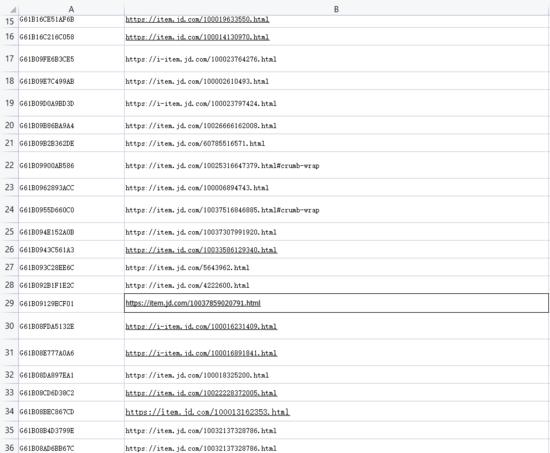
以下是爬取京东商品详情的Python3代码,以excel存放链接的方式批量爬取。excel如下
代码如下
私信小编01即可获取大量Python学习资源
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import datetime
import calendar
import logging
from logging import handlers
import requests
import os
import time
import pymssql
import openpyxl
import xlrd
import codecs
class EgongYePing:
options = webdriver.FirefoxOptions()
fp = webdriver.FirefoxProfile()
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showWhenStarting",False)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/zip,application/octet-stream")
global driver
driver= webdriver.Firefox(firefox_profile=fp,options=options)
def Init(self,url,code):
print(url.strip())
driver.get(url.strip())
#driver.refresh()
# 操作浏览器属于异步,在网络出现问题的时候。可能代码先执行。但是请求页面没有应答。所以硬等
time.sleep(int(3))
html = etree.HTML(driver.page_source)
if driver.title!=None:
listImg=html.xpath('//*[contains(@class,"spec-list")]//ul//li//img')
if len(listImg)==0:
pass
if len(listImg)>0:
imgSrc=''
for item in range(len(listImg)):
imgSrc='https://img14.360buyimg.com/n0/'+listImg[item].attrib["data-url"]
print('头图*载下**:'+imgSrc)
try:
Headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
r = requests.get(imgSrc, headers=Headers, stream=True)
if r.status_code == 200:
imgUrl=''
if item==0:
imgUrl+=code + "_主图_" + str(item) + '.' + imgSrc.split('//')[1].split('/')[len(imgSrc.split('//')[1].split('/'))-1].split('.')[1]
else:
imgUrl+=code + "_附图_" + str(item) + '.' + imgSrc.split('//')[1].split('/')[len(imgSrc.split('//')[1].split('/'))-1].split('.')[1]
open(os.getcwd()+'/img/'+ imgUrl , 'wb').write(r.content) # 将内容写入图片
del r
except Exception as e:
print("图片禁止访问:"+imgSrc)
listImg=html.xpath('//*[contains(@class,"ssd-module")]')
if len(listImg)==0:
listImg=html.xpath('//*[contains(@id,"J-detail-content")]//div//div//p//img')
if len(listImg)==0:
listImg=html.xpath('//*[contains(@id,"J-detail-content")]//img')
if len(listImg)>0:
for index in range(len(listImg)):
detailsHTML=listImg[index].attrib
if 'data-id' in detailsHTML:
try:
details= driver.find_element_by_class_name("animate-"+listImg[index].attrib['data-id']).value_of_css_property('background-image')
details=details.replace('url(' , ' ')
details=details.replace(')' , ' ')
newDetails=details.replace('"', ' ')
details=newDetails.strip()
print("详情图*载下**:"+details)
try:
Headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
r = requests.get(details, headers=Headers, stream=True)
if r.status_code == 200:
imgUrl=''
imgUrl+=code + "_详情图_" + str(index) + '.' + details.split('//')[1].split('/')[len(details.split('//')[1].split('/'))-1].split('.')[1]
open(os.getcwd()+'/img/'+ imgUrl, 'wb').write(r.content) # 将内容写入图片
del r
except Exception as e:
print("图片禁止访问:"+details)
except Exception as e:
print('其他格式的图片不收录');
if 'src' in detailsHTML:
try:
details= listImg[index].attrib['src']
if 'http' in details:
pass
else:
details='https:'+details
print("详情图*载下**:"+details)
try:
Headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
r = requests.get(details, headers=Headers, stream=True)
if r.status_code == 200:
imgUrl=''
imgUrl+=code + "_详情图_" + str(index) + '.' + details.split('//')[1].split('/')[len(details.split('//')[1].split('/'))-1].split('.')[1]
open(os.getcwd()+'/img/'+ imgUrl, 'wb').write(r.content) # 将内容写入图片
del r
except Exception as e:
print("图片禁止访问:"+details)
except Exception as e:
print('其他格式的图片不收录');
print('结束执行')
@staticmethod
def readxlsx(inputText):
filename=inputText
inwb = openpyxl.load_workbook(filename) # 读文件
sheetnames = inwb.get_sheet_names() # 获取读文件中所有的sheet,通过名字的方式
ws = inwb.get_sheet_by_name(sheetnames[0]) # 获取第一个sheet内容
# 获取sheet的最大行数和列数
rows = ws.max_row
cols = ws.max_column
for r in range(1,rows+1):
for c in range(1,cols):
if ws.cell(r,c).value!=None and r!=1 :
if 'item.jd.com' in str(ws.cell(r,c+1).value) and str(ws.cell(r,c+1).value).find('i-item.jd.com')==-1:
print('支持:'+str(ws.cell(r,c).value)+'|'+str(ws.cell(r,c+1).value))
EgongYePing().Init(str(ws.cell(r,c+1).value),str(ws.cell(r,c).value))
else:
print('当前格式不支持:'+(str(ws.cell(r,c).value)+'|'+str(ws.cell(r,c+1).value)))
pass
pass
if __name__ == "__main__":
start = EgongYePing()
start.readxlsx(r'C:\Users\newYear\Desktop\爬图.xlsx')
基本上除了过期的商品无法访问以外。对于京东的三种页面结构都做了处理。能访问到的商品页面。还做了模拟浏览器请求访问和*载下**。基本不会被反爬虫屏蔽*载下**。

上面这一段是以火狐模拟器运行

上面这一段是模拟浏览器*载下**。如果不加上这一段。经常会*载下**几十张图片后,很长一段时间无法正常*载下**图片。因为没有请求头被认为是爬虫。

上面这段是京东的商品详情页面,经常会三种?(可能以后会更多的页面结构)
所以做了三段解析。只要没有抓到图片就换一种解析方式。这杨就全了。

京东的图片基本只存/1.jpg。然后域名是 https://img14.360buyimg.com/n0/。所以目前要拼一下。

京东还有个很蛋疼的地方是图片以data-id拼进div的背景元素里。所以取出来的时候要绕一下。还好也解决了。
以下是爬取京东商品详情的Python3代码,以excel存放链接的方式批量爬取。excel如下
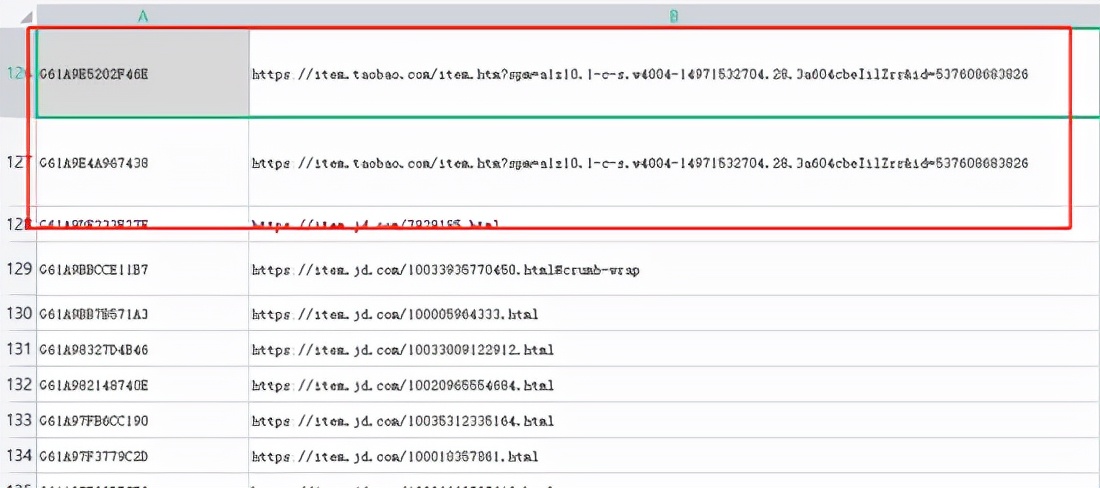
因为这次是淘宝和京东一起爬取。所以在一个excel里。代码里区分淘宝和京东的链接。以下是代码
from selenium import webdriver
from lxml import etree
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import datetime
import calendar
import logging
from logging import handlers
import requests
import os
import time
import pymssql
import openpyxl
import xlrd
import codecs
class EgongYePing:
options = webdriver.FirefoxOptions()
fp = webdriver.FirefoxProfile()
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showWhenStarting",False)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/zip,application/octet-stream")
global driver
driver= webdriver.Firefox(firefox_profile=fp,options=options)
def Init(self,url,code):
#driver = webdriver.Chrome('D:\python3\Scripts\chromedriver*ex.e**')
#driver.get(url)
print(url.strip())
driver.get(url.strip())
#driver.refresh()
# 操作浏览器属于异步,在网络出现问题的时候。可能代码先执行。但是请求页面没有应答。所以硬等
time.sleep(int(3))
html = etree.HTML(driver.page_source)
if driver.title!=None:
listImg=html.xpath('//*[contains(@id,"J_UlThumb")]//img')
if len(listImg)==0:
pass
if len(listImg)>0:
imgSrc=''
for item in range(len(listImg)):
search=listImg[item].attrib
if 'data-src' in search:
imgSrc=listImg[item].attrib["data-src"].replace('.jpg_50x50','')
else:
imgSrc=listImg[item].attrib["src"]
if 'http' in imgSrc:
pass
else:
imgSrc='https:'+imgSrc
print('头图*载下**:'+imgSrc)
try:
Headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
r = requests.get(imgSrc, headers=Headers, stream=True)
if r.status_code == 200:
imgUrl=''
if item==0:
imgUrl+=code + "_主图_" + str(item) + '.' + imgSrc.split('//')[1].split('/')[len(imgSrc.split('//')[1].split('/'))-1].split('.')[1]
else:
imgUrl+=code + "_附图_" + str(item) + '.' + imgSrc.split('//')[1].split('/')[len(imgSrc.split('//')[1].split('/'))-1].split('.')[1]
open(os.getcwd()+'/img/'+ imgUrl , 'wb').write(r.content) # 将内容写入图片
del r
except Exception as e:
print("图片禁止访问:"+imgSrc)
listImg=html.xpath('//*[contains(@id,"J_DivItemDesc")]//img')
if len(listImg)>0:
for index in range(len(listImg)):
detailsHTML=listImg[index].attrib
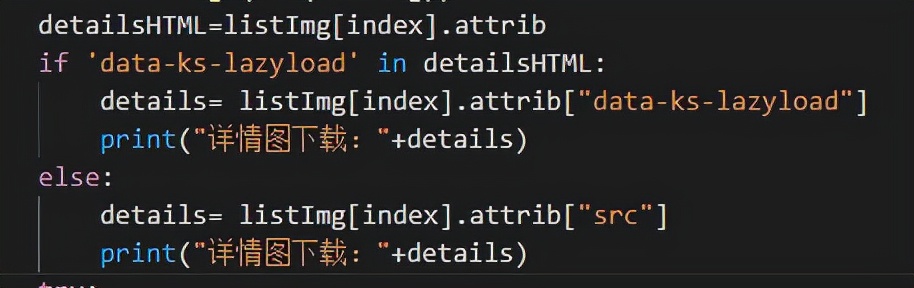
if 'data-ks-lazyload' in detailsHTML:
details= listImg[index].attrib["data-ks-lazyload"]
print("详情图*载下**:"+details)
else:
details= listImg[index].attrib["src"]
print("详情图*载下**:"+details)
try:
Headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'}
r = requests.get(details, headers=Headers, stream=True)
if r.status_code == 200:
imgUrl=''
details=details.split('?')[0]
imgUrl+=code + "_详情图_" + str(index) + '.' + details.split('//')[1].split('/')[len(details.split('//')[1].split('/'))-1].split('.')[1]
open(os.getcwd()+'/img/'+ imgUrl, 'wb').write(r.content) # 将内容写入图片
del r
except Exception as e:
print("图片禁止访问:"+details)
print('结束执行')
@staticmethod
def readxlsx(inputText):
filename=inputText
inwb = openpyxl.load_workbook(filename) # 读文件
sheetnames = inwb.get_sheet_names() # 获取读文件中所有的sheet,通过名字的方式
ws = inwb.get_sheet_by_name(sheetnames[0]) # 获取第一个sheet内容
# 获取sheet的最大行数和列数
rows = ws.max_row
cols = ws.max_column
for r in range(1,rows+1):
for c in range(1,cols):
if ws.cell(r,c).value!=None and r!=1 :
if 'item.taobao.com' in str(ws.cell(r,c+1).value):
print('支持:'+str(ws.cell(r,c).value)+'|'+str(ws.cell(r,c+1).value))
EgongYePing().Init(str(ws.cell(r,c+1).value),str(ws.cell(r,c).value))
else:
print('当前格式不支持:'+(str(ws.cell(r,c).value)+'|'+str(ws.cell(r,c+1).value)))
pass
pass
if __name__ == "__main__":
start = EgongYePing()
start.readxlsx(r'C:\Users\newYear\Desktop\爬图.xlsx')
淘宝有两个问题,一个是需要绑定账号登录访问。这里是代码断点。然后手动走过授权。
第二个是被休息和懒惰加载。被休息。其实没影响的。一个页面结构已经加载出来了。然后也不会影响访问其他的页面。
至于懒惰加载嘛。对我们也没啥影响。如果不是直接写在src里那就在判断一次取 data-ks-lazyload就出来了。
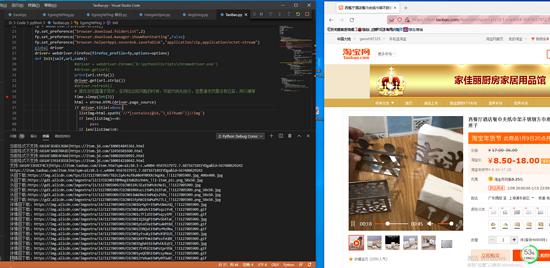
最后就是爬取的片段截图
建议还是直接将爬取的数据存服务器,数据库,或者图片服务器。因为程序挺靠谱的。一万条数据。爬了26个G的文件。最后上传的时候差点累死了
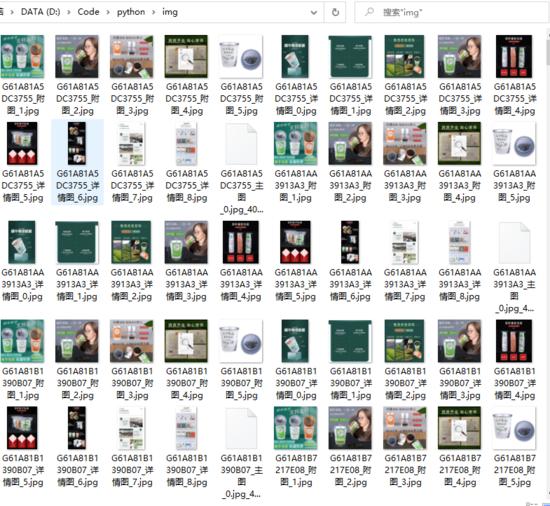
是真的大。最后还要拆包。十几个2g压缩包一个一个上传。才成功。
