小伙伴抓紧发挥你的独特的魅力,明年520之前脱单。恭喜已经脱单的朋友,祝你们幸福!
今年520为了给女友买礼物可也算是煞费苦心了,当然买礼物还不如帮她清空购物车来得直接一些。不知道各位小伙伴今年买了什么礼物啊。
除了重要的节日需要网上购买之外,平时她也是需要买日常的衣物,今天就来获取淘宝网的所有文胸数据,供她挑选,当然最后结账的也是你。
本次文章的字数可能会比之前多一些,我也是争取每一次爬取的技术都会提高一些,这样大家阅读起来也会轻松一些,不至于看不懂。今天的文章大概需要10分钟左右的时间才可以看完,希望各位小伙伴可以耐心一点。
随着时间的推移,文章难度需要提升,现在每篇文章都需要花两到3天的时间才可以完成,又要录制视频教程,所以会比之前更新的慢一些,希望小伙伴们可以理解。
在爬取信息之前需要先介绍一下,Python的一个自动化测试工具selenium,这个是本次的重点内容。如果熟悉selenium的小伙伴可以直接略过。
1.selenium简介
selenium是一个用于测试网站的自动化测试工具,支持很多主流的浏览器,比如:谷歌浏览器、火狐浏览器、IE、Safari等。
2.支持多个操作系统
如windows、Linux、IOS、Android等。
3、安装selenium
pip install Selenium
4、安装浏览器驱动
1、Chrome驱动文件*载下**:
https://chromedriver.storage.googleapis.com/index.html?path=2.35/
2、火狐浏览器驱动*载下**:
https://github.com/mozilla/geckodriver/releases/tag/v0.26.0
5、配置环境变量
配置环境变量的方法非常简单,首先将*载下**好的驱动进行解压,放到你安装Python的目录下,即可。
因为之前,在配置Python环境变量的时候,就将Python的目录放到我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path
Python安装路径
二、selenium快速入门
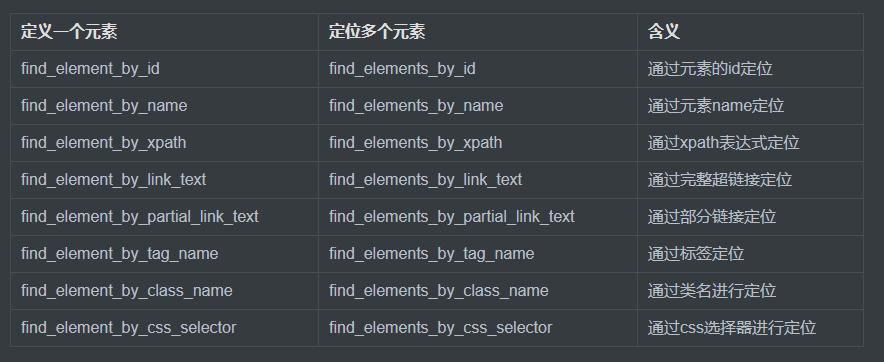
1、selenium提供8种定位方式
1、id
2、name
3、class name
4、tag name
5、link text
6、partial link text
7、xpath
8、css selector
2、定位元素的8种方式详解
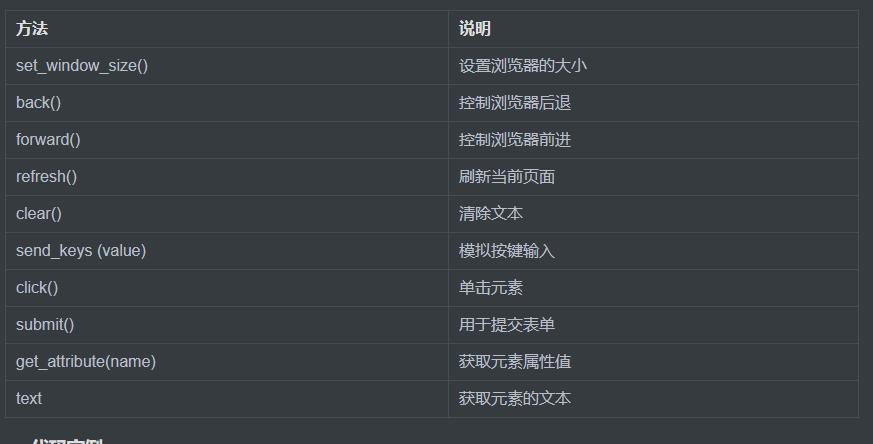
3、selenium库下webdriver模块常用的方法与使用
控制浏览器的一些方法
4、代码实例

from selenium import webdriverimport time# 创建Chrome浏览器对象,这会在电脑中打开一个窗口browser = webdriver.Chrome()# 通过浏览器向服务器发起请求browser.get('https://www.baidu.com')time.sleep(3)# 刷新浏览器browser.refresh()# 最大化浏览器窗口browser.maximize_window()# 设置链接内容element = browser.find_element_by_link_text('抗击肺炎')# 点击'抗击肺炎'element.click()关于selenium的简单介绍就先到这里了,更多详细内容大家可以去selenium官方文档查看。
关于selenium的简单介绍就先到这里了,更多详细内容大家可以去selenium官方文档查看。
爬取数据
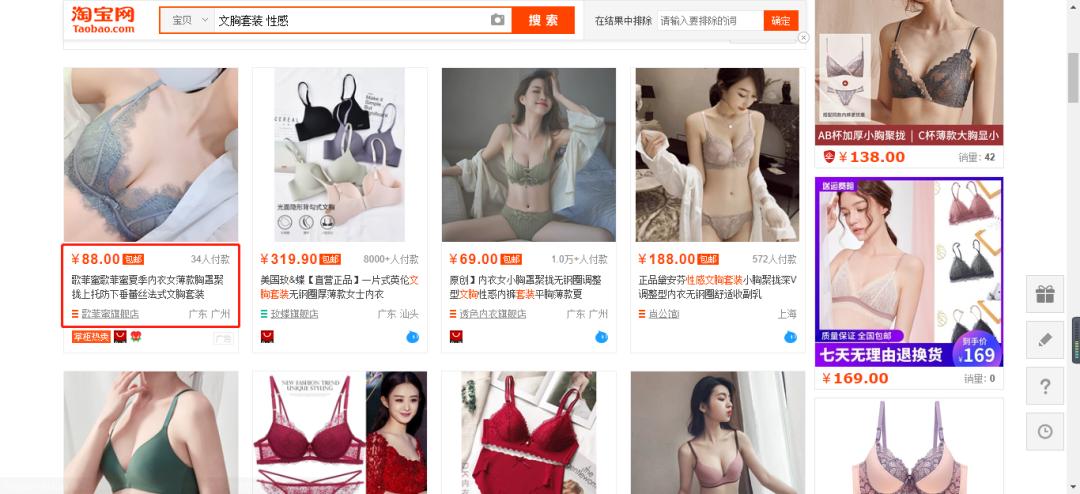
从上图,可以看到需要获取的信息是:价格、商品名称、付款人数、店铺名称。
现在我们开始进入主题。
首先,需要输入你要搜索商品的内容,然后根据内容去搜索淘宝信息,最后提取信息并保存。
1、搜素商品
我在这里定义一个搜索商品的函数和一个主函数。
搜索商品
在这里需要创建一个浏览器对象,并且根据该对象的get方法来发送请求。
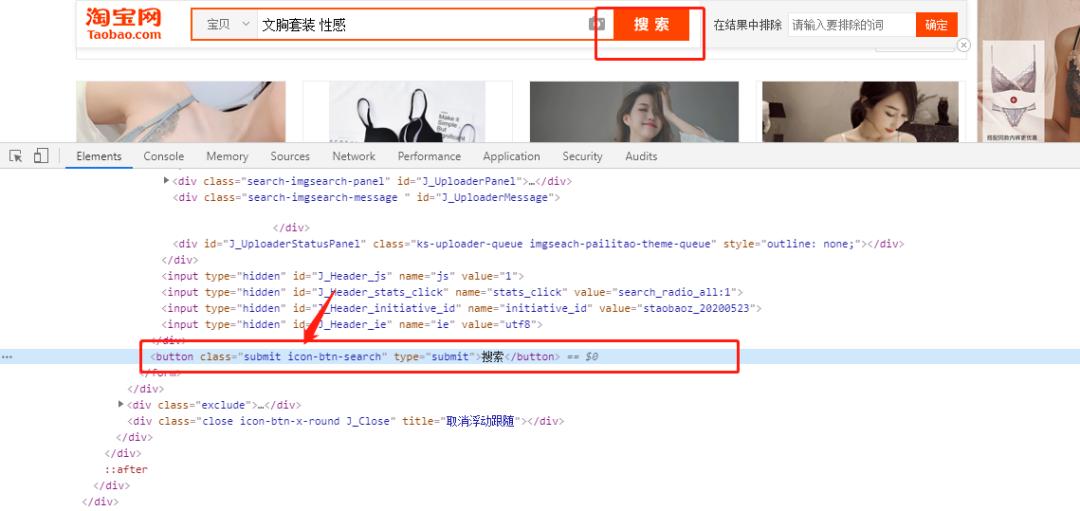
从上图可以发现搜索框的id值为q,那么这样就简单很多了,有HTML基础的朋友肯定知道id值是唯一的。
通过id值可以获取到文本框的位置,并传入参数,然后点击搜索按钮。
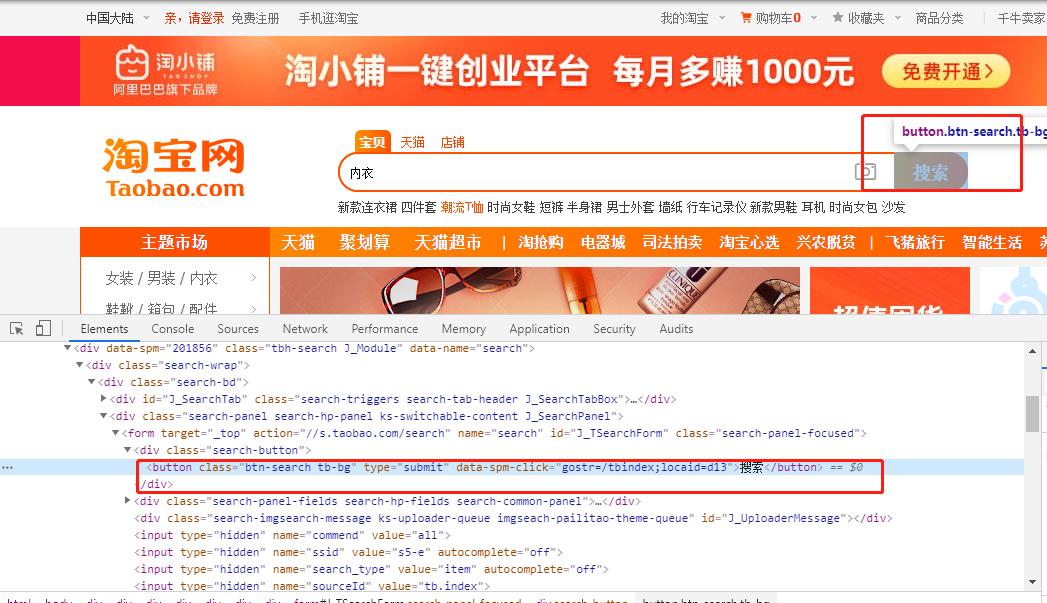
从上图可以发现搜索按钮在一个类里面,那么可以通过这个类来定位到搜索按钮,并执行点击操作。
当点击搜索按钮之后,网页便会跳转到登录界面,要求我们登录,如下图所示:
登录成功后会发现,里面的数据总共有100页面。

上图是前三页的url地址,你会发现其实并没有太大的变化,经过测试发现,真正有效的参数是框起来的内容,它的变化会导致页面的跳转,很明显第一页的s=0,第二页s=44,第三页s=88,以此类推,之后就可以轻松做到翻页了。
搜搜商品的代码如下:

代码如下框
def search_product(key_word): ''' :param key_word: 搜索关键字 :return: ''' # 通过id值来获取文本框的位置,并传入关键字 browser.find_element_by_id('q').send_keys(key_word) # 通过class来获取到搜索按钮的位置,并点击 browser.find_element_by_class_name('btn-search').click() # 最大化窗口 browser.maximize_window() time.sleep(15) page = browser.find_element_by_xpath('//div[@class="total"]').text # 共 100 页, page = re.findall('(\d+)', page)[0] # findall返回一个列表 return page
2、获取商品信息并保存
获取商品信息相对比较简单,可以通过xpath方式来获取数据。在这里我就不再论述。在这边我创建了一个函数get_product来获取并保存信息。在保存信息的过程中使用到了csv模块,目的是将信息保存到csv里面。
代码如下:
def get_product(): divs = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')# 这里返回的是列表,注意:elements for div in divs: info = div.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text price = div.find_element_by_xpath('.//strong').text + '元' nums = div.find_element_by_xpath('.//div[@class="deal-cnt"]').text names = div.find_element_by_xpath('.//div[@class="shop"]/a').text print(info, price, nums, names,sep='|') with open('data3.csv', mode='a', newline='', encoding='utf-8') as file: csv_writer = csv.writer(file, delimiter=',') # 指定分隔符为逗号 csv_writer.writerow([info, price, nums, names])
3、构造URL实现翻页爬取
从上面的图片中可以发现连续三页URL的地址,其实真正变化并不是很多,经过测试发现,只有q和s两个参数是有用的。
构造出的url:https://s.taobao.com/search?q={}&s={}
因为q是你要搜索的商品,s是设置翻页的参数。这段代码就放在了主函数里面
代码如下:
def main(): browser.get('https://www.taobao.com/') # 向服务器发送请求 page = search_product(key_word) print('正在爬取第1页的数据') get_product() # 已经获得第1页的数据 page_nums = 1 while page_nums != page: print('*'*100) print('正在爬取第{}页的数据'.format(page_nums+1)) browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_nums*44)) browser.implicitly_wait(10) # 等待10秒 get_product() page_nums += 1
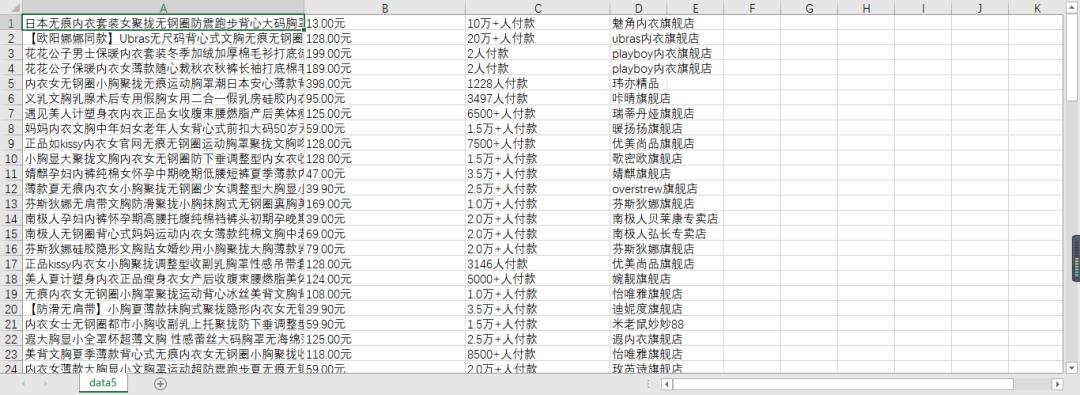
最后结果,如下图所示:
—— E N D ——
好了,又到了该说再见的时候了,希望我的文章可以给你带来知识,带给你帮助。同时也感谢你可以抽出你宝贵的时间来阅读,创作不易,如果你喜欢的话,点个关注再走吧。更多精彩内容会在后续更新,你的支持就是我创作的动力,我今后也会尽力给大家书写出更加优质的文章。