温馨提示:要看高清*码无**套图,请使用手机打开并单击图片放大查看。
1.文档编写目的
在开发Hadoop应用时,需要用到hadoop-client API来访问HDFS并进行本地调试。本篇文章则主要讲述如何使用Java代码访问Kerberos和非Kerberos环境下HDFS服务。
- 内容概述
1.环境准备
2.非Kerberos及Kerberos环境连接示例
- 测试环境
1.Kerberos集群CDH5.11.2,OS为Redhat7.2
2.非Kerberos集群CDH5.13,OS为CentOS7.2
- 前置条件
1.CDH集群运行正常
2.环境准备
1.Maven依赖
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0-cdh5.11.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0-cdh5.11.2</version> </dependency>
2.创建访问HDFS集群的Keytab文件(非Kerberos集群可跳过此步)
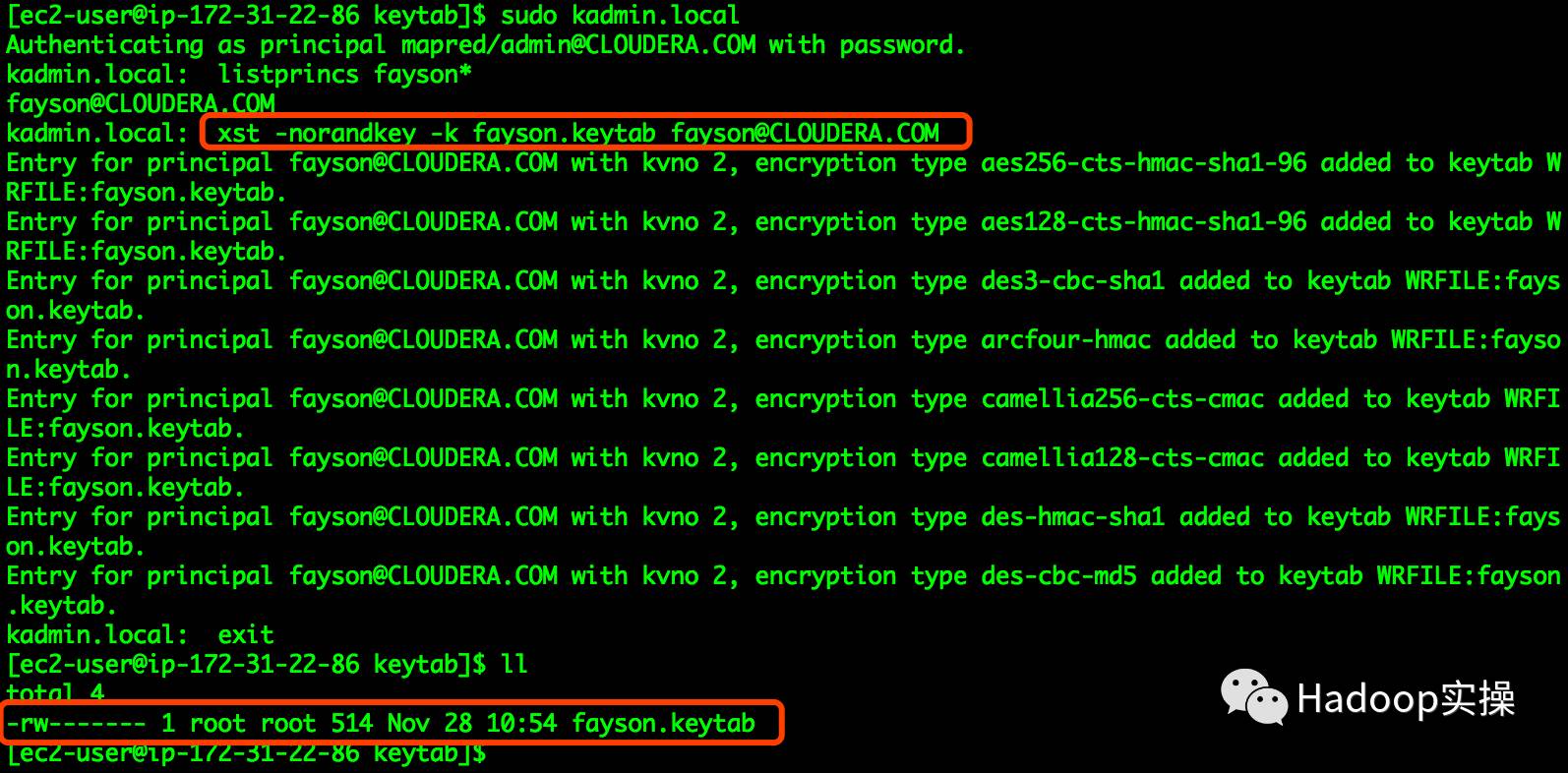
[ec2-user@ip-172-31-22-86 keytab]$ sudo kadmin.local Authenticating as principal mapred/admin@CLOUDERA.COM with password. kadmin.local: listprincs fayson* fayson@CLOUDERA.COM kadmin.local: xst -norandkey -k fayson.keytab fayson@CLOUDERA.COM ... kadmin.local: exit [ec2-user@ip-172-31-22-86 keytab]$ ll total 4 -rw------- 1 root root 514 Nov 28 10:54 fayson.keytab [ec2-user@ip-172-31-22-86 keytab]$
3.获取集群krb5.conf文件,内容如下(非Kerberos集群可跳过此步)
includedir /etc/krb5.conf.d/
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
default_realm = CLOUDERA.COM
#default_ccache_name = KEYRING:persistent:%{uid}
[realms]
CLOUDERA.COM = {
kdc = ip-172-31-22-86.ap-southeast-1.compute.internal
admin_server = ip-172-31-22-86.ap-southeast-1.compute.internal
}
4.配置hosts文件,确保本地开发环境与集群所有节点通且端口均放通(如8020等)
54.169.247.56 ip-172-31-22-86.ap-southeast-1.compute.internal 54.169.143.46 ip-172-31-26-102.ap-southeast-1.compute.internal 54.255.193.103 ip-172-31-21-45.ap-southeast-1.compute.internal 54.169.51.79 ip-172-31-26-80.ap-southeast-1.compute.internal
由于Fayson这里使用的是AWS环境所以hostname与外网的ip对应,这里会导致一个问题在向集群put数据文件时会失败,如果开发环境和HDFS都属于内网环境则不会有这个问题。后面Fayson又找了一台AWS的Windows机器执行代码才能成功执行。
5.通过Cloudera Manager*载下**HDFS客户端配置
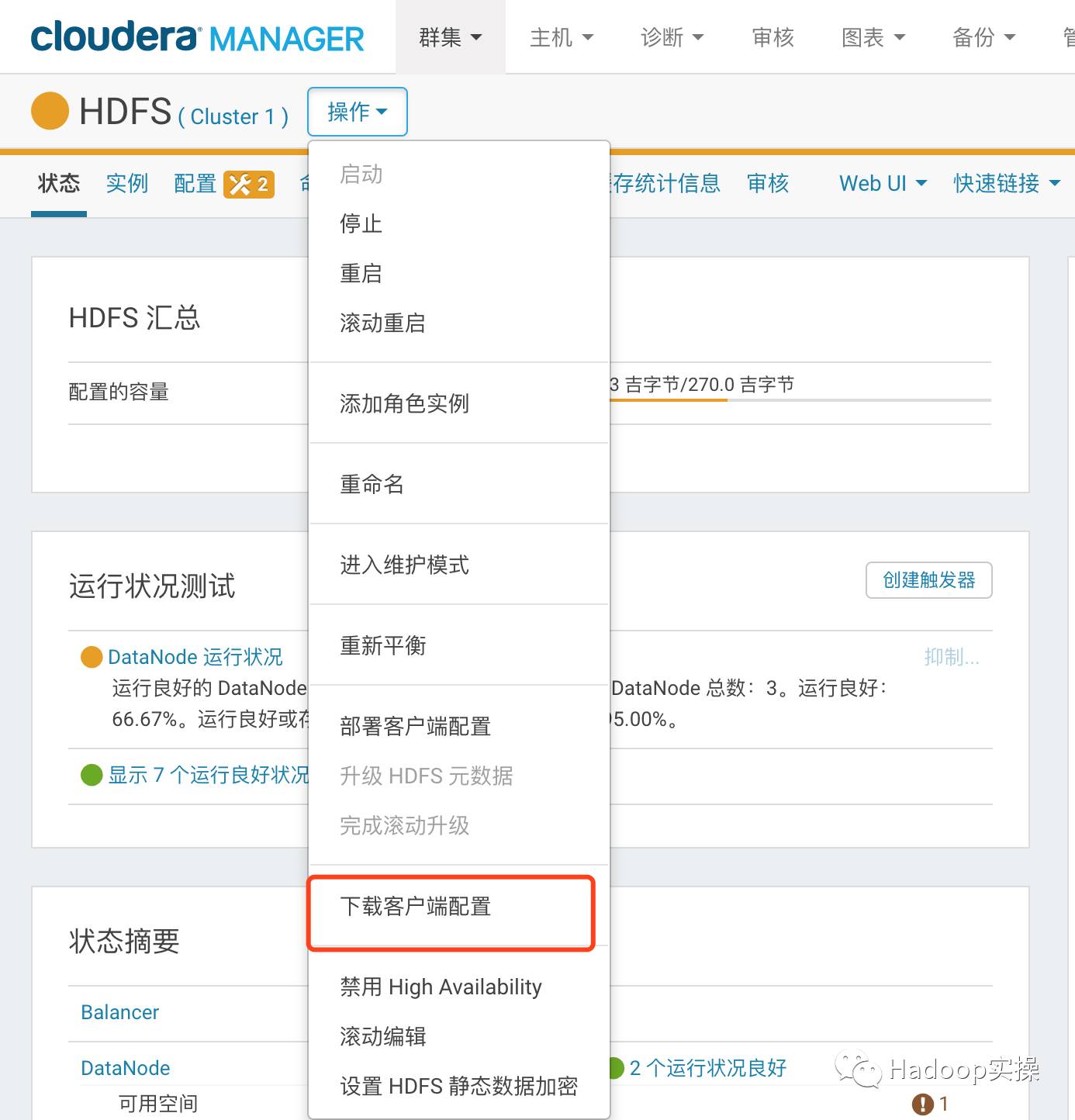
6.通过Cloudera Manager*载下**HDFS客户端配置
3.HDFS API工具类
这里Fayson将HDFS的一些常用方法作为一个工具类独立出来,下面无论是Kerberos环境还是非Kerberos环境都可以直接引用,也为后期其他的项目工程开发提供便利。该工具类主要是HDFS的一些常用操作,包括:创建文件,上传文件,删除文件,创建目录,读取HDFS文件等。
package com.cloudera.hdfs.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
/**
* package: com.cloudera.hdfs.utils
* describe: HDFS文件系统操作工具类
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/2
* creat_time: 下午10:39
* 公众号:Hadoop实操
*/
public class HDFSUtils {
/**
* 初始化HDFS Configuration
* @return configuration
*/
public static Configuration initConfiguration(String confPath) {
Configuration configuration = new Configuration();
System.out.println(confPath + File.separator + "core-site.xml");
configuration.addResource(new Path(confPath + File.separator + "core-site.xml"));
configuration.addResource(new Path(confPath + File.separator + "hdfs-site.xml"));
return configuration;
}
/**
* 向HDFS指定目录创建一个文件
*
* @param fs HDFS文件系统
* @param dst 目标文件路径
* @param contents 文件内容
*/
public static void createFile(FileSystem fs, String dst, String contents) {
try {
Path path = new Path(dst);
FSDataOutputStream fsDataOutputStream = fs.create(path);
fsDataOutputStream.write(contents.getBytes());
fsDataOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 上传本地文件至HDFS
* @param fs HDFS文件系统
* @param src 源文件路径
* @param dst 目标文件路径
*/
public static void uploadFile(FileSystem fs, String src, String dst) {
try {
Path srcPath = new Path(src); //原路径
Path dstPath = new Path(dst); //目标路径
//调用文件系统的文件复制函数,前面参数是指是否删除原文件,true为删除,默认为false
fs.copyFromLocalFile(false,srcPath, dstPath);
//打印文件路径
System.out.println("------------list files------------"+"\n");
FileStatus[] fileStatus = fs.listStatus(dstPath);
for (FileStatus file : fileStatus) {
System.out.println(file.getPath());
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 文件重命名
* @param fs
* @param oldName
* @param newName
* @throws IOException
*/
public static void rename(FileSystem fs, String oldName,String newName) {
try {
Path oldPath = new Path(oldName);
Path newPath = new Path(newName);
boolean isok = fs.rename(oldPath, newPath);
if(isok){
System.out.println("rename ok!");
}else{
System.out.println("rename failure");
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除文件
* @param fs
* @param filePath
* @throws IOException
*/
public static void delete(FileSystem fs, String filePath) {
try {
Path path = new Path(filePath);
boolean isok = fs.deleteOnExit(path);
if(isok){
System.out.println("delete ok!");
}else{
System.out.println("delete failure");
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建HDFS目录
* @param fs
* @param path
*/
public static void mkdir(FileSystem fs,String path) {
try {
Path srcPath = new Path(path);
if (fs.exists(srcPath)) {
System.out.println("目录已存在");
return;
}
boolean isok = fs.mkdirs(srcPath);
if (isok) {
System.out.println("create dir ok!");
} else {
System.out.println("create dir failure");
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 读取HDFS文件
* @param fs
* @param filePath 文件路径
*/
public static void readFile(FileSystem fs, String filePath) {
try {
Path srcPath = new Path(filePath);
InputStream in = null;
in = fs.open(srcPath);
IOUtils.copyBytes(in, System.out, 4096, false); //复制到标准输出流
} catch (IOException e) {
e.printStackTrace();
}
}
}
4.非Kerberos环境
1.示例代码
package com.cloudera.hdfs.nonekerberos;
import com.cloudera.hdfs.utils.HDFSUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.File;
import java.io.IOException;
/**
* package: com.cloudera.hdfs.nonekerberos
* describe: 访问非Kerberos环境下的HDFS
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/2
* creat_time: 下午11:54
* 公众号:Hadoop实操
*/
public class NoneKBHDFSTest {
private static String confPath = System.getProperty("user.dir") + File.separator + "hdfsdemo" + File.separator + "conf";
public static void main(String[] args) {
//初始化HDFS Configuration 配置
Configuration configuration = HDFSUtils.initConfiguration(confPath);
try {
FileSystem fileSystem = FileSystem.get(configuration);
//创建目录
// HDFSUtils.mkdir(fileSystem, "/fayson");
//创建文件
HDFSUtils.createFile(fileSystem, "/fayson/test.txt", "123testaaaaaaaaaa");
//文件重命名
HDFSUtils.rename(fileSystem, "/fayson/test.txt", "/fayson/fayson.txt");
//查看文件
HDFSUtils.readFile(fileSystem, "/fayson/fayson.txt");
//删除文件
HDFSUtils.delete(fileSystem, "/fayson/fayson.txt");
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.示例运行
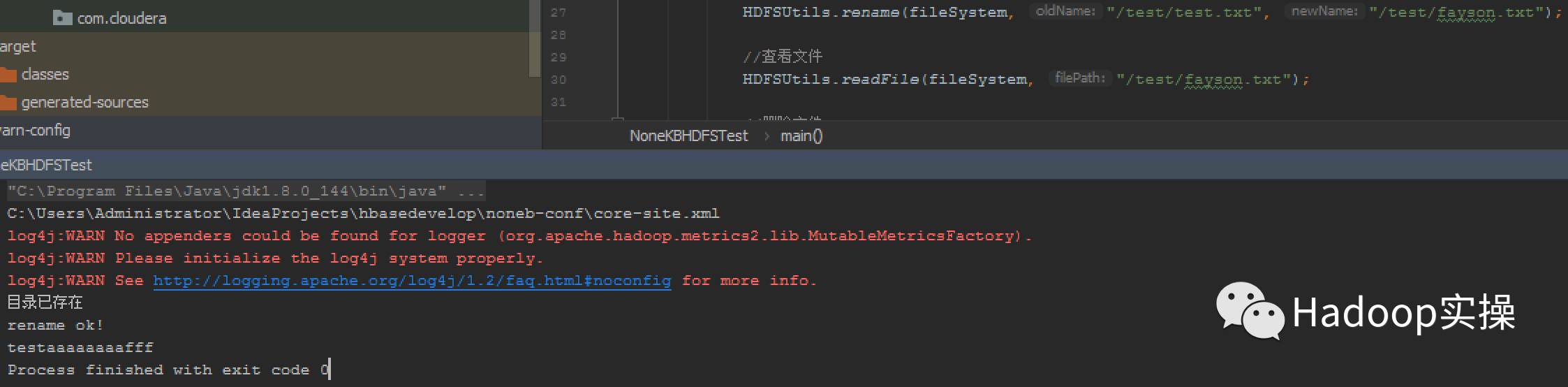
3.查看HDFS创建的目录及文件

5.Kerberos环境
1.示例代码运行
package com.cloudera.hdfs.kerberos;
import com.cloudera.hdfs.utils.HDFSUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.security.UserGroupInformation;
import java.io.File;
import java.io.IOException;
/**
* package: com.cloudera.hdfs.kerberos
* describe: 访问Kerberos环境下的HDFS
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/2
* creat_time: 下午11:54
* 公众号:Hadoop实操
*/
public class KBHDFSTest {
private static String confPath = System.getProperty("user.dir") + File.separator + "hdfsdemo" + File.separator + "kb-conf";
public static void main(String[] args) {
//初始化HDFS Configuration 配置
Configuration configuration = HDFSUtils.initConfiguration(confPath);
//初始化Kerberos环境
initKerberosENV(configuration);
try {
FileSystem fileSystem = FileSystem.get(configuration);
//创建目录
HDFSUtils.mkdir(fileSystem, "/test");
//上传本地文件至HDFS目录
// HDFSUtils.uploadFile(fileSystem, "/Volumes/Transcend/keytab/schema.xml", "/test");
//文件重命名
HDFSUtils.rename(fileSystem, "/test/item.csv", "/test/fayson.csv");
//查看文件
HDFSUtils.readFile(fileSystem, "/test/fayson.csv");
//删除文件
HDFSUtils.delete(fileSystem, "/test/fayson.csv");
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 初始化Kerberos环境
*/
public static void initKerberosENV(Configuration conf) {
System.setProperty("java.security.krb5.conf", "/Volumes/Transcend/keytab/krb5.conf");
System.setProperty("javax.security.auth.useSubjectCredsOnly", "false");
// System.setProperty("sun.security.krb5.debug", "true");
try {
UserGroupInformation.setConfiguration(conf);
UserGroupInformation.loginUserFromKeytab("fayson@CLOUDERA.COM", "/Volumes/Transcend/keytab/fayson.keytab");
System.out.println(UserGroupInformation.getCurrentUser());
} catch (IOException e) {
e.printStackTrace();
}
}
}
2.示例运行
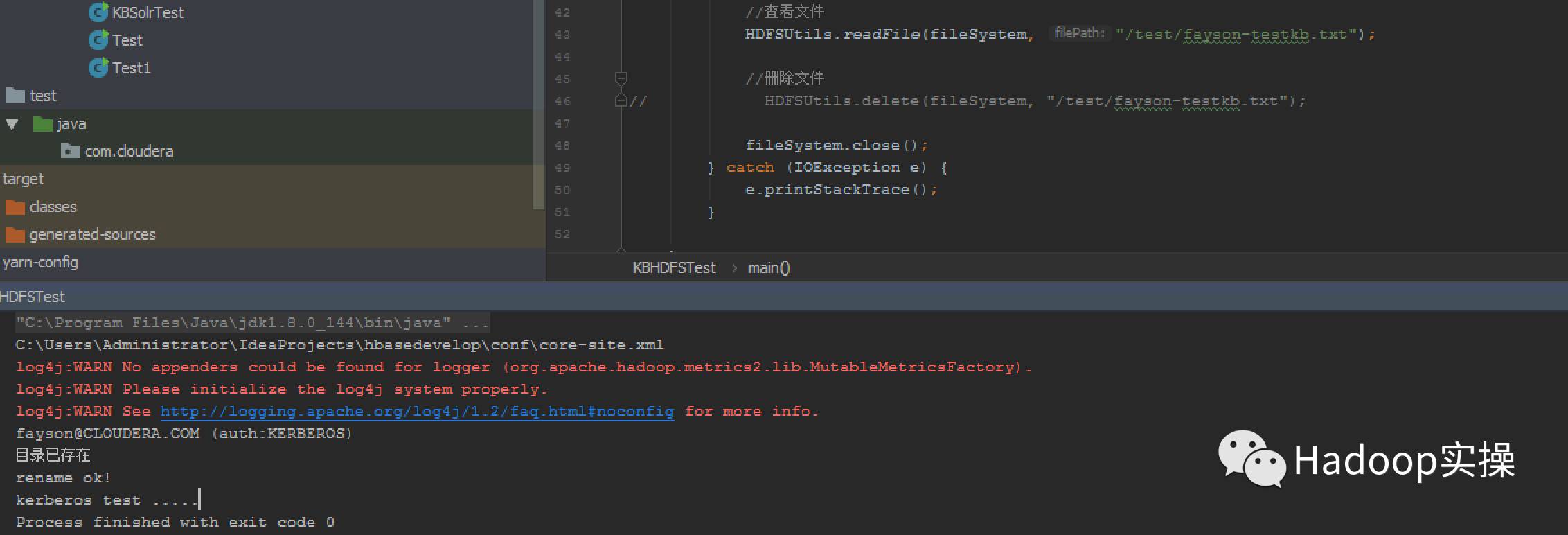
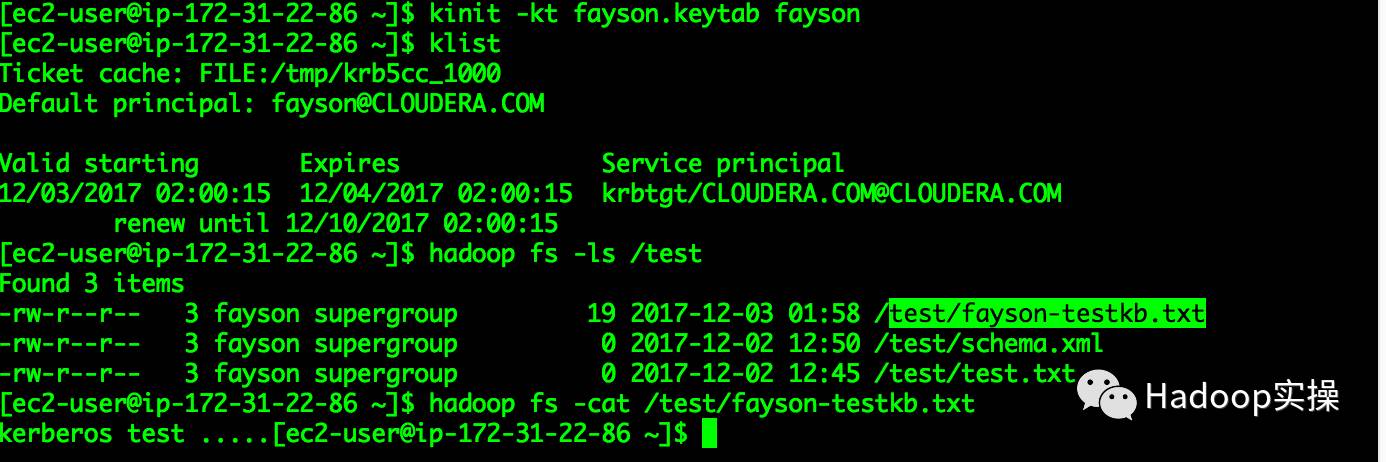
3.查看HDFS创建的目录及文件
6.总结
在进行本地开发时,必须将集群的hostname及IP配置在本地的hosts文件中(如果使用DNS服务则可以不配置hosts文件),否则无法与集群互通,确保本地客户端与集群的端口是放通的。
GitHub源码地址:
https://github.com/javaxsky/cdhproject
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清*码无**套图,请使用手机打开并单击图片放大查看。
您可能还想看
安装
CENTOS6.5安装CDH5.12.1(一)
CENTOS6.5安装CDH5.12.1(二)
CENTOS7.2安装CDH5.10和Kudu1.2(一)
CENTOS7.2安装CDH5.10和Kudu1.2(二)
如何在CDH中安装Kudu&Spark2&Kafka
如何升级Cloudera Manager和CDH
如何卸载CDH(附一键卸载github源码)
如何迁移Cloudera Manager节点
如何在Windows Server2008搭建DNS服务并配置泛域名解析
安全
如何在CDH集群启用Kerberos
如何在Hue中使用Sentry
如何在CDH启用Kerberos的情况下安装及使用Sentry(一)
如何在CDH启用Kerberos的情况下安装及使用Sentry(二)
如何在CDH未启用认证的情况下安装及使用Sentry
如何使用Sentry管理Hive外部表权限
如何使用Sentry管理Hive外部表(补充)
如何在Kerberos与非Kerberos的CDH集群BDR不可用时复制数据
Windows Kerberos客户端配置并访问CDH
数据科学
如何在CDSW中使用R绘制直方图
如何使用Python Impyla客户端连接Hive和Impala
如何在CDH集群安装Anaconda&搭建Python私有源
如何使用CDSW在CDH中分布式运行所有R代码
如何使用CDSW在CDH集群通过sparklyr提交R的Spark作业
如何使用R连接Hive与Impala
如何在Redhat中安装R的包及搭建R的私有源
如何在Redhat中配置R环境
什么是sparklyr
其他
CDH网络要求(Lenovo参考架构)
大数据售前的中年危机
如何实现CDH元数据库MySQL的主备
如何在CDH中使用HPLSQL实现存储过程
如何在Hive&Impala中使用UDF
Hive多分隔符支持示例
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。

原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操