通过利用深度学习技术来比较产品列表的标题,我们大大提高了 eBay 的“查看项目”页面上推荐项目的相关性。

介绍
当购物者来到 eBay 时,我们的目标是帮助他们轻松找到他们喜欢的产品。我们新推出的推荐模型(通常称为“排名器”)现在通过利用深度学习自然语言处理 (NLP) 技术通过来自 Transformers (BERT 1 ) 的双向编码器表示将项目标题编码为语义嵌入来提供更多相关的产品推荐) 模型。我们应用这些嵌入来生成项目之间的距离分数,以用作我们排名器中的一个特征。这种新方法可以从语义角度更好地理解项目标题中最重要的信息,特别是考虑到卖家经常在他们的项目标题中放置重要的描述符。因此,买家将收到更相关、更符合他们购物兴趣的改进商品推荐,而卖家的促销商品将在正确的上下文中显示。
背景
买家的购物旅程有不同的阶段,通常称为“漏斗”。在旅程的“漏斗下游阶段”,买家在 eBay 市场中确定了他们感兴趣的产品或项目类型,并点击了产品列表。在产品列表页面,有几个模块根据不同的主题向买家推荐商品。顶部模块“类似赞助商品”推荐与页面上的主要商品相似的商品,我们称之为“种子”商品。该模块使购物者能够比较 不同的促销商品2由卖家针对他们想要购买的特定商品进行搜索,并找到价格、卖家、运输速度和条件都符合他们需求的商品。最近,我们的团队对排名引擎进行了多项改进,该引擎可为“类似赞助商品”模块生成推荐,如下所示。

机器学习排名引擎
我们的 Promoted Listing SIM (PLSIM 3 ) 排名引擎分为三个阶段。它:
- 检索与种子项目最相关的候选 PLS 项目子集(“召回集”)。
- 应用训练有素的机器学习排名器根据购买的可能性对召回集中的列表进行排名。
- 通过纳入卖家广告费率对列表进行重新排名,以平衡通过促销实现的卖家速度与推荐的相关性。
引擎第 2 阶段的排名模型是根据历史数据离线训练的。排名模型的特征或变量包括以下数据:
- 推荐项目历史数据
- 推荐项目与种子项目相似度
- 上下文(国家、产品类别)
- 用户个性化功能
我们在创新新功能时迭代地训练模型的版本,使用梯度提升树 (GBT) 根据物品的相对购买概率对物品进行排名。此外,最近在项目间相似性类别中加入了新的基于深度学习的特征,显着提升了模型性能。
标题相似性特征
在机器学习模型中试验新特征时,不仅要考虑模型的性能评估指标如何变化,还要考虑新特征对模型的重要性。在 GBT 的上下文中,这种重要性被称为“增益”,意思是每个特征对模型的相对贡献。与另一个特征相比,更高的“增益”意味着它对于在树中生成预测更为重要。
我们的推荐排名模型中最有影响力的特征集之一与买家当前正在查看的商品标题与推荐的候选商品之间的相似度有关。我们之前的推荐排名模型通过使用词频-逆文档频率 (TF-IDF 4 ) 和 Jaccard 相似度系数5比较标题关键词来评估标题相似度. 在处理同义词和具有大量项目描述符的复杂或冗长的标题时,这些措施具有基本的局限性。例如,颜色“红色”和“深红色”的常用词为零。因此,这些对将被传统的基于标记的方法(如 TF-IDF 或 Jaccard 度量)视为非常不同的项目,而实际上它们代表几乎相同的含义。
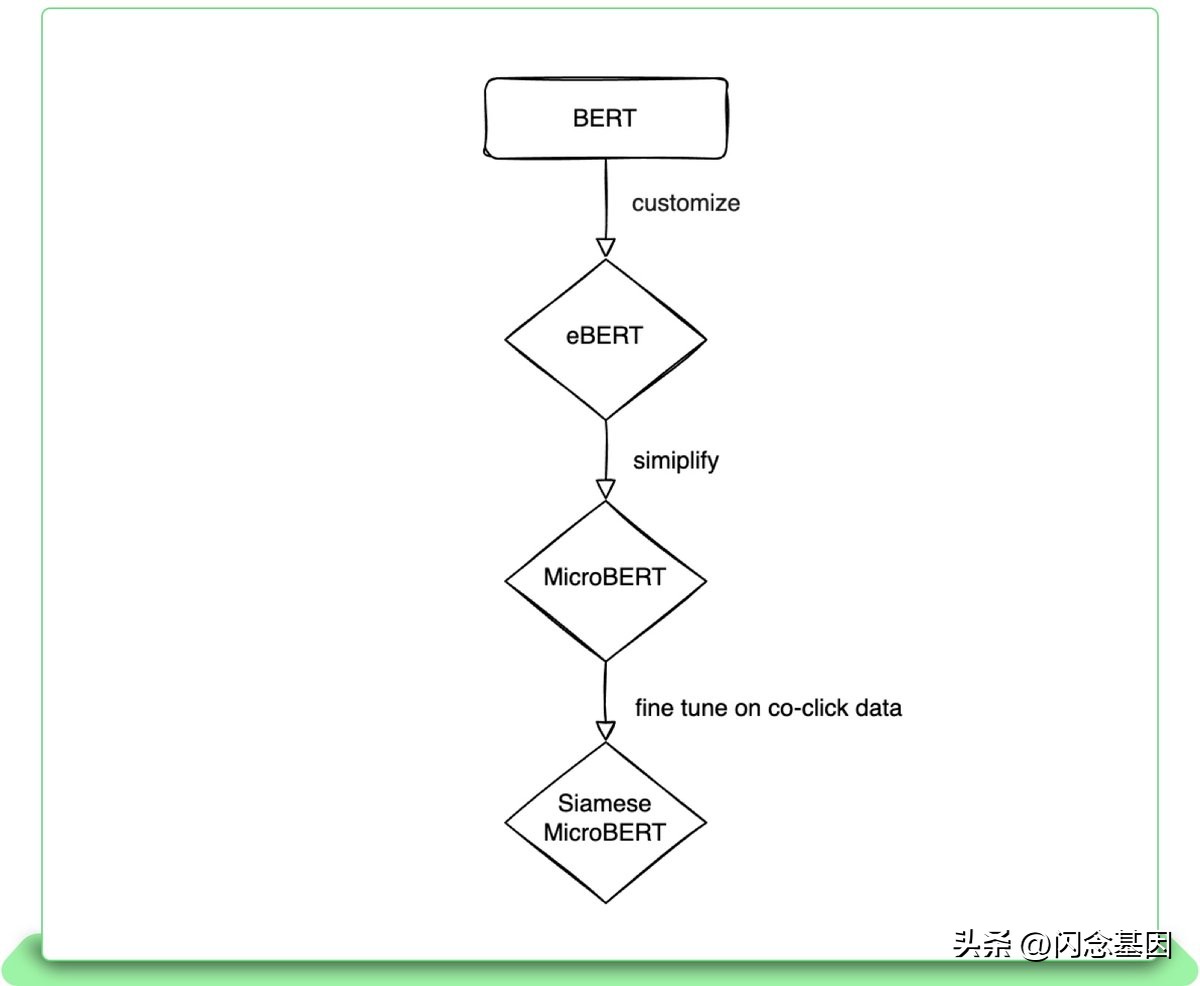
微调连体 MicroBERT
著名的 BERT 模型在语言理解任务上表现出了全面的稳定表现。BERT 是一种预训练模型,它利用大量未标记数据(来自维基百科和多伦多图书语料库的句子),使其能够识别语义相似的词(即同义词)并生成语境化词嵌入。例如,单词“server”在“The server crashed”和“Can you ask the server for the bill?”这句话中的嵌入是不同的。预训练的 BERT 模型可以通过添加特定于任务的层来微调以解决不同的 NLP 问题,这些层将上下文化的词嵌入映射到所需的输出函数。许多研究表明,针对特定任务微调预训练模型可在所有现有方法中产生最佳性能。
尽管这些开箱即用的模型取得了可接受的结果,但将 BERT 应用于 eBay 的语言理解任务仍有改进空间,因为我们的语料库与书籍或维基百科中使用的语言有很大不同。最重要的是,eBay 商品标题通常包含产品特定的词。因此,我们引入了 eBERT,这是 BERT 的一个变体,它已经在 eBay 商品标题和维基百科语料库上进行了预训练,更适合 eBay 语言理解任务的需要。eBERT 的训练数据包括来自维基百科的 2.5 亿个句子和英语、德语、法语、意大利语和西班牙语的 30 亿个 eBay 标题。在离线评估中,此 eBERT 模型在一组 eBay 特定标记任务上明显优于开箱即用的 BERT 模型,F1 得分为 88。
此外,BERT 架构对于需要高吞吐量推理的应用程序来说往往过于沉重;在这种情况下,延迟太高,因此模型无法在规定的时间内提出建议。为了解决这个问题,另一个名为 MicroBERT 的特定 eBay 模型被开发为针对 CPU 推理优化的 BERT 的较小版本,类似于 MobileBERT 6。在训练时,eBERT 模型在称为知识蒸馏的过程中充当 MicroBERT 模型的教师。这种方法允许 MicroBERT 保留 95-98% 的教师模型质量,同时将推理时间减少 300%。
最后,为了迎合我们的相似项目推荐用例,我们对 MicroBERT 进行了微调,将项目标题编码为嵌入向量,这样对于相似的项目标题,这些大数字向量之间的数学距离很小。我们使用了一个名为 InfoNCE 7的对比损失函数,它训练模型以增加已知彼此相关的标题嵌入的余弦相似度,同时降低小批量中所有其他项目标题对的余弦相似度。这种方法的优点是它只需要训练数据中语义相关的正对项。在我们的例子中,我们将正对定义为在同一搜索查询之后都被点击的项目,这是一种通过用户行为而不是手动标记来构建训练数据的廉价方式。在此数据集上微调的 MicroBERT 模型称为“Siamese MicroBERT”,可生成 96 维标题嵌入向量。虽然原则上标题嵌入也可以直接从预训练模型中提取,但微调显着提高了嵌入向量的质量。
离线实验结果
我们利用从 Siamese MicroBERT 推断出的标题嵌入来计算“查看项目”页面上的项目标题与每个推荐项目候选标题之间的余弦相似度。我们的排名模型在购买排名(即已售商品的平均排名)上取得了 3.5% 的提升,并且这个新的余弦相似度特征在特征增益列表中占据了首位。
在线推理挑战和解决方案
Siamese MicroBERT 模型的复杂性使得很难根据 eBay 的在线服务延迟要求实时进行标题嵌入推理。因此,我们不是按需计算标题嵌入,而是每天离线运行批处理作业以生成 eBay 上列出的所有新商品的标题嵌入,并将它们缓存在 NuKV 中,即 eBay 的云原生键值存储,商品标题作为键和标题嵌入作为值。缓存中每个条目的到期时间设置为共享相同标题的列表中最晚的到期时间,因此标题的条目仅在必要时保留在缓存中。通过这种方法,我们能够满足检索嵌入的延迟要求。还有一个附带的好处,
为了进一步减少延迟,我们检索标题嵌入并计算标题嵌入之间的余弦相似度,并与为我们的排名模型服务的其他任务并行计算。这样一来,我们能够将整体延迟保持在与我们之前没有余弦相似性特征的模型相同的水平。
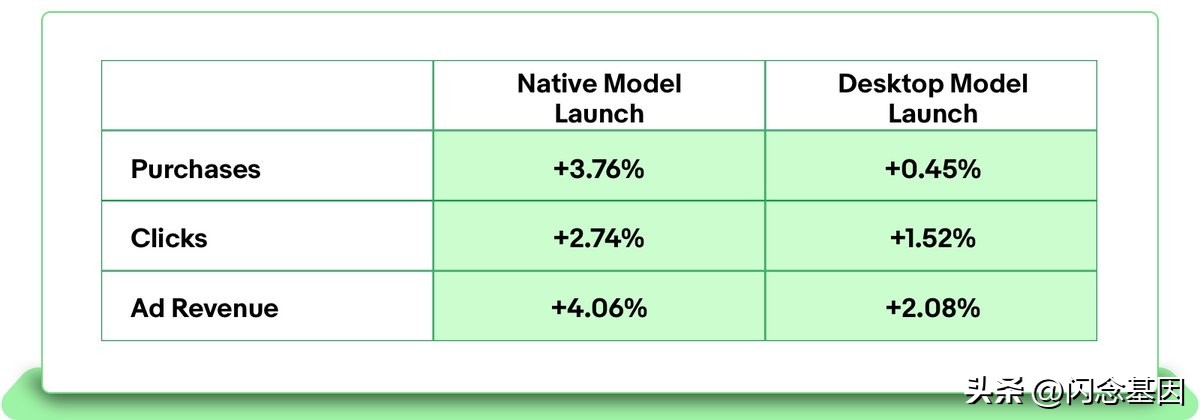
在线实验结果
与之前在本机应用程序(iOS 和安卓)和桌面网络平台上生产的模型相比,新的排名模型显着提高了购买、点击和广告收入。
A/B 测试结果证实,在我们的推荐排名模型中结合基于深度学习的自然语言处理 (NLP) 技术可以捕获项目属性之间的语义相似性,从而推动更好的转换。请参阅下面的在线示例,了解由基线生产模型生成的推荐与具有 eBERT 标题相似性特征的增强模型针对给定种子项目生成的推荐:

尽管两个模型在第一个插槽中的推荐相同,但第二个和第三个插槽中的推荐表明 eBERT 通过显示迈克尔乔丹棒球卡而不是篮球卡来检测标题中“White Sox”的相对重要性。
基于这些通过视觉检查和积极的 A/B 测试指标验证的改进排名结果,该团队正在探索其他潜在的基于深度学习的特征,例如项目图像相似性和多模式(组合标题和图像)相似性。
Alex Egg、Michael Kozielski 和 Pavel Petrushkov 也对本文做出了贡献。
1BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2 Promoted Listing Standard (PLS) offers higher surface rates to sellers and costs an additional ad rate fee that is Cost Per Acquisition (CPA) based, which means we don’t charge ads fee until conversions happen. Ads fee is determined by ad rate that sellers set with regard to total sale amount.
3Optimizing Similar Item Recommendations in a Semi-structured Marketplace to Maximize Conversion
4Semantic Sensitive TF-IDF to Determine Word Relevance in Documents
5Using of Jaccard Coefficient for Keywords Similarity
6MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
7Representation Learning with Contrastive Predictive Coding
作者:Chen Xue, Jesse Lute, Dan Schonfeld, Guoping Han and Leonard Dahlmann
出处:https://tech.ebayinc.com/engineering/how-ebay-created-a-language-model-with-three-billion-item-titles/