导读
有些时候我们需要构建一个自己的数据集来训练模型。但是,却苦于没有大量的数据,此时就需要去谷歌、百度、必应搜索引擎上去爬取一些图片作为自己的数据集。
很自然的,我们就会想到写一个爬虫的程序去爬取图片,然后就开始学习scrapy、Beautiful Soup、Selenium,除此之外还需要学习一些HTML和JS来解析网页获取我们想要的数据。这样看起来,好像点复杂。毕竟我们只是想爬取点图片,为什么要搞的如此复杂。
icrawler就可以帮我们轻松解决这些问题,不需要去学习其他的库了,甚至连解析网页这样的工作也不需要我们做。
icrawer
官网教程:https://icrawler.readthedocs.io/en/latest/
icrawler是一个mini的web爬虫框架,按照模块化的设计标准,我们能够很容易的去使用和继承它,支持图片、视频以及文本等信息的爬取。相对于功能强大的scrapy来说,icrawer要轻便小很多。icrawler也提供了很好的多线程、异常处理和线程调度的支持,提供了抓取搜索引擎网站(谷歌、百度、必应)上的图片的内置方法。
环境要求
python版本:2.7+或3.4+
安装方法
- pip安装
pip install icrawler
- conda安装
conda install -c hellock icrawler
爬取搜索引擎上的图片
我们将通过示例来介绍,如何通过icrawler从百度上抓取图片,对于从必应和谷歌上抓取图片的方式类似,就不重复介绍了。
- icrawler结构设计
- crawler主要由三个部分组成,Feeder、Parser、Downloader,每一个都连接一个FIFO队列。
- url_queue存储可能包含图片网页的url地址,task_queue存储媒体数据(图片、视频、文本)的url地址,task_queue队列中的每个元素都是一个字典,每个字典必须包含img_url属性。
- Feeder将网页的url地址放到url_queue中,Parser解析网页将媒体数据的url放到task_queue中,Downloder从task_queue中获取媒体数据的url*载下**并保存到本地。
- 从百度爬取图片
from icrawler.builtin import BaiduImageCrawler
#设置图片保存目录
save_img_dir = r"D:\dataset\icrawler_dataset"
#定义一个图片的Crawler对象
baidu_crawler = BaiduImageCrawler(storage={"root_dir":save_img_dir})
#设置搜索的关键词和从百度上爬取图片的数量
baidu_crawler.crawl(keyword="二哈",max_num=10)
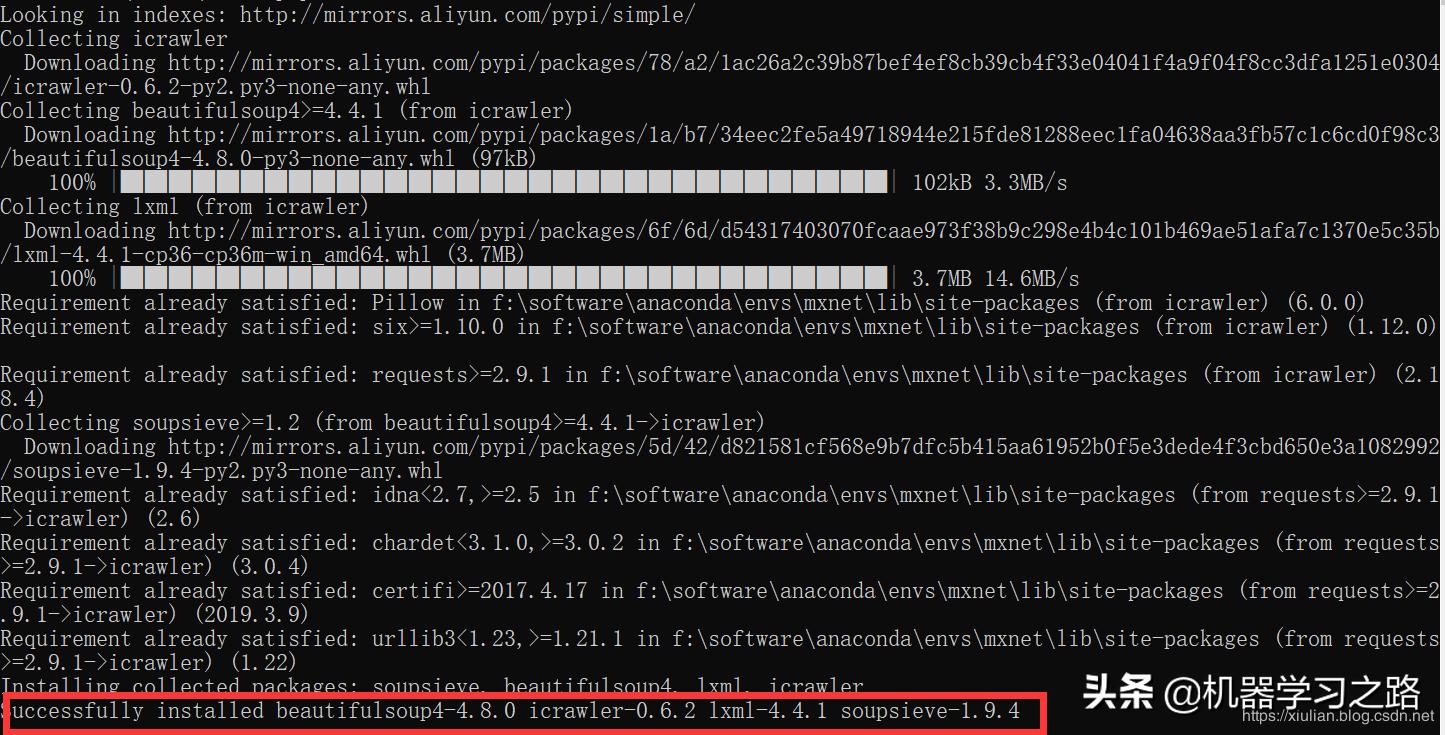
在从搜索引擎上爬取图片的过程中会从控制台输出一些信息
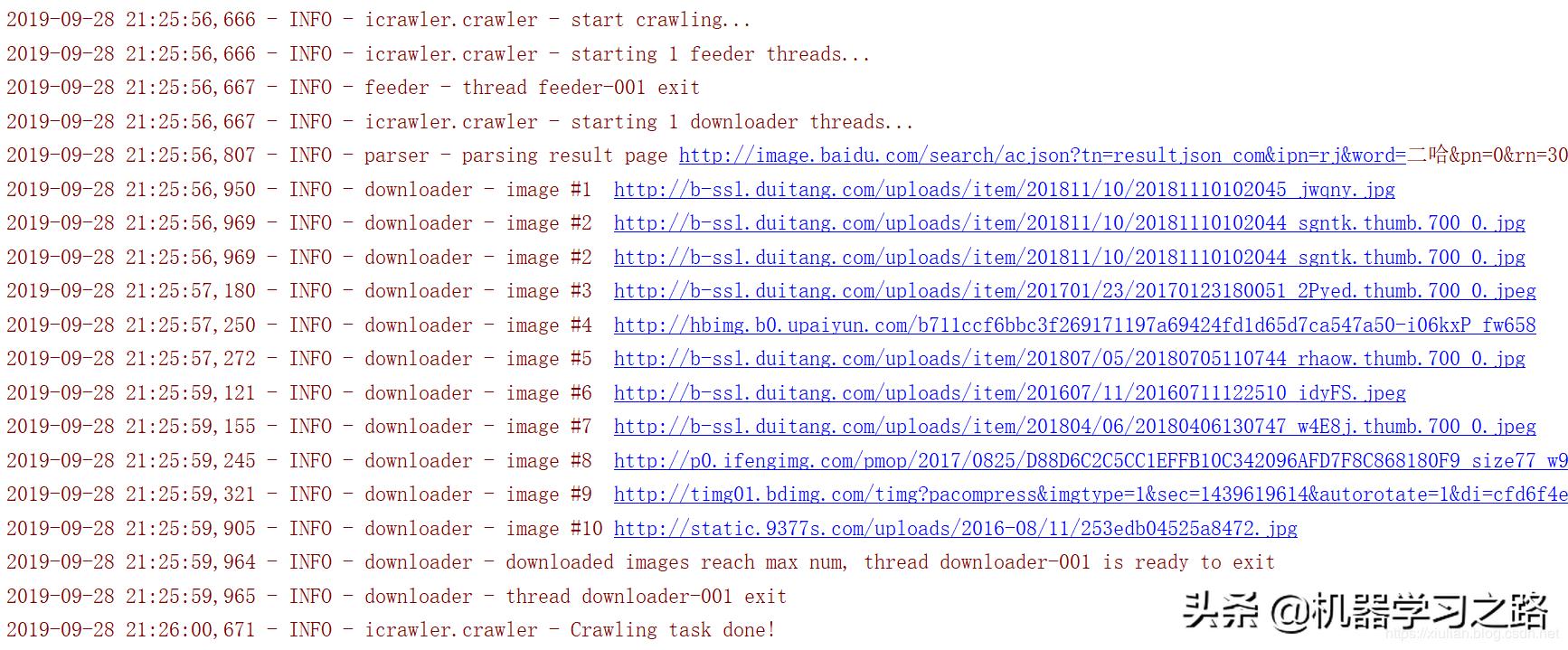
从百度爬取到的图片

有些图片肯定是不符合要求的,后续大家可以根据自己的要求做一下后处理工作,将部分图片剔除。
爬取图片参数设置
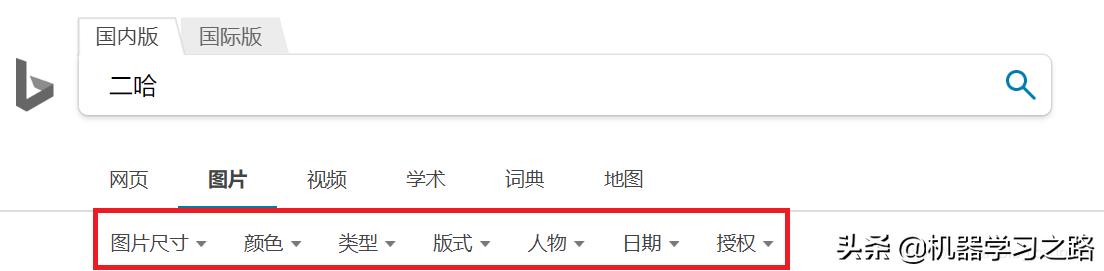
在*载下**图片的时候,我们可以设置参数来过滤一些图片,还可以设置线程数来加快*载下**速度

不同的搜索引擎能够设置的参数会有一些差别,在调用crawl方法的时候我们可以设置filters参数设置*载下**图片的过滤条件,如上图红色方框中的参数。

GoogleImageCrawler:
- type:*载下**图片的类型,photo、face、clipart、linedrawing、animated
- color:颜色设置,blackandwhite、 transparent、red、 orange、yellow、green、teal、blue、 purple、 pink、 white、 gray、 black、 brown.
- size:*载下**图片大小设置,large、medium、icon
- license:使用权限,noncommercial、commercial、noncommercial,modify、commercial,modify
- date:图片上传时间,pastday、pastweek.也可以使用一个元组来设置,例如((2018,1,1),(2019,10,1))或((2018,1,1),None)
BingImageCrawler:
- type:同上
- color:同上
- size:同上
- license:同上
- layout:版式,square、wide、tall
- people:人物、face、portrait
- date:同上
BaiduImageCrawler
- type:同上
- color:同上
from icrawler.builtin import BaiduImageCrawler
#设置图片保存目录
save_img_dir = r"D:\dataset\icrawler_dataset"
#定义一个图片的Crawler对象
baidu_crawler = BaiduImageCrawler(
feeder_threads=1,#设置获取网页链接的线程数
parser_threads=1,#设置解析网页的线程数
downloader_threads=5,#设置*载下**图片的线程数
storage={"root_dir":save_img_dir}
)
#设置参数
filters_config = dict(
type="animated",#*载下**动图
color="orange"
)
#设置搜索的关键词和从百度上爬取图片的数量
baidu_crawler.crawl(keyword="二哈",filters=filters_config,offset=0,max_num=10)
代理设置
如果需要爬取Google或者一些海外网站的数据,需要设置代理,icrawler提供了两种不同代理的设置方式,BaiduImageCrawler类继承了Crawler类,如果想要设置代理我们只需要重新set_proxy_pool方法
- 代理小于30个
def set_proxy_pool(self): self.proxy_pool = ProxyPool() self.proxy_pool.default_scan(region='overseas', expected_num=10, out_file='proxies.json')
上面的程序会自动扫描10个有效代理,然后去请求网页*载下**图片数据
- 自定义扫描代理需求
我们可以根据自己对于代理扫描的需求来自定义代理扫描函数
def set_proxy_pool(self):
proxy_scanner = ProxyScanner()
proxy_scanner.register_func(proxy_scanner.scan_file,
{'src_file': 'proxy_overseas.json'})
proxy_scanner.register_func(your_own_scan_func,
{'arg1': '', 'arg2': ''})
self.proxy_pool.scan(proxy_scanner, expected_num=10, out_file='proxies.json')
每次请求会从proxy_pool中获取一个代理然后发起请求,每个代理都会有一个proxy_weight参数,proxy_weight参数的取值范围在0到1之间,扫描程序会根据成功和失败的次数来增加或减少proxy_weight的大小,proxy_weight值越大,被选中的机会越大。
自定义Crawler
我们可以根据BaiduImageCrawler的结构来自定义一个类,爬取网站的数据,官网有详细介绍,这里就不说明了。