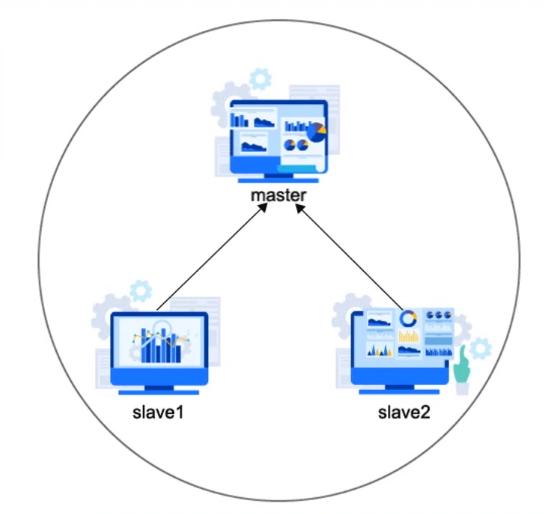
集群框架
三台主机节点(入门级别)
角色:
主节点 master
从节点save1、 slave2
配置 hosts文件
通过 ifconfig命令进行查看机器的p地址
将三个节点的地址以及其对应的名称写进hosts文件。这里我们设置为 master、 slave1、 slave2.注意保存退出。
关闭防火墙
关闭防火墙:systemctl stop firewall
查看状态:systemctl status firewall
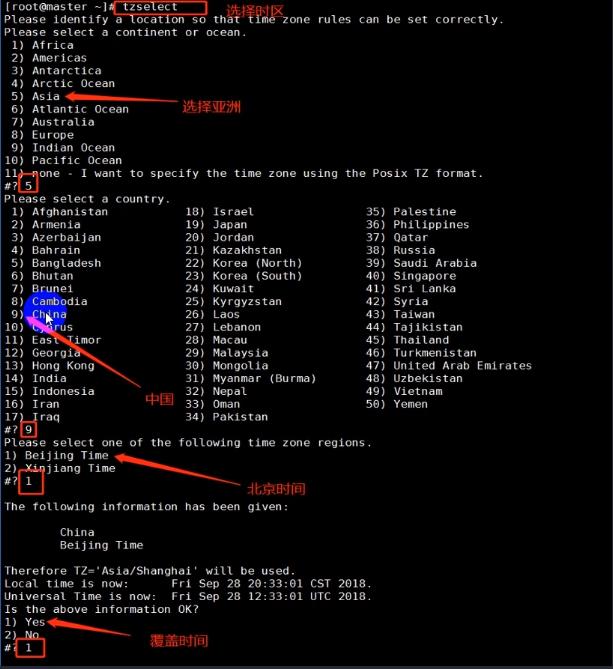
时间同步,选择时区:tzselect
master作为ntp服务器
vim /etc/ntp. conf
server 127.127.1.0
fudge 127. 127 1.0 stratum 10
重启ntp服务 master上执行
/bin/systemc/ restart ntpd.service
其他机器进行同步(在save1, slave2中执行)
ntpdate master
制作定时任务
确保 crontab服务开启
service crond status
/sbin/service crond start
·从节点( slave1、save2)在早十-晚五时间段每隔半个小时同步一次时间
crontab -e
添加定时任务:
*/30 10-17 * * */usr/sbin/ ntpdate master
查看定任务列装:crontab -l (区分字母l,和数字1,在这里是字母l)
建立ssh互信
hadoop需要通过ss互信来启动 slave里表中各个主机的守护迸程。
必须要建立ssh互信(即无密码登陆)?
解析:并不是必须的,如果不配置,每次启动 hadoop,都需要输入密码以便登录到每台机器的 Datanode上而一般的 hadoop集群动辄数百或数干台机器,因此一般来说都会配置SSh互信。
生成密钥
ssh-keygen-t dsa -P -f "" ~/.ssh/id_dsa.pub
添加至授权文件:
cat /id_dsa.pub >> authorized_keys
复制到 slaves1中的节点
scp authorized_keys root@slave:/.ssh/
检查是否成功:ssh slave1(在 master主机输入)
登陆成功则配置成功,输入exit,退出save1返回 master
安装JDK
Hadoop是用ava开发的, Hadoop的编译及 mapreduce的运行都需要使用JDK,所以JDK是必须安装的。
创建工作目录:
mkdir -p/ usr/java
*载下**软件
wget http://xxxx/jdk-8u221-linux-x64.tar.gz
解压
tar -zxvf jdk-8u221-linux-X64.tar.gz -C /usr/java/
环境变量:/etc/ profile
在 master中将JDK复制到 Slave1和 slave2中:
scp-r /usr/java root@slave1 /usr/
scp -r /usr/java root@slave2 /usr/