日前,Google举办的NLP比赛:Google Quest Q&A Labeling已在Kaggle发榜。
此次比赛的赛题是根据问答对,预测30个不同对label值, 这些label值是人工给问答对打上对标签,反映问题是否写得好,答案是否相关,是否有帮助,是否令人满意,是否包含明确的说明,等等。本次比赛提供的数据集包含数千个问答对,大部分来自StackExchange。
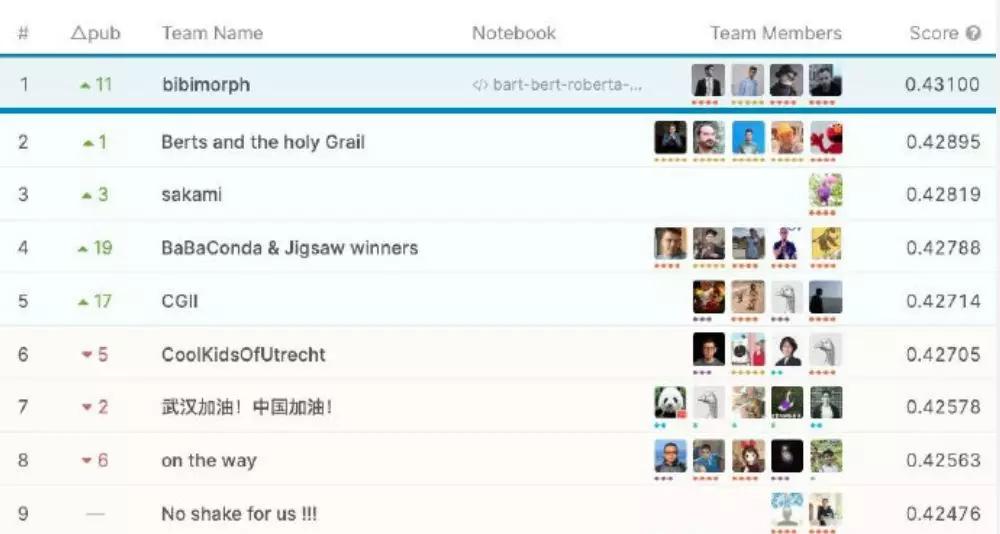
优胜队伍“Bibimorph”最近接受了采访,当被问到“本次比赛中你的团队最重要的发现是什么”时,他们的回答是“迁移学习”。
此外,他们还透露了赢得此次比赛的成功三要素:
1. Language model pre-training
2. Pseudo-labeling
3. Post-processing predictions
以下是详细解读:
language model pre-training
我们使用了一个额外的转储约7百万个StackExchange问题,通过一个掩模语言模型任务(MLM,详见BERT论文)和一个额外的句子顺序预测(SOP)任务(参考ALBERT论文)来微调BERT语言模型。
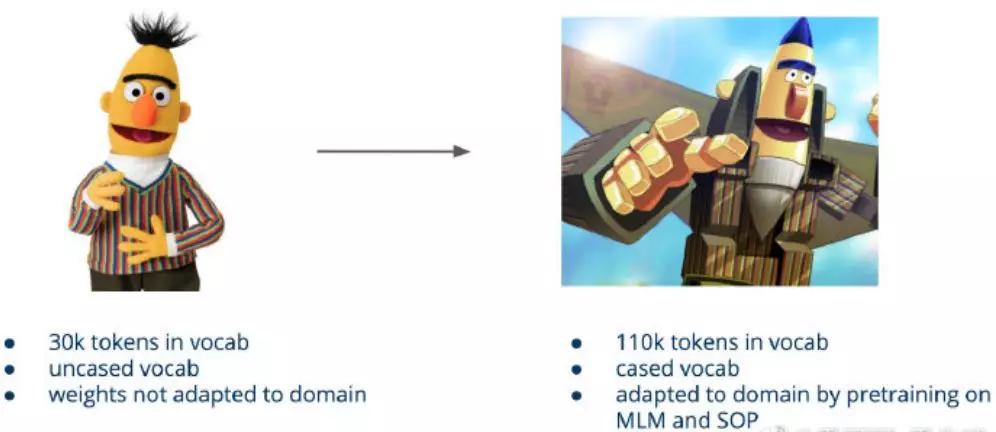
除此之外,我们还构建了额外的辅助目标——在微调LM的同时,我们还预测了5个target(question_score、question_view_count、question_favorite_count、answer_score、answers_count),这些target是我们基于StackExchange数据设计的。
我们使用了一个定制的扩展格式词汇表,原因很简单:StackExchange问题通常不仅包含纯粹的口语,还包含数学和代码。用LaTeX 扩展词汇表、一些数学公式和部分代码片段有助于捕捉这一事实。
总的来说,LM预训练的这一额外任务对于改进我们的模型起到了至关重要的作用,因为它有两个功能:
- 迁移学习。我们的模型在实际使用竞赛数据进行训练之前,已经“看到”了10倍以上的数据。
- 域适应。由于定制的词汇表和LM微调的辅助target,我们使我们的预训练模型更好地适应手头的数据。
pseudo-labeling
在Kaggle上,pseudo-labeling曾经是一个很酷很热门的话题,但是现在它已经是一个众所周知的常用技术了。
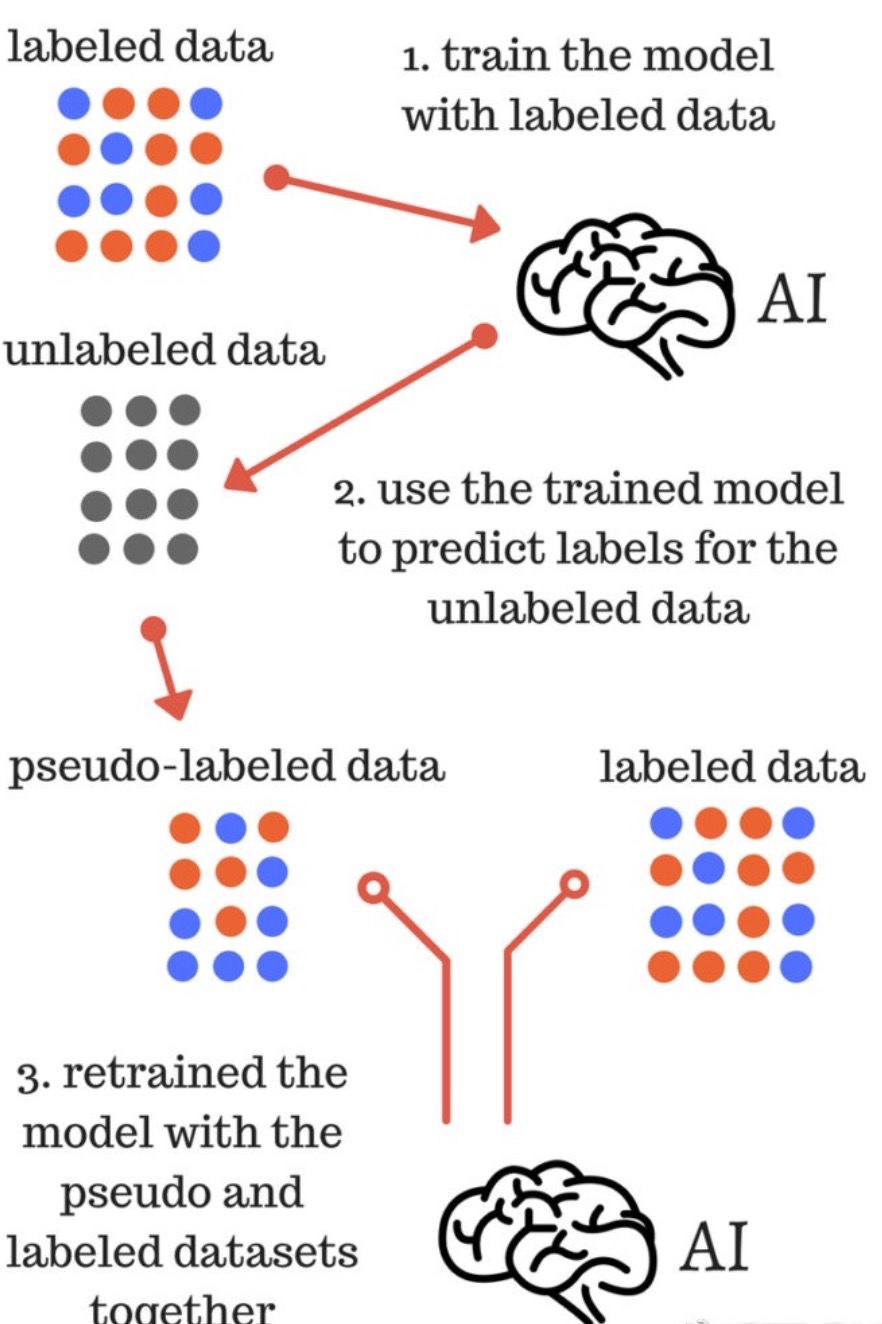
这个想法总结在上图中。简单地说,可以使用模型预测(对于某些未标记的数据集)作为“伪标签”来扩展现有的已标记的训练数据集。
我们使用来自StackExchange问题转储的20k和100k样本的伪标签来改进四个训练模型中的三个。
post-processing predictions
为比赛选择的度量标准是Spearman相关性。对于30个目标标签中的每一个,都会计算预测值与基本事实之间的Spearman相关性。然后,平均30个Spearman相关系数产生最终度量。
Spearman相关对某些预测是否相等非常敏感:

上面的玩具示例显示,可以将预测b的向量“阈值化”以生成b2,从而将其Spearman相关性与(基本事实)从0.89增加到1。
实际上,这是整个竞赛的缺点之一-目标指标对阈值预测之类的hack过于敏感。许多团队将各种阈值启发式方法应用于后处理,通常分别针对30个目标列中的每一个。
我们清楚地认识到这是过度拟合。但是,我们仍然对模型预测应用了一些后处理。
代替阈值预测,我们按照训练集中的分布将其离散化为多个bucket。这个想法是使特定目标列的预测分布与训练数据集中相应列的对应分布相匹配。
最后的解决方案是什么样的?
我们的基准模型几乎是普通BERT,在平均池化隐藏状态之上具有线性层。对于输入,我们仅传递了以特殊标记分隔的问题标题,问题正文和答案正文。

除上述三个“成功要素”外,其他一些hack包括针对所有BERT层(类似于ELMO)的隐藏状态的softmax归一化权重和多样本丢失。
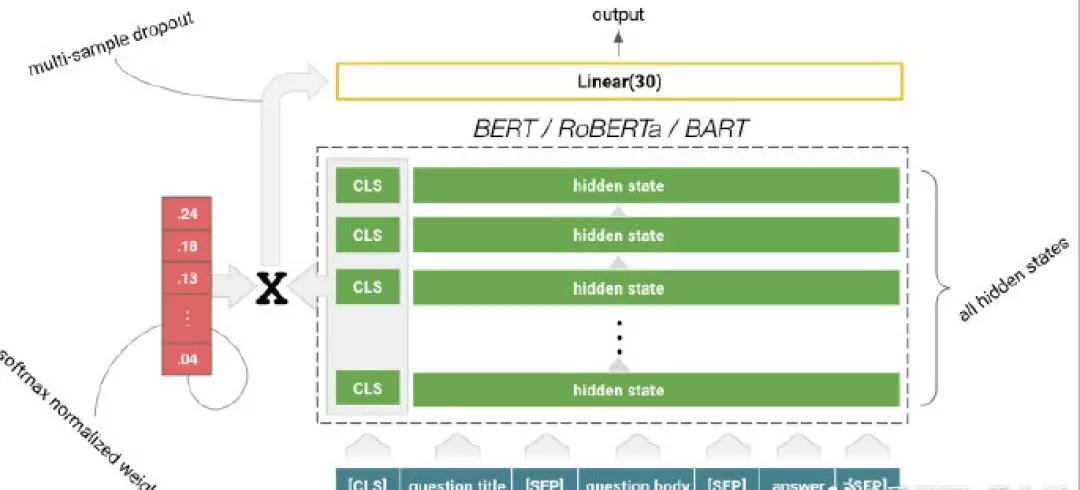
最终的解决方案是将四个模型(两个BERT基本模型,一个RoBERTa基本模型和一个BART大模型)的现成预测与上述三个“成功要素”混合在一起:预训练语言模型(“预训练”上标), 伪标签(“ pl”上标)和后处理预测。
这次比赛的经验教训有哪些?
- 不要太早参加比赛, 首先解决技术问题。
- 在小型训练数据集的情况下,应集中精力以适当的方式利用其他大型数据集。
- NLP中的迁移学习确实非常重要。它不仅适用于“计算机视觉”任务。
- 如果训练数据集很小,请特别注意验证,不要使用只会使您的解决方案不适合公开排行榜的黑客手段。
- 寻找可以在技能,方法,模型等方面为最终解决方案引入多样性的队友。
参考链接:
https://medium.com/kaggle-blog/the-3-ingredients-to-our-success-winners-dish-on-their-solution-to-googles-quest-q-a-labeling-c1a63014b88