美团开源了分布式ID生成服务Leaf,今天*载下**了源码做了下研究,git*载下**地址是:https://github.com/Meituan-Dianping/Leaf,目前已经广泛用在各个事业部。
ID生成方式有两种,一种是通过DB生成,一种是通过雪花算法生成。
DB生成方式原理如下:
- 表结构设计了业务类型,最大ID,步长,更新时间,表结构可以参考下图
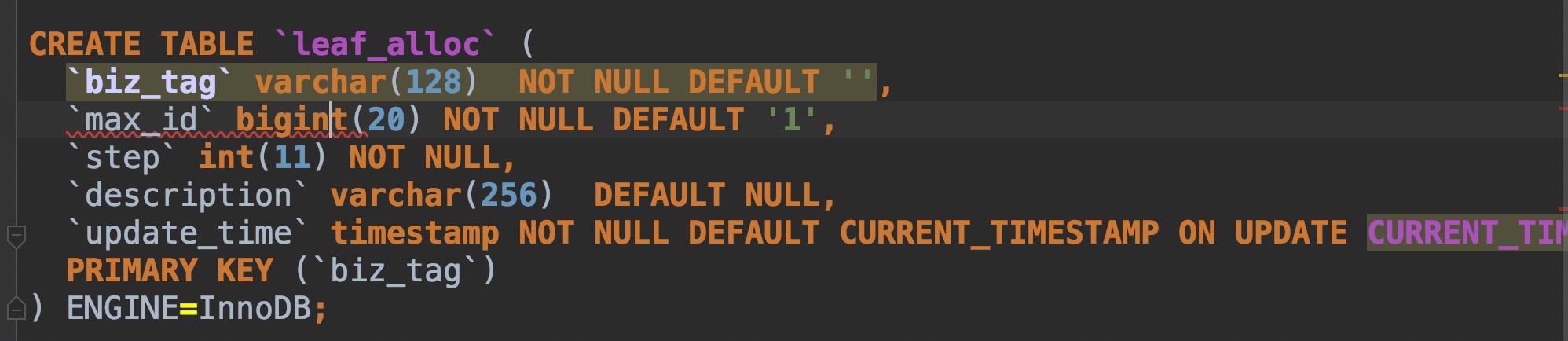
DB号段表结构
- 用户每次从db中根据自己的业务类型来获取步长大小的IDList,当用户get一个id的时候就会从给ID+1,如果达到最大值max_id的时候,就需要再次从db获取步长大小的IDList.此时更新max_id和时间即可。
- 为了做到高可用,考虑db有挂掉的情况,内部抽象了Segment概念,使用双buffer机制,当当前buffer使用了10%的时候,就开始更新下一个buffer,当当前buffer使用完毕就会切换下一个buffer使用。具体逻辑如下图。
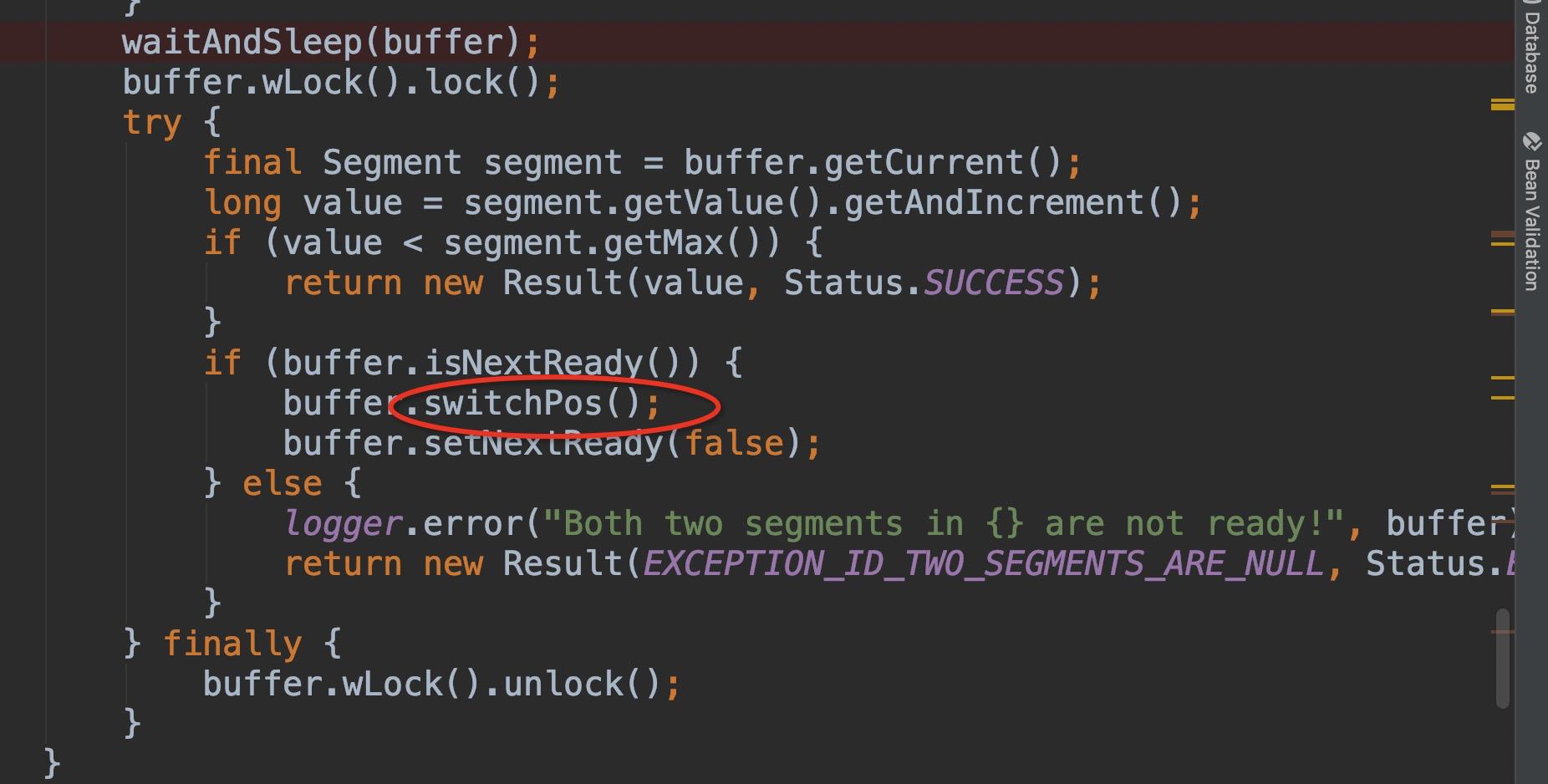
切换buffer
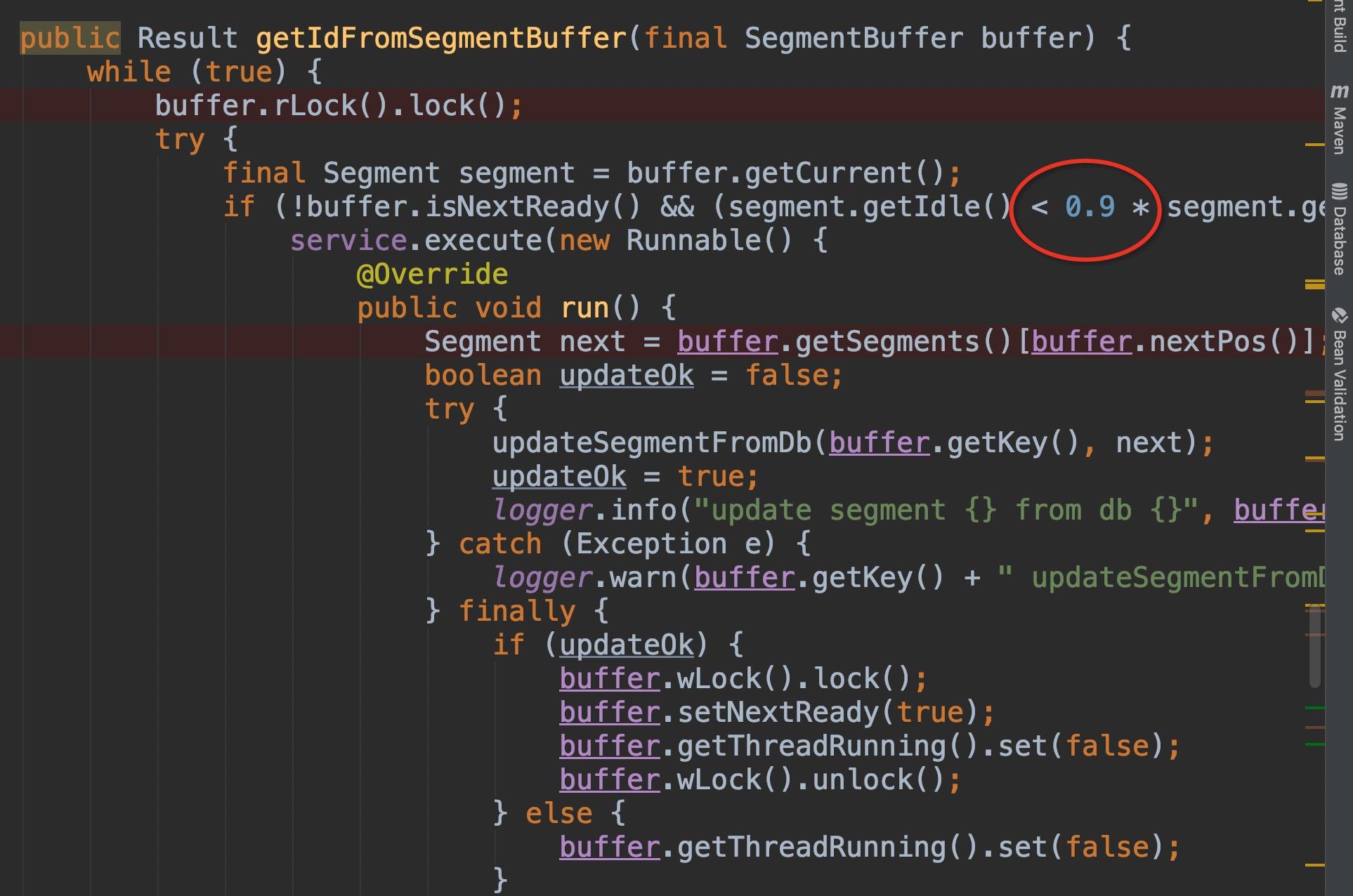
更新下一个buffer
雪花算法生成方式原理如下:
Snowflake,Twitter开源的一种分布式ID生成算法。基于64位数实现。第1位置为0。第2-42位是相对时间戳,通过当前时间戳减去一个固定的历史时间戳生成,第43-52位是机器号workerID,每个Server的机器ID不同,第53-64位是自增ID。Leaf算法内部其实简化了逻辑,43位到52位是可以有5位是机房id和5位机器id,在leaf内部只使用了workerId,最后的10位是自增ID,Leaf内部是使用的100以内的随机数。具体核心逻辑如下代码截图。

snowflake生成id
另外snowflake算法使用了zk来生成机器号,为来防止zk挂掉的情况,在生成workerid后会在本地保存一个workerId.properties文件,这样即使zk挂掉了也不影响号段生成。
使用方式:
db: curl http://localhost:8080/api/segment/get/test
雪花: curl http://localhost:8080/api/snowflake/get/test
其中test代表业务线的Biz_tag
监控:
curl http://localhost:8080/db

db信息展示
curl http://localhost:8080/cache

buffer cache信息展示
感谢阅读,如果您对我的文章感兴趣,欢迎关注我的公众号

@头条号