内容
1. Deepfake技术概述
2. Wav2Lip 的 Deepfake 音频实践
- 环境设置
- 文件准备
- 主要运行步骤
3、注意事项
Deepfake技术概述
Deepfake 是一种创建合成媒体的技术。

大家知道的一个常见场景是换脸 ,目标面孔被交换和合并。

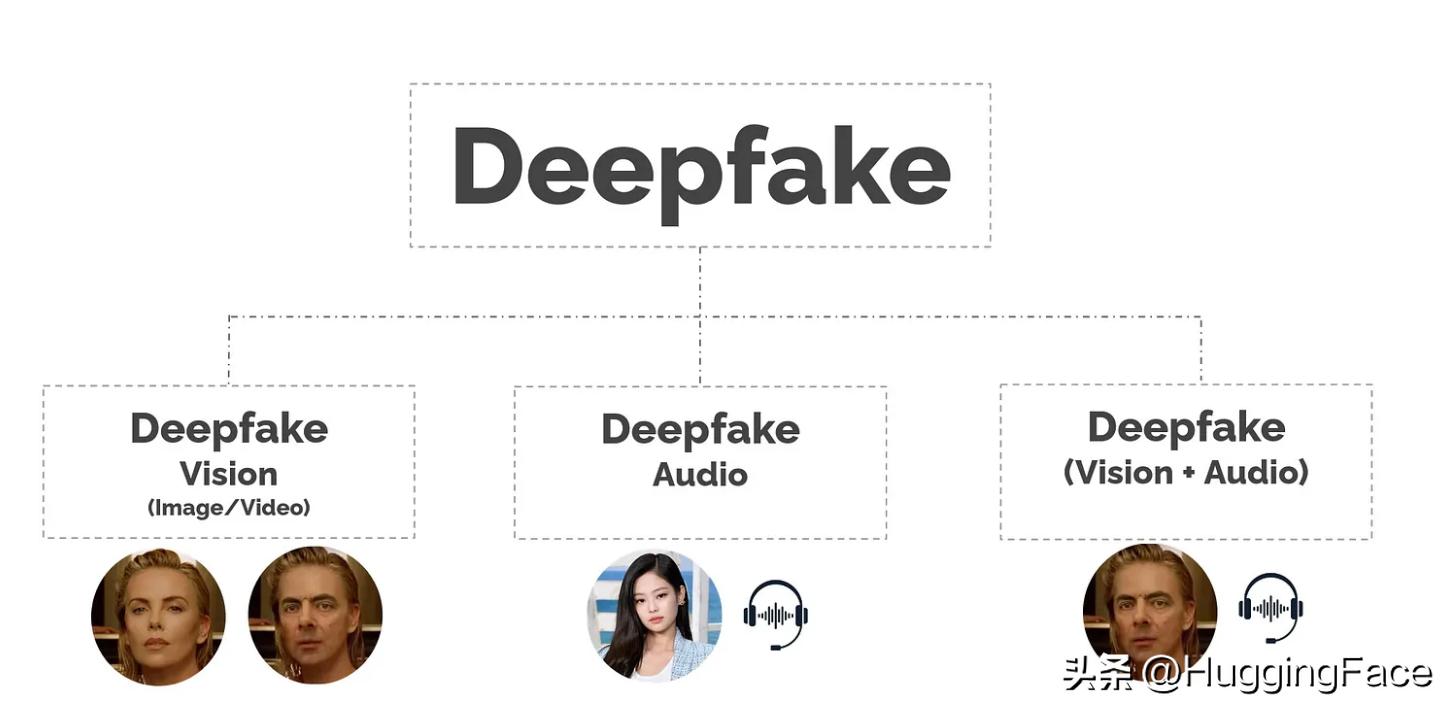
前面提到的换脸属于 Deepfake 视觉 ,其中图像或视频流是目标。
另一方面, Deepfake 音频 克隆,在仅通过电话沟通的场景下,人们可能无法辨别声音的真伪。

为了在视觉和听觉上实现模仿,人们不仅必须看起来像所需的目标,而且听起来也像他。
使用 Wav2Lip 的 Deepfake 音频
环境设置
Deepfake Audio,其实现来自Wav2Lip,基于ACM Multimedia 2020 上发表的论文《 A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild》 。
1.Python 3.6
使用您喜欢的方法创建一个新的虚拟 python 环境。在此示例中,说明了 conda 命令。
conda create -n wav2lip python=3.6
2. FFmpeg
pip install ffmpeg-python
特别是在Linux操作系统中,优选以下安装方法。
sudo apt-get install ffmpeg
3.从存储库安装requirements.txt
在此步骤中,首先使用以下命令克隆存储库。

git clone xxxx/Rudrabha/Wav2Lip
注意: 在主要执行步骤中,存储库中的 python 脚本对于实际合并音频和视频流是必需的。
所需的软件包(如文件 requests.txt 中的布局)使用以下命令安装。
pip install -r requirements.txt
文件准备
为了使用 Wav2Lip 运行口型同步,基本上需要三个数据源输入。
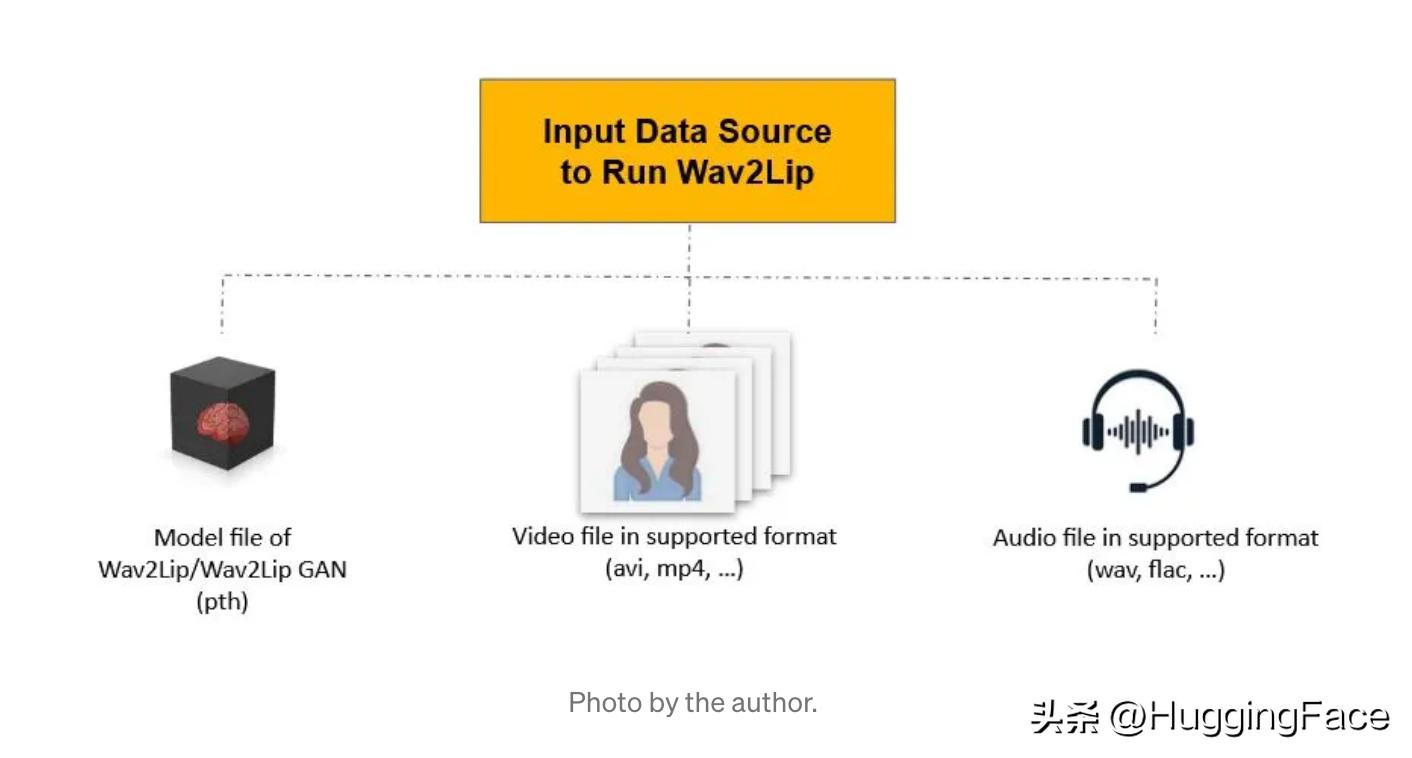
模型文件
开箱即用支持两种型号:
- Wav2Lip
- Wav2Lip GAN
虽然单次运行只需要一个模型,但请*载下**两个模型以比较结果。
视频文件:
为了获得理想的输出,输入视频应满足以下条件。
- 视频中以感兴趣的人为中心并放在前面
- 身体姿势受限且头部运动最少的感兴趣人员
- 面部区域周围没有遮挡的感兴趣的人(面具、阴影、头发)
- 光线充足,背景不杂乱
- 视频分辨率良好
特别是,已经发现当感兴趣的人没有嘴唇运动时,通过算法,嘴部区域将被改变以匹配语音的语调。源头的任何移动都会使更改变得复杂,并且可能会出现带有明显故障的不自然结果。
音频文件:
为了获得理想的输出,输入音频应满足以下条件。
- 清晰简洁的单一音频源(不要有超过一个人以重叠的语音交谈)
- 最小/无背景噪音
整体流程注意事项:
由于我们的想法是将音频脚本合并到对视频感兴趣的人,因此两个输入文件的时间长度应该相似。
主要运行步骤
准备好文件并将其保存在本地路径中后,就可以使用脚本 inference.py 运行 Wav2Lip 了。该脚本位于 的路径中 <path-to>\Wav2Lip\inference.py 。
命令应按以下方式构建:
python inference.py --checkpoint_path <模型文件路径> --face <视频文件路径> --audio <音频文件路径>
为了更清楚起见,命令示例:
python inference.py --checkpoint_path C:\Users\codenamewei\deepfake\model\wav2lip_gan.pth --face C:\Users\codenamewei\Documents\deepfake\data\video_short.mp4 --audio C:\Users\codenamewei\文件\deepfake\data\audio_short.wav
默认和常用参数的布局如下。有关完整列表,请查看源脚本中的参数设置。
--checkpoint_path:
支持模型的检查点文件的路径(Wav2Lip、Wav2Lip GAN)--face:
支持格式的视频文件路径(mp4、avi、...)--audio:
支持格式的音频文件路径(wav、flac...)(可选)--nosmooth:
设置后,将导致嘴部区域周围不平滑(可选)--pads:
设置后,调整区域的范围以改变
以这种方式设置的参数:(上、下、左、右)
示例:
--pads [0, 20, 0, 0]
示例上面为下巴区域添加了 20 个像素(选项)--static:
设置为 true 时,仅使用第一帧。
示例:
--static True
如果您想知道要使用哪个模型文件,存储库中的 readme.md 会指出每个模型的关键属性,如下面的屏幕截图所示。

Wav2Lip 更好地模仿了发音时的嘴部运动,Wav2Lip + GAN 创造了更好的视觉质量。