本文,我们将使用Python介绍MCMC在计算机科学领域中的一些应用。我们将努力解决以下两个问题:
- 破解密码-这个问题是由数学家Persi Diaconis提出的。有人带着下面的文字来找你。这段文字看起来像胡言乱语,但其实这是密码,你能进行解密吗?

- 背包问题——这个问题来自约瑟夫·布利茨斯坦的概率论。Bilbo发现了许多珍宝。每个珍宝都有一定的重量和价值。Bilbo只能携带一定的最大重量。作为一个聪明的霍比特人,他想最大化他所得到的宝藏的价值。考虑到重量和宝藏的价值,以及Bilbo能承受的最大重量,你能找到一个好的解决方案吗?这就是计算机科学中的背包问题。
破解密码
上面的示例数据实际上来自Oliver Twist。我们使用随机加密密钥对数据进行加密,我们希望使用MCMC Chains解密这个加密文本。真正的解密密钥实际上是“ICZNBKXGMPRQTWFDYEOLJVUAHS”
解密密钥可以是任何26个字母的字符串,所有字母表只出现一次。有多少字符串排列呢?将是26!(大约10 ^ 26个排列)。这是一个非常大的数字。我们应该怎么办呢? 这就是MCMC Chains发挥作用的地方。
我们将设计一个链,其状态在理论上可以是任何这些排列。
- 首先选择一个随机的当前状态。
- 通过交换当前状态中的两个随机字母,为新状态创建一个建议。
- 使用评分函数计算当前状态Score_C和建议状态的分数Score_P。
- 如果建议状态的得分大于当前状态,则移动到建议状态。
- 或者想抛硬币一样得到正面的概率是Score_P/Score_C。如果是正面,则移动到建议状态
- 重复第二步状态。
如果幸运的话,我们可能会达到一个稳态,在这个稳态中,链上需要的状态是平稳分布的,而链的状态可以作为一个解。
问题是我们的评分函数是什么。我们希望为每个状态(解密密钥)使用一个评分函数,该函数为每个解密密钥分配一个正分数。如果使用这个解密密钥解密的加密文本看起来更像真实的文字,那么这个分数应该会比较高。
我们如何量化这样一个函数。我们将检查长文本并计算一些统计数据。例如,我们想知道“BA”在文本中出现了多少次,或者“TH”在文本中出现了多少次。
对于每对字符β1和β2(例如β1= T和β2= H),我们用R(β1,β2)记录特定对(例如“TH”)在参考文本中连续出现的次数。
类似地,对于解密密钥x,我们用Fₓ(β1,β2)记录当使用解密密钥x解密密文时该对出现的次数。
然后,我们使用以下方法对特定的解密密钥x进行评分:
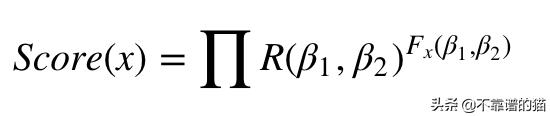
这个函数可以看作是对解密文本中每对连续的字母乘以该对在参考文本中出现的次数。
直观地说,当解密文本中的一对频率与参考文本的频率最接近时,score函数就会更高,因此解密密钥很可能是正确的。
为了简化计算,我们将计算log(Score(x))。
首先,让我们加密一些文本来创建我们的示例。
# AIM: To Decrypt a text using MCMC approach. i.e. find decryption key which we will call cipher from now on.
import string
import math
import random
# This function takes as input a decryption key and creates a dict for key where each letter in the decryption key
# maps to a alphabet For example if the decryption key is "DGHJKL...." this function will create a dict like {D:A,G:B,H:C....}
def create_cipher_dict(cipher):
cipher_dict = {}
alphabet_list = list(string.ascii_uppercase)
for i in range(len(cipher)):
cipher_dict[alphabet_list[i]] = cipher[i]
return cipher_dict
# This function takes a text and applies the cipher/key on the text and returns text.
def apply_cipher_on_text(text,cipher):
cipher_dict = create_cipher_dict(cipher)
text = list(text)
newtext = ""
for elem in text:
if elem.upper() in cipher_dict:
newtext+=cipher_dict[elem.upper()]
else:
newtext+=" "
return newtext

我们可能首先要为我们的评分函数和评分函数本身创建一些统计信息。
# This function takes as input a path to a long text and creates scoring_params dict which contains the
# number of time each pair of alphabet appears together
# Ex. {'AB':234,'TH':2343,'CD':23 ..}
def create_scoring_params_dict(longtext_path):
scoring_params = {}
alphabet_list = list(string.ascii_uppercase)
with open(longtext_path) as fp:
for line in fp:
data = list(line.strip())
for i in range(len(data)-1):
alpha_i = data[i].upper()
alpha_j = data[i+1].upper()
if alpha_i not in alphabet_list and alpha_i != " ":
alpha_i = " "
if alpha_j not in alphabet_list and alpha_j != " ":
alpha_j = " "
key = alpha_i+alpha_j
if key in scoring_params:
scoring_params[key]+=1
else:
scoring_params[key]=1
return scoring_params
# This function takes as input a text and creates scoring_params dict which contains the
# number of time each pair of alphabet appears together
# Ex. {'AB':234,'TH':2343,'CD':23 ..}
def score_params_on_cipher(text):
scoring_params = {}
alphabet_list = list(string.ascii_uppercase)
data = list(text.strip())
for i in range(len(data)-1):
alpha_i =data[i].upper()
alpha_j = data[i+1].upper()
if alpha_i not in alphabet_list and alpha_i != " ":
alpha_i = " "
if alpha_j not in alphabet_list and alpha_j != " ":
alpha_j = " "
key = alpha_i+alpha_j
if key in scoring_params:
scoring_params[key]+=1
else:
scoring_params[key]=1
return scoring_params
# This function takes the text to be decrypted and a cipher to score the cipher.
# This function returns the log(score) metric
def get_cipher_score(text,cipher,scoring_params):
cipher_dict = create_cipher_dict(cipher)
decrypted_text = apply_cipher_on_text(text,cipher)
scored_f = score_params_on_cipher(decrypted_text)
cipher_score = 0
for k,v in scored_f.items():
if k in scoring_params:
cipher_score += v*math.log(scoring_params[k])
return cipher_score

我们也想有一个函数来创建建议状态。
# Generate a proposal cipher by swapping letters at two random location def generate_cipher(cipher): pos1 = random.randint(0, len(list(cipher))-1) pos2 = random.randint(0, len(list(cipher))-1) if pos1 == pos2: return generate_cipher(cipher) else: cipher = list(cipher) pos1_alpha = cipher[pos1] pos2_alpha = cipher[pos2] cipher[pos1] = pos2_alpha cipher[pos2] = pos1_alpha return "".join(cipher) # Toss a random coin with robability of head p. If coin comes head return true else false. def random_coin(p): unif = random.uniform(0,1) if unif>=p: return False else: return True
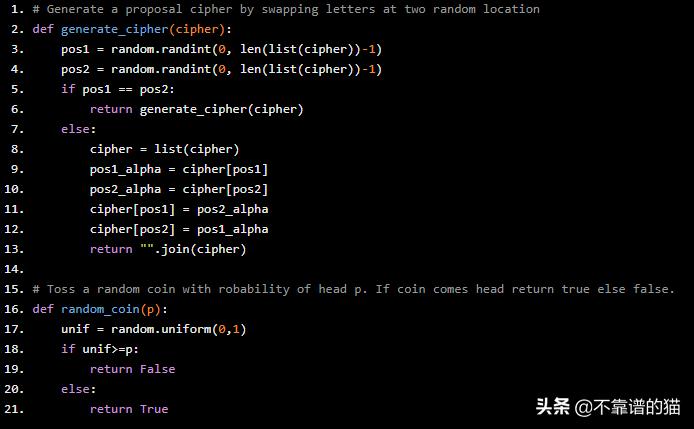
最后,这是我们的MCMC函数,它使用Metropolis-Hastings算法。
# Takes as input a text to decrypt and runs a MCMC algorithm for n_iter. Returns the state having maximum score and also
# the last few states
def MCMC_decrypt(n_iter,cipher_text,scoring_params):
current_cipher = string.ascii_uppercase # Generate a random cipher to start
state_keeper = set()
best_state = ''
score = 0
for i in range(n_iter):
state_keeper.add(current_cipher)
proposed_cipher = generate_cipher(current_cipher)
score_current_cipher = get_cipher_score(cipher_text,current_cipher,scoring_params)
score_proposed_cipher = get_cipher_score(cipher_text,proposed_cipher,scoring_params)
acceptance_probability = min(1,math.exp(score_proposed_cipher-score_current_cipher))
if score_current_cipher>score:
best_state = current_cipher
if random_coin(acceptance_probability):
current_cipher = proposed_cipher
if i%500==0:
print("iter",i,":",apply_cipher_on_text(cipher_text,current_cipher)[0:99])
return state_keeper,best_state
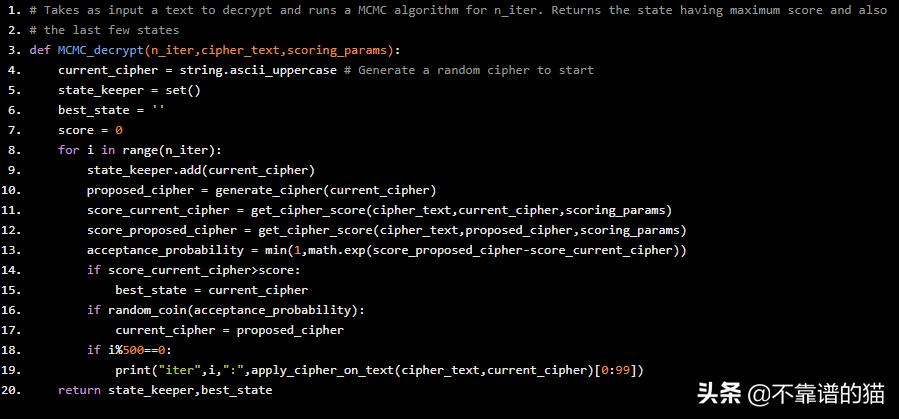
现在让我们使用上面的所有函数运行整个代码。
## Run the Main Program:
scoring_params = create_scoring_params_dict('war_and_peace.txt')
plain_text = "As Oliver gave this first proof of the free and proper action of his lungs, \
the patchwork coverlet which was carelessly flung over the iron bedstead, rustled; \
the pale face of a young woman was raised feebly from the pillow; and a faint voice imperfectly \
articulated the words, Let me see the child, and die. \
The surgeon had been sitting with his face turned towards the fire: giving the palms of his hands a warm \
and a rub alternately. As the young woman spoke, he rose, and advancing to the bed's head, said, with more kindness \
than might have been expected of him: "
encryption_key = "XEBPROHYAUFTIDSJLKZMWVNGQC"
cipher_text = apply_cipher_on_text(plain_text,encryption_key)
decryption_key = "ICZNBKXGMPRQTWFDYEOLJVUAHS"
print("Text To Decode:", cipher_text)
print("\n")
states,best_state = MCMC_decrypt(10000,cipher_text,scoring_params)
print("\n")
print("Decoded Text:",apply_cipher_on_text(cipher_text,best_state))
print("\n")
print("MCMC KEY FOUND:",best_state)
print("ACTUAL DECRYPTION KEY:",decryption_key)


在第2000次迭代中收敛。正如您所看到的,找到的MCMC密钥并不完全是加密密钥。所以这个解具有不确定性。
背包问题

这个问题中,我们有一个1xM重量值W、Gold值G的数组,以及一个表示可携带的最大重量w_MAX。我们想要找出一个由1和0组成的1xM数组X,它包含是否携带特定的宝藏。此数组需要遵循约束:

我们想要在特定状态X下使GX^T最大化。(这里T表示转置)
这是我们可以使用MCMC方法的地方。因此,让我们首先讨论如何从以前的状态创建建议。
- 从状态中选择一个随机索引并切换索引值。
- 检查我们是否满足约束条件。如果是,则此状态为提议状态。
- 否则,选择另一个随机索引并重复。
我们还需要考虑评分函数。我们将使用:
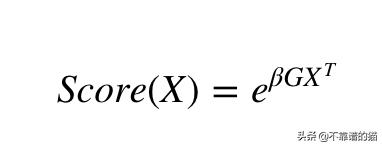
这里的是一个+ve常数。但是如何选择β呢?如果β很大,链将无法尝试新的解决方案,因为它可能会陷入局部最优。如果我们给一个小的β值,这个链就不会收敛到很好的解。因此,我们使用了一种叫做模拟退火的优化技术,也就是说,我们将从一个很小的β值开始,随着迭代次数的增加而增加。
import numpy as np W = [20,40,60,12,34,45,67,33,23,12,34,56,23,56] G = [120,420,610,112,341,435,657,363,273,812,534,356,223,516] W_max = 150 # This function takes a state X , The gold vector G and a Beta Value and return the Log of score def score_state_log(X,G,Beta): return Beta*np.dot(X,G) # This function takes as input a state X and the number of treasures M, The weight vector W and the maximum weight W_max # and returns a proposal state def create_proposal(X,W,W_max): M = len(W) random_index = random.randint(0,M-1) #print random_index proposal = list(X) proposal[random_index] = 1 - proposal[random_index] #Toggle #print proposal if np.dot(proposal,W)<=W_max: return proposal else: return create_proposal(X,W,W_max)

MCMC代码
# Takes as input a text to decrypt and runs a MCMC algorithm for n_iter. Returns the state having maximum score and also # the last few states def MCMC_Golddigger(n_iter,W,G,W_max, Beta_start = 0.05, Beta_increments=.02): M = len(W) Beta = Beta_start current_X = [0]*M # We start with all 0's state_keeper = [] best_state = '' score = 0 for i in range(n_iter): state_keeper.append(current_X) proposed_X = create_proposal(current_X,W,W_max) score_current_X = score_state_log(current_X,G,Beta) score_proposed_X = score_state_log(proposed_X,G,Beta) acceptance_probability = min(1,math.exp(score_proposed_X-score_current_X)) if score_current_X>score: best_state = current_X if random_coin(acceptance_probability): current_X = proposed_X if i%500==0: Beta += Beta_increments # You can use these below two lines to tune value of Beta #if i%20==0: # print "iter:",i," |Beta=",Beta," |Gold Value=",np.dot(current_X,G) return state_keeper,best_state

主程序:
max_state_value =0
Solution_MCMC = [0]
for i in range(10):
state_keeper,best_state = MCMC_Golddigger(50000,W,G,W_max,0.0005, .0005)
state_value=np.dot(best_state,G)
if state_value>max_state_value:
max_state_value = state_value
Solution_MCMC = best_state
print("MCMC Solution is :" , str(Solution_MCMC) , "with Gold Value:", str(max_state_value))


最后
在这篇文章中,我试图用MCMC解决计算机科学中的两个问题。密码学本身就是一门庞大的学科,有许多应用。背包问题出现在实际决策过程在各种各样的领域,如发现至少减少原材料浪费的方式,投资和投资组合的选择,选择数据块在互联网*载下**管理器和其他优化。这两个问题都有很大的状态空间,无法用蛮力来解决。