图神经网络的预训练是解决图机器学习任务中标签数据稀疏的潜在方法之一。目前主流的图神经网络预训练可以分为基于图生成和对比学习的方法。该两种方法都是基于自监督学习的思想从无标签的图数据中构造预训练的监督信号,这也是图神经网络预训练的研究重点。
前言
近年来,图神经网络(GNN) [1]对基于图结构数据的机器学习任务产生了深刻的影响,如节点分类、链接预测以及图分类等[2,3]。该方向的早期研究重点是把神经网络应用到非欧氏空间的图结构数据上,并完成相关任务。随着图卷积网络(GCN)[3]的诞生及其在半监督节点分类任务上的出色表现,不同架构的图神经网络不断涌现,比如图注意力神经网络(GAT) [4]。鉴于其强大的表达能力,图神经网络被广泛应用到其他领域,如推荐系统[5]、量子化学[6]、生物医疗[7]以及知识问答和认知推理)[8]。与此同时,越来越多的研究开始关注图神经网络的泛化能力和理论基础)[9]。
尽管图神经网络在过去几年取得了巨大的成功,但如同大多数有监督或半监督机器学习模型一样,为了学习到强大的表达能力,它需要大量的标签数据定义并优化学习目标。大规模标签数据,尤其是基于图结构的标签数据通常很难获取,而且不同数据的标注需要对应的专业领域知识。类似地,自然语言处理和计算机视觉等领域也面临同样的问题,其主要解决方案是在文本或图像数据上设计自监督的学习任务,从无标签的数据中通过预训练得到相应的机器学习模型(一般为神经网络模型),比如著名的BERT[10]、Deep InfoMax (DIM)[11]、Contrastive Predictive Coding(CPC)[12]、Momentum Contrast(MoCo)[13]等模型。受此启发,我们是否也可以通过在无标注的图结构数据上进行自监督学习来预训练图神经网络呢?
本文将对图神经网络的预训练进行介绍和探讨。
图神经网络
图神经网络的输入通常是一个带节点或连边属性的图结构,即包括该图的邻接矩阵A和对应的属性信息X。其最终输出一般取决于具体的任务,比如节点分类输出节点的标签,图分类输出图的标签,链接预测输出链接存在与否。以节点分类为例,图神经网络根据图结构和输入节点属性训练图中每个节点的隐式向量表示,其目标是让该向量表示包含足够强大的表达信息,使其能够帮助每个节点进行分类。
图神经网络模型学习的主要过程是通过迭代对邻居信息进行聚合和更新[1,6]。在一次迭代中,每一个节点通过聚合邻居节点的特征及自己在上一层的特征来更新自己的信息,通常也会对聚合后的信息进行非线性变换。通过堆叠多层网络,每个节点可以获取到相应跳数内的邻居节点信息。经典的图卷积网络[3]、图注意力神经网络[4]、GraphSage[2]等模型都遵循此过程。在图卷积网络模型中,每一节点对一跳邻居节点和自己当前的特征进行平均化聚合;图注意力神经网络模型进一步通过引入注意力机制对收集到的邻居信息进行加权平均聚合;GraphSage则提出多种方式对邻居信息进行有效聚合。
自监督学习与预训练
大多数情况下,我们很难获得大量标签数据,所以有监督的机器学习方法很难施展其强大的学习能力。而我们可以相对容易地获取海量的原始无标注数据,比如互联网上的文本、图像、关系型或结构化数据。那么,是否可以从大规模无标注数据中创造伪标签作为监督信号?比如以部分输入数据预测剩余部分的数据?这就是无监督学习的主要思想[14,15]。从高层面来看,输入数据是完全无标注的,所以属于无监督学习的范畴;但具体到模型的学习过程,其利用了部分输入数据构造监督信号,对模型进行有监督学习,从而有效地学习到数据中的潜在特征和信息。经典的语言模型、自编码器等生成模型,都属于自监督学习的范畴。以BERT掩码语言模型为例,对于输入的无标记信息的句子,通过随机掩盖15%的单词作为监督信号来训练底层的模型。
由于自监督学习直接作用于无标签数据,通常情况下得到的模型为通用的预训练模型。当需要解决具体的下游任务时,我们可以直接使用预训练模型来进行微调,从而避免为每一个下游任务从零开始训练全新的模型。由于预训练模型可以从大规模无标签数据中学习到数据中的通用规律,其在自然语言处理[10,16]、视觉[11,13]、语音[12]等领域取得了广泛的成功。
从广义上来讲,DeepWalk[17]、node2vec[18]、metapath2vec [19]和基于自编码器的无监督图表示学习方法也属于自监督学习的范畴,它们学习得到的节点向量表示(即预训练模型的参数),一般在下游任务中保持不变,并直接作为特征为下游任务做贡献。该类自监督模型并不会产生一个预训练的模型,因此很难为下游任务的新模型进行初始化和微调。因此,本文重点探讨如何根据自监督学习预训练图神经网络模型,使其能够对下游任务的具体新模型进行初始化和微调。
图神经网络的预训练
从方*论法**的角度,目前主流的自监督学习方法可以分为基于生成式的和基于对比学习的两大主要类别[14]。基于生成式的自监督学习方法通过让模型对输入数据进行生成重建学习到数据的潜在特征;基于对比学习的方法则主要是从输入数据中构造出正负样本,让模型在隐式表示空间对正负样本进行判别[15]。这两种思路是通过不同方式从无标记的输入数据中构建预训练任务,即监督信号。
基于生成模型的预训练
生成模型旨在将观测数据生成概率最大化,该思想与自监督学习的目标天然吻合,即把输入数据本身作为模型的监督信号。生成式自监督学习已经在自然语言处理领域取得了巨大的成功,例如以BERT和GPT[16]系列为代表的预训练语言模型,已经在10多个不同自然语言理解任务上取得了里程碑式的成果。我们是否可以借鉴该思想,将其用于图神经网络的自监督学习任务呢?
受BERT启发,文献[20]提出了基于生成式的图神经网络预训练框架(Generative Pre-Training of Graph Neural Networks,GPT-GNN)。其预训练的主要思路是通过将输入图数据的生成概率最大化,来产生模型训练的自监督信号。鉴于输入图数据一般包括图结构A和节点属性信息X,因此,GPT-GNN将预训练任务对应地分为结构生成和属性生成两个子任务。与此同时,GPT-GNN采用自回归的方式对图的生成概率进行建模,即对输入网络的所有节点随机(或根据数据中的时间信息)预定义一个顺序,在该顺序下依次进行节点连边及其属性的生成。在每轮(epoch)训练过程中,采用不同的节点顺序进行自回归式的生成建模。此外,为了给图神经网络的预训练提供有效的自监督信号,GPT-GNN并没有忽略网络结构与节点属性之间的依赖关系,即利用结构信息生成节点属性,反之亦然。
具体来说,对于一个带节点属性的输入图,GPT-GNN首先对网络中的所有节点进行随机排序,如图1(a)所示;然后,将其随机遮盖的节点的连边和属性作为模型生成的目标,如图1(b)所示;对每个遮盖的节点,比如节点3,其目标是根据观测到的数据分别生成它的属性和连边。为防止信息泄露,目标节点3的属性和结构被分别抽象为两个虚拟节点——属性生成节点和连边生成节点。为生成节点3的属性节点,模型根据前序节点1和2的所有信息及观测到的节点3的部分连边进行预测。预测到的节点3的属性节点则进一步用来生成它的其他连边结构,即其连边节点。节点3的属性和连边生成过程如图1(c)所示。模型会根据节点的标记顺序来对剩余节点4和5分别进行属性生成和结构生成,如图1(d,e)。至此,GPT-GNN完成了对输入图数据在当前节点排序下的一次生成过程。在此过程中,节点属性预测和连边预测扮演了图神经网络的预训练任务角色。
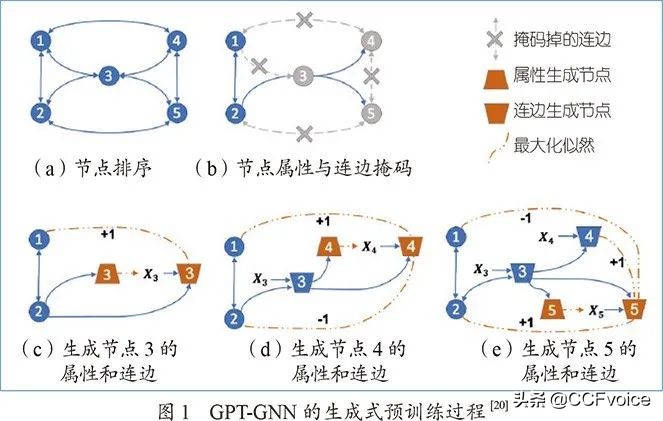
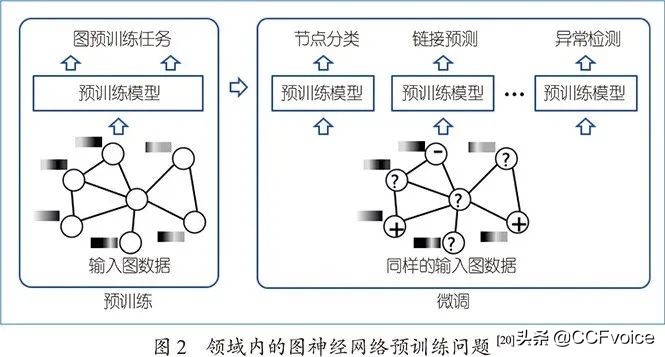
GPT-GNN尝试解决领域内的图神经网络预训练问题(如图2所示),即预训练和下游任务使用相同分布的图数据。通过生成式自监督学习,从所关心的图数据中预训练得到通用的图神经网络,然后对同一数据上的不同下游任务分别进行模型微调。GPT-GNN作者通过对亿级规模网络进行预训练得到的图神经网络,可以显著提升多个下游任务的性能。GPT-GNN预训练后的模型在仅使用10%~20%标记数据的情况下,比相同架构且使用全部(100%)标签数据的未预训练模型取得的结果更好。该发现对解决大规模图挖掘应用中标签数据稀疏的现实挑战提供了可行性思路。
文献[22]为了对化学分子图进行图神经网络预训练,同样提出了以节点属性掩码预测作为自监督学习的一个任务,该任务也是基于BERT思想的生成式预训练思路。此外,该工作还提出了基于对比学习的图结构上下文预测的预训练任务。
基于对比学习的预训练
基于对比学习的自监督学习模型在图像和基于序列的数据结构上取得了很大的成功,主要代表模型包括DIM、CPC和MoCo。该思路主要是从输入数据中构造出不同的样本,通过引导预训练模型在隐式表示空间对正负样本进行判别来学习输入数据中的特征。受此启发,基于对比学习的图神经网络预训练任务和模型也被相继提出,如基于DIM的Deep Graph Infomax(DGI) [23]和基于MoCo的Graph Contrastive Coding(GCC)[21]。
受DIM启发,文献[23]提出了基于互信息的图神经网络自监督学习框架DGI。基于随机游走定义的目标函数过度强调节点之间的近邻相似度,忽略了节点在整个图中的全局结构信息。而DGI基于互信息的核心思想是衡量节点的局部表示与其所属图的全局表示之间的相似关系,这样便可以跳出近邻相似度的约束,让节点向量表示同时捕获到全局图的信息。
DGI预训练框架包括编码器、readout函数和损失函数,关键点在于基于图结构的正负例设计。编码器可以采用任意一种图神经网络,为每个节点学习一个表示。Readout函数可以设计为将所有节点的表示平均并经过一个激活函数,以获取图级别的表示。损失函数接收一个节点和一个图结构,根据该节点的局部向量表示与该图的整体向量表示,判断该节点是否属于该图。由DIM可知,两个变量的联合分布和两个变量边缘分布乘积之间的Jensen-Shannon(JS)散度越高,两个变量之间的互信息就越大,也就是这两个变量的关联性越强。DGI使用一个判别器通过噪声对比估计,以二分类交叉熵为损失,通过优化损失让判别器正确区分正负例,来增大JS散度,从而达到增大局部节点表示和全局图表示互信息的作用。而增大互信息使得每个局部节点表示能够保存整个图的信息,即能够探索和保存不同节点之间的相似性,例如能学得两个不相邻却有着相似结构的节点之间的相似性。
DGI中图数据的正负例定义及具体的对比学习过程如图3所示:首先,构造原始输入空间的正负例。正例图是模型的输入图数据,即图的邻接矩阵A和节点属性信息X;负例图则是通过对A和X进行随机变换构造而得到,即
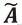
和
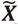
。构造完成后,它们分别通过图神经网络编码器得到对应的隐空间节点表示H和
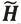
。然后通过readout函数把正例图的节点表示H变换成正例图在隐空间的整图表示
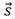
。DGI的预训练核心是它的自监督信号,是在隐空间将正例图中每一节点的节点表示
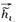
与其整图表示
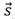
的互信息最大化,同时将负例图每一节点的节点表示
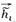
与正例图整体
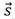
表示的互信息最小化。
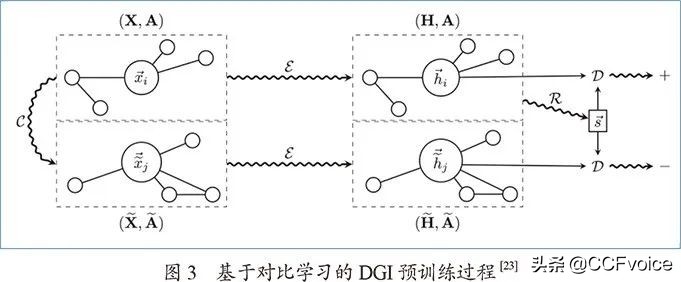
通过对隐空间上的正负局部节点表示与真实全局图表示之间的互信息对比作为自监督学习任务,DGI能够同时捕捉局部和全局信息的图神经网络。与GPT-GNN一样,DGI也专注于领域内的图神经网络预训练问题。实验结果表明,DGI的预训练框架能够让图神经网络从无标签数据中学习到比有监督的相同模型相似或更好的节点表示,极好地验证了图神经网络预训练的可行性和发展空间。
InfoGraph[24]在DGI的基础上做了两点改进,一是InfoGraph中节点的向量表示是将图神经网络编码器不同层的表示拼接在一起得到的,使得其包含不同规模的子图信息;二是损失函数中使用的是JS互信息估计器(MI estimator)。为了避免负迁移效果,InfoGraph使用了两个编码器,一个学习监督数据,另一个根据无监督数据将图和节点表示之间的互信息最大化,与此同时,也将这两个编码器每一层得到的图表示之间的互信息最大化。
接下来,我们探讨如何预训练具有领域迁移能力的图神经网络。
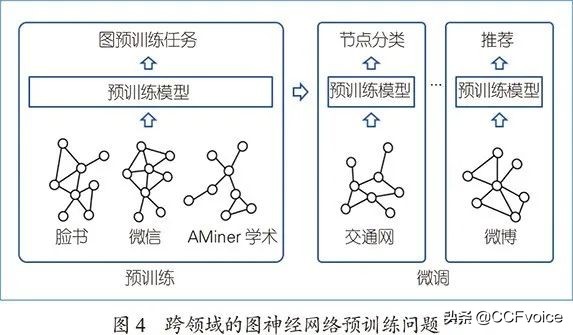
文献[21]提出了可以从多领域图数据中对图神经网络进行预训练的框架GCC,其目标是通过自监督学习的方式,让图神经网络从不同图数据中捕捉到它们遵循的潜在普适规律,从而赋予其对未知领域图数据进行表示学习的能力。以GCC的具体实验为例,在预训练阶段,通过对社交网络、学术合作网、电影合作网、在线博客网等6个图数据进行图神经网络的自监督学习;在微调阶段,预训练得到的模型被应用到航空交通网、在线论坛网等多个不同领域的图数据上解决相应的下游任务,如图4所示。
GCC预训练的主要思路也是通过从无标注的输入图数据中构造正负例来进行对比学习,以此作为自监督信号。如何从多个图数据中构造正例和负例呢?如图5所示,GCC首先以任意节点为起点进行随机游走,生成以该节点为中心的邻居子图。GCC假设从同一中心节点出发生成的两个子图应该具有相似的结构属性,因此被作为正例;对于从不同节点(包括相同网络或不同网络中的节点)出发生成的多个子图,则应该具有与中心节点相关的独特结构属性,也就是说彼此间不具有结构相似性,因此构成负例。在输入空间构造的各子图通过图神经网络编码得到子图在隐空间的整体向量表示,GCC的预训练任务则是在隐空间表示下在词典中为查询子图(query)q找到与之相似的键子图(key)k0,即采用对比学习常用的InfoNCE损失函数[25]。此外,GCC采用了MoCo中的队列机制,来维护足够大且支持动态更新的键子图词典。
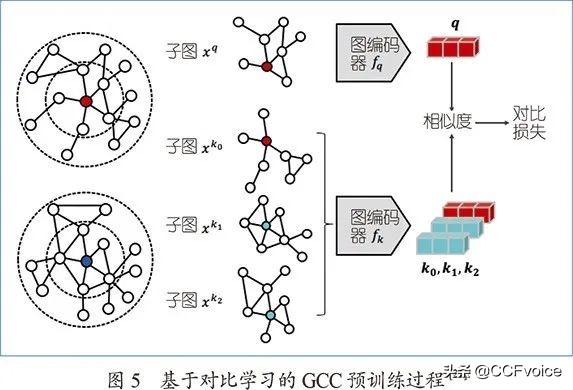
GCC中的子图判别任务为图神经网络的跨图数据预训练提供了有效的自监督信号。对6个不同图数据进行预训练得到的图神经网络模型,可以帮助完成完全不同领域的图数据上的下游任务,如节点分类、图分类、相似度搜索。也就是说,GCC的预训练机制能够让图神经网络捕捉到不同图数据中的通用结构规律,进而赋予其在下游图挖掘任务上的领域迁移能力。
从上述介绍可以看出,如何进行数据增强(augmentation),即如何在图结构上设计负例进行对比训练的自监督信号,对基于对比学习的图神经网络预训练的成功起着至关重要的作用。DGI[23]中的负例是通过对原始图结构进行随机变换而获得的。在InfoGraph[24]和GCC[21]中,所有样本都是从输入图中得到真实网络结构,其正负例则由样本的具体来源而定,如根据其是否来源于同一图结构。此外,GCC[21,26]等方法都是通过随机游走(或传播)的方式对输入图进行数据增强,从而产生预训练的监督信号。虽然目前的几种数据增强方法都在具体实验中得到了验证,但它们的理论基础以及是否存在更合理的图数据增强方法仍需进一步探索。
展望
图神经网络的自监督模型研究目前还处于起步阶段。从目前进展来看,针对图结构数据的预训练框架设计、理论基础以及应用价值仍然有待进一步探索,具体如下:
1. 图自监督学习模型旨在捕获图上的通用特征,但究竟是哪些特征对特定下游任务发挥作用,目前仍然不得而知,研究可解释性的模型至关重要。
2. 在对比学习这一方向上,如何有效地对图结构进行数据增强,以及更合理地设计图神经网络预训练的自监督信号,仍然有巨大的发展空间。
3. 生成式自监督学习任务与对比式任务在理论上有何异同,二者是否可以结合,是否存在更合理的自监督学习任务,仍值得进一步探讨。
4. 目前的研究多着眼于图结构与图属性的预训练,以知识图谱为例,其蕴含丰富的实体关系和文本信息,如何赋予图神经网络及其自监督学习捕捉到此类图数据中的实体关系和相关知识,是推动其具备认知和推理能力的关键基础,也是未来非常值得研究的课题。
参考文献
[1] Battaglia P W , Hamrick J B , Bapst V , et al. Relational inductive biases, deep learning, and graph networks[OL]. arXiv preprint arXiv:1806.01261, 2018.
[2] Hamilton W L, Ying R, Leskovec J.Inductive Representation Learning on Large Graphs[C]// Advances in Neural Information Processing Systems, 2017.
[3] Kipf TN and Welling M. Semi-Supervised Classification with Graph Convolutional Network[C]// International Conference on Learning Representations 2017.
[4] Veličković P, Cucurull G, Casanova A and et al. Graph Attention Networks[C]// International Conference on Learning Representations 2018.
[5] Hu Z, Dong Y, Wang K, et al. Heterogeneous Graph Transformer[C]//The Web Conference, 2020.
[6] Gilmer J, Schoenholz S S, Riley PF, et al. Neural Message Passing for Quantum Chemistry[C]//Proceedings of the 34th International Conference on Machine Learning - Volume 70, 2017.
[7] Zitnik M, Agrawal M, Leskovec J. Modeling Polypharmacy Side Effects with Graph Convolutional Networks[J].Intelligent Systems in Molecular Biology, 2018, 34(13).
[8] Ding M , Zhou C , Chen Q , et al. Cognitive Graph for Multi-Hop Reading Comprehension at Scale[C]// The 57th Annual Meeting of the Association for Computational Linguistics, 2019.
[9] Xu K, Hu W, Leskovec J, et al.How Powerful are Graph Neural Networks [C]//7th International Conference on Learning Representations, 2019.
[10] Devlin J, Chang M W, Lee K and et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [C]//Annual Conference of the North American Chapter of the Association for Computational Linguistics, 2019.
[11] Hjelm R D , Fedorov A , Lavoie-Marchildon S , et al. Learning deep representations by mutual information estimation and maximization[C]// 7th International Conference on Learning Representations, 2019.
[12] Oord A V D, Li Y, Vinyals O. Representation Learning with Contrastive Predictive Coding. arXiv preprint arXiv:1807.03748, 2018.
[13] He K, Fan H, Wu Y, et al. Momentum Contrast for Unsupervised Visual Representation Learning[C]// CVPR 2020: Computer Vision and Pattern Recognition, 2020.
[14] X. Liu, F. Zhang, Z. Hou, Z. Wang, L. Mian, J. Zhang and J. Tang, "Self-supervised Learning: Generative or Contrastive," arXiv: Learning, 2020.
[15] R. Hadsell, S. Chopra and Y. LeCun, "Dimensionality Reduction by Learning an Invariant Mapping," in 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06), 2006.
[16] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever and D. Amodei, "Language Models are Few-Shot Learners," arXiv preprint arXiv:2005.14165, 2020.
[17] B. Perozzi, R. Al-Rfou and S. Skiena, "DeepWalk: online learning of social representations," in Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, 2014.
[18] A. Grover and J. Leskovec, "node2vec: Scalable Feature Learning for Networks," in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016.
[19] Y. Dong, N. V. Chawla and A. Swami, "metapath2vec: Scalable Representation Learning for Heterogeneous Networks," in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017.
[20] Z. Hu, Y. Dong, K. Wang, K.-W. Chang and Y. Sun, "GPT-GNN: Generative Pre-Training of Graph Neural Networks," in KDD, 2020.
[21] J. Qiu, Q. Chen, Y. Dong, J. Zhang, H. Yang, M. Ding, K. Wang and J. Tang, "GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training.," in KDD, 2020.
[22] W. Hu, B. Liu, J. Gomes, M. Zitnik, P. Liang, V. Pande and J. Leskovec, "Strategies for Pre-training Graph Neural Networks," in ICLR 2020 : Eighth International Conference on Learning Representations, 2020.
[23] P. Veličković, W. Fedus, W. L. Hamilton, P. Liò, Y. Bengio and R. D. Hjelm, "Deep Graph Infomax," in ICLR 2019 : 7th International Conference on Learning Representations, 2019.
[24] F.-Y. Sun, J. Hoffman, V. Verma and J. Tang, "InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization," in ICLR 2020 : Eighth International Conference on Learning Representations, 2020.
[25] M. Gutmann and A. Hyvärinen, "Noise-contrastive estimation: A new estimation principle for unnormalized statistical models," in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 2010.
[26] K. Hassani and A. H. Khasahmadi, "Contrastive Multi-View Representation Learning on Graphs.," arXiv preprint arXiv:2006.05582, 2020.
特别声明:中国计算机学会(CCF)拥有《中国计算机学会通讯》(CCCF)所刊登内容的所有版权,未经CCF允许,不得转载本刊文字及照片,否则被视为侵权。对于侵权行为,CCF将追究其法律责任
作者简介
