References on Optimal Control, Reinforcement Learning and Motion Planning
by Edouard Leurent
Github项目地址:
https://github.com/eleurent/phd-bibliography
注:带有“video”字样的链接请用科学上网访问
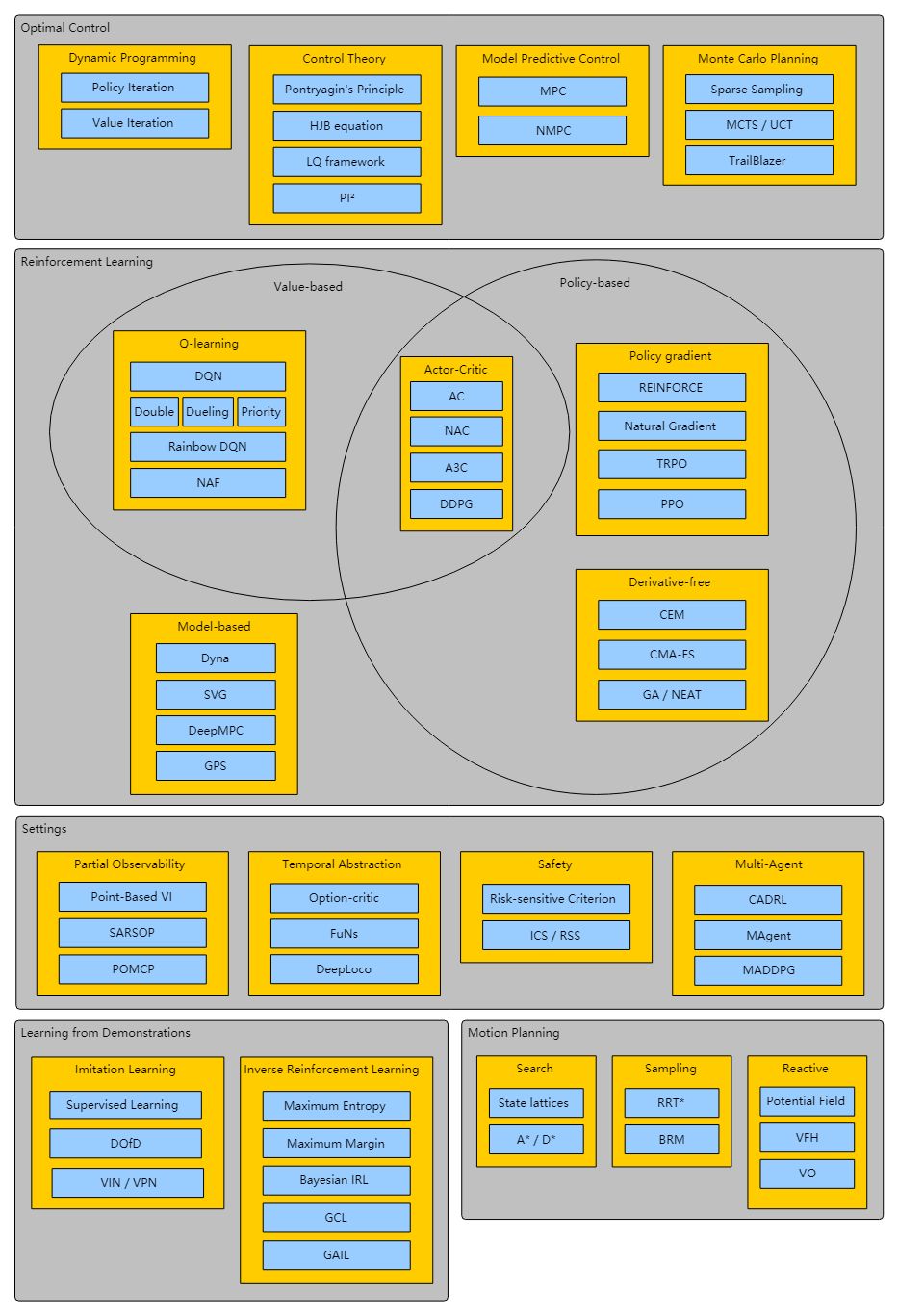
最优控制
动态编程
-
(book) Dynamic Programming, Bellman R. (1957).
-
(book) Dynamic Programming and Optimal Control, Volumes 1 and 2, Bertsekas D. (1995).
-
(book) Markov Decision Processes - Discrete Stochastic Dynamic Programming, Puterman M. (1995).
近似规划
-
ExpectiMinimax Optimal strategy in games with chance nodes, Melkó E., Nagy B. (2007).
-
Sparse sampling A sparse sampling algorithm for near-optimal planning in large Markov decision processes, Kearns M. et al. (2002).
-
MCTS Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search, Rémi Coulom, SequeL (2006).
-
UCT Bandit based Monte-Carlo Planning, Kocsis L., Szepesvári C. (2006).
-
Bandit Algorithms for Tree Search, Coquelin P-A., Munos R. (2007).
-
OPD Optimistic Planning for Deterministic Systems, Hren J., Munos R. (2008).
-
OLOP Open Loop Optimistic Planning, Bubeck S., Munos R. (2010).
-
LGP Logic-Geometric Programming: An Optimization-Based Approach to Combined Task and Motion Planning, Toussaint M. (2015). video️
-
AlphaGo Mastering the game of Go with deep neural networks and tree search, Silver D. et al. (2016).
-
AlphaGo Zero Mastering the game of Go without human knowledge, Silver D. et al. (2017).
-
AlphaZero Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, Silver D. et al. (2017).
-
TrailBlazer Blazing the trails before beating the path: Sample-efficient Monte-Carlo planning, Grill J. B., Valko M., Munos R. (2017).
-
MCTSnets Learning to search with MCTSnets, Guez A. et al. (2018).
-
ADI Solving the Rubik's Cube Without Human Knowledge, McAleer S. et al. (2018).
-
OPC/SOPC Continuous-action planning for discounted infinite-horizon nonlinear optimal control with Lipschitz values, Busoniu L., Pall E., Munos R. (2018).
控制理论
-
(book) Constrained Control and Estimation, Goodwin G. (2005).
-
PI² A Generalized Path Integral Control Approach to Reinforcement Learning, Theodorou E. et al. (2010).
-
PI²-CMA Path Integral Policy Improvement with Covariance Matrix Adaptation, Stulp F., Sigaud O. (2010).
-
iLQG A generalized iterative LQG method for locally-optimal feedback control of constrained nonlinear stochastic systems, Todorov E. (2005).
-
iLQG+ Synthesis and stabilization of complex behaviors through online trajectory optimization, Tassa Y. (2012).
模型预测控制
-
(book) Model Predictive Control, Camacho E. (1995).
-
(book) Predictive Control With Constraints, Maciejowski J. M. (2002).
-
Linear Model Predictive Control for Lane Keeping and Obstacle Avoidance on Low Curvature Roads, Turri V. et al. (2013).
-
MPCC Optimization-based autonomous racing of 1:43 scale RC cars, Liniger A. et al. (2014). Video 1 | Video 2
-
MIQP Optimal trajectory planning for autonomous driving integrating logical constraints: An MIQP perspective, Qian X., Altché F., Bender P., Stiller C. de La Fortelle A. (2016).
安全控制
鲁棒控制
-
Minimax analysis of stochastic problems, Shapiro A., Kleywegt A. (2002).
-
Robust DP Robust Dynamic Programming, Iyengar G. (2005).
-
Robust Planning and Optimization, Laumanns M. (2011). (lecture notes)
-
Robust Markov Decision Processes, Wiesemann W., Kuhn D., Rustem B. (2012).
-
Coarse-Id On the Sample Complexity of the Linear Quadratic Regulator, Dean S., Mania H., Matni N., Recht B., Tu S. (2017).
-
Tube-MPPI Robust Sampling Based Model Predictive Control with Sparse Objective Information, Williams G. et al. (2018). Video
风险规避控制
-
A Comprehensive Survey on Safe Reinforcement Learning, García J., Fernández F. (2015).
-
RA-QMDP Risk-averse Behavior Planning for Autonomous Driving under Uncertainty, Naghshvar M. et al. (2018).
约束控制
-
ICS Will the Driver Seat Ever Be Empty, Fraichard T. (2014).
-
RSS On a Formal Model of Safe and Scalable Self-driving Cars, Shalev-Shwartz S. et al. (2017).
-
HJI-reachability Safe learning for control: Combining disturbance estimation, reachability analysis and reinforcement learning with systematic exploration, Heidenreich C. (2017).
-
BFTQ A Fitted-Q Algorithm for Budgeted MDPs, Carrara N. et al. (2018).
-
MPC-HJI On Infusing Reachability-Based Safety Assurance within Probabilistic Planning Frameworks for Human-Robot Vehicle Interactions, Leung K. et al. (2018).
不确定动力系统
-
Simulation of Controlled Uncertain Nonlinear Systems, Tibken B., Hofer E. (1995).
-
Trajectory computation of dynamic uncertain systems, Adrot O., Flaus J-M. (2002).
-
Simulation of Uncertain Dynamic Systems Described By Interval Models: a Survey, Puig V. et al. (2005).
-
Design of interval observers for uncertain dynamical systems, Efimov D., Raïssi T. (2016).
顺序学习
Multi-Armed Bandit
-
UCB1/UCB2 Finite-time Analysis of the Multiarmed Bandit Problem, Auer P., Cesa-Bianchi N., Fischer P. (2002).
-
GP-UCB Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design, Srinivas N., Krause A., Kakade S., Seeger M. (2009).
-
kl-UCB The KL-UCB Algorithm for Bounded Stochastic Bandits and Beyond, Garivier A., Cappé O. (2011).
-
KL-UCB Kullback-Leibler Upper Confidence Bounds for Optimal Sequential Allocation, Cappé O. et al. (2013).
-
LUCB PAC Subset Selection in Stochastic Multi-armed Bandits, Kalyanakrishnan S. et al. (2012).
-
POO Black-box optimization of noisy functions with unknown smoothness, Grill J-B., Valko M., Munos R. (2015).
-
Track-and-Stop Optimal Best Arm Identification with Fixed Confidence, Garivier A., Kaufmann E. (2016).
-
M-LUCB/M-Racing Maximin Action Identification: A New Bandit Framework for Games, Garivier A., Kaufmann E., Koolen W. (2016).
-
LUCB-micro Structured Best Arm Identification with Fixed Confidence, Huang R. et al. (2017).
-
Bayesian Optimization in AlphaGo, Chen Y. et al. (2018)
强化学习
-
Reinforcement learning: A survey, Kaelbling L. et al. (1996).
基于价值的强化学习
-
NFQ Neural fitted Q iteration - First experiences with a data efficient neural Reinforcement Learning method, Riedmiller M. (2005).
-
DQN Playing Atari with Deep Reinforcement Learning, Mnih V. et al. (2013). Video
-
DDQN Deep Reinforcement Learning with Double Q-learning, van Hasselt H., Silver D. et al. (2015).
-
DDDQN Dueling Network Architectures for Deep Reinforcement Learning, Wang Z. et al. (2015). Video
-
PDDDQN Prioritized Experience Replay, Schaul T. et al. (2015).
-
NAF Continuous Deep Q-Learning with Model-based Acceleration, Gu S. et al. (2016).
-
Rainbow Rainbow: Combining Improvements in Deep Reinforcement Learning, Hessel M. et al. (2017).
-
Ape-X DQfD Observe and Look Further: Achieving Consistent Performance on Atari, Pohlen T. et al. (2018). Video
基于策略的强化学习
策略梯度
-
REINFORCE Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning, Williams R. (1992).
-
Natural Gradient A Natural Policy Gradient, Kakade S. (2002).
-
Policy Gradient Methods for Robotics, Peters J., Schaal S. (2006).
-
TRPO Trust Region Policy Optimization, Schulman J. et al. (2015). video️
-
PPO Proximal Policy Optimization Algorithms, Schulman J. et al. (2017). video️
-
DPPO Emergence of Locomotion Behaviours in Rich Environments, Heess N. et al. (2017). video️
评价器
-
AC Policy Gradient Methods for Reinforcement Learning with Function Approximation, Sutton R. et al. (1999).
-
NAC Natural Actor-Critic, Peters J. et al. (2005).
-
DPG Deterministic Policy Gradient Algorithms, Silver D. et al. (2014).
-
DDPG Continuous Control With Deep Reinforcement Learning, Lillicrap T. et al. (2015). video️ 1 | 2 | 3 | 4
-
MACE Terrain-Adaptive Locomotion Skills Using Deep Reinforcement Learning, Peng X., Berseth G., van de Panne M. (2016). video1️ | video2️
-
A3C Asynchronous Methods for Deep Reinforcement Learning, Mnih V. et al 2016. video️ 1 | 2 | 3
-
SAC Soft Actor-Critic : Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja T. et al. (2018). video️
无导数
-
CEM Learning Tetris Using the Noisy Cross-Entropy Method, Szita I., Lörincz A. (2006). video️
-
CMAES Completely Derandomized Self-Adaptation in Evolution Strategies, Hansen N., Ostermeier A. (2001).
-
NEAT Evolving Neural Networks through Augmenting Topologies, Stanley K. (2002). video️
基于模型的强化学习
-
Dyna Integrated Architectures for Learning, Planning, and Reacting Based on Approximating Dynamic Programming, Sutton R. (1990).
-
UCRL2 Near-optimal Regret Bounds for Reinforcement Learning, Jaksch T. (2010).
-
PILCO PILCO: A Model-Based and Data-Efficient Approach to Policy Search, Deisenroth M., Rasmussen C. (2011). (talk)
-
DBN Probabilistic MDP-behavior planning for cars, Brechtel S. et al. (2011).
-
GPS End-to-End Training of Deep Visuomotor Policies, Levine S. et al. (2015). video️
-
DeepMPC DeepMPC: Learning Deep Latent Features for Model Predictive Control, Lenz I. et al. (2015). video️
-
SVG Learning Continuous Control Policies by Stochastic Value Gradients, Heess N. et al. (2015). video️
-
Optimal control with learned local models: Application to dexterous manipulation, Kumar V. et al. (2016). video️
-
BPTT Long-term Planning by Short-term Prediction, Shalev-Shwartz S. et al. (2016). video️ 1 | 2
-
Deep visual foresight for planning robot motion, Finn C., Levine S. (2016). video️
-
VIN Value Iteration Networks, Tamar A. et al (2016). video️
-
VPN Value Prediction Network, Oh J. et al. (2017).
-
An LSTM Network for Highway Trajectory Prediction, Altché F., de La Fortelle A. (2017).
-
DistGBP Model-Based Planning with Discrete and Continuous Actions, Henaff M. et al. (2017). video️ 1 | 2
-
Prediction and Control with Temporal Segment Models, Mishra N. et al. (2017).
-
Predictron The Predictron: End-To-End Learning and Planning, Silver D. et al. (2017). video️
-
MPPI Information Theoretic MPC for Model-Based Reinforcement Learning, Williams G. et al. (2017). video️
-
Learning Real-World Robot Policies by Dreaming, Piergiovanni A. et al. (2018).
-
PlaNet Learning Latent Dynamics for Planning from Pixels, Hafner et al. (2018). video️