[TOC]
# 一、[uptime](https://man.linuxde.net/uptime) —— 查看系统负载均衡
>作用:快速查看系统总共运行了多长时间和系统的平均负载
**语法**
> uptime(选项)
**选项**
> -V:显示指令的版本信息。
**实例**
使用`uptime`命令查看系统负载:
> [root@LinServ-1 ~]# uptime -V #显示uptime命令版本信息
> procps version 3.2.7
>
> [root@LinServ-1 ~]# uptime
> 15:31:30 up 127 days, 3:00, 1 user, load average: 0.00, 0.00, 0.00
显示内容说明:
```
15:31:30 // 系统当前时间
up 127 days, 3:00 // 主机已运行时间,时间越大,说明你的机器越稳定。
1 user // 用户连接数,是总连接数而不是用户数
load average: 0.00, 0.00, 0.00 // 系统平均负载,统计最近1,5,15分钟的系统平均负载
```
通过average的这三个数据,可以了解服务器负载是在趋于紧张还是趋于缓解。
如果1分钟平均负载很高,而15分钟平均负载很低,说明服务器正在命令高负载情况,需要进一步排查CPU资源都消耗在了哪里。反之,如果15分钟平均负载很高,1分钟平均负载较低,则有可能是CPU资源紧张时刻已经过去。
**实例2**

上面例子中的输出,可以看见最近1分钟的平均负载非常高,且远高于最近15分钟负载,因此我们需要继续排查当前系统中有什么进程消耗了大量的资源。可以通过下文将会介绍的vmstat、mpstat等命令进一步排查。
# 二、dmesg —— 帮助排查性能问题
> 作用:用于检查和控制内核的环形缓冲区。
> 注:kernel会将开机信息存储在ring buffer中。您若是开机时来不及查看信息,可利用dmesg来查看。开机信息保存在`/var/log/dmesg`文件里
**语法**
> dmesg(选项)
**选项**
> -c:显示信息后,清除ring buffer中的内容;
> -s<缓冲区大小>:预设置为8196,刚好等于ring buffer的大小;
> -n:设置记录信息的层级。
**实例**
> [root@localhost ~]# dmesg | head
> Linux version 2.6.18-348.6.1.el5 (mockbuild@builder17.centos.org) (gcc version > 4.1.2 20080704 (Red Hat 4.1.2-54)) #1 SMP Tue May 21 15:34:22 EDT 2013
> BIOS-provided physical RAM map:
> BIOS-e820: 0000000000010000 - 000000000009f400 (usable)
> BIOS-e820: 000000000009f400 - 00000000000a0000 (reserved)
> BIOS-e820: 00000000000f0000 - 0000000000100000 (reserved)
> BIOS-e820: 0000000000100000 - 000000007f590000 (usable)
> BIOS-e820: 000000007f590000 - 000000007f5e3000 (ACPI NVS)
> BIOS-e820: 000000007f5e3000 - 000000007f5f0000 (ACPI data)
> BIOS-e820: 000000007f5f0000 - 000000007f600000 (reserved)
> BIOS-e820: 00000000e0000000 - 00000000e8000000 (reserved)
**实例2**
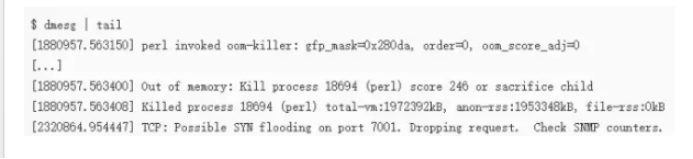
该命令会输出系统日志的最后10行。示例中的输出,可以看见一次内核的oom kill和一次TCP丢包。这些日志可以帮助排查性能问题。千万不要忘了这一步。
# 三、vmstat —— 了解系统状态
> 作用:显示虚拟内存状态,并且它可以报告关于进程、内存、I/O等系统整体运行状态。
**语法**
> vmstat(选项)(参数)
**选项**
> -a:显示活动内页;
> -f:显示启动后创建的进程总数;
> -m:显示slab信息;
> -n:头信息仅显示一次;
> -s:以表格方式显示事件计数器和内存状态;
> -d:报告磁盘状态;
> -p:显示指定的硬盘分区状态;
> -S:输出信息的单位。
**参数**
- 事件间隔:状态信息刷新的时间间隔;
- 次数:显示报告的次数。
**实例**
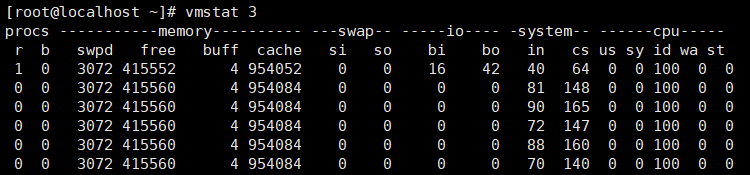
字段说明:
```
Procs(进程)
- r: 等待在CPU资源的进程数,这个值也可以判断是否需要增加CPU。(长期大于1)
注意:这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和。
- b: 等待IO的进程数量。
Memory(内存)
- swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
- free: 系统可用内存数。(以千字节为单位)
注意:如果剩余内存不足,也会导致系统性能问题。下文介绍到的free命令,可以更详细的了解系统内存的使用情况。
- buff: 用作缓冲的内存大小。
- cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap
- si: 每秒从交换区写到内存的大小,由磁盘调入内存。(写入)
- so: 每秒写入交换区的内存大小,由内存调入磁盘。(读取)
注意:如果这个数据不为0,说明系统已经在使用交换区(swap),机器物理内存已经不足。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(现在的Linux版本块的大小为1kb)
- bi: 每秒读取的块数
- bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
- in: 每秒中断数,包括时钟中断。
- cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示)
- us: 用户进程执行时间百分比(user time)
注意: us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
- sy: 内核系统进程执行时间百分比(system time)
注意:sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
- id: 空闲时间百分比
- wa: IO等待时间百分比 (IO等待时间(wait))
注意:wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
- st: 被偷走的时间(stolen,一般被其他虚拟机消耗)
```
上述这些CPU时间,可以让我们很快了解CPU是否出于繁忙状态。一般情况下,如果用户时间和系统时间相加非常大,CPU出于忙于执行指令。如果IO等待时间很长,那么系统的瓶颈可能在磁盘IO。
# 四、[mpstat](https://man.linuxde.net/mpstat) —— 显示每个CPU占用情况
> 作用:主要用于多CPU环境下,它显示各个可用CPU的状态系你想。
> 注:这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
**语法**
> mpstat(选项)(参数)
**选项**
> -P:指定CPU编号。
**参数**
- 间隔时间:每次报告的间隔时间(秒);
- 次数:显示报告的次数。
**安装命令**
```
yum install sysstat
```
> 注:`mpstat`并不是linux自带的命令,而是`sysstat`性能监控工具集的一个子集,因此要想使用必须安装`sysstat`
**实例**
当mpstat不带参数时,输出为从系统启动以来的平均值。

**每2秒产生了2个处理器的统计数据报告:**
下面的命令可以每2秒产生了2个处理器的统计数据报告,一共产生三个interval 的信息,然后再给出这三个interval的平均信息。默认时,输出是按照CPU 号排序。第一个行给出了从系统引导以来的所有活跃数据。接下来每行对应一个处理器的活跃状态。。

> 注:`mpstat`命令可以显示每个CPU的占用情况,如果有一个CPU占用率特别高,那么有可能是一个单线程应用程序引起的。
# 五、pidstat —— 监控进程占用的系统资源
> 作用:用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
**语法**
> pidstat(选项)(时间间隔)(次数)
**参数**
```
-C comm #只显示那些包含字符串(可是正则表达式)comm的命令的名字
-d #显示I/O统计信息(须内核2.6.20及以后)
PID #进程号
kB_rd/s #每秒此进程从磁盘读取的千字节数
kB_wr/s #此进程已经或者将要写入磁盘的每秒千字节数
kB_ccwr/s #由任务取消的写入磁盘的千字节数
Command #命令的名字
-h #显示所有的活动的任务
-I #在SMP环境,指出任务的CPU使用(等同于选项-u)应该被除于cpu的总数
-l #显示进程的命令名和它的参数
-p { pid [,...] | SELF | ALL }#指定线程显示其报告
-r #显示分页错误的内存利用率
When reporting statistics for individual tasks, the following values are displayed:
PID #进程号
minflt/s #每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数
majflt/s #每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生
VSZ #该进程使用的虚拟内存(以kB为单位)
RSS #该进程使用的物理内存(以kB为单位)
%MEM #当前任务使用的有效内存的百分比
Command #任务的命令名
When reporting global statistics for tasks and all their children, the following values are displayed:
PID #PID号
minflt-nr #在指定的时间间隔内收集的进程和其子进程的次缺页错误次数
majflt-nr #在指定的时间间隔内收集的进程和其子进程的主缺页错误次数
Command #命令名
-s #堆栈的使用
-t #显示与所选任务相关的线程的统计数据
-T { TASK | CHILD | ALL } #指定必须监测的内容:TASK是默认的,单个任务的报告;CHILD:指定的进程和他们的子进程的全局报告,ALL:相当于TASK和CHILD
-u #报告CPU使用
When reporting statistics for individual tasks, the following values are displayed:
PID
%usr #用户层任务正在使用的CPU百分比(with or without nice priority ,NOT include time spent running a virtual processor)
%system #系统层正在执行的任务的CPU使用百分比
%guest #运行虚拟机的CPU占用百分比
%CPU #所有的使用的CPU的时间百分比
CPU #处理器数量
Command #命令
When reporting global statistics for tasks and all their children, the following values are displayed:
PID #PID号
usr-ms #在指定时间内收集的在用户层执行的进程和它的子进程占用的CPU时间(毫秒){with or without nice priority,NOT include time spent running a virtual processor)
system-ms #在指定时间内收集的在系统层执行的进程和它的子进程占用的CPU时间(毫秒)
guest-ms #花在虚拟机上的时间
Command #命令
-V #版本号
-w #报告任务切换情况
PID #PID号
cswch/s #每秒自动上下文切换
nvcswch/s #每秒非自愿的上下文切换
Command #命令
```
**实例1**
查看系统启动后所有活动进程的cpu统计信息

**实例2**
pidstat命令指定采样周期和采样次数,命令形式为”pidstat [option] interval [count]”
以下pidstat输出以2秒为采样周期,输出10次cpu使用统计信息:
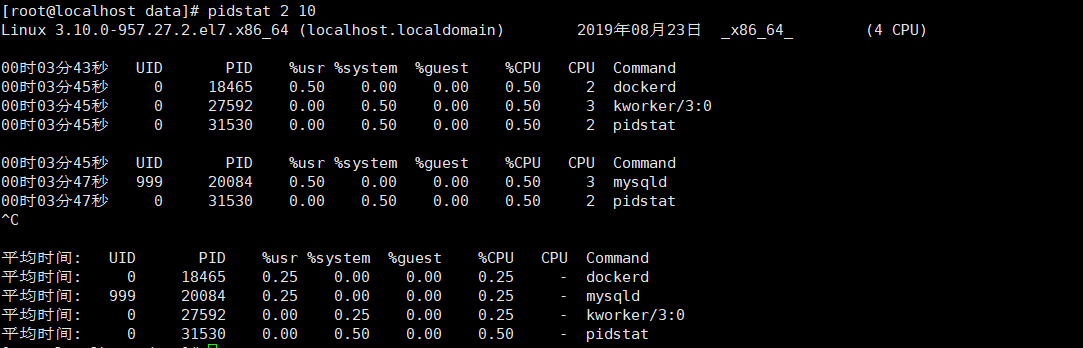
**实例3**
pidstat将显示某活动进程的内存使用统计:

**实例4**
查看进程IO的统计信息:

> 注:pidstat命令输出进程的CPU占用率,该命令会持续输出,并且不会覆盖之前的数据,可以方便观察系统动态。
# 六、[iostat](https://man.linuxde.net/iostat) —— 监视系统IO和CPU使用情况
> 作用:用于监视系统输入输出设备和CPU的使用情况。
**语法**
> iostat(选项)(参数)
**选项**
> -c:仅显示CPU使用情况;
> -d:仅显示设备利用率;
> -k:显示状态以千字节每秒为单位,而不使用块每秒;
> -m:显示状态以兆字节每秒为单位;
> -p:仅显示块设备和所有被使用的其他分区的状态;
> -t:显示每个报告产生时的时间;
> -V:显示版号并退出;
> -x:显示扩展状态。
**参数**
- 间隔时间:每次报告的间隔时间(秒);
- 次数:显示报告的次数。
**实例**
用`iostat -x /dev/sda1`来观看磁盘I/O的详细情况:

详细说明:第一行是系统信息和监测时间,第二行和第三行显示CPU使用情况(具体内容和mpstat命令相同)。这里主要关注后面I/O输出的信息,如下所示:
**重点讲解**
r/s, w/s, rkB/s, wkB/s这几个参数,它们表示每秒读写次数和每秒读写数据量(千字节)。如果读写量过大,可能会引起性能问题。
await:IO操作的平均等待时间,单位是毫秒。这是应用程序在和磁盘交互时,需要消耗的时间,包括IO等待和实际操作的耗时。如果这个数值过大,可能是硬件设备遇到了瓶颈或者出现故障。
avgqu-sz:向设备发出的请求平均数量。如果这个数值大于1,可能是硬件设备已经饱和(部分前端硬件设备支持并行写入)。
%util:设备利用率。这个数值表示设备的繁忙程度,经验值是如果超过60,可能会影响IO性能(可以参照IO操作平均等待时间)。如果到达100%,说明硬件设备已经饱和。
如果显示的是逻辑设备的数据,那么设备利用率不代表后端实际的硬件设备已经饱和。值得注意的是,即使IO性能不理想,也不一定意味这应用程序性能会不好,可以利用诸如预读取、写缓存等策略提升应用性能。
# 七、free ———— 查看系统内存
> 作用:显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
**语法**
> free(选项)
> -b:以Byte为单位显示内存使用情况;
> -k:以KB为单位显示内存使用情况;
> -m:以MB为单位显示内存使用情况;
> -o:不显示缓冲区调节列;
> -s<间隔秒数>:持续观察内存使用状况;
> -t:显示内存总和列;
> -V:显示版本信息。
**实例**

**第一部分Mem行解释:**
> total:内存总数;
> used:已经使用的内存数;
> free:空闲的内存数;
> shared:当前已经废弃不用;
> buffers Buffer:缓存内存数;
> cached Page:缓存内存数。
关系:total = used + free
**第二部分(-/+ buffers/cache)解释:**
> (-buffers/cache) used内存数:第一部分Mem行中的 used – buffers – cached
> (+buffers/cache) free内存数: 第一部分Mem行中的 free + buffers + cached
**解析**
> 需要注意的是:
>
> 第二行-/+ buffers/cache,看上去缓存占用了大量内存空间。
>
> 这是Linux系统的内存使用策略,尽可能的利用内存,如果应用程序需要内存,这部分内存会立即被回收并分配给应用程序。因此,这部分内存一般也被当成是可用内存。
>
> 如果可用内存非常少,系统可能会动用交换区(如果配置了的话),这样会增加IO开销(可以在iostat命令中体现),降低系统性能。
# 八、[sar](http://linux.51yip.com/search/sar) ———— 查看网络设备的吞吐率
> 作用:最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。
**语法**
> sar(选项)(参数)
**选项**
> -A:显示所有的报告信息;
> -b:显示I/O速率;
> -B:显示换页状态;
> -c:显示进程创建活动;
> -d:显示每个块设备的状态;
> -e:设置显示报告的结束时间;
> -f:从指定文件提取报告;
> -i:设状态信息刷新的间隔时间;
> -P:报告每个CPU的状态;
> -R:显示内存状态;
> -u:显示CPU利用率;
> -v:显示索引节点,文件和其他内核表的状态;
> -w:显示交换分区状态;
> -x:显示给定进程的状态。
**参数**
- 间隔时间:每次报告的间隔时间(秒);
- 次数:显示报告的次数。
**实例**
察看内存和交换空间的使用率:
```
sar -r
Linux 2.4.20-8 (www.linuxde.net) 20130503
12:00:01 AM kbmemfree kbmemused %memused
kbmemshrd kbbuffers kbcached
12:10:00 AM 240468 1048252 81.34
0 133724 485772
12:20:00 AM 240508 1048212 81.34
0 134172 485600
…
08:40:00 PM 934132 354588 27.51
0 26080 185364
Average: 324346 964374 74.83
0 96072 467559
```
kbmemfree与kbmemused字段分别显示内存的未使用与已使用空间,后面跟着的是已使用空间的百分比(%memused字段)。kbbuffers与kbcached字段分别显示缓冲区与系统全域的数据存取量,单位为KB。
观察系统部件10分钟,并对数据进行排序:
> sar -o temp 60 10
**通常作用**
sar命令在这里可以查看网络设备的吞吐率。在排查性能问题时,可以通过网络设备的吞吐量,判断网络设备是否已经饱和。
sar命令常用于查看TCP连接状态,其中包括:
active/s:每秒本地发起的TCP连接数,既通过connect调用创建的TCP连接;
passive/s:每秒远程发起的TCP连接数,即通过accept调用创建的TCP连接;
retrans/s:每秒TCP重传数量;
TCP连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,还是被动接受的连接。
TCP重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。
# 九、[top](http://linux.51yip.com/search/top) ———— 动态地查看系统的整体运行情况
> 作用:可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。通过top命令所提供的互动式界面,用热键可以管理。
**语法**
> top(选项)
**选项**
> -b:以批处理模式操作;
> -c:显示完整的治命令;
> -d:屏幕刷新间隔时间;
> -I:忽略失效过程;
> -s:保密模式;
> -S:累积模式;
> -i<时间>:设置间隔时间;
> -u<用户名>:指定用户名;
> -p<进程号>:指定进程;
> -n<次数>:循环显示的次数。
**top交互命令**
在top命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了-s选项, 其中一些命令可能会被屏蔽。
> h:显示帮助画面,给出一些简短的命令总结说明;
> k:终止一个进程;
> i:忽略闲置和僵死进程,这是一个开关式命令;
> q:退出程序;
> r:重新安排一个进程的优先级别;
> S:切换到累计模式;
> s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;
> f或者F:从当前显示中添加或者删除项目;
> o或者O:改变显示项目的顺序;
> l:切换显示平均负载和启动时间信息;
> m:切换显示内存信息;
> t:切换显示进程和CPU状态信息;
> c:切换显示命令名称和完整命令行;
> M:根据驻留内存大小进行排序;
> :根据CPU使用百分比大小进行排序;
> T:根据时间/累计时间进行排序;
> w:将当前设置写入~/.toprc文件中。
**实例**
> [root@localhost ~]# top
> top - 09:44:56 up 16 days, 21:23, 1 user, load average: 9.59, 4.75, 1.92
> Tasks: 145 total, 2 running, 143 sleeping, 0 stopped, 0 zombie
> Cpu(s): 99.8%us, 0.1%sy, 0.0%ni, 0.2%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
> Mem: 4147888k total, 2493092k used, 1654796k free, 158188k buffers
> Swap: 5144568k total, 56k used, 5144512k free, 2013180k cached
**解释**
```
top - 09:44:56 [当前系统时间],
16 days [系统已经运行了16天],
1 user [个用户当前登录],
load average: 9.59, 4.75, 1.92 [系统负载,即任务队列的平均长度]
Tasks: 145 total [总进程数],
2 running [正在运行的进程数],
143 sleeping [睡眠的进程数],
0 stopped [停止的进程数],
0 zombie [冻结进程数],
Cpu(s): 99.8%us [用户空间占用CPU百分比],
0.1%sy [内核空间占用CPU百分比],
0.0%ni [用户进程空间内改变过优先级的进程占用CPU百分比],
0.2%id [空闲CPU百分比], 0.0%wa[等待输入输出的CPU时间百分比],
0.0%hi[],
0.0%st[],
Mem: 4147888k total [物理内存总量],
2493092k used [使用的物理内存总量],
1654796k free [空闲内存总量],
158188k buffers [用作内核缓存的内存量]
Swap: 5144568k total [交换区总量],
56k used [使用的交换区总量],
5144512k free [空闲交换区总量],
2013180k cached [缓冲的交换区总量],
```
**通常作用**
top命令包含了前面好几个命令的检查的内容。比如系统负载情况(uptime)、系统内存使用情况(free)、系统CPU使用情况(vmstat)等。
因此通过这个命令,可以相对全面的查看系统负载的来源。同时,top命令支持排序,可以按照不同的列排序,方便查找出诸如内存占用最多的进程、CPU占用率最高的进程等。
但是,top命令相对于前面一些命令,输出是一个瞬间值,如果不持续盯着,可能会错过一些线索。这时可能需要暂停top命令刷新,来记录和比对数据。