R语言作为脚本语言,有一套文件系统管理的功能函数,能对文件系统进行操作,包括文件操作和目录操作,相关函数都定义在base包中。
导读:
- 常用数据和文件读写
- 文件系统操作函数概览
- 目录操作
- 文件操作
- 几个特殊的目录
一、常用数据和文件读写
R文件和目录操作功能强大、函数较多,通常只掌握几个常用文件读写命令,实现纯文本、EXCEL(csv格式)和数据框结构数据读写即可。其它功能可通过Windows目录和文件管理系统完成。
#定义文件所在路径
#source("D:\\baiduclouddisk\\source\\R\\sample\\twosam.R")
#folder1 <- "C:\\R\\sample\\"
#folder2 <- "C:\\R\\data\\"
#读入R文件
folder <- "D:\\baiduclouddisk\\source\\R\\sample\\" #定义文件路径
fname <- "twosam.R" #定义文件名称
fpath <- paste(folder,fname,sep="") #连接路径和文件名
source(fpath) #导入R文件
A<-c(1,2,3,4,5)
B<-c(2,4,6,3,7)
twosam(A,B) #调用R文件在的自定义函数
#读入外部数据文件
data <- read.csv("D:\\baiducloudDisk\\source\\R\\data\\data.csv")
data <- read.delim("D:\\baiducloudDisk\\source\\R\\data\\data.txt")
data <- read.table("D:\\baiducloudDisk\\source\\R\\data\\data.txt")
#数据文件保存
df <- data.frame(
Name=c("Alice", "Becka", "James", "Jeffrey", "John"),
Sex=c("F", "F", "M", "M", "M"),
Age=c(13, 13, 12, 13, 12),
Height=c(56.5, 65.3, 57.3, 62.5, 59.0),
Weight=c(84.0, 98.0, 83.0, 84.0, 99.5)
)
write.table(df, file="D:\\baiducloudDisk\\source\\R\\data\\data1.txt")
write.csv(df, file="D:\\baiducloudDisk\\source\\R\\data\\data1.csv")
1、用edit编辑器输入或编辑数据
(1) 编辑向量和列表数据
x <- c(1,2,3) #定义向量变量
xc <- edit(x) #弹出文本编辑器,编辑后退出(参见下图)
print(xc) #输出编辑过的向量
y <- c("a","b","c","d")
oList <- list(x,y) #建立列表
eList <- edit(oList) #同样弹出文本编辑器,编辑后退出(图略)
print(eList) ##输出编辑过的列表
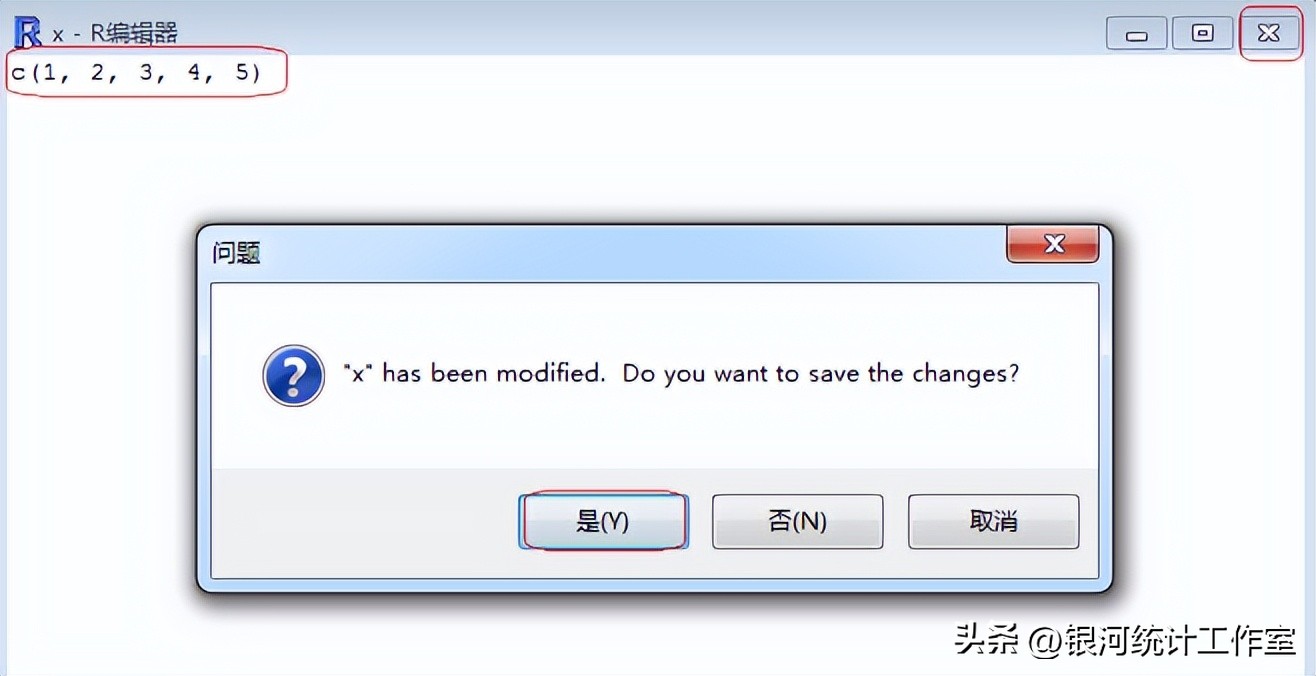
注意:按向量或列表格式编辑文本;点击编辑器右上角“X”按钮;在弹出按钮中按“是(Y)”按钮确认编辑。
(2) 编辑数据框数据
x <- c(1,2,3)
y <- c(5,3,2)
oDF <- data.frame(x,y) #定义数据框,注意向量x、y中元素相等
eDF <- edit(x,y) #弹出表格编辑器,编辑后退出(参见下图)
print(eDF) #输出编辑过的向量
z <- c("a","b","c")
oDF <- data.frame(x,y,z)
eDF <- edit(x,y,z) #表格编辑器z列按因子处理,只能输入"a"、"b"、"c"中之一
print(eDF)
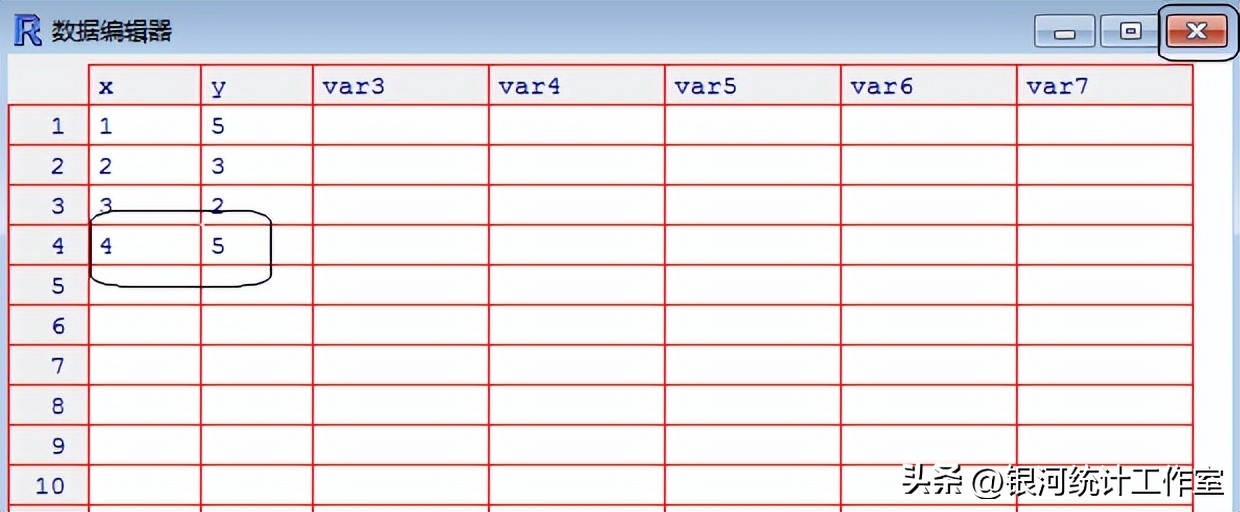
注意:表格编辑器编辑数据;点击编辑器右上角“X”按钮确认编辑。鼠标点击表格编辑器列标题,在弹出菜单中可以重新命名列标题。
2、读R包中的数据
data() #显示可以R包数据集(参见下图)
BOD #输出BOD数据
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8

3、读入EXCEL的csv格式数据
d <- read.csv("E:\\R\\data\\Cars.csv") #按路径和文件名读入csv文件
d <- read.csv("E:\\R\\data\\Cars.csv",head=T,sep=",") #等效
d <- read.table("E:\\R\\data\\Cars.csv",head=T,sep=",") #等效
#数据集有中文防止出现乱码
d <- read.csv('E:\\R\\data\\Cars.csv',fileEncoding='utf-8')
d <- read.csv('E:\\R\\data\\Cars.csv',nrows=10) #读取前10行数据,无header
d <- read.csv('E:\\R\\data\\Cars.csv',nrows=10,skip=2) #跳过前两行,无header
#指示每一列的数据类型
#读取网站服务器上的csv数据
d <- read.csv("http://www.galaxystatistics.com/R/data/Cars.csv")
d <- read.csv('E:\\R\\data\\Cars.csv',colClasses=list('integer','factor'))
> lines <- length(readLines('E:\\R\\data\\Cars.csv')) #获得数据行数,包括标题
lines
[1] 51
d #输出数据
speed dist
1 4 2
2 4 10
3 7 4
4 7 22
5 8 16
6 9 10
7 10 18
8 10 26
9 10 34
10 11 17
d$speed #按列表输出第一列数据(向量)
[1] 4 4 7 7 8 9 10 10 10 11
注意:读入外部数据尽量先用EXCEL编辑数据,并把数据存储在sheet1表中。对于扩展名为.xls和.xlsx的EXCEL文件应先另存为.csv文本格式。读入文档是注意路径的不要出错
Cars.csv文档如下图:
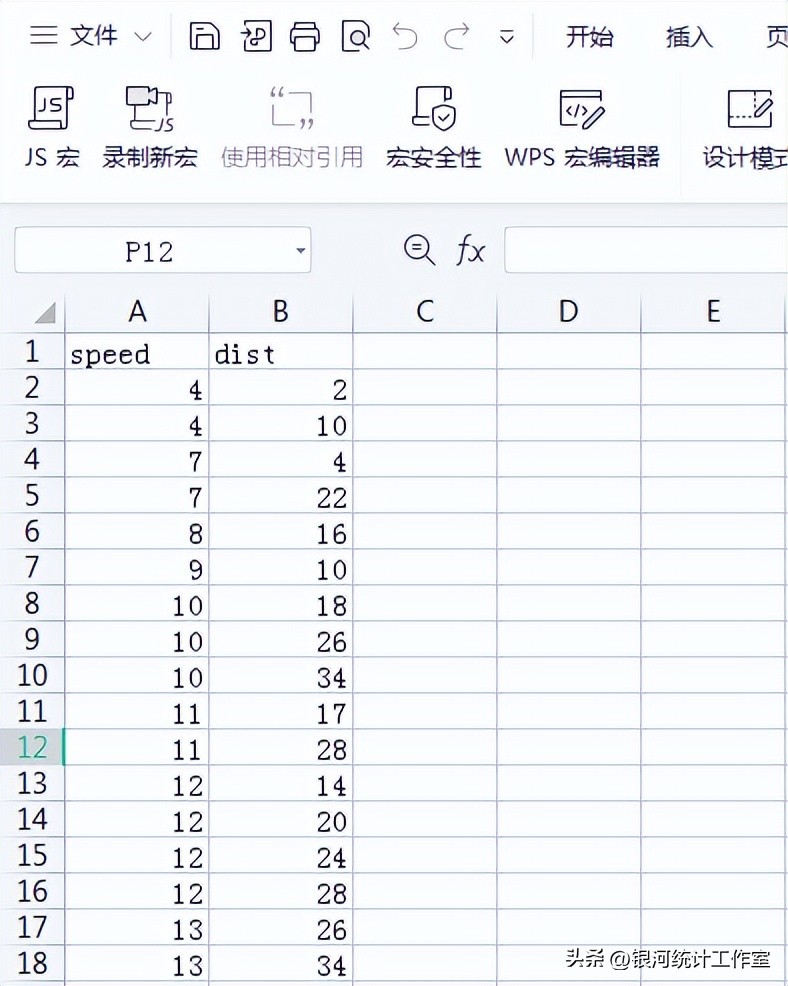
4、读入txt格式数据
已保存的txt文本文件如下:
Name Sex Age Height Weight
Alice F 13 56.5 84
Becka F 13 65.3 98
James M 12 57.3 83
Jeffrey M 13 62.5 84
John M 12 59 99.5
在R窗口代码如下:
data <- read.table("E:\\R\\data\\data.txt") #按路径和文件名读入txt格式数据
data <- read.delim("E:\\R\\data\\data.txt") #等效
data <- read.csv("E:\\R\\data\\data.txt") #等效
#读取网站服务器上的txt数据
data <- read.csv("http://www.galaxystatistics.com/R/data/data.txt")
data
Name Sex Age Height Weight
1 Alice F 13 56.5 84.0
2 Becka F 13 65.3 98.0
3 James M 12 57.3 83.0
4 Jeffrey M 13 62.5 84.0
5 John M 12 59.0 99.5
注意:读入外部txt格式数据前,文本文件应按ANSI编码保存
5、用scan函数导入数据
当数据量较大时,用scan函数导入数据效率更高。
R代码如下:
#读入txt文件
d <- scan("http://www.galaxystatistics.com/R/data/data.txt",what="")
Read 30 items
d
[1] "Name" "Sex" "Age" "Height" "Weight" "Alice" "F" "13" "56.5" "84" "Becka"
[12] "F" "13" "65.3" "98" "James" "M" "12" "57.3" "83" "Jeffrey" "M"
[23] "13" "62.5" "84" "John" "M" "12" "59" "99.5"
#将下列转换为矩阵
d <- matrix(d,ncol=5,byrow=T)
d
[,1] [,2] [,3] [,4] [,5]
[1,] "Name" "Sex" "Age" "Height" "Weight"
[2,] "Alice" "F" "13" "56.5" "84"
[3,] "Becka" "F" "13" "65.3" "98"
[4,] "James" "M" "12" "57.3" "83"
[5,] "Jeffrey" "M" "13" "62.5" "84"
[6,] "John" "M" "12" "59" "99.5"
#去除标题
d <- d[2:6,]
d
[,1] [,2] [,3] [,4] [,5]
[1,] "Alice" "F" "13" "56.5" "84"
[2,] "Becka" "F" "13" "65.3" "98"
[3,] "James" "M" "12" "57.3" "83"
[4,] "Jeffrey" "M" "13" "62.5" "84"
[5,] "John" "M" "12" "59" "99.5"
#读入csv文件,sep=","为按逗号分隔符读入,数据结构为向量
d <- scan("http://www.galaxystatistics.com/R/data/Cars.csv",what="",sep=",")
#数据结构为列表
d <- scan("http://www.galaxystatistics.com/R/data/Cars.csv",what=list("speed","dist"),sep=",")
#跳过标题读取数据,Skip从第几行开始读入数据
d <- scan("http://www.galaxystatistics.com/R/data/Cars.csv",what=list("speed","dist"),sep=",",skip=1)
#nlines指定最大读入行数
d <- scan("http://www.galaxystatistics.com/R/data/Cars.csv",what=list("speed","dist"),sep=",",skip=1,nlines=10)
6、导入R代码
编好的R代码可以保存为文件(一般扩展名为.R),使用时以外部文件数据方式导入即可。设有保存在data_outline.R文本文件中的自编(采用统计指标)R代码如下:
data_outline <- function(x){
n <- length(x) #样本量
m <- mean(x) #均值
v <- var(x) #方差
s <- sd(x) #标准差
me <- median(x) #中位数
cv <- 100*s/m #相对误差百分比
css <- sum((x-m)^2) #二阶中心动差
uss <- sum(x^2) #二阶动差
R <- max(x)-min(x) #全距
R1 <- quantile(x,3/4)-quantile(x,1/4) #四分位差
sm <- s/sqrt(n) #均值标准差
g1 <- n/((n-1)*(n-2))*sum((x-m)^3)/s^3 #偏态系数(偏度)
g2 <- ((n*(n+1))/((n-1)*(n-2)*(n-3))*sum((x-m)^4)/s^4-(3*(n-1)^2)/((n-2)*(n-3)))
#峰态系数(峰度)
df <- data.frame(N=n, Mean=m, Var=v, std_dev=s,
Median=me, std_mean=sm, CV=cv, CSS=css, USS=uss,
R=R, R1=R1, Skewness=g1, Kurtosis=g2, row.names=1) #将统计指标合并为数据框输出
}
在R窗口输入代码导入R文件data_outline.R、并调用自编函数。代码如下:
source("E:R\\sample\\data_outline.R") #导入R文件
x <- c(1,3,2,4,6,7,9,3,2,6) #输入统计样本
v <- data_outline(x) #调用自编函数计算样本指标
print(v) #以数据框形式输出指标
N Mean Var std_dev Median std_mean CV CSS USS R R1
1 10 4.3 6.677778 2.58414 3.5 0.8171767 60.09627 60.1 245 8 3.75
Skewness Kurtosis
1 0.5524549 -0.726754
v$Median #输出个别指标(中位数)
[1] 3.5
注意:读入外部txt格式数据前,文本文件应按ANSI编码保存
7、数据存储
x <- c(1,3,4,5,6)
y <- c('a','b','f','g','m')
z <- list(x,y) #将向量为定义列表
names(z) <- c("A_n","B_c") #列表命名
#存储列表数据,注意同名文件将被覆盖
write.table(z,file="E:\\R\\data\\test.txt")
#数据存储时无需列标题和行标题
write.table(z,file="E:\\R\\data\\test.txt",row.names=FALSE,col.names=FALSE)
#数据存储时保存列标题,不需要行标题
write.table(z,file="E:\\R\\data\\test.txt",row.names=FALSE,col.names=TRUE)
#write.csv文件存储和write.table类似
write.csv(z,file="E:\\R\\data\\test.csv")
二、文件系统操作函数概览
1、文件操作
- dir.create: 新建一个文件夹
- list.dirs: 显示目录下的文件夹
- list.files: 显示目录下的文档
- file.create: 文档创建
- file.exists: 判断文档是否存在
- file.remove: 文档删除
- file.rename: 重命名
- file.append: 文档添加
- file.copy: 文档复制
- file.symlink(file1,file2): 软连接
- file.link(file1,file2): 硬连接
- file.show: 显示文档内容
- file.info: 显示文档信息
- file.edit: 编辑文档
- zip: 压缩文件
- unzip: 解压缩文件
2、相关命令简介
- rm(list=ls()): 表示清除R工作环境中的全部东西
- setwd(path): 按路径设置目录
- cat("file A\n", file="A"): 创建一个文件A,文件内容是'file A','\n'表示换行,这是一个很好的习惯
- cat("file B\n", file="B"): 创建一个文件B
- file.append("A","B"): 将文件B的内容附到A内容的后面,注意没有空行
- file.create("A"): 创建一个文件A, 注意会覆盖原来的文件
- file.append("A",rep("B",10)): 将文件B的内容复制10便,并先后附到文件A内容后
- file.show("A"): 新开工作窗口显示文件A的内容
- file.copy("A", "C"): 复制文件A保存为C文件,同一个文件夹
- dir.create("tmp"): 创建名为tmp的文件夹
- file.copy(c("A","B"),"tmp"): 将文件夹拷贝到tmp文件夹中
- list.files("tmp"): 查看文件夹tmp中的文件名
- unlink("tmp",recursive=F): 如果文件夹tmp为空,删除文件夹tmp
- unlink("tmp",recursive=TRUE): 删除文件夹tmp,如果其中有文件一并删除
- file.remove("A","B","C"): 移除三个文件
三、目录操作
1、查看目录
# 当前的目录
getwd()
[1] "C:/Users/abdata/Desktop/get_pm_data"
# 查看当前目录的子目录
list.dirs()
[1] "." "./test"
# 查看当前目录的子目录和文件。
dir()
[1] "pm_2014_1.RData" "pm_2014_10.RData"
[3] "pm_2014_11.RData" "pm_2014_12.RData"
[5] "test"
# 查看指定目录的子目录和文件。
dir(path="C:/Users/abdata/Desktop/get_pm_data/test")
[1] "test.txt" "test_test"
# 只列出以'pm_2014'开头的子目录或文件
dir(path="C:/Users/abdata/Desktop/get_pm_data", pattern='^pm_2014')
[1] "pm_2014_1.RData" "pm_2014_10.RData"
[3] "pm_2014_11.RData" "pm_2014_12.RData"
[5] "pm_2014_2.RData" "pm_2014_3.RData"
# 列出目录下所有的目录和文件,包括隐藏文件。
dir(path="C:/Users/abdata/Desktop/get_pm_data",all.files=TRUE)
[1] "." ".."
[3] "pm_2014_1.RData" "pm_2014_10.RData"
[5] "pm_2014_11.RData" "pm_2014_12.RData"
[7] "test"
# 查看当前目录的子目录和文件,同dir()函数。
list.files()
[1] "pm_2014_1.RData" "pm_2014_10.RData"
[3] "pm_2014_11.RData" "pm_2014_12.RData"
[5] "test"
list.files(".",all.files=TRUE)
# 查看当前目录权限
file.info(".")
size isdir mode mtime ctime
. 0 TRUE 777 2026-03-18T19:57:19+00:00 2026-03-18T19:57:19+00:00
atime exe
. 2026-03-18T19:57:19+00:00 no
# 查看指定目录权限
file.info("./test")
size isdir mode mtime
./test 0 TRUE 777 2026-03-18T19:57:19+00:00
ctime atime exe
./test 2026-03-18T19:57:19+00:00 2026-03-18T19:57:19+00:00 no
2、创建目录
# 在当前目录下,新建一个目录
dir.create("/test/test1")
# 指定目录下,创建新目录
dir.create("C:/Users/abdata/Desktop/get_pm_data/test/test1")
list.dirs()
[1] "." "./test" "./test/test_test"
[4] "./test/test1" "./test2"
# 创建一个3级子目录./test1/test1_1/test1_2
# 直接创建,出错(win和linux目录路径写法不同)
dir.create(path="/test1/test1_1/test1_2") 或 dir.create(path="./test1/test1_1/test1_2")
# 递归创建,成功
dir.create(path="./test1/test1_1/test1_2",recursive = TRUE)
list.dirs()
[1] "." "./test"
[3] "./test/test_test" "./test/test1"
[5] "./test1" "./test1/test1_1"
[7] "./test1/test1_1/test1_2" "./test2"
# 通过系统命令查看目录结构
system("tree")
卷 系统 的文件夹 PATH 列表
卷序列号为 00000034 E6A9:F9BA
C:.
├─test
│ ├─test1
│ └─test_test
├─test1
│ └─test1_1
│ └─test1_2
└─test2
3、检查目录是否存在
# 目录存在
file.exists(".")
[1] TRUE
file.exists("./test/test1")
[1] TRUE
# 目录不存在
file.exists("./test3")
[1] FALSE
4、检查和修改目录的权限
df<-dir(full.names = TRUE)
# 检查文件或目录是否存在,mode=0。
file.access(df, 0) == 0
./pm_2016_7.RData ./pm_2016_8.RData ./pm_2016_9.RData
TRUE TRUE TRUE
./test ./test1 ./test2
TRUE TRUE TRUE
# 检查文件或目录是否可执行,mode=1,目录为可以执行
file.access(df, 1) == 0
./pm_2016_7.RData ./pm_2016_8.RData ./pm_2016_9.RData
FALSE FALSE FALSE
./test ./test1 ./test2
TRUE TRUE TRUE
# 检查文件或目录是否可写,mode=2。
file.access(df, 2) == 0
./pm_2016_7.RData ./pm_2016_8.RData ./pm_2016_9.RData
TRUE TRUE TRUE
./test ./test1 ./test2
TRUE TRUE TRUE
# 检查文件或目录是否可读,mode=4。
file.access(df, 4) == 0
./pm_2016_7.RData ./pm_2016_8.RData ./pm_2016_9.RData
TRUE TRUE TRUE
./test ./test1 ./test2
TRUE TRUE TRUE
# 修改目录权限,所有用户只读(linux-?)
Sys.chmod("./test", mode = "0555", use_umask = TRUE)
# 查看目录完整信息,mode=555
file.info("./test")
# create目录不可以写
file.access(df, 2) == 0
5、对目录重命名
# 对test目录重命名
file.rename("test", "tmp")
[1] TRUE
# 查看目录
dir()
[1] "pm_2014_1.RData" "pm_2014_10.RData" "pm_2014_11.RData"
[4] "tmp" "test1" "test2"
6、删除目录
# 删除tmp目录
unlink("tmp", recursive = TRUE)
# 查看目录
dir()
[1] "pm_2014_1.RData" "pm_2014_10.RData" "pm_2014_11.RData"
[4] "test1" "test2"
7、拼接目录字符串
# 拼接目录字符串
file.path("test1","test1_1","test1")
[1] "test1/test1_1/test1"
dir(file.path("test1","test1_1"))
[1] "test1_2"
8、获取最底层的子目录名
# 当前目录
getwd()
[1] "C:/Users/abdata/Desktop/get_pm_data"
# 最底层子目录
dirname("C:/Users/abdata/Desktop/get_pm_data/test1/test1_1/test1_2/abdata.txt")
[1] "C:/Users/abdata/Desktop/get_pm_data/test1/test1_1/test1_2"
# 最底层子目录或文件名
basename(getwd())
[1] "get_pm_data"
basename("C:/Users/abdata/Desktop/get_pm_data/test1/test1_1/test1_2/abdata.txt")
[1] "abdata.txt"
9、 转换文件扩展路径
# 转换~为用户目录
path.expand("~/tmp")
[1] "C:/Users/abdata/Documents/tmp"
10、 标准化路径,用来转换win或linux的路径分隔符
# linux
normalizePath(c(R.home(), tempdir()))
[1] "C:\\Program Files\\R\\R-3.2.0"
[2] "C:\\Users\\abdata\\AppData\\Local\\Temp\\Rtmp8S0U8a"
# win
normalizePath(c(R.home(), tempdir()))
[1] "C:\\Program Files\\R\\R-3.2.0"
[2] "C:\\Users\\abdata\\AppData\\Local\\Temp\\Rtmp8S0U8a"
# 短路径,缩减路径的显示长度,只在win中运行。
# win
shortPathName(c(R.home(), tempdir()))
[1] "C:\\PROGRA~1\\R\\R-32~1.0"
[2] "C:\\Users\\abdata\\AppData\\Local\\Temp\\RTMP8S~1"
四、文件操作
1、 查看文件
# 查看当前目录的子目录和文件。
dir()
[1] "abdata.txt" "pm_2014_1.RData" "pm_2014_10.RData"
[4] "pm_2014_11.RData" "pm_2014_12.RData" "pm_2014_2.RData"
[7] "test1" "test2" "tmp"
# 检查文件是否存在
file.exists("pm_2014_1.RData")
[1] TRUE
# 文件不存在
file.exists("pm_2014_1.RData111")
[1] FALSE
# 查看文件完整信息
file.info("pm_2014_1.RData")
size isdir mode mtime
pm_2014_1.RData 66346 FALSE 666 2026-03-18T19:57:19+00:00
ctime atime exe
pm_2014_1.RData 2026-03-18T19:57:19+00:00 2026-03-18T19:57:19+00:00 no
# 查看文件访问权限,存在
file.access("pm_2014_1.RData",0)
pm_2014_1.RData
0
# 不可执行
file.access("pm_2014_1.RData",1)
pm_2014_1.RData
-1
# 可写
file.access("pm_2014_1.RData",2)
pm_2014_1.RData
0
# 可读
file.access("pm_2014_1.RData",4)
pm_2014_1.RData
0
# 查看一个不存在的文件访问权限,不存在
file.access("pm_2014_1.RData111")
pm_2014_1.RData111
-1
2、 判断是文件还是目录
# 判断是否是目录
file_test("-d", "pm_2014_1.RData")
[1] FALSE
file_test("-d", "test1")
[1] TRUE
# 判断是否是文件
file_test("-f", "pm_2014_1.RData")
[1] TRUE
file_test("-f", "test1")
[1] FALSE
3、 创建文件
# 创建一个空文件 A.txt
file.create("A.txt")
[1] TRUE
# 创建一个有内容的文件 B.txt
cat("file B\n", file = "B.txt")
dir()
[1] "A.txt" "B.txt" "create" "readme.txt"
# 打印A.txt
readLines("A.txt")
character(0)
# 打印B.txt
readLines("B.txt")
[1] "file B"
4、 把文件B.txt的内容,合并到 A.txt
# 合并文件
file.append("A.txt", rep("B.txt", 10))
[1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
# 查看文件内容
readLines("A.txt")
[1] "file B" "file B" "file B" "file B" "file B" "file B" "file B" "file B" "file B" "file B"
5、 把文件A.txt复制到文件C.txt
# 复制文件
file.copy("A.txt", "C.txt")
[1] TRUE
# 查看文件内容
readLines("C.txt")
[1] "file B" "file B" "file B" "file B" "file B" "file B" "file B" "file B" "file B" "file B"
6、 修改文件权限
# 修改文件权限,创建者可读可写可执行,其他人无权限
Sys.chmod("A.txt", mode = "0700", use_umask = TRUE)
# 查看文件信息
file.info("A.txt")
size isdir mode mtime ctime atime uid gid uname grname
A.txt 70 FALSE 700 2026-03-18T19:57:19+00:00 2026-03-18T19:57:19+00:00 2026-03-18T19:57:19+00:00 1000 1000 conan conan
7、文件重命名
# 给文件A.txt重命名为AA.txt
file.rename("A.txt","AA.txt")
[1] TRUE
dir()
[1] "AA.txt" "B.txt" "create" "C.txt" "readme.txt"
8、 硬连接和软连接
硬连接,指通过索引节点来进行连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件真正删除的条件是与之相关的所有硬连接文件均被删除。
软连接,也叫符号连接(Symbolic Link)。软链接文件有类似于Windows的快捷方式。它实际上是一个特殊的文件。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。硬连接和软连接,只在Linux系统中使用。
# 硬连接
file.link("readme.txt", "hard_link.txt")
[1] TRUE
# 软连接
file.symlink("readme.txt", "soft_link.txt")
[1] TRUE
# 查看文件目录
system("ls -l")
-rwx------ 1 conan conan 70 Nov 14 12:55 AA.txt
-rw-rw-r-- 1 conan conan 7 Nov 14 12:51 B.txt
dr-xr-xr-x 2 conan conan 4096 Nov 14 08:36 create
-rw-rw-r-- 1 conan conan 70 Nov 14 12:56 C.txt
-rw-rw-r-- 2 conan conan 7 Nov 14 08:24 hard_link.txt
-rw-rw-r-- 2 conan conan 7 Nov 14 08:24 readme.txt
lrwxrwxrwx 1 conan conan 10 Nov 14 13:11 soft_link.txt -> readme.txt
文件hard_link.txt是文件readme.txt硬连接文件,文件soft_link.txt是文件readme.txt软连接文件。
9、 删除文件
# 有两个函数可以使用file.remove和unlink,其中unlink函数使用同删除目录操作是一样的。
# 删除文件
file.remove("A.txt", "B.txt", "C.txt")
[1] FALSE TRUE TRUE
# 删除文件
unlink("readme.txt")
# 查看目录文件
system("ls -l")
total 12
-rwx------ 1 conan conan 70 Nov 14 12:55 AA.txt
dr-xr-xr-x 2 conan conan 4096 Nov 14 08:36 create
-rw-rw-r-- 1 conan conan 7 Nov 14 08:24 hard_link.txt
lrwxrwxrwx 1 conan conan 10 Nov 14 13:11 soft_link.txt -> readme.txt
# 打印硬连接文件
readLines("hard_link.txt")
[1] "file A"
# 打印软连接文件,soft_link.txt,由于原文件被删除,有错误
readLines("soft_link.txt")
Error in file(con, "r") : cannot open the connection
In addition: Warning message:
In file(con, "r") :
cannot open file 'soft_link.txt': No such file or directory
五、几个特殊的目录
- R.home() 查看R软件的相关目录
- Library 查看R核心包的目录
- Library.site 查看R核心包的目录和root用户安装包目录
- libPaths() 查看R所有包的存放目录
- system.file() 查看指定包所在的目录
1、R.home() 查看R软件的相关目录
# 打印R软件安装目录
R.home()
[1] "/usr/lib/R"
# 打印R软件bin的目录
R.home(component="bin")
[1] "/usr/lib/R/bin"
# 打印R软件文件的目录
R.home(component="doc")
[1] "/usr/share/R/doc"
通过系统命令,找到R文件的位置。
# 检查系统中R文件的位置
~ whereis R
R: /usr/bin/R /etc/R /usr/lib/R /usr/bin/X11/R /usr/local/lib/R /usr/share/R /usr/share/man/man1/R.1.gz
# 打印环境变量R_HOME
~ echo $R_HOME
/usr/lib/R
通过R.home()函数,我们可以很容易的定位R软件的目录。
2、R软件的包目录
# 打印核心包的目录
.Library
[1] "/usr/lib/R/library"
# 打印核心包的目录和root用户安装包目录
.Library.site
[1] "/usr/local/lib/R/site-library" "/usr/lib/R/site-library"
[3] "/usr/lib/R/library"
# 打印所有包的存放目录
.libPaths()
[1] "/home/conan/R/x86_64-pc-linux-gnu-library/3.0"
[2] "/usr/local/lib/R/site-library"
[3] "/usr/lib/R/site-library"
[4] "/usr/lib/R/library"
3、查看指定包所在的目录
# base包的存放目录
system.file()
[1] "C:/PROGRA~1/R/R-32~1.0/library/base"
# pryr包的存放目录
system.file(package = "pryr")
[1] "C:/Users/abdata/Documents/R/win-library/3.2/pryr"
计算机的文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易,文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备使用数据块的概念。用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名。在写入新数据之前,用户不必关心硬盘上的那个块地址没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。