Hive 的官网:http://hive.apache.org/
Hive versions 1.2 onward require Java 1.7 or newer.
上一篇提到的 MapRedue 虽然简化了分布式应用的实现方式,但还是离不开写代码。
Hive 简介
Hive 是基于 Hadoop 的一个【数据仓库工具】,可以将结构化的数据文件映射为一张 hive 数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。
非 Java 编程者对 HDFS 的数据做 mapreduce 操作。
好处:使用 SQL 来快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,学习成本低,十分适合数据仓库的统计分析。
数据仓库简介
Hive 是一个数据仓库工具,那么数据仓库是什么呢?相信大家对数据库并不陌生,翻译成英文是 DataBase , 而数据仓库的英文翻译是 Data Warehouse,可以简写成 DW 或 DWH。不同于数据库,数据仓库是面向主题的,为了支持决策创建的,主要理解这四个特点就可以了:面向主题、数据集成、历史数据、有时间维度的。
OLTP & OLAP
联机事务处理 on-line transaction processing
OLTP 是传统关系数据库的主要应用,主要是基本的事务处理,例如交易系统。
它强调数据库内存效率,强调各种指标的命令率,强调绑定变量,强调并发操作。
联机分析处理 on-line analytical processing
OLAP 是数据仓库的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
它强调数据分析,强调 SQL 执行市场,强调磁盘 I/O,强调分区。
下表是 OLTP 和 OLAP 的区别(用户,功能,DB 设计,数据,存取,工作单位,用户数,DB 大小,时间要求,主要应用)
OLTPOLAP用户初级的决策者、高级的功能基本查询分析决策DB 设计面向应用面向主题数据当前的。最新的细节,二维分立的历史的,多数据源的(聚集的,多维的)存取读取 10 条记录读上百万条记录工作单位简单的事务复杂的查询用户数上千个上百万个DB 大小MB-GBGB、TB、PB、EB时间要求实时对实时要求不严格主要应用数据库数据仓库
综上。数据仓库支持很复杂的查询,就是用来做数据分析的数据库。基本不用来做插入,修改,删除操作。
Hive 运行时,元数据存储在关系型数据库中。
还需要明确两点:
Hive 的真实数据是在 HDFS 上的。
Hive 的计算是通过 Yarn 和 MR 的。
Hive 架构
用户接口主要有三个:Cli, Client 和 WUI 。见图 1-1,图 1-2
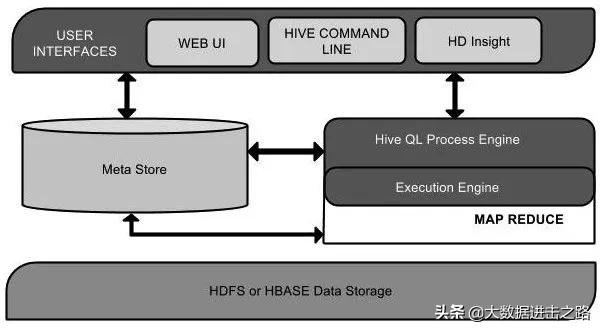
图 1-1
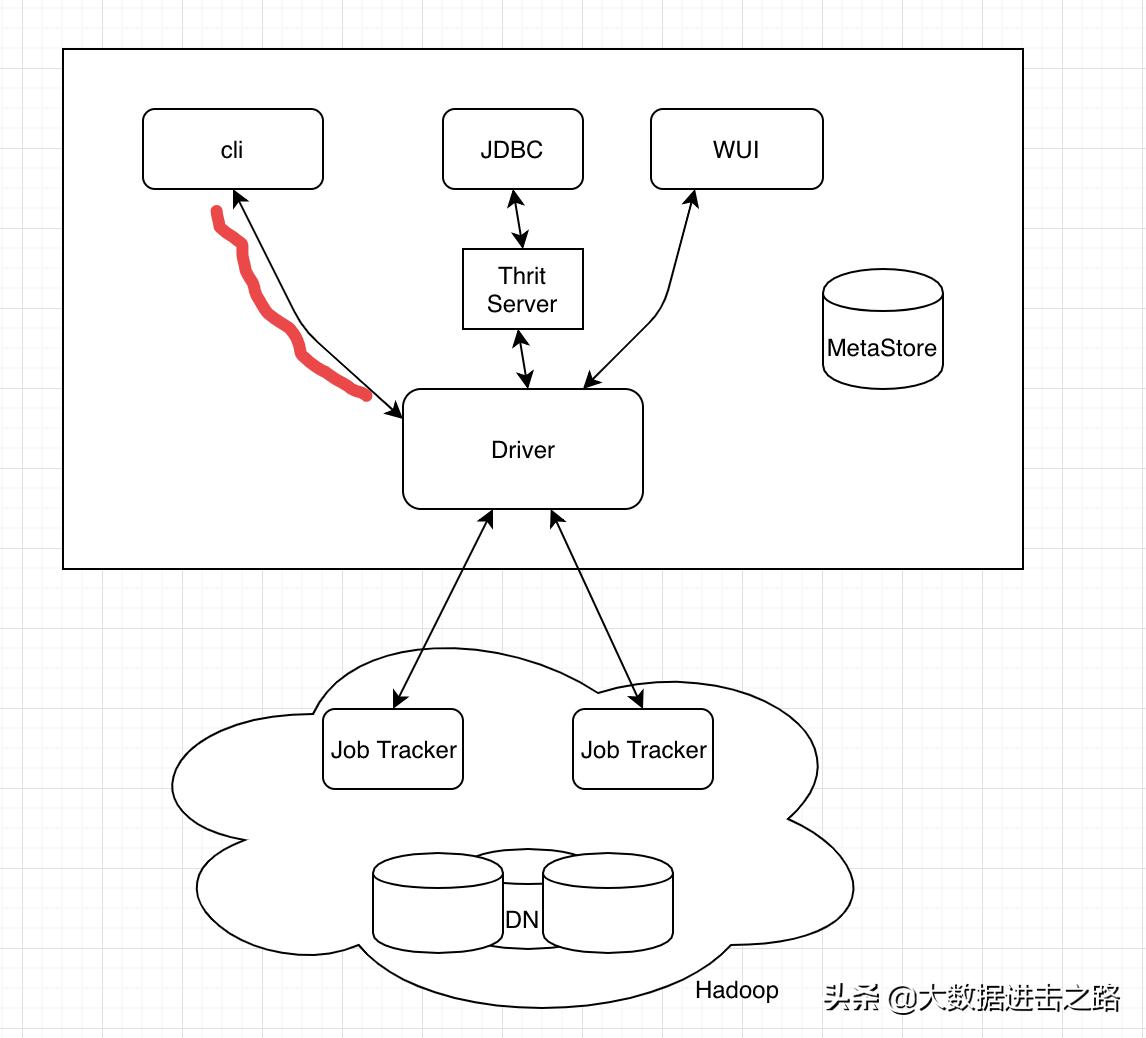
图 1-2
从图中可以看到,有三种连接方式:
1.cli 是最常用的,cli 启动时,会同时创建一个 Hive 副本。
安装好之后,直接使用 hive 命令,进入 hive> ,如下图 1-3

图 1-3
这种方式,也可以使用命令: hive --service cli
2.使用 Client 方式,需要在编写 JDBC 程序,需要指定 HIve Server。 所指定的节点需要开启 Hive Server。
Plain Text
1
$ $HIVE_HOME/bin/hiveserver2
2
$ $HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT
当然也可以使用 hive --service hivesrver2 的方式开启。
注:使用 hiveServer2 的方式和使用 metastore 方式不同的地方在于前者还可以提供 JDBC 等连接。
3.WUI ,使用浏览器使用 Hive。(这个很少用)
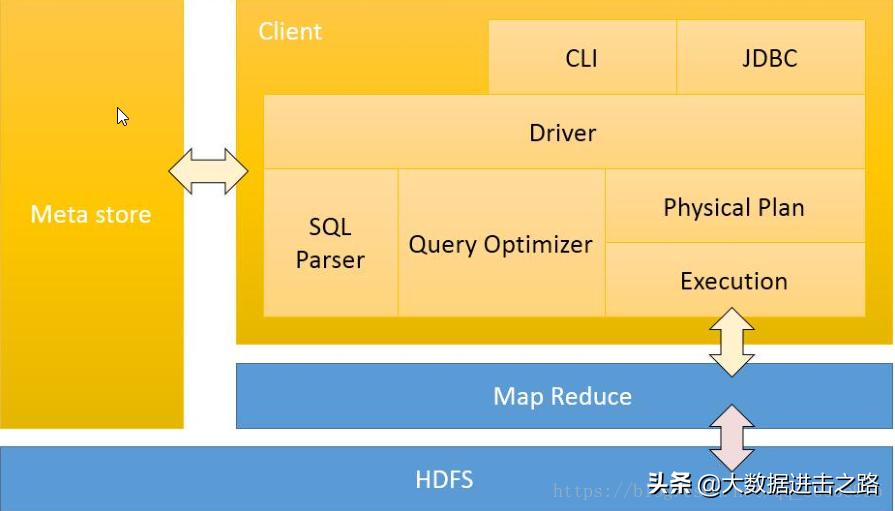
数据仓库 Hive 的元数据存储在关系型数据库中,如 mysql,derby等。元数据包括表的名字,表的列,属性,数据所在目录等信息。
解释器,编译器,优化器成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
Hive 的数据存储在 HDFS 中。计算由 Yarn 和 mapReduce 来完成。值得注意的是,SELECT * from XXX;这样的操作,不会提交 MapReduce 任务。
总结:
Hive 是一个基于 Hadoop 文件系统之上的数据仓库架构,存储用 hdfs,计算用 mapreduce。
Hive 可以理解为一个工具,不存在主从架构,不需要安装在每台服务器上,只需要安装几台就行了。
Hive 还支持类 sql 语言,它可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。
Hive 有个默认数据库:derby,默认存储元数据--->一般企业使用关系型数据库存储 mysql 元数据
。
三种部署方式
前提
*载下**安装包:apache-hive-1.2.1-bin.tar.gz ,解压。
准备 mysql 环境,用来保存元数据的。
有Hadoop 集群环境,Hive 存储要使用 HDFS 的。
内嵌模式
这种模式,使用的是内嵌的数据库 derby 来保存元数据,但是只允许一个会话连接。
配置很简单,只需要一个 hive-site.xml 文件。(注:使用 derby 存储方式时,运行 hive 会在当前目录生成一个 derby 文件和一个 metastore_db)
XML
1
<?xml version="1.0"?>
2
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3
<configuration>
4
<property>
5
<name>javax.jdo.option.ConnectionURL</name>
6
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
7
</property>
8
<property>
9
<name>javax.jdo.option.ConnectionDriverName</name>
10
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
11
</property>
12
<property>
13
<name>hive.metastore.local</name>
14
<value>true</value>
15
</property>
16
<property>
17
<name>hive.metastore.warehouse.dir</name>
18
<value>/user/hive/warehouse</value>
19
</property>
20
</configuration>
本地模式(测试用)
本地模式就是把元数据的存储介质由 derby 换成了 mysql 。
需要:
把 mysql 的驱动添加到 $HIVE_HOME 目录下的 lib 下。
配置文件:hive-site.xml, 注意这种方式 mysql 的账户密码就明文写在配置文件里面了。
XML
1
<?xml version="1.0"?>
2
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3
<configuration>
4
<property>
5
<name>hive.metastore.warehouse.dir</name>
6
<value>/user/hive_rlocal/warehouse</value>
7
</property>
8
<property>
9
<name>hive.metastore.local</name>
10
<value>true</value>
11
</property>
12
<property>
13
<name>javax.jdo.option.ConnectionURL</name>
14
<value>jdbc:mysql://node01/hive_local?createDatabaseIfNotExist=t
15
rue</value>
16
</property>
17
<property>
18
<name>javax.jdo.option.ConnectionDriverName</name>
19
<value>com.mysql.jdbc.Driver</value>
20
</property>
21
<property>
22
<name>javax.jdo.option.ConnectionUserName</name>
23
<value>root</value>
24
</property>
25
<property>
26
<name>javax.jdo.option.ConnectionPassword</name>
27
<value>123456</value>
28
</property>
29
</configuration>
这里要说明一点的是,hive 和 MySQL 不用做 HA,单节点就可以。通过设置其他节点可以访问得到数据库。
远程模式(重要)
这种模式需要在远端的服务器运行一个 mysql 服务器,并且需要在 Hive 服务器开启 meta 服务。
hive-site.xml 文件。
XML
1
<?xml version="1.0"?>
2
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3
<configuration>
4
<property>
5
<name>hive.metastore.warehouse.dir</name>
6
<value>/user/hive/warehouse2</value>
7
</property>
8
<property>
9
<name>javax.jdo.option.ConnectionURL</name>
10
<value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true</value>
11
</property>
12
<property>
13
<name>javax.jdo.option.ConnectionDriverName</name>
14
<value>com.mysql.jdbc.Driver</value> </property>
15
<property>
16
<name>javax.jdo.option.ConnectionUserName</name>
17
<value>root</value>
18
</property>
19
<property>
20
<name>javax.jdo.option.ConnectionPassword</name>
21
<value>123456</value>
22
</property>
23
<property>
24
<name>hive.metastore.local</name>
25
<value>false</value>
26
</property>
27
<property>
28
<name>hive.metastore.uris</name>
29
<value>thrift://node01:9083</value>
30
</property>
31
32
</configuration>
这里把 hive 的服务端和客户端都放在同一台服务器上了。服务端和客户端可以拆开,
远程模式(分开,企业常用)
服务端配置:
XML
1
<?xml version="1.0"?>
2
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3
<configuration>
4
<property>
5
<name>hive.metastore.warehouse.dir</name>
6
<value>/user/hive/warehouse-server</value> </property>
7
<property>
8
<name>javax.jdo.option.ConnectionURL</name>
9
<value>jdbc:mysql://node03:3306/hive?createDatabaseIfNotExist=true</value>
10
</property>
11
<property>
12
<name>javax.jdo.option.ConnectionDriverName</name>
13
<value>com.mysql.jdbc.Driver</value> </property>
14
<property>
15
<name>javax.jdo.option.ConnectionUserName</name>
16
<value>root</value>
17
</property>
18
<property>
19
<name>javax.jdo.option.ConnectionPassword</name>
20
<value>123456</value>
21
</property>
22
</configuration>
启动:hive --service metastore
客户端配置
XML
1
<!-- 客户端 -->
2
<?xml version="1.0"?>
3
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
4
<configuration>
5
<property>
6
<name>hive.metastore.warehouse.dir</name>
7
<value>/user/hive/warehouse-server</value>
8
</property>
9
<property>
10
<name>hive.metastore.local</name>
11
<value>false</value>
12
</property>
13
<property>
14
<name>hive.metastore.uris</name>
15
<value>thrift://node01:9083</value>
16
</property>
17
</configuration>
Hive常见问题总汇: 链接
HSQL 详解
可以查看官网更加详细的案例:https://cwiki.apache.org/confluence/display/Hive/LanguageManual
DDL 语句:详情看这里 https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
下面,记录的是一些常用的操作,重要的是建表语句和分区。
下面只展示几个例子,以供大家参考
创建数据库:
create database if not exists foo; 创建数据库,不存在则创建。
create database foo comment 'this is a database for test '; 创建数据库,并指定描述信息
数据库的位置默认是在 HDFS 上的 /user/hive/warehouse/ 目录下的,可以通过 show create database foo会打印出,创建数据库的信息。
Hive 会为每一个数据库创建一个目录,该数据库的每张表都会存在该目录的子目录里面。
删除数据库:使用 DROP 命令
修改数据库:使用 ALTER 命令
查看数据库描述:使用 describe 命令
切换数据库:使用 use 命令
创建表:
先来看一下数据类型
数据类型:
data_type:标蓝色的是常用的
| primitive_type 原始数据类型
| array_type 数组
**
| map_type map键值对**
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION
| STRING 基本可以搞定一切
BINARY
| TIMESTAMP
| DECIMAL
| DECIMAL(precision, scale) | DATE
| VARCHAR
| CHAR
**
array_type
: ARRAY < data_type > **
map_type
: MAP < primitive_type, data_type > struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... >
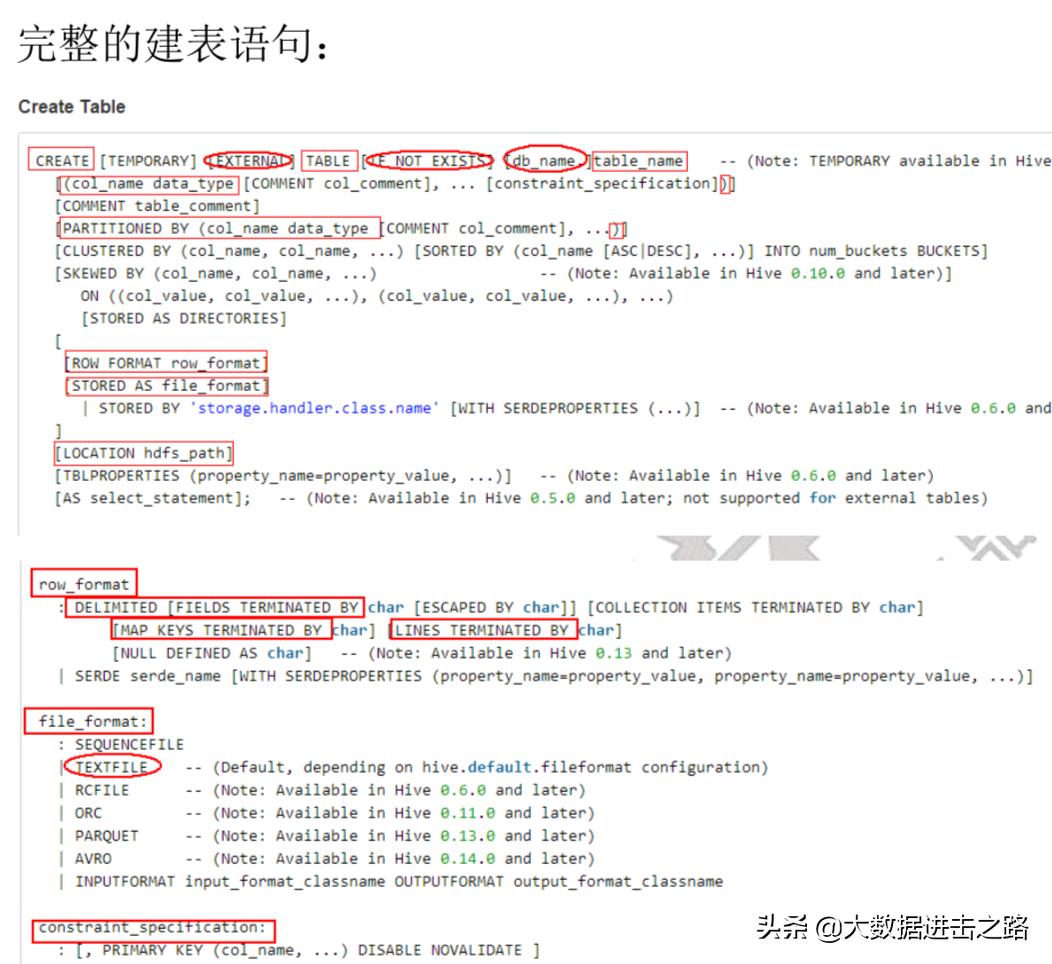
例子:
SQL
1
create table foo(
2
id int,
3
name string,
4
age int,
5
likes array<string>,
6
address map<string, string>
7
)
8
row format delimited fields terminated by ','
9
COLLECTION ITEMS TERMINATED by '-'
10
map keys terminated by ':'
11
lines terminated by '\n';
准备如下测试数据,字段
Bash
1
1,lily,18,game-girl-book,stu_addr:beijing-work_addr:shanghai
2
2,tom,16,shop-swimming-book,stu_addr:hunan-work_addr:shanghai
3
3,bob,20,read-run,stu_addr:shanghai-work_addr:USA
准备好数据之后,开始导入数据:
语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
操作:
load data local inpath '/opt/datas/hive_test.txt' into table foo;
说明:local 指定的是系统的本地路径,如果不加 local,就要指定 hdfs 上的路径。
导入数据之后,可以看到 mysql 数据库中有一些元数据信息,如下:
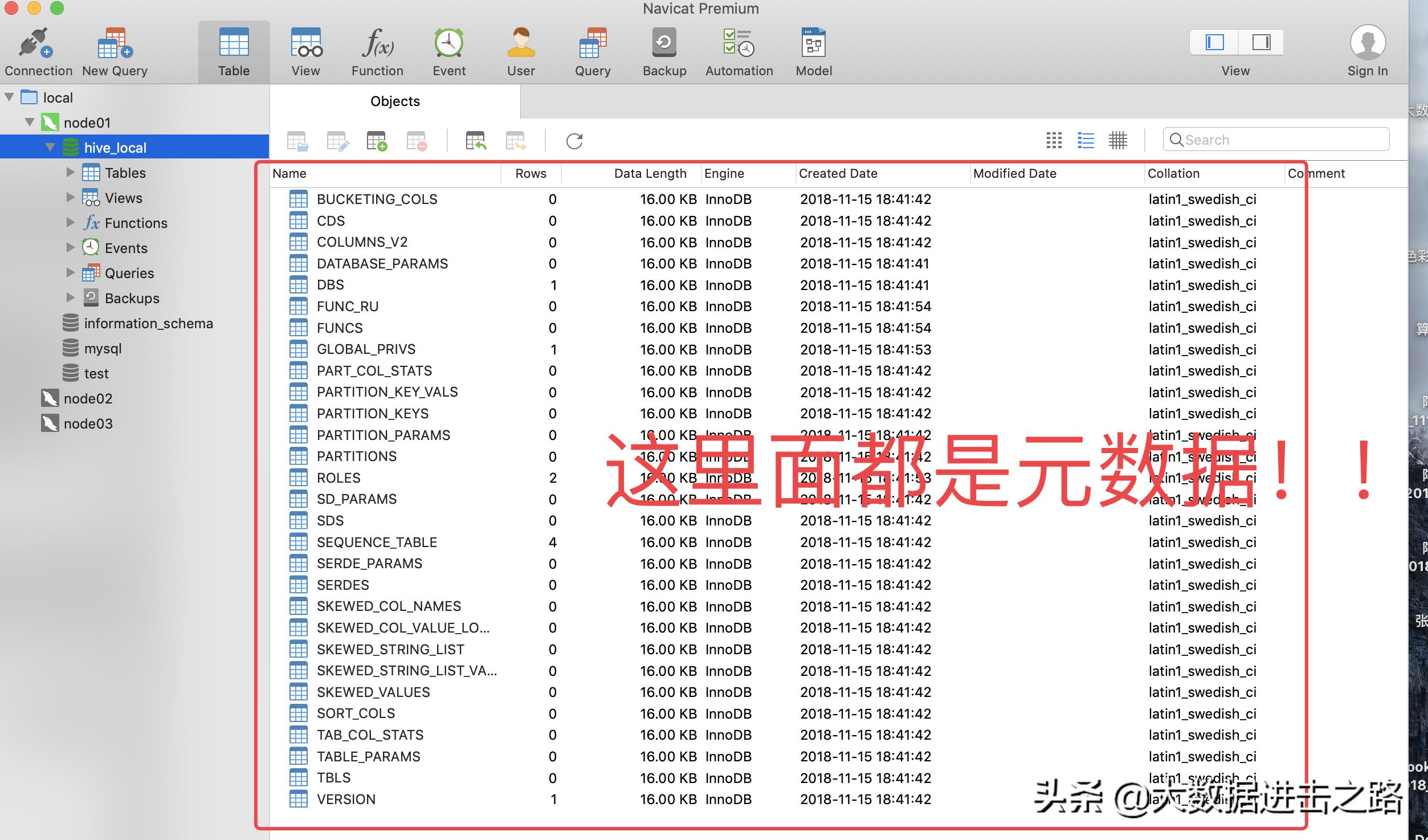
分区表
使用关键词 PARTITIONED BY 来指定分区字段,一张表可以有一个或者多个分区,数据按照分区字段分别存储到不同的目录下。简单的分区表如下:
SQL
1
create table table_name (
2
id int,
3
dtDontQuery string,
4
name string
5
)
6
partitioned by (date string)
更多关于分区表的内容,下面会介绍的。
上面是 DDL 的一些操作,重点是建表语句和分区语句。下面简单总结一下,
- Managed and External Tables:内表和外表的区别,建立外表需要加上额外的关键词 external ,外表的数据可以指向任何 HDFS 的位置,而不一定是默认的位置。删除外表的时候,不会删除数据,只会删除元数据。
- 为了健壮性,建表的时候最好加上 IF NOT EXISTS 来避免发生异常。
- Hive 的存储格式:textFile 、SEQUENCEFILE、ORC 等。
DML
具体可以参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML
Hive 不能很好的支持用 insert 语句一条一条的进行插入操作,不支持 update 操作。数据是以 load 的方式加载到建立好的表中。数据一旦导入就不可以修改。
插入数据
第一种:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLEtablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
可选项:local 、overwrite 、partition
第二种:
创建表的时候,通过 select 或者 insert 或者 location 加载数据。注意通过 insert 这种方式个非常耗时,尽量避免使用这种方式。
参考:https://www.2cto.com/kf/201609/545560.html
本地 load 数据和从 HDFS 上 load 加载数据的过程有什么区别?
本地: local 会自动复制到 HDFS 上的 hive 的**目录下
查询数据并保存
第一种,保存到本地:insert overwrite local directory '/opt/date/xxx.txt' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from table_name;
第二种,保存到 HDFS 上的某个路径上:insert overwrite directory '/opt/date/xxx.txt' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from table_name;
第三种,可以在 hive客户端执行 hive -e "select * from table_name " > "/opt/data/xxx.txt" 重定向到文件。
备份或还原数据
使用 export table db_2019.emp to '/xx/xx' 备份数据
使用 import from '/xx/xx' 还原数据
常见的查询,如 group by、 having、join 、sort by、order by等,与 mysql 类似。
Hive SerDe 用于对做序列化和反序列化,构建在数据存储和计算引擎之间,实现两者的解耦。下面是官网的几个例子:
SQL
1
CREATE TABLE apachelog (
2
host STRING,
3
identity STRING,
4
user STRING,
5
time STRING,
6
request STRING,
7
status STRING,
8
size STRING,
9
referer STRING,
10
agent STRING)
11
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
12
WITH SERDEPROPERTIES (
13
"input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
14
)
15
STORED AS TEXTFILE;
SQL
1
CREATE TABLE my_table(a string, b bigint, ...)
2
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
3
STORED AS TEXTFILE;
Beeline & Hiveserver2
官网的描述:
Beeline is started with the JDBC URL of the HiveServer2, which depends on the address and port where HiveServer2 was started.
By default, it will be (localhost:10000), so the address will look like jdbc:hive2://localhost:10000.
Beeline 和 cli 的区别:CliDriver是 SQL 本地直接编译,然后访问 MetaStore,提交作业,是重客户端。
BeeLine 是把 SQL 提交给 HiveServer2,由 HiveServer2 编译,然后访问 MetaStore,提交作业,是轻客户端。
这种模式下经常用来使用 JDBC 来查询数据,下面是一个官网的示例代码:
Java
1
import java.sql.SQLException;
2
import java.sql.Connection;
3
import java.sql.ResultSet;
4
import java.sql.Statement;
5
import java.sql.DriverManager;
6
7
public class HiveJdbcClient {
8
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
9
10
/**
11
* @param args
12
* @throws SQLException
13
*/
14
public static void main(String[] args) throws SQLException {
15
try {
16
Class.forName(driverName);
17
} catch (ClassNotFoundException e) {
18
// TODO Auto-generated catch block
19
e.printStackTrace();
20
System.exit(1);
21
}
22
//replace "hive" here with the name of the user the queries should run as
23
Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "hive", "");
24
Statement stmt = con.createStatement();
25
String tableName = "testHiveDriverTable";
26
stmt*ex.e**cute("drop table if exists " + tableName);
27
stmt*ex.e**cute("create table " + tableName + " (key int, value string)");
28
// show tables
29
String sql = "show tables '" + tableName + "'";
30
System.out.println("Running: " + sql);
31
ResultSet res = stmt*ex.e**cuteQuery(sql);
32
if (res.next()) {
33
System.out.println(res.getString(1));
34
}
35
// describe table
36
sql = "describe " + tableName;
37
System.out.println("Running: " + sql);
38
res = stmt*ex.e**cuteQuery(sql);
39
while (res.next()) {
40
System.out.println(res.getString(1) + "\t" + res.getString(2));
41
}
42
43
// load data into table
44
// NOTE: filepath has to be local to the hive server
45
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
46
String filepath = "/tmp/a.txt";
47
sql = "load data local inpath '" + filepath + "' into table " + tableName;
48
System.out.println("Running: " + sql);
49
stmt*ex.e**cute(sql);
50
51
// select * query
52
sql = "select * from " + tableName;
53
System.out.println("Running: " + sql);
54
res = stmt*ex.e**cuteQuery(sql);
55
while (res.next()) {
56
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
57
}
58
59
// regular hive query
60
sql = "select count(1) from " + tableName;
61
System.out.println("Running: " + sql);
62
res = stmt*ex.e**cuteQuery(sql);
63
while (res.next()) {
64
System.out.println(res.getString(1));
65
}
66
}
67
}
分区 & 分桶
Hive 分区表的建立是为了方便管理大量的数据。比如下面这个例子:分区使用关键词 partitioned by
SQL
1
create table day_hour_table (id int, content string)
2
partitioned by (dt string, hour string)
3
row format delimited fields terminated by ',';
使用查询的时候,指定 where 后面跟着分区字段, 可以减少计算的数据量,加快查询效率。
查看分区:show partitions table_name
添加分区:alter table table_name add partition(dt='2018',hour='9')
重命名分区:alter table table_name partition(dt='2018',hour='9') rename to partition(dt='2018',hour='10')
删除分区:alter table table_name drop partition(dt='2018',hour='10'), 分区的数据和元数据一起被删除。
加载数据到分区:load data inpath 'xxxx' into table table_name partition(dt='2018',hour='9')
加载的数据的时候,上面的是未开启动态分区的情况下的,如果开启了动态分区,就不需要手动指定分区的值了。
开启动态分区的参数如下:
hive*ex.e**c.dynamic.partition 设置成 true ,
hive*ex.e**c.dynamic.partition.mode 需要设置成 nostrict 模式,表示允许所有的字段是动态分区字段。hive*ex.e**c.max.dynamic.partitions.pernode 在每个执行 MR 的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就需要设置成大于 365,如果使用默认值 100,则会报错。
动态分区表的使用流程:1.常见临时表,将数据家在进去。2.使用 hsql 将临时表的按照分区字段动态加入。
分桶:分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。对于 hive 中每一个表、分区都可以进一步进行分桶。由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
适用场景:适用场景:
数据抽样( sampling )、map-join
开启支持分桶
set hive.enforce.bucketing=true;默认:false;
设置为 true 之后,mr 运行时会根据 bucket 的个数自动分配 reduce task 个数。(用户也可以通过 mapred.reduce.tasks 自己设置 reduce 任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶(文件数量)和 reduce task 个数一致。
桶表 抽样查询
select * from bucket_table tablesample(bucket 1 out of 4 on columns);TABLESAMPLE 语法:
函数自定义
UDAF:多进一出
UDF: 一进一出
UDTF:一进多出
使用方式: 在 hive 中 add jar , 之后创建函数调用这个 jar 就可以了。下面是 一个自定义函数的例子:
编写 UDF 函数的时候需要注意一下几点:
a)自定义 UDF 需要继承 org.apache.hadoop.hive.ql.UDF。
b)需要实现 evaluate 函数,evaluate 函数支持重载。
Java
1
package com.hive.test.udf;
2
3
import org.apache.commons.lang.StringUtils;
4
import org.apache.hadoop.hive.ql*ex.e**c.UDF;
5
import org.apache.hadoop.io.Text;
6
7
// 例子
8
public class Trim extends UDF {
9
private Text res = new Text();
10
11
public Text evaluate(String str) {
12
13
if (str == null) {
14
return null;
15
}
16
res.set(StringUtils.strip(str.toString()));
17
18
return res;
19
}
20
21
public Text evaluate(Text str,String stripChars){
22
if (str == null) {
23
return null;
24
}
25
26
res.set(StringUtils.strip(str.toString(),stripChars));
27
return res;
28
29
}
30
}
然后导出 Jar 包,在 Hive 中执行 add jar jar 位置,
方式1:hive> add jar /xxx/xx/xxx.jar
方式2:在启动时在命令后传递 --auxpath选项, --auxpath后面为jar包所在的路径hive -auxpath /xxx/xx/xxx.jar
清除缓存时记得删除 jar 包 delete jar /*
之后再创建临时函数: hive>CREATE TEMPORARY FUNCTION trim1 'com.hive.test.udf.Trim'; ps: 红色部分为类的全限定名
使用:select trim1(参数) form 表。
如果只用这一次,可以销毁了:hive> DROP TEMPORARY FUNCTION trim1;
UDAF 和 UDTF 函数用的比较少。
Hive 优化
Hive 优化
核心思想:把Hive SQL 当做Mapreduce程序去优化
以下SQL不会转为Mapreduce来执行
--select仅查询本表字段
--where仅对本表字段做条件过滤
------------------------------------------------------------------------------
Explain 显示执行计划
EXPLAIN [EXTENDED] query
-------------------------------------------------------------------------------
Hive运行方式:
本地模式 100MB
集群模式
本地模式
开启本地模式:
set hive*ex.e**c.mode.local.auto=true;
注意:
hive*ex.e**c.mode.local.auto.inputbytes.max默认值为128M【134217728】
表示加载文件的最大值,若大于该配置仍会以集群方式来运行!
-------------------------------------------------------------------------------
严格模式
通过设置以下参数开启严格模式[防止误操作]:
set hive.mapred.mode=strict;
(默认为:nonstrict非严格模式)
查询限制:
1、对分区表查询时,必须添加where对于分区字段的条件过滤;
2、order by语句必须包含limit输出限制;
3、限制执行笛卡尔积的查询
-------------------------------------------------------------------------------
Hive排序
Order By - 对于查询结果做全排序,只允许有一个reduce处理
(当数据量较大时,应慎用。严格模式下,必须结合limit来使用)
Sort By - 对于单个reduce的数据进行排序
Distribute By - 分区排序,经常和Sort By结合使用
Cluster By - 相当于 Sort By + Distribute By
(Cluster By不能通过asc、desc的方式指定排序规则;
可通过 distribute by column sort by column asc|desc 的方式)
-------------------------------------------------------------------------------
Hive Join
Join计算时,将小表(驱动表)放在join的左边
Map Join:在Map端完成Join
两种实现方式:
1、SQL方式,在SQL语句中添加MapJoin标记(mapjoin hint)
语法:
SELECT /+ MAPJOIN(smallTable) / smallTable.key, bigTable.value
FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key;
2、开启自动的MapJoin
通过修改以下配置启用自动的mapjoin:
set hive.auto.convert.join = true;
(该参数为true时,Hive自动对左边的表统计量,如果是小表就加入内存,即对小表使用Map join)
其他相关配置参数:
hive.mapjoin.smalltable.filesize;
(大表小表判断的阈值25MB左右,如果表的大小小于该值则会被加载到内存中运行)
hive.ignore.mapjoin.hint;
(默认值:true;是否忽略mapjoin hint 即mapjoin标记)
hive.auto.convert.join.noconditionaltask;
(默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin)
hive.auto.convert.join.noconditionaltask.size;
(将多个mapjoin转化为一个mapjoin时,其表的最大值)
-------------------------------------------------------------------------------
Map-Side聚合 如count()等聚合函数
通过设置以下参数开启在Map端的聚合:
set hive.map.aggr=true;
相关配置参数:
hive.groupby.mapaggr.checkinterval:
map端group by执行聚合时处理的多少行数据(默认:100000)
hive.map.aggr.hash.min.reduction:
进行聚合的最小比例(预先对100000条数据做聚合,若聚合的数据量 /100000
的值小于该配置0.5,则不会聚合)
hive.map.aggr.hash.percentmemory:
map端聚合使用的内存的最大值
hive.map.aggr.hash.force.flush.memory.threshold:
map端做聚合操作是hash表的最大可用内容,大于该值则会触发flush
hive.groupby.skewindata
是否对GroupBy产生的数据倾斜做优化,默认为false
分成两个 MR 任务。
-------------------------------------------------------------------------------
控制Hive中Map以及Reduce的数量
Map数量相关的参数
mapred.max.split.size
一个split的最大值,即每个map处理文件的最大值
mapred.min.split.size.per.node
一个节点上split的最小值
mapred.min.split.size.per.rack
一个机架上split的最小值
Reduce数量相关的参数
mapred.reduce.tasks
强制指定reduce任务的数量
hive*ex.e**c.reducers.bytes.per.reducer
每个reduce任务处理的数据量
hive*ex.e**c.reducers.max
每个任务最大的reduce数 [Map数量 >= Reduce数量 ]
-------------------------------------------------------------------------------
Hive - JVM重用
适用场景:
1、小文件个数过多
2、task个数过多
通过 set mapred.job.reuse.jvm.num.tasks=n; 来设置
(n为task插槽个数)
缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,
直到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源!