
数据驱动控制概述
模型参考控制是目前控制系统设计的主流方法。其中,最具代表性的是模型参考自适应控制。只要建模足够理想且精准,那么根据需求和理论设置控制器,便可以达到所需的控制性能。 然而实际情况是 ,模型通常是时变的、非线性的、不确定的,无法得到理想的精准模型。同时,控制器的设计还需要考虑有机械和传感器等带来的约束。控制系统的设计一般包括模型辨识、控制设计、性能评估三个环节,三者相互影响、相互迭代。模型的线性拟合辨识精度低会导致与实际被控对象的偏差较大,进而控制器设计不准确,性能评估也难以起到迭代作用。或者为了减少建模误差,充分考虑时变性、非线性等,这也会导致控制系统设计相当困难、实现相当复杂。加之机械特性、传感器等约束的现实条件,最终可能导致 理论可行但实际难以实现 。

有没有不需要建模的方法,是指可以直接从现有数据入手,设计控制器呢?
无模型控制,也称为数据驱动控制( Data-Driven Control ) ,是一种不依赖于被控对象本身的数学模型,只利用测量的输入输出数据集来设计控制器的控制方法。换句话说,在控制器设计过程中,无模型控制使用了很少或甚至没有与被控对象本身有关的信息。
数据驱动的控制技术通过性能指标来提高性能表现。这些指标通常在时间域中指定,例如超调量、稳定时间和上升时间,以积分或求和的目标函数进行聚合。通过将这些目标函数最小化,在约束优化问题中可以实现多种目标,例如参考轨迹跟踪、控制输入的约束以及扰动抑制。数据驱动的控制技术专注于在没有或者只有较少过程模型信息的情况下实现性能,通过简单而易于解释的控制器(如行业中最流行的PI和PID控制器)来满足性能规范。
神经网络控制和模糊控制算不算数据驱动控制? 观点1: 神经网络控制和模糊控制都属于无模型控制 。在这两种控制方法中,没有显式的数学模型来描述受控系统的动态行为,而是通过对输入-输出数据关系的学习或根据模糊的知识和规则来进行控制决策。因此,这些方法也被称为基于数据或经验的控制方法。 观点2: 严格来说,神经网络控制和模糊控制并不是无模型控制 。网络节点和隐层的选择需要了解受控对象的一些信息,而且神经网络本身就是受控对象的一种模型,模型发生变化时是需要重新训练以适应系统变化。同样地,模糊控制也不算无模型控制,因为IF-THEN规则本身就是一种模型,需要深入了解受控系统,以便在系统发生大变化时重新制定规则。因此,根据无模型控制方法的定义,它们并不属于无模型控制方法。 本人观点:数据驱动控制本身就是一个较为宽泛的概念,神经网络控制和模糊控制算不算数据驱动控制不同角度有不同的观点,实际应用时可根据自己需要来定义,总之 不管黑猫白猫,抓住老鼠就是好猫!

握手言和
数据驱动控制的主要缺点是难以进行系统稳定性和鲁棒性分析 。换句话说,即使确保参考轨迹跟踪的调整,也不能保证鲁棒稳定性和鲁棒性能。这是因为这些分析需要受控过程的详细数学模型。尽管如此,术语“鲁棒性”在基于模型的控制中指的是控制器对建模错误不敏感的特性,但在数据驱动控制中通常会避免使用。由于数据驱动控制不需要模型,因此应澄清“鲁棒性”一词的使用。与数据驱动控制的稳定性相关的另一个缺点是它们的有效性受到测量噪声的强烈影响。
相关方法
- 无模型自适应控制(Model-Free Adaptive Control,MFAC) 利用在线数据来不断更新自适应控制器参数
- 迭代学习控制( Iterative Learning Control, ILC ) 使用先前执行的控制结果来改善系统性能的控制方法。在一系列连续的迭代上,逐步调整控制器的输出,通过不断的迭代来提高系统精度和稳定性。在每次迭代中,控制器收集执行过程中产生的误差信号和过程输出,以便在下一次迭代中进行更好的控制。通过重复进行迭代,系统可以逐步消除由于测量误差和非线*行为性**引起的控制误差,最终实现高精度的控制.
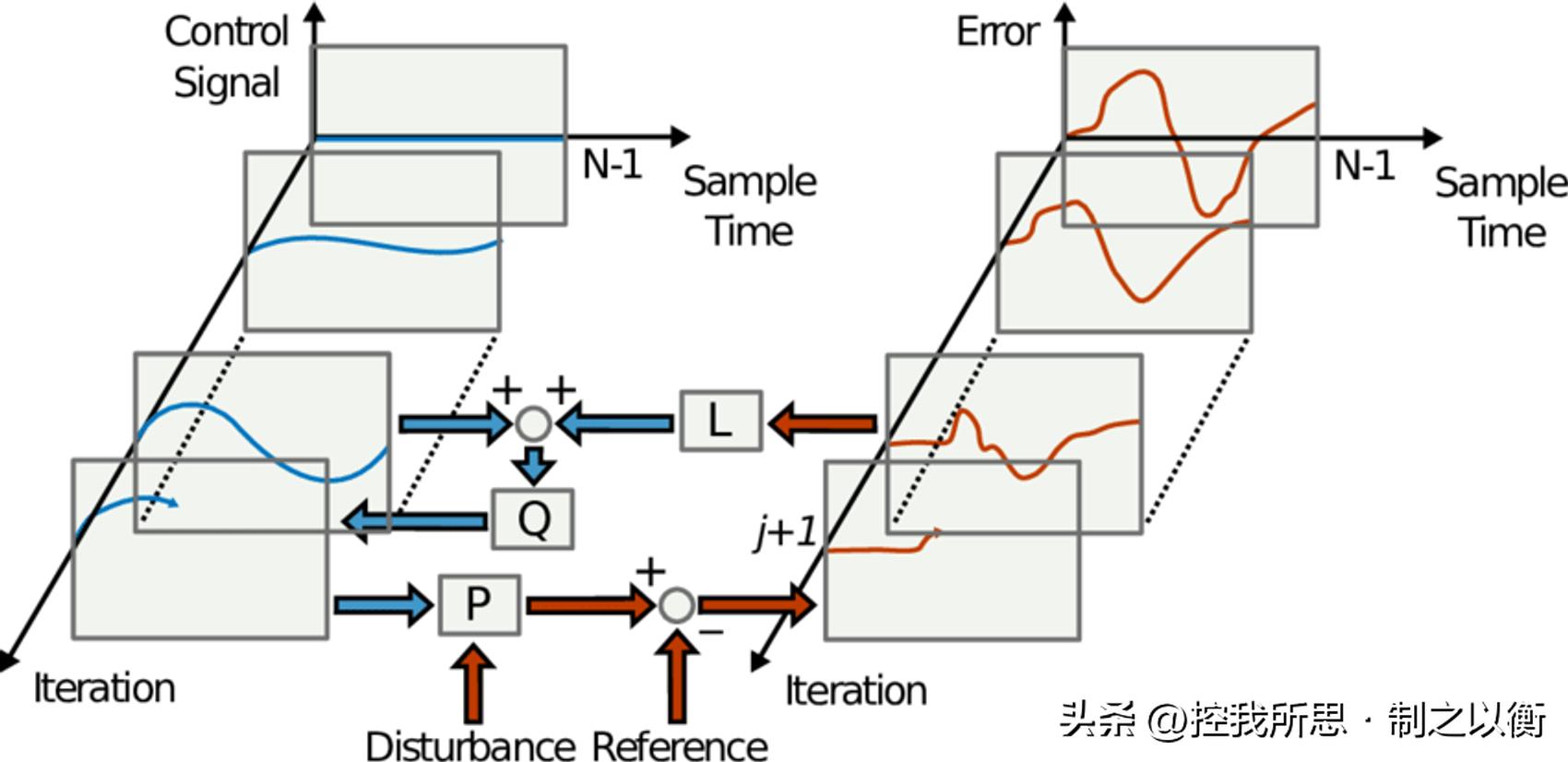
- 迭代反馈调节( Iterative Feedback Tuning, IFT ) 使用周期性的试验信号来收集系统响应,并根据收集到的数据来对控制器参数进行逐步调整,以实现更好的控制性能。
- 迭代相关性调谐( Iterative Correlation-based Tuning, ICbT ) 基于系统的输出信号和参考信号之间的相关性,以自适应地调整控制器参数。在每次迭代中,CbT方法会检查输出信号和参考信号之间的相关性,然后根据这个相关性来更新控制器参数以实现更好的控制性能。

频域调节同步扰动随机逼近( Frequency-domain Tuning with Simultaneous Perturbation Stochastic Approximation, FDSA-SPSA )
- 根据控制器频域响应的误差信号来更新控制器参数
- 迭代回归调整( Iterative Regression Tuning, IRT ) 使用回归分析技术来计算最优的控制器参数
- 强化学习( Reinforcement Learning, RL ) 数据驱动的机器学习方法,通过与环境交互来学习适当的行为。智能体在环境中通过执行一个操作来获取反馈信号,然后通过反馈信号来学习如何做出更好的决策。通过试错并且逐步提高自己,智能体最终可以学会如何优化某种特定的目标。Q-learning算法,使用Q值函数来记录每种行动的预期回报,并通过选择最高Q值的行为来最大程度地优化行动策略。在机器人控制、游戏AI、自动驾驶等领域中得到了广泛应用。

- 去伪控制( Unfalsified Control, UC ) 首先构造一组可能满足性能要求的可行控制器集合基于新数据进行迭代判别是否满足要求。一旦新数据否定目前控制器,则自动切换到新的控制器。用优化算法来缩小可行控制器范围,UC方法实质上是一种切换控制方法

- 惰性学习( Lazy learning,LL ) 学习方法不同,不直接构建一个模型,而是推迟学习过程,等待新的输入数据进来再进行学习和预测性学习方法主要分为两类:近邻方法和核密度估计方法3 近邻方法是根据距离度量选取目标样本附近的一些训练样本进行预测,如K-最近邻算法核密度估计方法是通过某一个样本点所在区域内的训练样本来推测该样本的类别 灵活、高效、可解释性强和容易扩展,尤其适用于具有复杂度高且不规则的问题容易受到噪声数据和样本不平衡问题的影响,需要对数据进行预处理和优化
- 自抗扰控制( Active Disturbance Rejection Control,ADRC ) 扩展状态观测器+非线性控制律+跟踪微分器
- 数据驱动的预测控制( Data-driven predictive control ) 核心思想是通过分析系统的数据,找出系统的动态规律和关联规则,然后预测未来系统的运行状态并采取控制行动。重点在于利用历史数据和实时数据来预测未来的系统行为,并根据该预测结果进行控制

- 数据驱动逆向控制( Data-Driven Inversion-Based Control,D2-IBC ) 使用数据驱动方法构建逆动态模型,然后使用模型预测控制算法解决系统的控制问题主要目的是在控制精度和执行效率之间找到良好的平衡PS:D2-IBC注重控制器的实时反馈控制,而数据驱动的预测控制注重利用数据预测未来的系统行为并实现长期控制。
- 极值搜索控制( Extremum Seeking Control, ESC ) 基于迭代寻优的自适应控制方法,旨在实现最优化控制核心思想是通过寻找控制对象的反馈信号中的极值点,直接估算并实现系统的最优化控制极值搜索控制方法主要包括两个步骤:搜索和调整 通过改变控制器的输入信号以及对控制对象的反馈信号进行采样,进而实现对极值点的搜索在搜索到极值点之后,将其作为反馈控制器的输入信号,进行控制器的调整,以实现最优化控制 具有快速响应、精细控制等优点

- 基于脉冲响应的控制( Pulse response-based control ) 通过分析系统的脉冲响应,建立系统的数学模型,然后根据该模型设计优化控制器使用脉冲信号来激励系统,并测量系统的脉冲响应。通过分析和处理脉冲响应数据,建立系统的传递函数或状态空间模型PS:与工程上应用最多的根据频率响应辨识被控对象传递函数的方法相同,严格来讲不算是数据驱动控制
部分图片来源于互联网,侵删
欢迎关注维信公号:控我所思VS制之以衡,获取更多有用知识!