热泵在能源转型中发挥着重要作用。它们可以从空气或地面中提取可再生能源,并越来越多地取代建筑物中的化石供暖系统。然而,在运行中,由于不正确的设置和安装缺陷,热泵通常消耗比必要的更多的电力。尽管许多设置和安装问题很容易解决,但问题往往被忽视,快速修复的节省潜力仍不清楚。在一项针对297个瑞士家庭(41个治疗,256个对照)运行四年的研究中,我们调查了一项能源效率活动,其中治疗组接受了专业的热泵检查和用户培训。我们发现在实现的节约方面存在相当大的异质性。我们根据以下条件得出了两个标准智能电表使公用事业公司能够识别相关家庭的数据,从而提高此类效率运动的影响:例如,根据现有信息预先选择一半的家庭,与低潜力组相比,高潜力组的家庭平均每年节省1,805千瓦时(15.2%)。因此,在预选家庭中进行热泵检查可以节省大量、具有成本效益的电力,并且我们表明,常见的智能电表数据使这种预选成为可能。
1.简介
化石燃料供暖系统满足了我们社会最基本的需求之一,同时对温室气体排放做出了重大贡献。全球近四分之一的最终能源消耗归因于空间供暖,化石燃料仍占所用能源的最大份额(IEA,2019)。燃料的使用会导致燃烧产生的直接排放(例如一氧化碳2,不x和颗粒物)和间接排放(例如CH4),甚至生物燃料在生产、运输和储存过程中也会出现(Adams 等人,2015 年;劳沃等人,2021 年)。
多年来,通过用依赖可再生能源的化石供暖系统取代化石供暖系统,减少了这些排放的努力得到了加强。其中,热泵受到了相当大的关注,因为它们可以使用来自地面或环境空气的热能。从技术角度来看,热泵可以提取一个单位的电力,投入三到五倍的可用能源(IEA,2019)。现代系统甚至可以在没有温室气体作为制冷剂的情况下运行,并且在整个生命周期中具有出色的能量平衡。热泵也获得了经济吸引力,因为规模经济和政策制定者给予补贴降低了投资成本(IEA,2021)。另一方面,与传统供暖系统相比,在对化石燃料实行碳价格的国家以及由于天然气市场的增加,相对运营成本已经下降(《经济学人》,2021 年)。
由于这些原因,热泵通常是新建筑的首选。2018年,美国近50%的新建建筑多户住宅和超过 40% 的单户住宅配备了热泵(IEA,2020 年),而德国为 43%(Breisig 等人,2020 年),瑞士为 90%(Renz,2020 年)。在一些斯堪的纳维亚国家,热泵已经占住宅建筑存量的30%,欧洲的销售表明整体市场扩张强劲(EHPA,2019;国际能源署,2019 年)。
然而,这种理想的发展创造了额外的电力需求和峰值。两者都必须由(可再生)电力生产商满足,并由电网运营商管理。在一场正在进行的辩论中,几位研究人员评估了电网在多大程度上可以应对高热泵穿透力。例如,英国电网的峰值容量必须提高14%(60%)才能达到20%(50%)(Eggimann等人,2019年;洛夫等人,2017 年)。Connolly (2017) 从更全面的角度来看,考虑欧洲国家的电网全面推广情景,估计峰值需求可能会增加两倍,而其他人则预计许多国家(但并非所有国家)的电力基础设施都能处理额外的负载(Thomaβen 等人,2021 年)。即使是现代热泵也会增加电网的压力,因为它们可以实现与传统系统相当的高输出温度,并且现在更有可能安装在更耗能的建筑存量中(EHPA,2019)。因此,它们的部署必须伴随着对建筑物效率的广泛投资(Jack 等人,2021 年),但随后往往会被不断增长的住宅空间所抵消(Ürge-Vorsatz 等人,2015 年)。
除了提高建筑物效率的织物优先改造、电网能力、绿色电力供应和热泵的快速普及等重要因素外,它们在现场的效率成为成功改造空间供暖的关键因素之一。然而,一个实际的挑战是热泵通常无法满足最低效率标准或运行远低于制造商规定的效率,导致电力消耗高于必要的电力消耗(Caird 等人,2012 年;乔等, 2020;尹等人,2019)。标称效率和实际效率之间的差距是众所周知的。文献中记录了许多性能不佳的原因,包括规划和设计缺陷、安装故障、组件质量相关问题、参数配置不理想甚至不正确,以及对技术知之甚少的用户(Domanski 等人,2014 年;马达尼和罗卡特洛,2014年;米亚拉等人,2011,2017;乔等, 2020;温克勒等人,2020 年)。广泛的研究提出了下一代热泵的方法,以改进其机械设计、动态控制、安装简单性和可用性。许多提案依赖于基于AI的控制算法,网络功能和更多的传感器信息,因此旨在改进下一代热泵。
在这里介绍的研究中,我们设定了一个不同的重点:我们针对大量已安装的系统,这些系统通常会再使用十年,并建议如何改进热泵检查活动,重点关注现有库存中易于修复的问题。这些措施也与目前市场上的热泵有关,这些热泵通常还没有最新的控制技术,也没有使用互联网连接。
性能低下有几个易于纠正的原因,例如参数配置不理想和缺乏用户知识(Caird 等人,2012 年;米亚拉等人,2011,2017;乔等人,2020)。一个例子是过于谨慎的加热曲线设置,这可能是由于选择加热系统设置时的分裂激励而发生的。安装人员倾向于将流动温度设置得太高,以确保居民的舒适度(以及更少的无偿校正请求),而牺牲了居民的能源消耗。在这种情况下,居民倾向于调整室温而不修改加热控制设置,这导致整体系统效率降低。这种失调往往不会被注意到,即使供暖专业人员可以在短暂的检查访问中立即解决这些易于修复的问题。尽管看起来易于解决的性能问题具有巨大的潜力,但如果家庭接受专业的现场热泵检查以及用户培训,他们平均可以节省多少能源,目前尚不清楚。因此,我们研究的第一个研究问题(RQ)是:
RQ1:热泵的现场能效检查在多大程度上减少了家庭的用电量?
回答RQ1可以评估相应热泵服务的成本效益和碳减排成本。
以前的能源效率运动以及我们自己的分析表明,现场检查的节约效果差异很大。例如,Taylor等人(2014)报告说,只有先验能源绩效相对较低的家庭在接受能源审计(包括全面的巡视检查)后才显示出显着的节省。即使在有类似问题的家庭之间(例如夏季不必要的供暖,额外的电供暖),节省潜力也可能有很大差异(Miara等人,2011)。此外,Domanski等人(2014)发现了各种问题的相互作用:虽然存在效率损失按预期累积的问题星座,但也存在与单个故障条件相比发生微小变化的星座,而其他星座的性能甚至恶化。因此,我们调查了研究中接受专业热泵检查和用户培训的家庭之间的节能差异,试图回答以下RQ:
RQ2:不同家庭亚组的储蓄差异有多大?
RQ2的答案提供了对关注特定家庭群体是否以及在多大程度上可以提高此类效率计划的绩效的见解。
除了描述性分析,我们还为公用事业公司获得与决策相关的见解。虽然以前的研究(Caird等人,2012;格里森和洛,2013 年;米亚拉等人,2011,2017;乔等, 2020;尹等人,2019)我们提到了重要的利益相关者,如安装人员、规划者、制造商和用户,以及为提高热泵性能做出贡献的行动建议,我们指出了公用事业的关键作用,因为他们已经开始执行多项能源效率要求(例如欧盟,2018,2012)并在实施能源效率活动方面拥有经验。他们还投资昂贵的智能计量基础设施,生成有关家庭用电量的数据流,包括热泵装置的用电量(EC,2014)。智能计量可以使热泵提高电网稳定性并促进可再生能源的整合(Fischer和Madani,2017;Hillberg等人,2019),例如,使用动态电价(Gottwalt等人,2011)。然而,公用事业公司仍在寻找新的用例,以利用其智能电表基础设施来获得重大投资回报。(生态计划,2015 年)。
效率活动——无论是由监管机构强制要求还是由公司发起,因为它们帮助他们吸引新客户——如果事先刻意选择高潜力参与者,可以大获全胜(Taylor et al.,2014)。因此,我们的第三个RQ调查了选择标准,以确定具有高储蓄潜力的家庭:
RQ3:易于获得的信息是否有助于识别高潜力家庭?
RQ3的答案将告知读者如何实施细分以确定具有高可实现增益的目标,并提供来自大型案例的具体数据,说明这如何促进节省和成本效益。
为了回答这三个RQ,我们研究了一家瑞士公用事业公司的能源效率活动,该活动提供对住宅热泵的专业现场检查,包括修复易于解决的问题和用户培训。在一项准实验中,我们检查了智能电表的每月用电量数据,这些数据测量了热泵消耗以及来自 297 户家庭的天气数据。虽然有41户家庭接受了热泵检查,但256户家庭使用另一家公用事业公司(不提供此类服务)的热泵作为对照组。总的来说,我们分析了每个四年家庭的平均数据,产生了14,815个数据点。
本文的其余部分组织如下:第2节回顾了以前关于热泵在现场性能的研究,低性能的原因以及检测故障热泵的方法。第3节描述了本分析中使用的现场实验和数据。第4节描述了所使用的分析方法,介绍并讨论了结果。最后,在第5节中,我们总结了我们的发现,总结了对政策和公用事业的影响,并列举了这项研究的局限性以及对未来工作的建议。
2.背景及相关工作
热泵的性能引起了研究人员的高度关注。一些研究侧重于节能热泵的工程设计(例如 Deng 等人,2020 年)及其与其他加热系统的组合(例如 Long 等人,2021 年;帕特,2019)。这些研究的主要理由是增强未来的热泵技术。相比之下,我们研究的重点在于这些装置在长期运行阶段的性能改进。它是整个热泵生命周期中能源最密集的部分,占其总环境影响的 50%(Marinelli 等人,2019 年)。牢记这种差异,我们回顾了有关热泵性能测量的文献,热泵性能低的原因及其在运行阶段的易于修复,易于解决的干预措施的影响以及识别故障热泵安装的方法。
2.1.热泵性能
决策者1引入了标准化方法来测量实验室中热泵的性能(例如热泵EN14511的测试标准,计算标准SCOP EN14825)并定义了最低系统效率(EC,2013a,2009)。这些标准主要旨在提高市场上空间和水加热系统的可比性。他们建议能效标签(欧盟法规 1369/2017 和 CDR EU 811/2013),以促进在同类产品中实施更高效的系统(EC,2013b;EP,2017)。但是,它们并不能指导估计该领域的实际性能,我们将在下面进行描述。
在实验室中,热泵的性能通常使用性能系数(COP)来测量,该系数定义为热泵产生的热能(Q)与热泵消耗的电能(W)之比C .需要注意的是,W通常只包括热泵使用的能量,以及风扇或必要的辅助泵。它不包括属于加热系统(例如循环泵,缓冲器存储,电备用加热器)和热水生产系统(例如热水存储,热水循环泵)的其他消费者(Gleeson和Lowe,2013)。在COP测量期间,所用储热器的输入温度是恒定的。例如,在空气源热泵的情况下,假设输入空气温度为2°C或7°C,输出流量温度为35°C。 这种性能评估通常在测试实验室中对每个模型应用一次,但不能指导估计现场的实际性能。运行中的热泵具有不同的输入和输出温度。此外,它始终是属于热泵的几个系统的更复杂配置的一部分,例如单个热分配和热水生产系统,以及适当的设置(例如运行周期、温度水平)。
不出所料,多项研究表明,住宅热泵在该领域的实际性能往往低于预期指标。表1概述了针对不同市场和时期的住宅装置的研究,这些研究报告了空气源热泵(ASHP)和地源热泵(GSHP)表现不佳的情况。例如,Qiao等人(2020)发现,中国60%的被调查系统仅在法规接受的最低效率等级下运行,而10%甚至未能达到最低能效标准。同样,Caird等人(2012)发现,在英国,“只有少数热泵达到了欧盟可再生能源指令下的最低系统效率”(第285页)。美国也出现了类似的情况,所研究的地源热泵中有 80% 的运行低于其标称效率水平(Yin 等人,2019 年)。在一项较小的地源热泵研究中,Puttagunta等人(2010)指出,“整个冬季系统COP [...]为3.6;广告单位COP是5.0。“(第949页)。最后,在最近的一项研究中,Chesser 等人(2021 年)发现“大多数 ASHP 表现不佳。在7°C的输出温度下,8.5 kW ASHP的平均预测COP与制造商之间的差异水平为-16%[...],11.2 kW ASHP 为-24%“(第9-10页)。
表 1.报告热泵在现场表现不佳的研究概述。
|
空单元格 |
普塔贡塔等人 (2010) |
Caird et al. (2012) |
尹等 (2019) |
乔等 (2020) |
切瑟等人 (2021) |
|
样本量 |
3 |
83 |
32 |
28 |
12 |
|
建筑物 |
|||||
|
住宅 |
x |
x |
x |
x |
x |
|
商业 |
– |
– |
– |
x |
– |
|
私有 |
x |
x |
x |
– |
x |
|
社会住房 |
– |
x |
– |
– |
– |
|
位置 |
美国 |
英国 |
美国 |
中国 |
爱尔兰 |
|
热泵 |
|||||
|
阿什普 |
– |
x |
– |
– |
x |
|
格斯普 |
x |
x |
x |
x |
– |
|
性能一个 |
GSHP 3.3–4.3 |
阿什普 1.2–3.2 |
水平 GSHP 1.2–4.6 |
土源热泵 4.3 |
ASHP 3.0–3.6 (7 °C 时的COP) |
|
GSHP 4.2 |
|||||
|
GSHP 1.3–3.3 |
垂直 GSHP 2.0–3.8 |
地表水热泵 4.2 |
笔记:一个作者对COP使用了不同的定义。有些只包括热泵的用电量(例如Qiao等人,2020),有些还使用辅助设备的消耗,这限制了可比性。Gleeson和Lowe(2013)也报告了比较不同研究的性能指标的难度。
2.2.热泵性能低的原因及解决方法
由于全球热泵性能通常低于最低效率标准或制造商规定的效率(Caird 等人,2012 年;切瑟等人,2021 年;格里森和洛,2013 年;普塔贡塔等人,2010;乔等, 2020;Yin 等人,2019 年),几项研究调查了热泵性能低的原因,并给出了补救建议。文献指出(1)规划和设计缺陷,(2)热泵组件的质量问题,(3)安装故障,(4)参数配置,以及(5)热泵用户训练不足。我们将在下面描述这些类别,列出问题示例,并讨论安装系统后修复它们的复杂性。
首先,规划和设计缺陷包括,例如,错误的系统容量和管道系统的尺寸错误(Decuypere 等人,2022 年;多曼斯基等人,2014;米亚拉等人,2011,2017)。如果对隔热效果较差且热需求较高的建筑物进行改造并且预算有限,则热泵更有可能超大(Decuypere 等人,2022 年)。对规模过大的解释可能是房主倾向于紧急订购与能源相关的投资。例如,更换损坏的供暖系统可能比建筑围护结构中“不太必要”的先决条件投资(例如新窗户、墙壁隔热)更受欢迎,因此可以通过更大的热泵进行补偿。虽然专业人员通常可以在事后轻松识别此类问题,但它们的补救需要大量劳动力,而且通常不经济。文献表明,对于未来的安装,只有训练有素和认证的规划师和安装人员才能进行热泵项目,以避免此类规划和设计缺陷(Caird 等人,2012 年;格里森和洛,2013)。此外,承包商之间的有效协调也可以防止此类问题(Caird 等人,2012 年;德库佩尔等人,2022 年)。
热泵性能低的第二个原因是组件的质量问题(Madani和Roccatello,2014;米亚拉等人,2011,2017;乔等人,2020)。两个经常被命名的例子:阀门不能正确关闭并导致热水储存中的排放和温度传感器故障,这可能导致热泵除霜循环出现严重问题(Madani 和 Roccatello,2014 年;米亚拉等人,2011,2017)。制造商可以通过改善组件生产过程的质量管理来避免此类问题,与整体价格相比,成本较低(Madani和Roccatello,2014)。在操作系统中交换低质量组件也可能与相对较高的工作量有关。
第三,即使热泵规划正确且其组件正常工作,也可能发生安装故障。例如制冷剂过度充电或充电不足、传感器安装不当和管道绝缘不良(Domanski 等人,2014 年;米亚拉等人,2011,2017;温克勒等人,2020 年)。专家无法立即解决其中的许多问题,但必须首先订购零件或制冷剂。
第四组问题是非最优参数配置。与加热曲线(例如流量温度过高)、操作周期(例如夜间后退)、电荷泵(例如速度调节)、备用电加热器(例如意外使用)和家用热水箱(例如温度过高)有关的问题(Miara 等人,2011,2017)。另一个原因可能是系统的复杂性。使用传统的供暖分配系统(即散热器)不仅会降低整体性能,因为它们是为高温供暖系统设计的,而且有时它们与地板采暖一起使用(Caird 等人,2012 年)。这导致几个更复杂的加热回路需要优化。同样的逻辑也适用于外部生活热水系统。因此,此类别非常适合低成本和快速改进。
最后,几篇论文引用了热泵用户除了技术问题外缺乏知识。效率较高的系统与对其热泵系统具有一般知识和理解的用户之间似乎存在很强的依赖性(Caird 等人,2012 年;米亚拉等人,2011,2017;乔等人,2020)。例如,训练有素的用户不会在较短的缺勤时间(仅在较长的假期)时关闭供暖系统,而是让热泵在一夜之间打开,这与操作传统供暖系统的方式相反(Caird et al., 2012)。了解供暖系统和电价还可以通过将供暖系统的运行周期转变为成本最佳时间(例如昼夜费率)来避免不必要的成本。从社会角度来看,培训也很重要,因为一项研究表明,社会住房居民对热泵的了解少于私人家庭(Caird et al.,2012)。同样,研究表明,使用热泵的教育水平低的租户可能会遭受能源贫困,因此只能根据他们负担得起的为房屋供暖(Primc等人,2019)。因此,加强对热泵用户的培训可以减少热泵消耗并降低成本,而不会降低热舒适度。
最后两类可以通过相对容易解决的措施来补救,以提高热泵性能。专家可以在一次现场访问中完成,而无需更换任何组件。这两个类别也是相关的,因为用户的意识可以导致优化的配置(例如,仅在必要时激活备用加热器)。可以直接实施并增强用户知识的措施也可能立即带来性能提升。相反,属于“建议未来实施”类别的措施,因为它们需要大量的后续工作(即修改安装或更换组件),业主往往没有及时实施(Barbetta 等人,2015 年;布罗伯格等人,2019 年;墨菲,2014)。因此,专注于速赢类别是有帮助的。
2.3.易于解决的干预措施对热泵性能的影响
尽管这种易于解决的措施具有潜力,但只有少数研究明确调查了此类干预措施的影响。Miara等人,2011,Miara等人,2017发现解决严重的配置问题可以提高热泵性能。其他作者记录了用户知识和效率之间的相关性(Caird 等人,2012 年;乔等人,2020)。到目前为止,尚不清楚通过用户培训和修复易于解决的配置问题可以节省多少能源。
2.4.识别具有节约潜力的热泵
尽管到目前为止,该领域的热泵性能存在问题,但许多热泵实际上运行正常。当专注于规划有影响力的能源效率干预措施时,活动应关注那些需要检查的装置,因为这可以显着提高此类活动的有效性(Taylor et al.,2014)。识别具有高节约潜力的热泵装置的现有方法提供的指导很少,如下所述。
我们在上一节中回顾了调查低热泵性能原因的研究,但没有提供不同的选择方法来从运行数据中识别性能低的装置。然而,越来越多的研究领域使用统计或机器学习技术来识别安装后的传感器数据。一些研究确定了故障条件,例如制冷剂充注量水平差(Bode 等人,2020 年;Eom等人,2019)并使用来自放置在热泵内部和周围的多个传感器(例如温度、压力和电力消耗)的数据。对于实际应用,此类传感器数据的可用性可能是最大的障碍,因为传感器主要是专有的,现有的热泵通常没有配备足够的通信接口进行数据交换。此外,Bode等人(2020)报告了在现场应用基于实验室数据的模型时的可转移性问题。
其他工作侧重于利用智能计量技术的方法,该技术可以单独测量热泵的电力消耗,也可以与整个家庭的消耗一起测量,在不同的时间间隔,例如,每天或15分钟的测量,并将消耗轨迹传达给公用事业(EC,2014)。与前面提到的专有热泵传感器相比,智能计量已经安装在今天的许多欧洲建筑物中,预计到2024年将推出77%(Tounquet和Alaton,2020)。多项研究表明,智能电表数据如何与天气数据一起使用,以预测建筑物中是否存在热泵(Fei等人,2013 年;霍普夫等人,2018)甚至更详细的特征,例如热泵类型和年龄(Weigert 等人,2020 年)。然而,据我们所知,没有研究检查公用事业公司可用的智能电表数据,以识别性能不佳的热泵。
因此,我们将公用事业公司视为一个重要的利益相关者群体,在效率活动中应用数据驱动的性能不佳的热泵选择,从而有助于提高该领域的热泵效率。此外,公用事业公司通常有减少客户用电量的公共授权。效率措施,如我们在这项研究中分析的热泵检查,通常不是由订购服务的客户全额支付的,而是由公众共同资助的。公用事业公司将纳税人的费用重新分配为补贴,例如,在公共授权下,电价附加税(Alberini and Towe,2015;Cho等人,2019;欧盟,2021 年;泰勒等人,2014)或者也使用他们的财政储备(Energieschweiz,2015)。在这种情况下,公用事业公司必须确保以具有成本效益的方式实施相关措施,并确保这些措施的暴利者做出公平的贡献。因此,有必要从节省的能源、成本和效益方面确定这些措施的有效性。
许多基于数据的方法旨在确定能源效率运动的有希望的候选者,这是一个挑战,那就是回归均值效应。这种统计效应意味着极端测量(在随机影响下和数据中的高度相关性)与连续周期的测量相对化(Barnett,2004)。就选择家庭进行治疗而言,这意味着在观察期内能源消耗相当高或相当低的家庭往往在未来一段时间内消费,平均而言,接近“正常”消费(例如,一个家庭在一个时期内供暖更多,因为在家里的时间比平时更长)。在几次节能活动中观察到了这种效果(例如Verkooijen等人,2015年;Viggers等人,2019),并可能导致高估的治疗效果。因此,如果使用基于消费特征的选择标准来确定效率运动的有希望的候选人,则研究设计必须控制这种效果。
3.研究方法
我们从瑞士的两家电力公司获得了数据。来自公用事业A的数据包括来自41户家庭的电表读数和检查报告,这些家庭接受了专业的现场热泵检查,其中包括解决易于解决的问题和用户培训。公用事业公司B的数据集提供了256户家庭的用电量数据,这些家庭的热泵安装相当,这些家庭没有接受专业的现场热泵检查。我们首先描述我们的准实验的进行干预和研究设计。然后,我们介绍了分析中使用的电力消耗和天气数据。
3.1.实验设置
公用事业A作为客户服务进行了研究的热泵检查。这项服务的价格为400瑞士法郎(约合426美元),而其核心销售地区的客户获得了50%的折扣,因为他们已经通过对此类服务的电价附加费间接支付了该服务的费用。检查旨在提高家庭供暖系统的性能,包括专业能效顾问的现场访问,该顾问评估了整个供暖系统的整体性能,例如热泵、蓄热器、管道和散热器。必要时,专家解决了易于修复的问题,优化了加热控制单元的参数,并培训用户如何在用户遇到系统问题(例如热泵的热输出过低)时正确操作系统。顾问记录了评估结果以及无法立即补救的维修建议,这些建议随后应由安装人员在类似问卷的报告中进行。消费者在检查结束时收到报告。
在 2015 年至 2020 年期间通过公用事业公司网站预订检查服务的 200 多个家庭中,41 个家庭的用电量数据适合我们进行分析(如下一节所述)。我们将这些家庭在下文中称为治疗组。鉴于公用事业公司A无法提供未接受热泵检查的热泵家庭的类似用电量数据,2我们使用了公用事业公司B的热泵家庭数据集,该公用事业公司服务于非常接近的地理销售区域(两个数据集中家庭之间的平均距离为51.6公里)。该数据集源于与公用事业公司B的联合研究项目,当时公用事业公司不提供此类服务。我们在研究中使用这些家庭作为对照组。
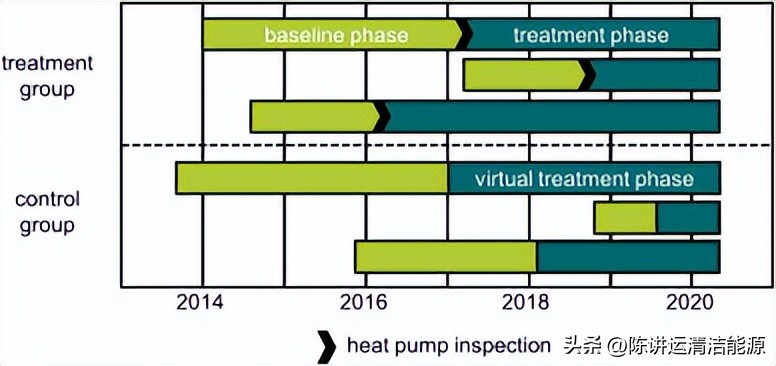
我们的研究在准实验设计中调查了基于这两个数据集的热泵检查干预措施。干预发生在治疗组的每个家庭在一个单独的时间点。因此,我们将数据分为干预前的时期(我们称之为基线阶段)和治疗后的时间。基线阶段的开始对每个家庭都是单独的,因为两家公用事业公司都在推出智能电表,在我们的研究期间,家庭逐渐配备了智能电表。由于每个阶段的开始时间和时间段不同(如图1所示),因此生成的数据集可以限定为不平衡面板结构。每个家庭可获得的数据量平均约为四年(表2)。
*载下**:*载下**高分辨率图像 (216KB)*载下**:*载下**全尺寸图片
图 1.准实验示意图。
表 2.每个组和阶段的数据。
|
数据特征 |
治疗 (实用工具A) |
控制 (实用程序 B) |
总 |
|
家庭 |
41 |
256 |
297 |
|
数月的数据 |
2,353 |
12,462 |
14,815 |
|
处于基线阶段 |
1,134 |
12,462 |
– |
|
处于治疗阶段 |
1,219 |
– |
– |
|
每户平均月数 |
57.4 |
48.7 |
49.9 |
|
处于基线阶段 |
27.7 |
48.7 |
– |
|
处于治疗阶段 |
29.7 |
– |
– |
我们计算了整个期间基线阶段每个家庭的消费统计数据(平均值,中位数),但分别计算了供暖阶段(9月至4月)和非供暖阶段(5月至8月)的消费统计数据(平均值,中位数)。
为了验证我们的实验是否允许从可用样本中得出合理的结论,我们按照科恩的方法对多元回归进行了功效分析(Cohen,2013)。在功率水平为 0.8,显著性标准为 0.1,中等效应大小 (F2= 0.15),这是家庭能源审计的典型特征(Delmas等人,2013年)和两个自变量(供暖度天数,检查),该分析使我们得出建议的样本量为54户,即27户要检查的家庭。
我们认为 0.1 的α水平是评估统计差异的阈值,适合我们的分析。这是因为在针对家庭用电量的活动中,由于消费差异很大,在针对家庭用电量的活动中,特别难以获得统计上的显着差异(Allcott,2011)。除此之外,对于我们仅涉及经济风险的调查干预措施,0.1 的α水平是可以接受的(Anderson 等人,2020 年)。
3.2.用电量数据
我们以相同的方式准备了两家公用事业公司的用电量数据。由于许多家庭只配备了一个仪表,但其他家庭有多个仪表(例如一个用于热泵,一个用于剩余家庭消费)。3我们将每个家庭所有仪表的测量值相加,并将它们汇总为每月总和。很少有家庭显示缺失值,通常为几个小时到几天。在本例中,我们排除了发生测量误差的整个月份。此外,我们删除了消费值与光伏系统的馈入值混合的家庭,那些关于热泵存在的明显错误文件的家庭,以及具有异常高或低消费模式的家庭(例如,表明商业辅助使用或小屋)。最后,我们排除了所有没有收到全年供暖期数据的家庭,以及在处理阶段数据少于三个月的家庭。这导致了14,815个月的总消费价值(表2)。
表3和附录中图A.2中的箱线图显示了两组的消耗特性、平均值、标准差(SD)和范围。由于处理组和对照组来自邻近地区的两个不同公用事业,我们通过执行Kruskal-Wallis秩和检验来确保两组消费值的可比性。表3中的p值显示,除一个变量外,在基线阶段,治疗组和对照组之间的消费特征没有统计学上的显着差异,但效应大小很小(
表 3.基线阶段处理(T)组和对照组(C)的用电量。
|
基线阶段的用电量(每月千瓦时) |
控制 |
治疗 |
总 |
C 和 T 之间的差异(p 值) |
|
|
消费中位数 |
平均值 (标准偏差) |
1,000.1 (521.9) |
901.8 (469.9) |
986.6 (515.4) |
0.348 |
|
范围 |
237.4–3,809.7 |
97.5–2,131.5 |
97.5–3,809.7 |
||
|
平均消耗 |
平均值 (标准偏差) |
1,048.3 (522.3) |
959.8 (517.0) |
1,036.1 (521.6) |
0.310 |
|
范围 |
261.7–3,787.6 |
171.3–2,808.5 |
171.3–3,787.6 |
||
|
加热阶段的平均消耗量 |
平均值 (标准偏差) |
1,232.4 (611.9) |
1,202.8 (718.3) |
1,228.3 (626.4) |
0.637 |
|
范围 |
325.4–4,265.3 |
248.8–4,101.3 |
248.8–4,265.3 |
||
|
非加热阶段的平均消耗量 |
平均值 (标准偏差) |
629.7 (377.5) |
536.5 (275.8) |
616.8 (366.1) |
0.230 |
|
范围 |
120.7–2,877.9 |
61.9–1,386.7 |
61.9–2,877.9 |
||
|
加热阶段的平均消耗量 − 非加热阶段的平均消耗量 |
平均值 (标准偏差) |
602.7 (363.9) |
666.3 (506.0) |
611.5 (386.2) |
0.701 |
|
范围 |
−388.8–2,621.7 |
60.0–2,714.6 |
−388.8–2,714.6 |
||
|
非加热阶段的平均消耗量/加热阶段的平均消耗量 |
平均值 (标准偏差) |
0.5 (0.1) |
0.5 (0.2) |
0.5 (0.1) |
0.045 |
|
范围 |
0.2–1.3 |
0.2–0.9 |
0.2–1.3 |
||
3.3.天气数据
外部温度极大地影响了建筑物的热量需求,从而影响了热泵的电力消耗。为了将天气的影响纳入我们的分析,我们使用了瑞士气象局(2017)的“TabsD”数据集,该数据集包含瑞士上空1×1公里网格中每个点的插值平均气温值。我们计算了每个网格点每月的加热度天数(HDD)。HDD 描述了假设的室内温度(我们使用 20 °C)与平均室外空气温度低于加热系统通常运行的阈值(我们使用 12 °C)之间的每日差异之和。我们根据离每户最近的网格点将HDD数据与月用电量数据进行匹配,并构建了一个不平衡的面板数据集。
4.结果和讨论
本节介绍用于回答RQ1-3的分析方法,并介绍和讨论我们的发现。
4.1.节省热泵检查
为了回答RQ1,我们使用线性回归方法分析了我们的纵向数据集。分析此类面板数据的最常见方法是合并、固定效应 (FE) 和随机效应模型。与合并模型相比,有限元模型在捕获未观察到的个体特定效应(例如建筑物大小或隔离标准)方面具有优势。附录 B详细介绍了模型选择,并建议对我们的数据集使用 FE 模型。因此,我们使用R包PLM的普通最小二乘法,通过双向FE面板数据回归估计了通过热泵检查的平均节省(Croissant和Millo,2008年;Millo,2017),并将线性面板模型定义为(一)C o n s um p t i o n i t=β1Insp e cted it+β2HDD i t+ci+λt+uit其中 C o n s是一个家庭在 月的用电量, i t 是一个虚拟变量,表示顾问检查了热泵, i t 对应于给定月份 家庭的供暖度天数,i 是每个家庭未观察到的个体固定效应,t 是相应月份的时间固定效应,是误差项。我们估计了一个稳健的协方差矩阵,并使用White-Arellano方法按家庭对观察结果进行聚类,以解释在我们的数据集中也发现的面板数据模型中众所周知的已识别问题异方差性和连续相关标准误差(Arellano,1987;伍尔德里奇,2010 年)。附录B显示了相应的统计检验。表4显示了模型1a的估计值,该估计值导致热泵检查节省的点估计为每月53.5千瓦时,每个家庭每年分别节省642千瓦时,或该数据集中平均供暖度日节省5.3%。4然而,治疗效应在统计学上并不显著,很可能是由于家庭之间效应大小的差异很大,这需要进行亚组分析。
表 4.热泵检查的整体处理效果(模型1a)。
|
自变量 |
消耗量 [千瓦时/月] |
||
|
估计 |
[CI] |
S.E. |
|
|
检查 |
−53.53 |
[−130.83; 23.78] |
46.99 |
|
硬盘 |
0.96 |
[0.75; 1.16] |
0.12*** |
|
观察 |
|||
|
分析的家庭户数 n |
n = 297 |
||
|
分析的月份范围 T |
T = 12–86 |
||
|
家庭月数 N |
N = 14,815 |
||
|
R2/R2调整 |
0.01/−0.02 |
||
注释:***、**、* 和 。表示 0.1%、1%、5% 和 10% 的统计学显著性。使用怀特-阿雷拉诺方法估计按家庭聚类的稳健标准误差(SE)(Arellano,1987);90% 置信区间显示在方括号中。
4.2.具有不同储蓄潜力的子组
为了检查总体治疗效果的差异并回答RQ2,我们探讨了消费量大幅减少的家庭亚组,减少量很少的家庭和没有减少消费的家庭亚组。为此,我们分别计算了每个家庭的治疗效果,然后根据个人储蓄估计的相对顺序对家庭进行了分组。
我们通过使用可变系数(VC)模型(Hsiao,2014)的热泵检查来估计单个节省效果,这使我们能够系统地改变系数and D对于每个家庭。由于该模型独立估计每个家庭的消费差异,因此无法控制单个、时间固定和回归均值效应。这使得我们有必要为对照组引入一个虚拟治疗阶段,这使我们能够估计对照组随时间推移的消费差异,从而将治疗组的实际节省与对照组的差异进行比较(我们一直称之为“节省”)。为了实现虚拟治疗阶段(图2),我们划分了对照组的可用数据点,将前半部分作为基线阶段,并使用后半部分作为虚拟治疗阶段,因为这种拆分(表2)类似于治疗组的干预阶段。即使在将一半的对照组数据删除到虚拟处理阶段后,基线阶段两组之间的消耗值仍然相当(见附录中的表A.1)。
Download : Download high-res image (231KB)Download : Download full-size image
Fig. 2. Schematic illustration of the quasi-experiment adopted by a virtual treatment phase.
Based on the actual treatment phase (treatment group) and the virtual treatment phase (control group) that are both coded in Inspectedit, we estimate the following VC model(1b)Consumptionit=β0i+β1iInspectedit+β2iHDDit+uit
结果显示基线和(虚拟)治疗阶段之间的个体估计差异很大。接受治疗的41户家庭的个人估计数()从每年减少15,000千瓦时(-50%)到增加近5,000千瓦时(+75%)不等。对照组显示出类似的变化,这意味着一些家庭偶然大大减少或增加了他们的消费。接下来,我们使用每个家庭的估计顺序来区分治疗组中具有不同储蓄潜力的几组。61%的家庭在检查后减少了消费(我们称这个群体为储蓄者),而另外39%的家庭则没有储蓄甚至增加了消费(非储蓄者)。鉴于一些储蓄者仅表现出适度的下降,而另一些则表现出显着的下降,我们将这一组分开,并将上半部分定义为高储蓄者(占治疗组的29%),将下半部分定义为低储蓄者(占治疗组的32%)。我们将相同的逻辑应用于对照组,并相应地将他们分为高储蓄者(25%),低储蓄者(25%)和非储蓄者(50%)。
我们得出的结论是,家庭之间储蓄潜力的巨大差异会导致中等效果,而没有目标。相反,当预先确定“高影响”家庭时,我们可以预期高平均储蓄。我们在图3中说明了这种情况,其中我们描述了不同比例的家庭的平均年节省量,假设能源效率服务提供商可以事先识别家庭并根据他们的储蓄对家庭进行分类。上线显示了从高储蓄者开始时,治疗组在这个假设的活动中的平均储蓄,其次是低储蓄者,当包括非储蓄者时,下降到几乎为零。此逻辑也适用于显示对照组节省的下线(基于虚拟治疗阶段),并且可能是由回归均值效应引起的,该效应也适用于治疗组的部分情况。但是,我们可以观察到两个方面表明治疗组的实际节省。首先,对于所针对的每个客户份额,治疗组的平均节省更大(例如 25%、50% 和 100%),因此表明实际节省更大。其次,治疗组的消费量更大,尽管对照组在基线阶段的消费量略高,因此“储蓄”潜力更高(参见附录表A.1中对照组新基线的两个组的消费值)。通过干预治疗组的实际减少取决于两条线。下面,我们将使用智能电表电力数据并估计实际节省潜力来演示这种事前识别高储蓄者的可能性。
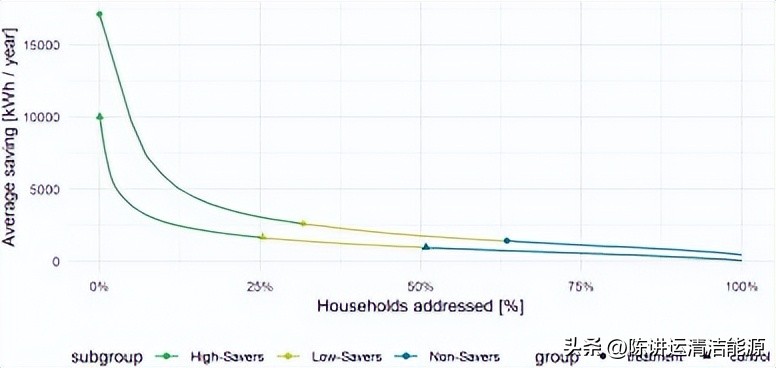
*载下**:*载下**高分辨率图像 (220KB)*载下**:*载下**全尺寸图片
图 3.每个家庭的平均储蓄取决于所覆盖的家庭的百分比。
4.3.确定有储蓄潜力的家庭
为了确定将产生大量能源节约的家庭,我们测试了十二个标准的力量,这些标准可以帮助找到这种“高影响”家庭(RQ3)。为此,我们使用了之前定义的高保存者、低保存者和非保存者组。我们特意测试了许多公用事业公司的选择标准,即(1)智能电表数据中基于消耗的标准,(2)供暖系统的特征,以及(3)建筑物:对于第一类,我们纳入了比当前智能计量基础设施可以测量和传输的更高的聚合级别的消耗数据,以确保即使是具有较大读取间隔的公司也可以实施这种简单的预选程序。对于后两类,有关供暖系统和建筑物的信息要么是公开的,要么是基于智能电表数据的可预测的。例如,公共地籍数据库包含有关地源热泵的信息,出于水保护原因,通常必须进行注册。此外,基于具有15分钟通用时间分辨率的智能电表数据和天气数据,热泵类型(Weigert等人,2020)和热水类型(Hopf等人,2018)的预测被证明是可行的。
为了评估选择标准,我们首先检查所考虑的子组之间每个标准的差异。为此,我们使用单变量统计量 - 分类变量的 Fisher 精确检验和连续变量的 Kruskal-Wallis 秩和检验。我们评估了治疗亚组之间的差异,并在表5中总结了结果。高储蓄者和低储蓄者在干预前测量的四个消费特征上存在统计学差异,即中位消耗()、平均消耗()、加热阶段的平均消耗(),以及非加热阶段的平均消耗量()。特别有趣的是,非储蓄者群体在干预前表现出持续的低用电量,这可能有多种原因(例如,已经高效的安装,用户的高能源意识,低收入)。此外,储水器组(高储蓄者和低储蓄者组合)和非储蓄者组在热泵类型方面存在统计学差异()。从这个角度来看,在我们的样本中,Savers安装地源热泵的频率几乎是Non-Savers的两倍。
表 5.亚组分析以确定家庭预选的选择标准。
|
标准 |
储户 |
非储蓄者 |
p 值 |
|||
|
总计 (N = 25) |
高节省器 (N = 12) |
低储蓄器 (N = 13) |
总计 (N = 16) |
储蓄者与非储蓄者 |
高储蓄者与低储蓄者 |
|
|
每月消耗量中位数(千瓦时) |
0.209 |
0.008 |
||||
|
平均值 (标准偏差) |
949.7 (418.0) |
1,167.4 (459.4) |
748.7 (254.5) |
827.0 (547.2) |
||
|
范围 |
304.5–2,131.5 |
304.5–2,131.5 |
372.0–1,213.0 |
97.5–2,099.4 |
||
|
每月平均消耗量(千瓦时) |
0.323 |
0.026 |
||||
|
平均值 (标准偏差) |
1,010.5 (512.4) |
1,221.3 (605.0) |
815.9 (322.7) |
880.7 (530.8) |
||
|
范围 |
347.3–2,808.5 |
375.1–2,808.5 |
347.3–1,474.7 |
171.3–2,170.9 |
||
|
加热阶段的平均消耗量(每月千瓦时) |
0.336 |
0.057 |
||||
|
平均值 (标准偏差) |
1,282.8 (749.0) |
1,537.1 (922.1) |
1,048.0 (467.2) |
1,077.8 (671.4) |
||
|
范围 |
394.0–4,101.3 |
429.6–4,101.3 |
394.0–1,978.6 |
248.8–2,664.8 |
||
|
非加热阶段的平均消耗量(以千瓦时/月为单位) |
0.121 |
0.022 |
||||
|
平均值 (标准偏差) |
589.6 (280.2) |
724.7 (293.4) |
464.9 (207.4) |
453.6 (255.5) |
||
|
范围 |
148.0–1,386.7 |
231.3–1,386.7 |
148.0–778.8 |
61.9–1,033.8 |
||
|
加热阶段的平均消耗量 − 非加热阶段的平均消耗量 |
0.789 |
0.253 |
||||
|
平均值 (标准偏差) |
693.2 (538.9) |
812.4 (686.8) |
583.1 (348.1) |
624.2 (463.7) |
||
|
范围 |
60.0–2,714.6 |
81.2–2,714.6 |
60.0–1,352.9 |
101.7–1,630.9 |
||
|
非加热阶段的平均消耗量/加热阶段的平均消耗量 |
0.364 |
0.415 |
||||
|
平均值 (标准偏差) |
0.5 (0.2) |
0.5 (0.2) |
0.5 (0.2) |
0.4 (0.2) |
||
|
范围 |
0.2–0.9 |
0.3–0.9 |
0.2–0.8 |
0.2–0.8 |
||
|
加热空间面积(米)2 |
0.134 |
0.604 |
||||
|
平均值 (标准偏差) |
252.2 |
256.7 (113.0) |
248.2 (97.2) |
215.1 (78.4) |
||
|
范围 |
80.0–560.0 |
80.0–560.0 |
135.0–525.0 |
126.0–400.0 |
||
|
居民人数 |
0.351 |
0.401 |
||||
|
平均值 (标准偏差) |
3.0 (1.6) |
3.2 (1.5) |
2.8 (1.6) |
2.5 (1.0) |
||
|
范围 |
1.0–6.0 |
1.0–6.0 |
1.0–6.0 |
1.0–5.0 |
||
|
热泵类型 |
0.025 |
1.0 |
||||
|
地 |
16 (64.0%) |
8 (66.7%) |
8 (61.5%) |
4 (25.0%) |
||
|
空气 |
9 (36.0%) |
4 (33.3%) |
5 (38.5%) |
12 (75.0%) |
||
|
热水类型 |
0.522 |
0.695 |
||||
|
加热系统。 |
13 (52.0%) |
7 (58.3%) |
6 (46.2%) |
6 (37.5%) |
||
|
外置锅炉 |
12 (48.0%) |
5 (41.7%) |
7 (53.8%) |
10 (62.5%) |
||
|
地暖 |
0.685 |
1.0 |
||||
|
不存在 |
5 (20.0%) |
2 (16.7%) |
3 (23.1%) |
2 (12.5%) |
||
|
存在 |
20 (80.0%) |
10 (83.3%) |
10 (76.9%) |
14 (87.5%) |
||
|
散热 器 |
1.0 |
0.226 |
||||
|
不存在 |
16 (64.0%) |
6 (50.0%) |
10 (76.9%) |
10 (62.5%) |
||
|
存在 |
9 (36.0%) |
6 (50.0%) |
3 (23.1%) |
6 (37.5%) |
||
Notes: The table shows the mean and standard deviation in parenthesis for continuous variables and the p-value of Kruskal-Wallis rank sum tests. For categorical variables, it shows the frequency of households for each category, the percentage in parenthesis, and the p-value of a Fisher's exact test.
在附录C中,我们使用更全面的多变量方法复制了该分析,该方法还包括对照组。这种扩展分析证实了中位数消耗和热泵类型是重要的预选择因素。此外,我们没有发现任何证据表明,与热泵类型相比,节省者取决于整体热量需求(例如,由建筑物的大小和居民数量给出)或其他供暖系统特征(例如外部热水锅炉、散热器的存在或地板采暖)。这些结果很有趣,因为这些特征被证明与影响整体热泵性能有关(Caird等人,2012),但似乎与热泵检查引起的快速获胜无关。该多变量分析还揭示了加热相和非加热相之间的差异作为可能的选择因子,这在单变量分析中是微不足道的。因此,我们决定对两个变量(中位数消耗和热泵类型)的预选择器进行影响调查,因为它们在两种分析中都表明了选择功率。
我们评估选择标准的第二步是影响分析。我们使用之前介绍的相同 FE 建模方法来估计一次使用一个选择标准的广告系列的平均节省,以估计没有选择的整体处理效果。
因此,我们通过添加预选择器作为假人形式的自变量并将它们与治疗效果 相互作用来扩展模型 1a。这是通过将预选择变量中位数消费量二元化来完成的,该中位数拆分将组分为两半,即高消费者(HC)和低消费者(LC)。在我们的符号中,虚拟表示消费中位数高于组内位数的家庭(默认值为 0)。反之亦然,上标“LC”代表低消费者。在分类预选变量HeatPump 类型的情况下,上标“ground”代表地源热泵,而我们使用类型“空气源”作为默认情况(默认值为 0)。
在我们评估这些预选标准的影响之前,还有一个重要方面需要考虑。鉴于我们使用因变量Consumption来推导预选标准,该标准在模型中也用作自变量,则处理效果可能会受到前面引入的回归均值效应的影响。我们纠正了这一方面,因为我们也使用先前引入的虚拟治疗阶段为对照组推导出预选标准。通过在预选标准和组之间的模型中添加交互作用项,我们估计了治疗组和对照组的高消费者之间的消费差异,从而计算出治疗的真实差异,而没有回归均值效应。这导致以下型号规范(2)C o n s um p t io n i t=β 1 Insp e cted it+β阿拉伯数字I n sp e c t e d i t×C o n trol×M ed i a niLC+β3I n sp e c t e d i t×Tr e a t m e nt×M edi a n i LC+β4I n sp e c t e di t×Tr e atm ent×Med i an i H C+β5HDD it+ci+λt+uit(3)C o n s um p t io n i t=β 1 Insp e cted it+β阿拉伯数字I n s p e c t e d i t×HeatP u mpiground+β3H D Di t+ci+λt+uit
模型2-3的估计值显示了清晰的画面(表6)。这两个标准对消费都有统计学上的显着影响。例如,在模型2中,与具有相同选择标准的对照组(本模型中的参考组)相比,基线阶段消费量高于中位数的家庭每月节省152千瓦时(p值= 0.097)或平均供暖日节省15.2%。对于基线消费中位数较低的治疗家庭来说,情况并非如此,与基线消费较低的对照组相比,这些家庭没有储蓄。点估计值表明每月增加 34 kWh,在统计上与零没有差异(p 值 = 0.218)。与未选择的组(空气源热泵)相比,根据热泵的热源(模型 3)进行预选甚至会导致地源热泵的处理效果高出 239 kWh(p 值 = 0.015),或在此过滤数据集中为 23.5%。请注意,模型 3 不需要回归均值校正,因为选择不依赖于因变量。与我们的第一个模型 (1a) 相比,这两个预选标准都大大增加了平均节省量,该模型估计每月总体节省 54 kWh。请注意,此处报告的节省是月平均值,每年节省的费用是这些数字的十二倍,根据高中位数消耗量选择,每年和家庭节省 1,805 kWh,根据热泵类型选择,每年节省 2,158 kWh。在下面的小节中,我们估计了使用已确定的预选标准的节能活动可能产生的财务影响。
表 6.分析已确定的预选高潜力热泵的标准。
|
自变量 |
消耗量 [千瓦时/月] |
|||||
|
型号 2 |
型号 3 |
|||||
|
估计 |
[CI] |
S.E. |
估计 |
[CI] |
S.E. |
|
|
检查 |
1.73 |
[−26.43; 29.89] |
17.12 |
59.16 |
[−37.92; 156.24] |
59.02 |
|
硬盘 |
0.95 |
[0.75; 1.15] |
0.12*** |
1.35 |
[0.33; 2.36] |
0.62* |
|
检查×控制×中位数立法会 |
12.68 |
[−14.94; 40.29] |
16.79 |
|||
|
检查×处理×中位数立法会 |
46.84 |
[−2.83; 96.52] |
30.20 |
|||
|
检查×处理×中位数慧聪 |
−152.15 |
[−302.93; −1.37] |
91.67. |
|||
|
×热泵检查地 |
−239.02 |
[−401.07; −76.98] |
98.52* |
|||
|
观察 |
||||||
|
分析的家庭户数n |
n = 297 |
n = 41 |
||||
|
分析的月份范围 T |
T = 12-86 |
T = 19-86 |
||||
|
家庭月数 N |
N = 14,815 |
N = 2,353 |
||||
|
R2/R2调整 |
0.01/−0.01 |
0.03/−0.02 |
||||
注释:***、**、* 和 。表示 0.1%、1%、5% 和 10% 的统计学显著性。使用怀特-阿雷拉诺方法估计按家庭聚类的稳健标准误差(SE)(Arellano,1987);90% 置信区间显示在方括号中。
4.4.在效率活动中使用预选标准
效率措施,如我们在这项研究中分析的热泵检查,通常不是由订购服务的客户全额支付的,而是由公众共同资助的,因此有必要确定这些措施在节省能源、成本和效益方面的有效性。
我们的研究表明,并非所有被检查的家庭都实现了能源效率的提高,但社会承担了很大一部分费用。因此,此类计划的成本效益和有目的的候选人预选至关重要,有助于实现这两个目标。因此,我们分析了在分析软件解决方案中使用已确定的选择标准来自动预先选择高影响力家庭的货币影响。
在此过程中,我们会考虑两个示例广告系列:在广告系列 A 中,客户订购服务,这意味着他们选择自己参加广告系列。在活动B中,公用事业公司使用上述标准之一,仅向他们认为储蓄高额的50%的家庭提供服务。表 7显示了两种选择方法的净收益:我们采用进行热泵检查的原始成本,在我们的案例中为 400 瑞士法郎(426 美元)。对于活动 B,我们假设智能电表基础设施已经到位(例如,强制要求或支持电表到现金流程),但需要一个分析系统来处理数据并计算所有客户的选择标准值。我们假设该系统的每个分析家庭的许可费为10瑞士法郎(10.7美元)。此外,我们将模型 1a 的估计值用于活动 A,模型 2 的估计值用于活动 B,并假设电价为 0.207 瑞士法郎/千瓦时(0.223 美元/千瓦时)。5
表7.基于客户选择方法的每户热泵检查净收益。
|
空单元格 |
活动A:通过自选进行热泵检查 |
活动B:通过预选进行热泵检查(使用分析系统) |
|
每次检查的成本 |
400瑞士法郎 |
400瑞士法郎 |
|
426 美元 |
426 美元 |
|
|
分析的确定每个家庭高影响家庭的许可费 |
0瑞士法郎 |
10瑞士法郎 |
|
0 美元 |
11 美元 |
|
|
每个高影响家庭的许可费 |
0瑞士法郎 |
10/50%家庭选择瑞士法郎=20瑞士法郎 |
|
0 美元 |
21 美元 |
|
|
通过热泵检查,每户家庭每年节省千瓦时 |
53.53 kWh × 36 个月 = 1,927 kWh |
150.42 kWh × 36 个月 = 5,415 kWh |
|
每千瓦时的电价 |
0.207瑞士法郎/千瓦时 |
0.207瑞士法郎/千瓦时 |
|
0.221美元/千瓦时 |
0.221美元/千瓦时 |
|
|
每户净收益 |
1,927 千瓦时 × 0.207 瑞士法郎/千瓦时 – 400 瑞士法郎 =瑞士法郎−1 |
5,415 千瓦时 × 0.207 瑞士法郎/千瓦时 – 400 瑞士法郎 – 20 瑞士法郎 = 701 瑞士法郎 |
|
美元 −1 |
747 美元 |
总体而言,在三年内累积效率收益时,活动A的每户净收益几乎为零。相比之下,在活动B中使用分析工具进行预选可产生701瑞士法郎(747美元)的净收益。但是,这两种类型的活动也可能与更高的风险或更高的收益相关联。因此,我们使用表 6中估计值的 90% 置信区间来表示我们在图 4 中给出的预期净收益的上限和下限。结果表明,两个活动的净收益下限可能是负的,活动A约为-577瑞士法郎(-615美元),活动B约为-633瑞士法郎(-675美元),这部分可以用分析系统的许可费来解释B。活动A的净收益上限(575瑞士法郎,613美元)不超过活动B的平均净收益(701瑞士法郎,747美元),而B最多可节省2,034瑞士法郎(2,168美元)。从风险/收益的角度来看,我们总结了两个广告系列的负净收益风险大致相似。尽管如此,广告系列B的平均净值和上限净值表明经济价值更高。
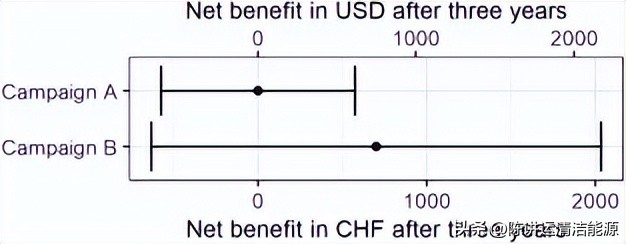
*载下**:*载下**高分辨率图像 (176KB)*载下**:*载下**全尺寸图片
图4.每户热泵检查的净收益,包括90%置信区间。
5.结论和政策含义
热泵可以从地面、土壤或环境空气中提取能量,将其所有者转变为小型可持续发电厂的运营商。然而,它们依靠电力来运行,热泵的日益普及给电网带来了压力。因此,热泵系统运行的效率变得越来越重要。每个未按预期执行的安装都会浪费资源并导致不必要的运营成本。一些性能低下的原因在安装后很难解决。尽管如此,能源顾问可以通过一次检查访问轻松解决许多问题。
我们的研究调查了专家调查住宅热泵的活动的影响,以解决易于检测和解决的问题(例如优化供暖控制单元的设置,包括用户培训)。对41个接受治疗的家庭的纵向用电量数据的分析显示,与对照组256个未处理的家庭相比,他们平均每年节省642千瓦时(5.3%)。然而,治疗效果差异很大,总体上没有统计学意义:虽然治疗组中一个相当大的亚组(61%)与基线消耗相比节省了能量,但还有另一个非储蓄者亚组(占我们样本的39%)增加了他们的消耗。这些结果表明,只有有目的地预先选择家庭,热泵检查才能产生实质性的节能效果。
为了进行这样的预选,我们在本研究中评估了几个易于获得的电力公用事业标准(例如中位数消耗和热泵类型)。有了这些标准,可以大大提高活动的成本效益。根据我们的评估,使用建议的预选标准“消费中位数”的活动每年和家庭可以节省1,805千瓦时(15.2%),如果知道热泵来源,甚至可以节省2,158千瓦时(23.5%)。在这样的活动中,与家庭的自我选择活动相比,更保守的估计产生701瑞士法郎(747美元)的三年净收益,平均而言,经济上不可行的CHF -1(美元-1)。我们的研究结果对能源政策和公用事业公司有影响,我们将在下面描述。之后,我们列出了我们研究的局限性。
5.1.对能源政策的影响
自《巴黎协定》签署以来,可持续和高效的能源供应一直是政治议程的重中之重。在这种情况下,热发电的电气化和加热系统的效率变得更加关键。我们的研究表明,目前安装的热泵具有很高的节约潜力——很可能会运行十多年——并证实了早期研究的结果,即该领域的许多热泵性能低于预期(Caird 等人,2012 年;切瑟等人,2021 年;普塔贡塔等人,2010;乔等, 2020;尹等人,2019)。虽然迄今为止,提高热泵性能的政策措施主要集中在补贴某些效率标准的新装置上(EC,2013a,2013b,2009;EP,2017),我们的研究结果敦促关注现有的装置库存。提高已安装热泵能源效率的强大工具是专家的现场访问,以识别易于修复的问题并提供用户培训。如本文所示,如果有意预先选择家庭,这一措施表明了显著的净收益。如果向所有客户提供此类检查,则每次检查的效果(以及成本效率)会大大降低,因为节省效果因家庭而异。
决定将哪些家庭纳入活动需要对其潜力进行数据驱动的评估。为此,我们提出了一套选择标准,公用事业公司可以使用普通智能电表记录的用电量数据得出这些标准。调查标准不仅限于单独测量的热泵安装,而是基于整个家庭的汇总用电量数据。这使得公用事业和智能电表基础设施运营商成为这项任务的关键参与者。但是,这些组织需要具备合法条件,以便出于能源效率干预的目的访问和处理此类数据。在许多国家/地区,智能电表数据的使用仅限于少数用例,通常是出于分拆原因,这应该会阻止参与者将垄断获得的数据用于狭义范围之外的用例。例如,在瑞士,法规禁止公用事业公司使用来自电网运营的智能电表数据,因为这可能会导致比能源顾问更具竞争优势。此外,家庭通常不知道使用他们的智能电表数据可以节省大量能源和金钱,从而避免明确同意用户进行数据处理。因此,政策制定者需要在社会对竞争、数据保护和可持续发展目标的需求之间取得平衡。
即使消除了为能源效率干预而处理数据的法律障碍,或者当用户对数据处理提供知情同意时,技术问题也会阻碍与服务提供商的数据共享。其中一个障碍是缺乏接口,即使家庭同意,也无法向外部服务提供商提供计量数据。智能电网运营商应为客户提供与服务提供商交换数据的接口,这些接口易于使用、安全且有据可查。事实上,政策制定者应该为使用现有数据来检测调整不良的供暖系统铺平道路。
此外,我们看到了使用其他(开放)数据源的巨大潜力。例如,水或噪音保护的地籍数据记录了已安装热泵的特征(例如地点、安装日期和类型)。这些数据可以加强分析系统,以支持能源效率服务。迄今为止,此类数据仅在少数几个地区公开提供,并且通常分布在不同的当局(例如区域规划和建筑检查部门)之间。因此,拥有此类数据的政府组织应该整合其数据池,并提供统一的中央数据接口,以便为研究和服务公司提供这些数据。
5.2.对公用事业的影响
公用事业经常被要求执行提高能源效率的公共任务(Alberini and Towe,2015;Cho等人,2019;欧盟,2021 年;泰勒等人,2014 年)。我们的研究表明,热泵检查是以理想的成本实现效率目标的措施——前提是对家庭的目标是基于适当的预选。智能电表数据使这种预选成为可能。因此,公用事业公司可以收回对智能计量基础设施的大量投资,到目前为止,这些投资只是缓慢摊销。此外,实施此类分析解决方案可以培养他们的数据分析能力和价值创造机制(Hopf 等人,2022 年)。另一方面,客户可以从目标中受益,因为热泵检查依赖于时间投资(通常也是财务投资)。通过预选活动,他们的努力/成本收益比平均会显着提高。同时,客户负净收益的风险与自我选择活动中的客户相当。通过一致的成本分摊和收益模式,可以降低客户订购没有回报的服务的风险,其中公用事业公司承担成本,但与家庭一起从改进中受益。这样的模型可以支持遭受能源贫困的家庭(Guertler,2012)。最后但并非最不重要的一点是,公用事业公司必须为这种方法设定法律基础,并要求其客户处理其计量数据,以便在有针对性的活动中使用它们。我们的研究结果为这样做提供了合理的理由。
5.3.限制和未来工作
我们的研究是第一个使用涉及真实消费者行为的纵向数据集来检查热泵检查对现场住宅用电量的影响的研究之一。由于其探索性,我们的研究有几个局限性,同时为未来的研究工作铺平了道路。
我们利用这个机会检查了一家公用事业公司已经进行的热泵检查;我们对研究设计的影响有限。例如,我们对治疗组和对照组的研究受试者、居住属性等信息有限。此外,我们的研究还包括较小的住宅。因此,我们激励未来的研究,通过先进的研究设计来验证我们的发现,这些设计控制潜在的混杂因素、样本偏倚和影响消费者参与热泵检查活动意愿的因素,他们可以在治疗组和对照组之间进行额外的随机检查。此类研究还可以包括较大的热泵装置(例如多户住宅或企业),并可以使用更详细的电力消耗数据(例如单独测量的热泵和家庭消耗或增加测量间隔)。此外,可以想象,我们的研究设计使用总电力消耗而不是纯热泵消耗,导致更保守的节省估计。这是因为其他电器(即娱乐电子产品)的使用也与一年中的时间(即冬季)相关,因此与我们的分析中用于控制的加热度天数相关。
效率顾问不仅在热泵检查期间纠正了易于修复的措施,而且还培训了用户并列出了未来改进的建议(例如安装调速循环泵)。目前尚不清楚检查在多大程度上只导致立即进行技术调整或启动居民未来的行动或行为改变,例如对供暖系统进行进一步调整以及影响他们在使用其他耗电设备时的行为。但是,此类计划中通常会提供技术解决方案和用户培训的结合,因此我们认为从整体上检查该计划是有帮助的。哪些部分影响来自长期措施,哪些部分源于可能不持久的行为改变也是一个悬而未决的问题;然而,我们研究中的观察期相对较长,每个家庭大约有四年的数据,所以我们认为这种限制很小。然而,未来的研究应该调查这种干预措施的纵向持久性以及对其他领域的潜在溢出效应。
CRediT作者贡献声明
Andreas Weigert:方*论法**,软件,形式分析,调查,数据管理,写作 - 原始草稿,可视化,项目管理。康斯坦丁·霍普夫:方*论法**,数据管理,写作 - 审查和编辑,监督,资金获取。塞巴斯蒂安·京特:方法、软件、验证、形式分析。托斯滕·斯塔克:概念化,方*论法**,资源,写作 - 审查和编辑,可视化,监督,资金获取。
竞合利益声明
作者声明,他们没有已知的相互竞争的经济利益或个人关系,这些利益或个人关系似乎会影响本文中报告的工作。
确认
这项工作得到了瑞士联邦能源局的支持[批准号SI/501521-01];以及德国联邦经济事务和能源部[批准号0350010]。
作者要感谢公用事业公司“苏黎世州电力公司”(EKZ)的Lorenz Deppeler,Marina Gonzalez Vaya,Hardy Schröder和Michael Peter提供热泵检查和电力消耗数据,以及对典型热泵问题的富有成效的讨论和见解,公用事业公司“Centralschweizerische Kraftwerke AG”的André Rast提供电力消耗数据, 苏黎世联邦理工学院的Peter Molnar提供天气数据。最后,作者要感谢Kathrin Schmitt和Leonard Michels对这份手稿早期版本的宝贵评论。
附录A.样品详情
另外两项分析确保了治疗组和对照组在引入虚拟治疗阶段之前和之后的可比性,因此丰富了我们在第 3.2 节中首次介绍的两组之间的相似性检查。表A.1显示,各组的消费统计没有显著差异(克鲁斯卡尔-瓦利斯秩和检验)。图 A.2显示了箱线图,直观地说明了它们的相似性。
对于对照组,我们在引入虚拟治疗阶段后使用了第一次分析和一半的数据集(我们将虚拟治疗阶段定义为初始基线阶段的后半部分)。治疗组的数据保持不变。表A.1中的p值显示,在基线阶段,处理和对照组在消耗特征方面没有统计学上的显着差异,有完整数据和一半数据。在完整数据集的情况下,只有一个变量(加热阶段/非加热阶段)是不同的。由于加热相和非加热阶段之间的比率而不是差异在统计上是不同的,我们认为这总体上没有实质性差异,因为效应大小很小(
表 A.1.治疗组(T)和对照组基线阶段的用电量,完整数据(C满)和半数据(C半)
|
基线阶段的用电量(每月千瓦时) |
空单元格 |
T |
C满 |
C半 |
p 值,两者之间的差值 |
||||
|
T 和 C满 |
T 和 C半 |
||||||||
|
消费中位数 |
平均值 (标准偏差) |
901.8 |
(469.9) |
1,000.1 |
(521.9) |
943.7 |
(525.2) |
0.348 |
0.947 |
|
范围 |
97.5–2,131.5 |
237.4–3,809.7 |
178.9–3,815.6 |
||||||
|
平均消耗 |
平均值 (标准偏差) |
959.8 |
(517.0) |
1,048.3 |
(522.3) |
1,018.7 |
(537.5) |
0.310 |
0.633 |
|
范围 |
171.3–2,808.5 |
261.7–3,787.6 |
249.9–3,908.7 |
||||||
|
加热阶段的平均消耗量 |
平均值 (标准偏差) |
1,202.8 |
(718.3) |
1,232.4 |
(611.9) |
1,241.1 |
(643.8) |
0.637 |
0.679 |
|
范围 |
248.8–4,101.3 |
325.4–4,265.3 |
308.3–4,286.5 |
||||||
|
非加热阶段的平均消耗量 |
平均值 (标准偏差) |
536.5 |
(275.8) |
629.7 |
(377.5) |
621.7 |
(390.4) |
0.230 |
0.357 |
|
范围 |
61.9–1,386.7 |
120.7–2,877.9 |
90.2–3,135.9 |
||||||
|
加热阶段的平均消耗量 – 非加热阶段的平均消耗量 |
平均值 (标准偏差) |
666.3 |
(506.0) |
602.7 |
(363.9) |
625.6 |
(424.3) |
0.701 |
0.742 |
|
范围 |
60.0–2,714.6 |
−388.8–2,621.7 |
−350.9–3,161.2 |
||||||
|
非加热阶段的平均消耗量/加热阶段的平均消耗量 |
平均值 (标准偏差) |
0.5 |
(0.2) |
0.5 |
(0.1) |
0.5 |
(0.2) |
0.045 |
0.127 |
|
范围 |
0.2–0.9 |
0.2–1.3 |
0.1–1.2 |
||||||
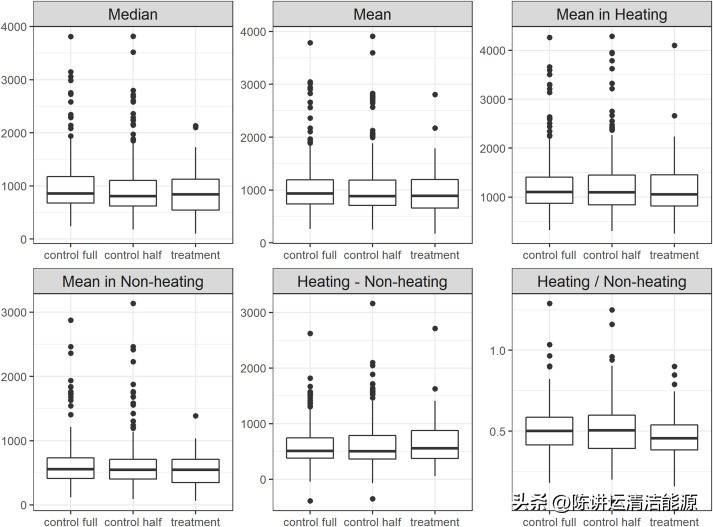
*载下**:*载下**高分辨率图像 (659KB)*载下**:*载下**全尺寸图片
图 A.2.基线期处理组和对照组用电量的箱线图
附录B.选型详情
进一步的统计测试帮助我们选择一个适当的模型来估计我们在4.1 节中介绍的整体节约潜力。我们进行了两次统计测试,以确定哪种类型的模型(合并、有限元或随机效应)是合适的。首先,我们进行了 F 检验来比较合并模型和有限元模型,并且可以拒绝所有固定效应等于零 的 H 0。. 其次,我们用豪斯曼检验表明应该使用有限元模型,而不是随机效应模型(豪斯曼,1978)。
有限元模型的标准误差同时表现出异方差性和序列相关性。前者是通过应用布鲁施-异教检验发现,后者通过应用布鲁施-戈弗雷检验(布鲁施,1978年;布鲁什和异教徒,1979)。
附录 C.预选标准详情
我们进行了另外两项多变量分析,以确定具有储蓄潜力的家庭的预选标准,从而确认了第4.2节中单变量分析的结果。我们应用逻辑回归来估计拟议选择标准的对数几率(见表5),从而控制多元和回归均值效应。为此,我们使用之前根据VC模型的估计值对研究参与者进行排名得出的两个因变量(储蓄者与非储蓄者,高储蓄者与低储蓄者)。
首先,我们在模型 C.M1 中估计所有可用选择标准对类 Saver 的影响(与非节省程序相比)。为了与主要文章中的分析保持一致,我们认为公用事业公司具有有关建筑物,供暖系统和智能电表数据访问的基本信息,从而查看可用于处理组的所有变量。在回归分析中,我们必须解决变量之间的强相关性,因为它们会导致逻辑回归模型中的多重共线性。受影响的变量是加热阶段(加热)的平均基线消耗量和非加热阶段(非加热)的平均基线消耗量。此外,这两个变量都与总体基线消耗量(平均值和中位数)密切相关。因此,我们使用加热相和非加热阶段之间的差异作为变量,并删除了其他强相关的变量。因此,逻辑回归模型是P(y1=1|x)=β0+β1M e d i a n+β2(H eati n g−NonHe a t ing)+β 3 H e a t e dsp a c e area+β4N u m b e r ofr e sid e n t s+β5Heat p umptype+β 6热水类型+β 7地暖+β8散热器+u(C.M1)其中表示第一个因变量,定义如下:y1={0 i f a h o u s eh o ldis a N onSav e r 1if a h o u s e hold s i s asaver
表C.1中的结果表明,只有地源热泵类型显着增加了成为节省者的对数几率。我们无法找到对描述供暖系统特征(热水类型、地板采暖和散热器)或建筑物(居民人数、供暖空间面积)的其他变量的支持。因此,多变量方法的结果与正文中的单变量方法一致,并证实了热泵类型的影响,该类型似乎与正在研究的其他特征无关。
在第二种分析中,我们感兴趣的是识别高储蓄者,并假设只有基准消耗的特征,从而在纯智能电表数据上,才可用。因此,我们可以将对照组包含在模型 C.M2 中(基于引入的虚拟处理阶段),并通过在选择标准之间添加交互作用项来控制回归均值效应。我们制定P(y2=1|x)=β0+β1M e d i a n+β2(H eati n g−NonH e a t i n g)+β3M e di a n×G r oupTr e atme n t+β4(H e a t i n g−N o n Heat ing)×GroupTr e atment+u(C.M2)其中表示第二个因变量,定义如下:y2={0 i f a h o u s eh o ldis a L owSav e r1 i f a h o u s e h old s is a HighSaVer
表 C.1中的结果表明,有两个变量显著影响成为高保存者的对数几率。基线消耗中位数(与治疗组相互作用)对高储蓄者的对数几率产生积极影响。另一方面,加热阶段和非加热阶段(也与治疗组相互作用)的消耗量之间的差异降低了成为高储蓄者的对数几率。此分析证实了单变量分析的结果。我们再次发现支持消费中位数作为高储蓄者的预选标准。当我们控制回归均值效应时,这种效应是稳定的。
这一额外的分析进一步强调,公用事业公司应预先选择消费中位数较高的家庭。最后,结果表明,治疗组不会增加成为高储蓄者的对数几率。这强调了预选标准对于确定竞选活动有前途的家庭的重要性,因为至少在我们的样本中,自我选择似乎并不平均有效。
表 C.1.亚组分析以确定家庭预选的选择标准
|
自变量 |
型号 C.M1 |
型号 C.M2 |
||||||
|
储蓄者与非储蓄者 |
高节省与低节省 |
|||||||
|
估计 |
[CI] |
S.E. |
p 值 |
估计 |
[CI] |
S.E. |
p 值 |
|
|
(截距) |
−0.458 |
[−3.506; 2.590] |
1.853 |
−2.229 |
[−3.167; −1.291] |
0.570 |
*** |
|
|
中位数 |
−0.000 |
[−0.003; 0.002] |
0.002 |
0.002 |
[ 0.001; 0.003] |
0.001 |
** |
|
|
(加热-非加热) |
0.000 |
[−0.002; 0.002] |
0.001 |
0.001 |
[−0.000; 0.002] |
0.001 |
||
|
加热空间区 |
0.002 |
[−0.007; 0.010] |
0.005 |
|||||
|
居民人数 |
0.344 |
[−0.245; 0.933] |
0.358 |
|||||
|
热泵类型地 |
1.762 |
[0.240; 3.285] |
0.925 |
. |
||||
|
热水类型外部锅炉 |
0.044 |
[−1.268; 1.357] |
0.798 |
|||||
|
地暖存在 |
−0.858 |
[−2.892; 1.176] |
1.237 |
|||||
|
散热 器存在 |
−0.803 |
[−2.378; 0.772] |
0.957 |
|||||
|
群治疗 |
−2.643 |
[−6.228; 0.942] |
2.179 |
|||||
|
群治疗× 中位数 |
0.006 |
[ 0.000; 0.011] |
0.003 |
. |
||||
|
群治疗×(加热-非加热) |
−0.004 |
[−0.008; −0.001] |
0.002 |
* |
||||
|
AIC |
64.312 |
181.983 |
||||||
|
比克 |
79.734 |
199.926 |
||||||
|
对数似然 |
−23.166 |
−84.992 |
||||||
|
变异 |
46.312 |
169.983 |
||||||
|
数字。 |
41 |
147 |
||||||
注释:***、**、* 和 。表示 0.1%、1%、5% 和 10% 的统计学显著性。