近两年新冠疫情持续,加速了人工智能等计算技术在各大领域的颠覆式应用,制药业也不例外。
科学家在家工作、与实验室及同事分离…这些技术在新药研发领域的应用广泛且成熟,更衍生了一套全新的商业模式。
基于此背景,本文分析了 对机器学习进一步演变的看法,人工智能紧密集成到自动化实验设备及药物管道中的潜力。
其次,还重点介绍了一些头部AI公司,来展示机器学习如何影响药物研发工作。
最后,团队提出了一些 未来可能影响药物分子设计的代表性技术 ,强调人工智能如何帮助提高新药“设计-制造-测试”周期的效率。
01、研究背景
在大流行期间,生物医药领域非必要的研究停止了,科学家们被送往许多国家。这导致了一个明显的分歧:使用计算机进行研究的科学家能够远程工作,而其他类型的研究则完全停止。
这告诉我们,如果疫情持续数年,或者我们面临 物理实验室准入的其他障碍 ,科学研究将如何改变?如果科学家必须远程工作,他们又如何进行实验室实验?
也许我们会看到更多专门建造的“远程控制”演讲厅提供这种服务。
在化学合成领域,一些小组已经进行了部分或完全自主合成的实验,而在药物筛选方面,这几十年来基本上是完全自动化的,只需很少的人力投入。但这仍需要一位科学家来进行人工实验室工作。
如果把这些元素放在一起,则可以自动完成整个过程并远程运行,从而 使“设计-制造-测试”周期在各个行业中完全自主运行 。
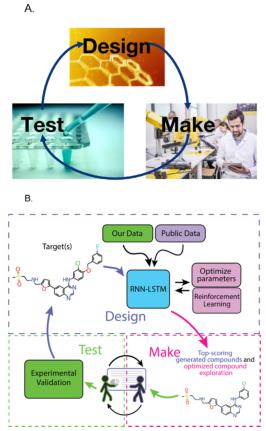
图:A、设计制造测试周期;B、一个假设案例,说明电流神经网络如何与机器学习模型和科学家的反馈相结合,以优化激酶*制剂抑**拉帕替尼。
此外, 资源限制 也使我们考虑到每个实验的重要性。如果耗材(如移液管尖端或其他基本物品)短缺,如何进行更多的研究。
科学家需要重新思考哪些实验是最关键的,如何回收和重用已经存在的数据,以确保在原始资源数据尚未被利用的情况下,不会重复实验。
在公共领域中, 生物数据的数量 正在不断增长。其中一些可以在PubChem、ChEMBL等数据库或FigShare、GitHub等存储库中轻松访问,而有些则位于不易访问的区域,如付费出版物或个人实验室网站;以及由于商业原因公司内部无法访问的数据。
大家最关注的是这些智能自动化技术、可访问数据的应用范围,从而改进整个制药行业。
02、AI药物分子,下一个商品
虽然人工智能并非药物发现领域的新技术,但不到十年时间,机器学习已经通过添加注意力基础模型、提高数据集可用性和改进硬件等方式发生了革命性的变化。
近年来,我们看到了人工智能,特别是机器学习方法在许多行业中的应用,它也可以进行商业化买卖,类似于药企们提供体外体内合成、临床测试服务。
如果机器学习成为药物研发领域的一种商品,那么这种商业的近况和前景如何?
商业模式
过去几年,AI制药公司获得了大量资金,并与大型制药公司签署合作协议。一些公司在不同的环境中使用机器学习,但都将其软件应用于药物发现项目。

图:AI公司用机器学习进行药物发现的应用案例
人们已经认识到,开源机器学习平台和化学信息学软件的产生和使用变得普遍,这也成了新一代AI-Biotech公司的起点,实现商业变现。
比如,在此类开源软件的基础上开发机器学习工具和模型,以帮助药物发现和毒理学内部项目,通过与学界共享并从中受益。
这些算法模型越来越多地利用公共数据库来选择化合物,以针对罕见、被忽视和常见疾病的靶点进行测试。
因此,在适度的资金支持下,执行这项计算工作并建立湿实验室进行验证的商业模式是切实可行的。
在疫情期间,AI-Biotech们验证了内部机器学习以及公司之间如何进行合作的重要性。机器学习为其提供了一种更有效地生产和测试新思想的方法。
而一家规模大得多的药企,往往通过更多员工和更大的财务投资来布局其中,这并不新鲜。
关键技术、数据
但当考虑到 生成模型的出现 (下文将讨论)时,它表明加速早期药物发现的管道即将到来:使用机器学习模型来指导新分子的生成,我们可以比过去的虚拟筛选方法获得更多分子;也帮助科学家识别和生成“发明”,以确定哪些值得申请专利和/或与商业应用一起发布。
此外,部分流程可以通过开源软件免费完成,取代了以前的商业化软件,但它们的集成式应用对未来的成败产生关键影响。这证明了 端到端机器学习平台 的价值。
同样,这一领域的公司与竞争对手的核心差异很可能是 对可用基础实验数据的管理 ,并确保每个公司形成基础的机器学习模型和差异化技术。
大药企不断收集数据,从而掌握了几十年来的药物发现和毒理学领域知识,与AI-Biotech相比,他们的优势要大得多。
了解不同机器学习算法的“优缺点” 也很重要,因为没有一种算法或生成的模型能完成所有预测任务。对于大多数药物发现机器学习模型,仍需要一位科学家参与其中,但这也并不意味着离自主使用很远。
03、药物分子设计的未来技术
机器学习用于建模、预测研究和开发过程中产生的各种类型的数据,它也可以在不同的研究阶段帮助分子纯化。从已知分子数据库中学习是有价值的。
但“由AI设计”不是机器学习的终点。
深入了解目前已知或最先进的技术,并根据机器学习模型、物理化学性质或其他数据提出新的分子合成方法 ,未来值得重点关注。
近年来,通过使用许多 不同架构的生成模型 (如变分自动编码器、生成对抗网络和递归神经网络) 来设计和生成小分子,以从头生成分子,这一领域已经取得了实质性进展。
关于进一步的细节,读者可以参考该领域的多篇评论。但使用这些方法对所提出的分子进行前瞻性测试通常很少,许多人倾向于跳过合成,寻找结构相似但可从供应商处购买的化合物。
当这种生成的机器学习模型衍生的分子被实际合成时,通常也不是以自动化或紧密集成的方式完成,而是交给CRO、合作方或其他研究团队跟进。
生成方法在大分子从头设计中的应用 也相对空白,尽管有许多大型生物技术公司专注于生物制品,不过其专利最终也将到期。
有人会假设,这些公司也在探索这种机器学习方法如何帮助他们设计新的生物制剂或优化现有产品。
比如借助公开可用数据对机器学习模型进行验证,使用生成性长短期记忆(LSTM)算法生成具有预测的胰高血糖素样肽-1(GLP-1)激动剂活性的新肽。
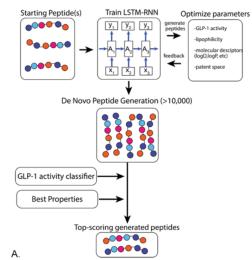
GLP-1生成肽设计的案例研究。图A,在1554个抗菌肽的数据集上训练RNN-LSTM,并用ChEMBL中的数据生成的GLP-1激动剂模型对生成的肽进行评分。
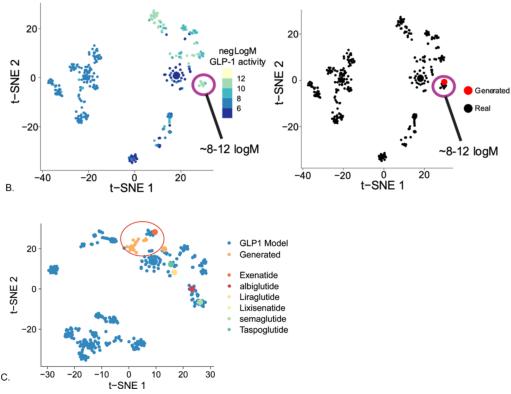
图B,使用生成的拟议GLP-1激动剂的t-SNE图和最近邻距离进行降维;图C,将新产生的GLP-1激动剂与商业GLP-1药物一起可视化,以说明它们在化学性质空间上接近。
这表明, 算法中新提出的分子在结构和预测的生物活性上,与已知的商业GLP-1激动剂非常接近 ,这将为其实用性提供一定的信心。
这一点的最终证明仍需要合成和测试这些假设分子,有许多模式可以帮助我们探索化学和性质空间。
基于片段的药物发现、基于结构设计、计算机辅助设计等技术历史悠久,生成方法不是生产或优化分子的唯一方法。
DNA编码库等其他技术可以快速生成数十亿个潜在结构,这些结构需要通过机器学习模型进行评分。其瓶颈在于指纹生成(如ECFP6)及其处理前的存储结构。一种解决方案是以SMILES编码结构,作为使用端到端卷积LSTM模型建模的输入。
此外,使用卷积LSTM模型对DNA编码库中的十亿分子进行预测,从而在GPU上进行计算,允许并行模型预测和预处理。这与在内部的10个GPU服务器上单独使用ECFP6指纹构建的模型相比,预测生成速度提高了 近50倍 。
这证明了使用SMILES的端到端机器学习模型,也可以用于其他类型的数据集。
此外,我们还将看到这些 模型被集成到未来的自动化实验室设备中 。
硬件和软件组合能够帮助分子设计,同时根据计算预测提出并制造分子;这也将有助于重复紧密集成的“设计-制造”测试,直到达到期望的终点(如可测量的生物活性、分子特性)。
过去,大型制药公司在相对较小的范围中应用机器学习,因此影响不大;相比之下,规模小而新的制药公司正在大范围应用机器学习,并专注于新分子的测试。一些数据也验证了AI-Biotech公司可观的交易估值。
从更大的角度来看, 机器学习也可能是达到目的的一种手段 ,这一目的是具有所需活性的分子,继而获得专利以创造知识产权,最后公司将其货币化。
应用于药物发现过程中的机器学习模型可以很容易地用于开发小分子或大分子药物管道,或者作为风险投资投资者创建新公司的起点。
如果多家公司纷纷布局,将会为行业创造一个围绕AI辅助设计分子的全新市场;同时,拥有此类技术的公司向其他人提供这种专业知识和能力,以创建一个新的服务行业,也即AI CRO。
结论:
总之,文中的例子说明了人工智能应用于分子设计可能如何影响几个相关行业,包括制药业、材料业、合成生物学等。
值得关注的是,人工智能技术是否确实提高了这一批AI制药公司的长期生产力和成功率? 我们谨慎乐观地认为,人工智能在制药行业的时机已经到来,它将产生持久的影响 。
诚然,人工智能方法的应用研究、监管审查方面还有大量空白,一些伦理问题也尚未解决。但我们期待着,与参与该领域的科学家们一同探讨。
参考链接:
https://doi.org/10.1016/j.ailsci.2022.100031
—The End—