温馨提示:要看高清*码无**套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
最近后台有位兄弟向Fayson提了一个问题,原文如下:
“就是我的hdfs机器配置两个ip,一个外部可以访问,一个内部互联的地址,机器的hostname都是配置内网地址,现在有一个集群外的机器要写hdfs文件,发现namenode分配的datanode的地址是内网地址,不能访问到,这个不知道怎么去配置了。”
Fayson想了想这个问题其实在各个环境是都可能碰到的,于是在这篇文章给大家系统介绍一下。
在做Hadoop应用开发时有多种方式访问HDFS文件系统(如:FileSystem、WebHdfsFileSystem),Fayson前面的文章《
如何使用Java代码访问HDFS.docx
》已讲过使用FileSystem访问HDFS。另外一种基于REST的API实现,分为两种一种是Hortonworks提供的WebHDFS默认的与Hadoop集成,一种是Cloudera 提供的HttpFS需要安装独立的HttpFS服务。本篇文章主要介绍如何使用WebHdfs和HttpFS方式访问HDFS。两种方式具体架构如下图:
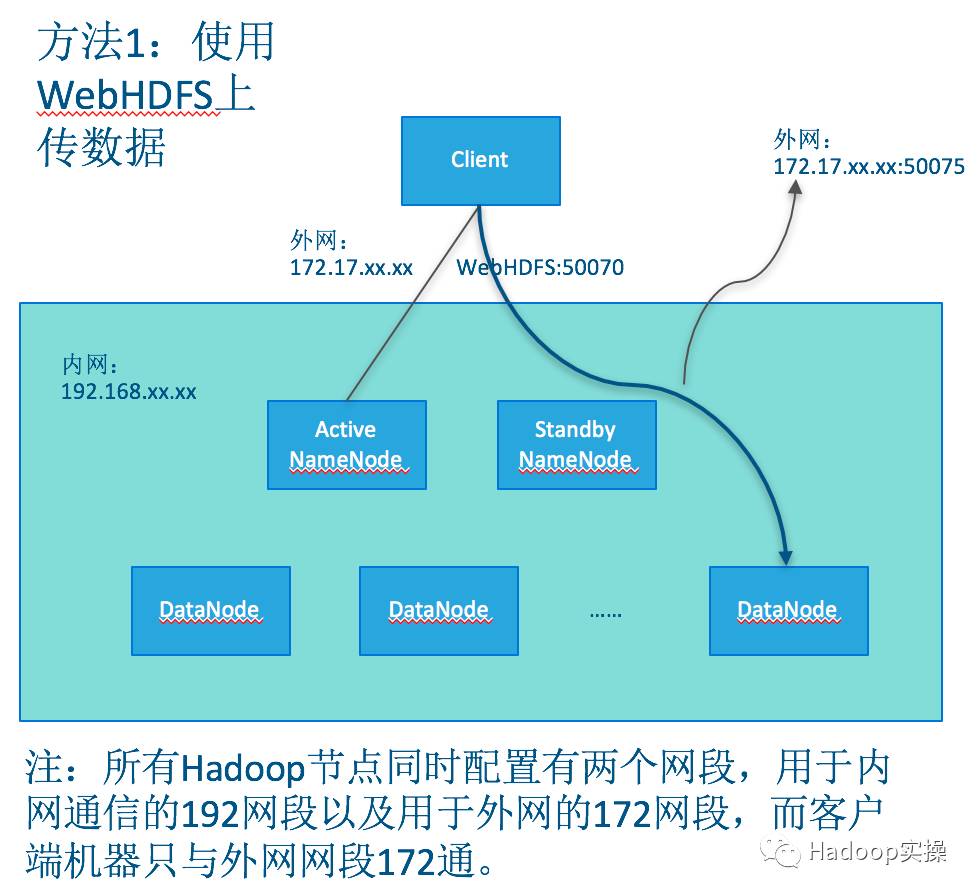
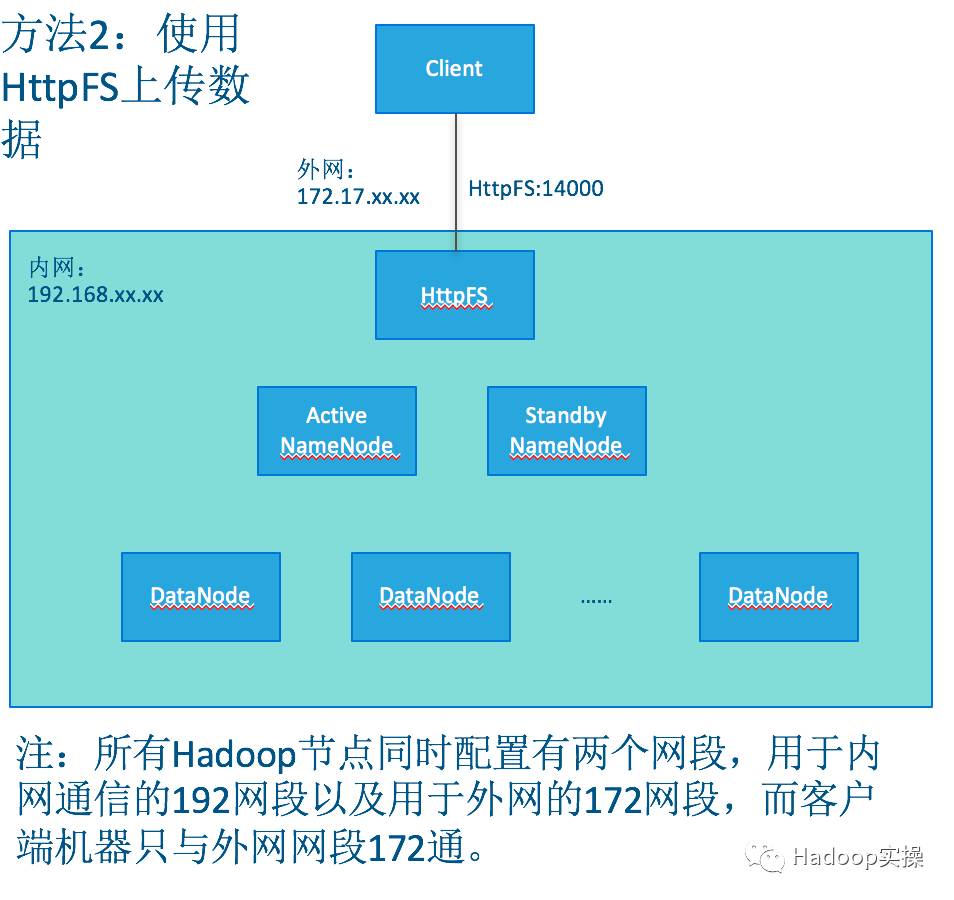
- 内容概述
1.WebHDFS和HttpFS访问HDFS
2.常见问题
3.总结
- 测试环境
1.CM和CDH版本为5.13.1
2.采用root用户操作
前置条件
1.HDFS已安装HttpFS服务
2.集群已启用高可用
3.集群未启用Kerberos
2.HDFS NameNode状态
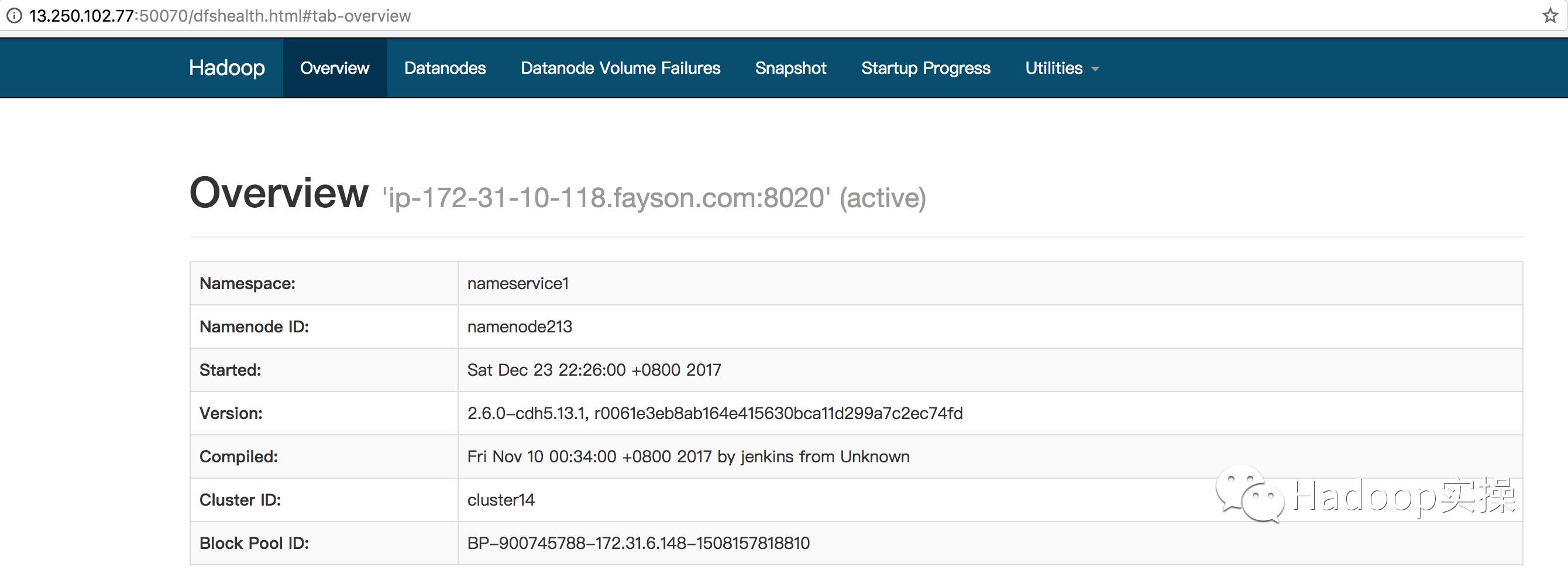
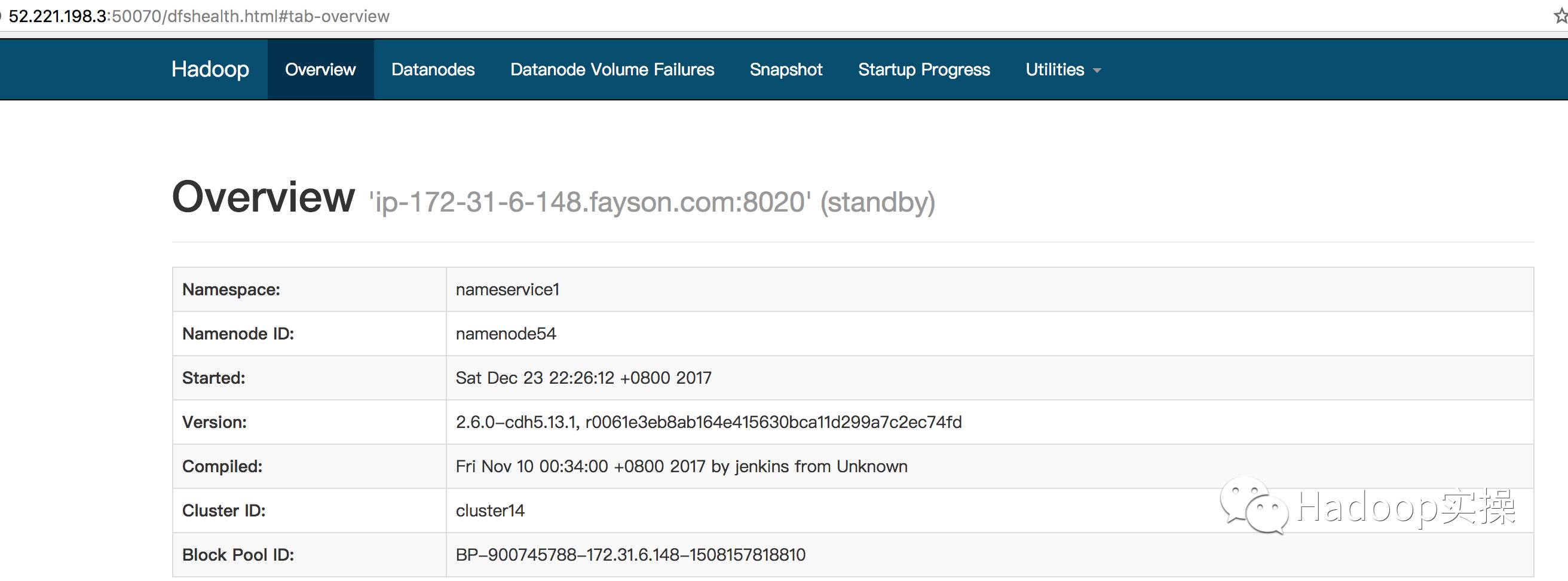
3.WebHDFS访问HDFS
1.java代码实现如下,提示:代码块部分可以左右滑动查看噢
package com.cloudera.hdfs.nonekerberos;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.web.WebHdfsFileSystem;
import java.io.IOException;
import java.net.URI;
/**
* package: com.cloudera.hdfs.nonekerberos
* describe: 使用WebHDFSFileystem的方式访问Hadoop集群的文件系统
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/21
* creat_time: 下午11:51
* 公众号:Hadoop实操
*/
public class WebHDFSTest {
public static void main(String[] args) {
Configuration configuration = new Configuration();
WebHdfsFileSystem webHdfsFileSystem = new WebHdfsFileSystem();
try {
webHdfsFileSystem.initialize(new URI("http://13.250.102.77:50070"), configuration);
System.out.println(webHdfsFileSystem.getUri());
//向HDFS Put文件
webHdfsFileSystem.copyFromLocalFile(new Path("/Users/fayson/Desktop/run-kafka"), new Path("/fayson1"));
//列出HDFS根目录下的所有文件
FileStatus[] fileStatuses = webHdfsFileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath().getName());
}
webHdfsFileSystem.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
本段代码主要写了使用WebHdfs提供的API接口访问HDFS,向HDFS的/fayson1目录下put文件,并列出HDFS根目录下所有文件。
2.本地目录待上传文件
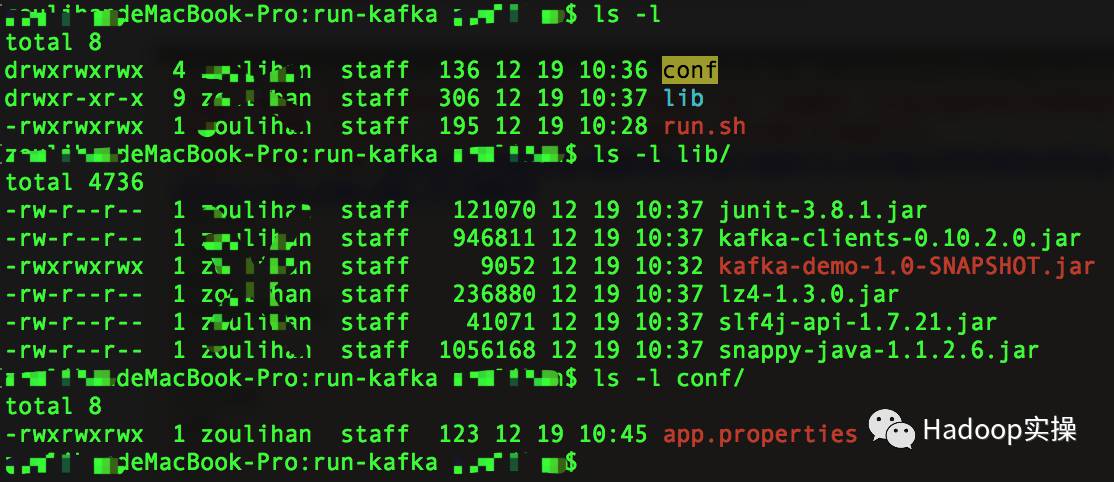
3.执行代码前HDFS根目录
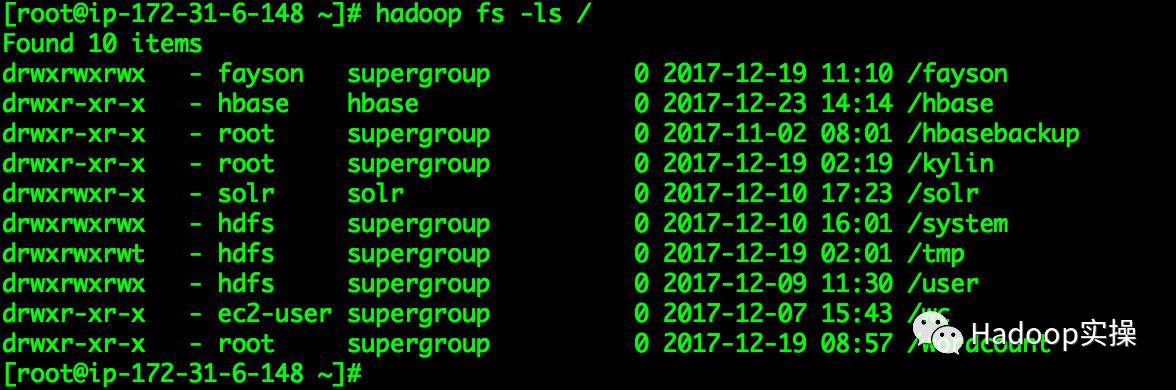
4.在Intellij中运行代码,执行结果如下
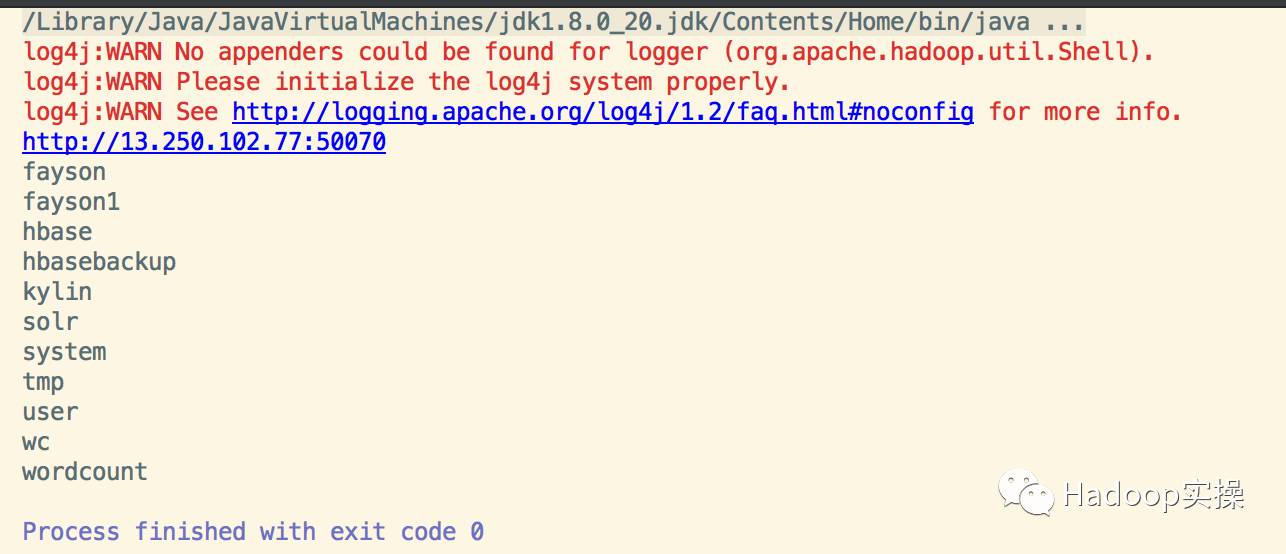
5.查看HDFS的数据目录
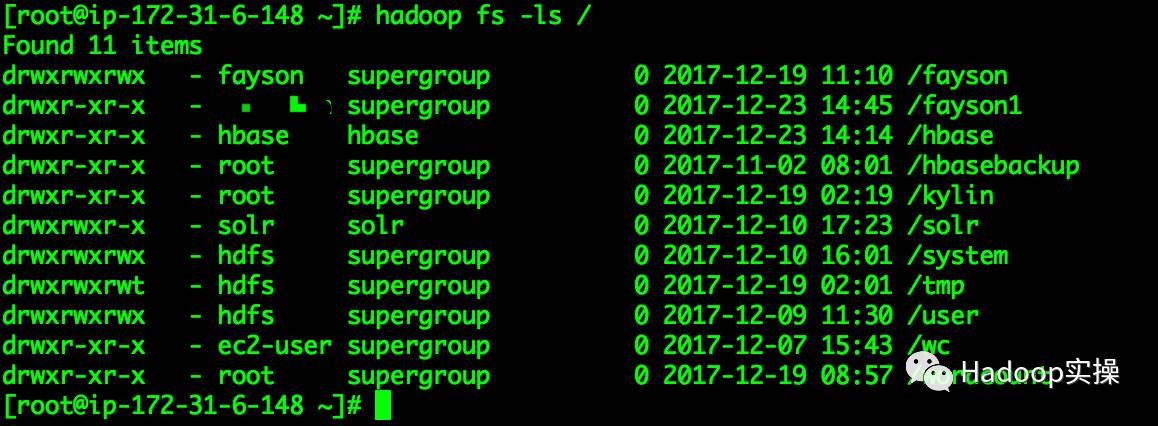
与代码执行返回结果一致。查看put的数据文件
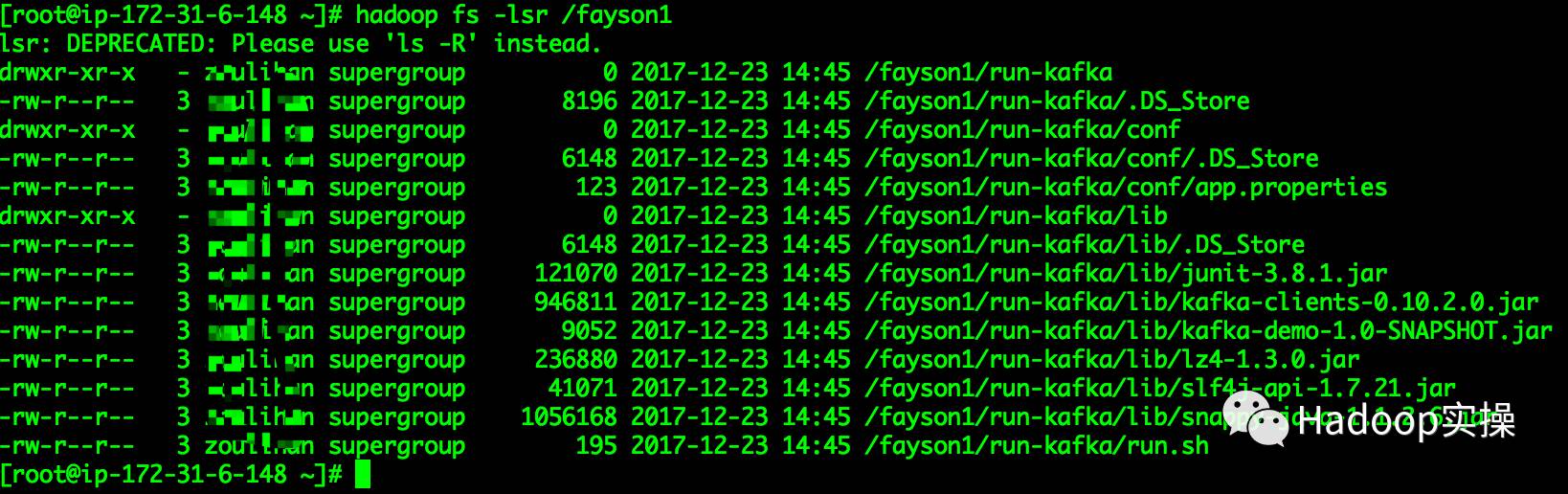
6.将代码里面访问的webhdfs修改为另外一个NameNode的Ip地址测试
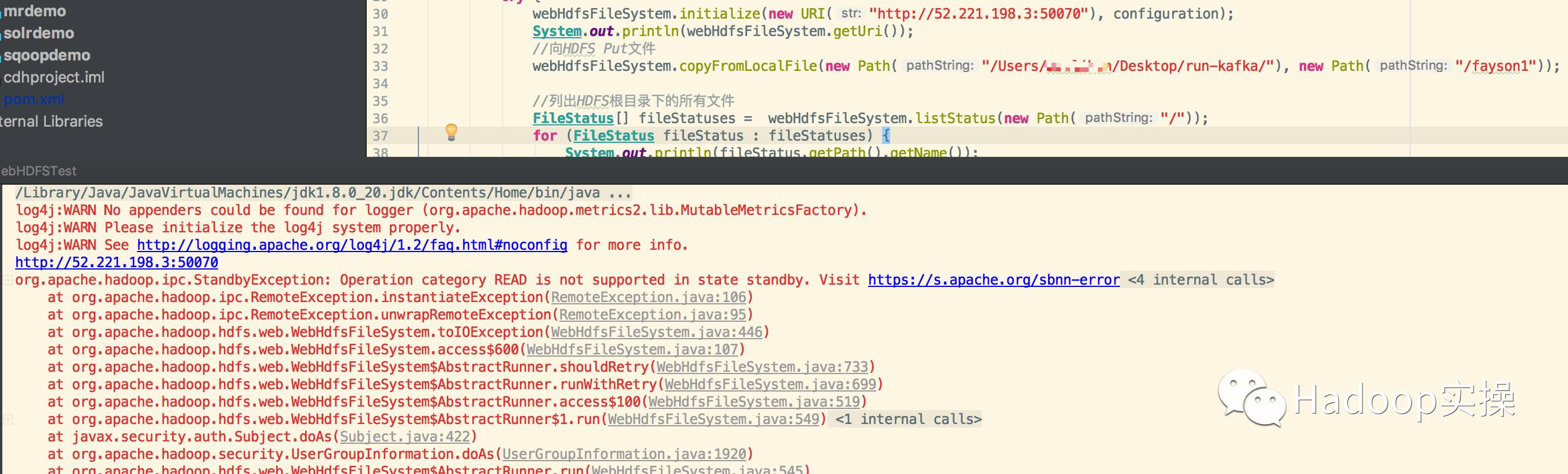
选择另外一个Standby状态的NameNode不能够正常访问HDFS,需要指定Active状态的NameNode,API接口才能正常调用。
4.HttpFS访问HDFS
我们使用同样的webhdfs访问HDFS的代码,这里只需要将访问地址修改为HttpFS服务所在的服务器ip及端口即可。
1.HttpFs服务
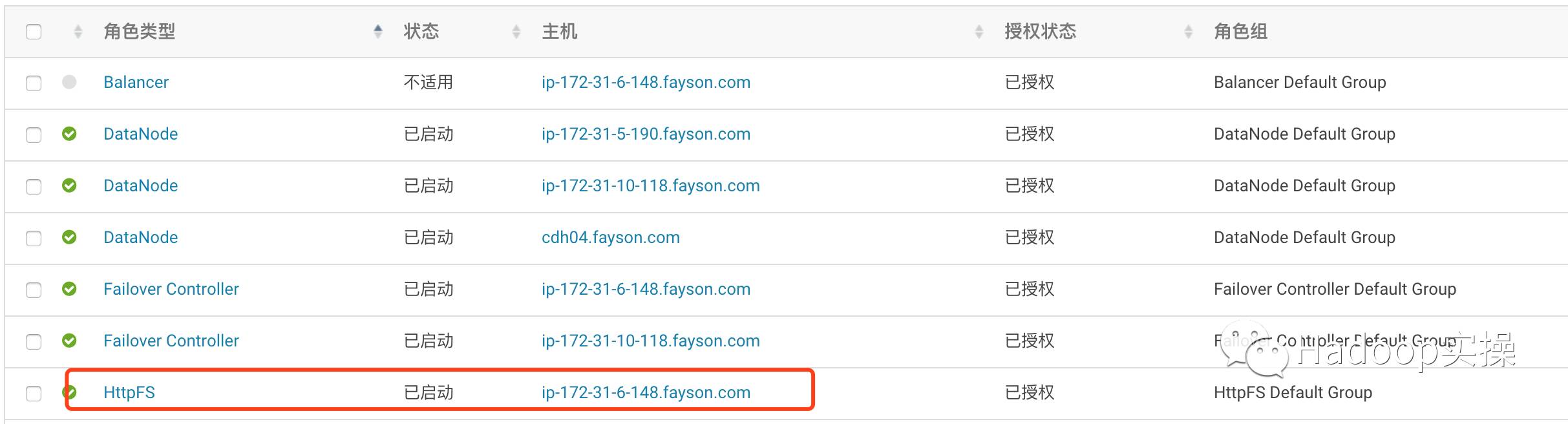
由于Fayson使用的是AWS服务器,所以ip-172-31-6-148.fayson.com对应的公网IP地址为:52.221.198.3,HttpFS服务的端口号为14000。我们将代码里面的访问地址修改为http://52.221.198.3:14000
2.java代码实现如下,提示:代码块部分可以左右滑动查看噢
package com.cloudera.hdfs.nonekerberos;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.web.WebHdfsFileSystem;
import org.apache.hadoop.security.UserGroupInformation;
import java.net.URI;
/**
* package: com.cloudera.hdfs.nonekerberos
* describe: 使用Cloudera HttpFS提供的API接口访问HDFS
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/23
* creat_time: 下午11:06
* 公众号:Hadoop实操
*/
public class HttpFSDemo {
public static void main(String[] args) {
Configuration configuration = new Configuration();
UserGroupInformation.createRemoteUser("fayson");
WebHdfsFileSystem webHdfsFileSystem = new WebHdfsFileSystem();
try {
webHdfsFileSystem.initialize(new URI("http://52.221.198.3:14000"), configuration);
System.out.println(webHdfsFileSystem.getUri());
//向HDFS Put文件
webHdfsFileSystem.copyFromLocalFile(new Path("/Users/fayson/Desktop/run-kafka/"), new Path("/fayson1-httpfs"));
//列出HDFS根目录下的所有文件
FileStatus[] fileStatuses = webHdfsFileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath().getName());
}
webHdfsFileSystem.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码中实现的逻辑与webhdfs代码一样,将本地run-kafka目录下的所有问题put到HDFS的/fayson1-httpfs目录下,并列出HDFS根目录下的所有文件。
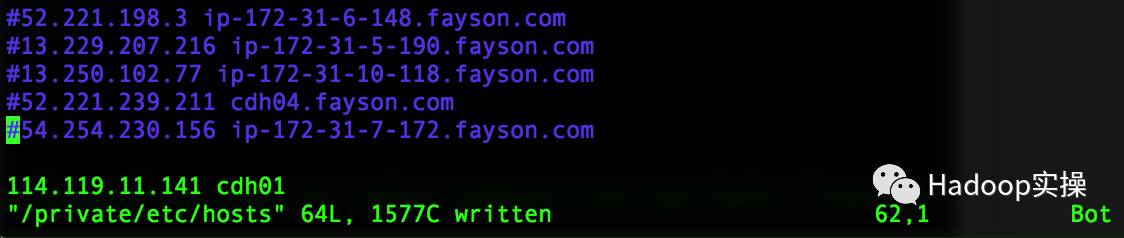
3.将本地hosts配置集群的信息注释掉
4.在Intellij中运行代码,执行结果如下:
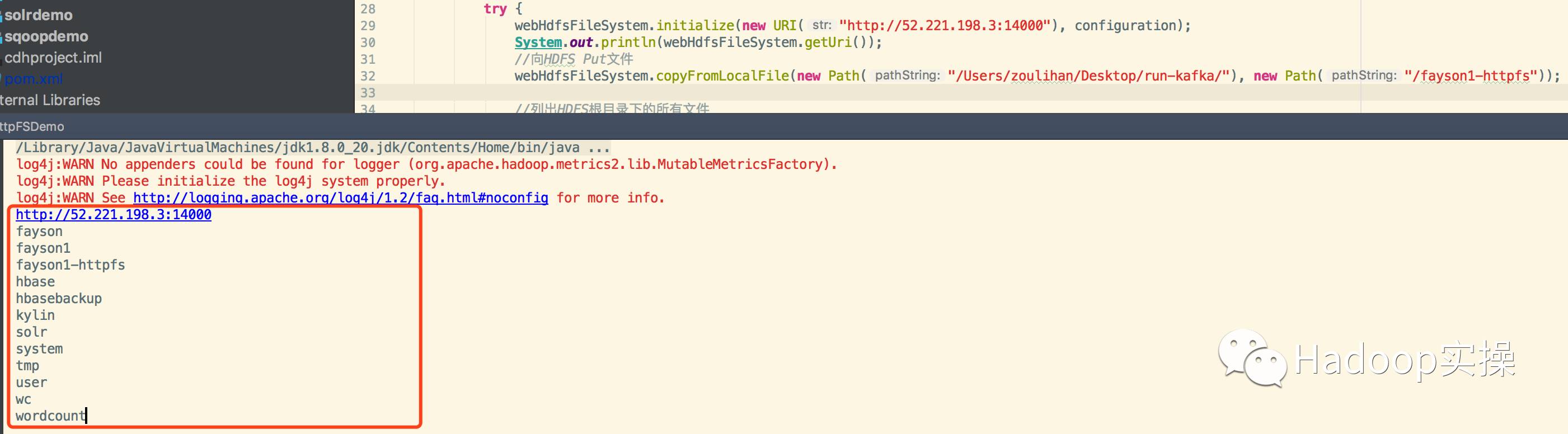
5.查看HDFS根目录
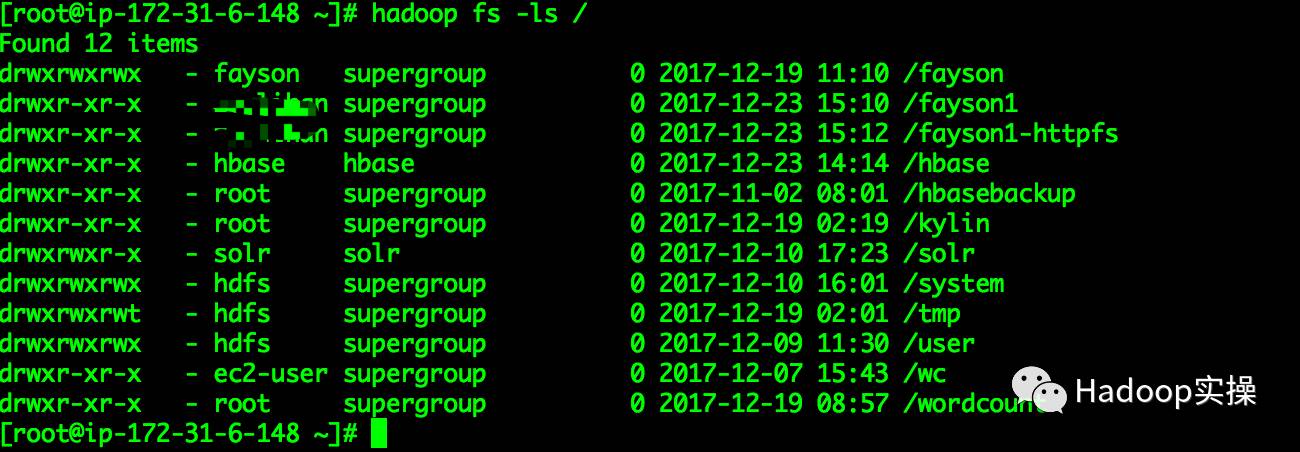
HDFS的根目录信息与代码执行结果一致
6.查看/fayson1-httpfs目录文件
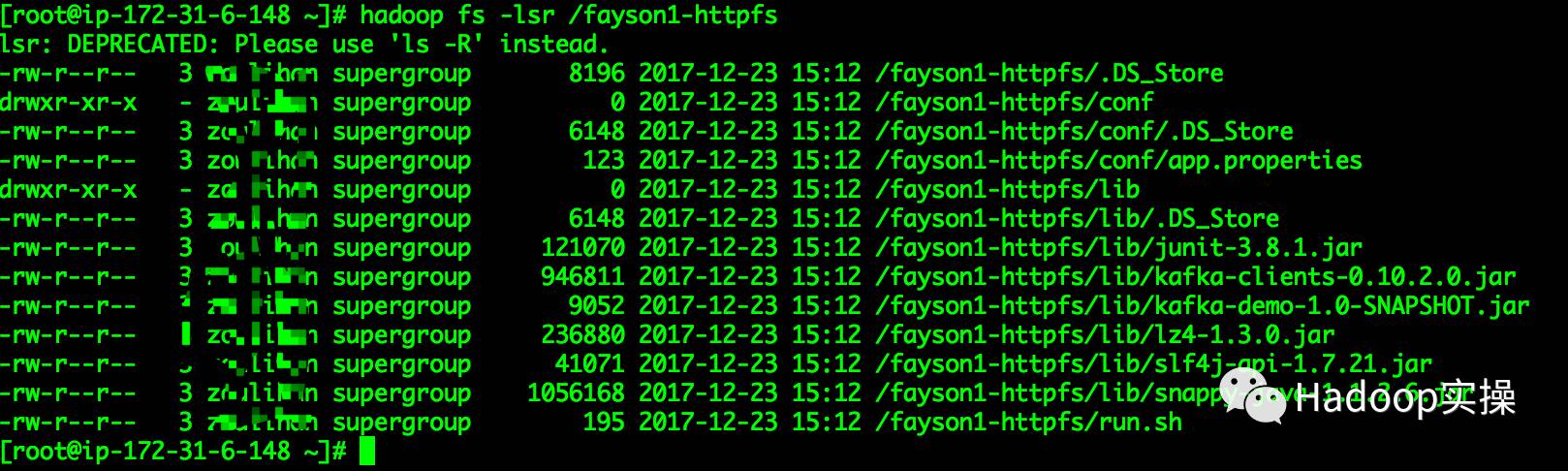
/fayson1-httpfs目录文件与本地run-kafka目录内容一致。
5.常见问题
1.使用webhdfs向HDFS put数据时异常,提示:代码块部分可以左右滑动查看噢
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. http://13.250.102.77:50070 java.net.UnknownHostException: cdh04.fayson.com:50075: cdh04.fayson.com at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:408) at org.apache.hadoop.hdfs.web.WebHdfsFileSystem$AbstractRunner.runWithRetry(WebHdfsFileSystem.java:693) at org.apache.hadoop.hdfs.web.WebHdfsFileSystem$AbstractRunner.access$100(WebHdfsFileSystem.java:519) at org.apache.hadoop.hdfs.web.WebHdfsFileSystem$AbstractRunner$1.run(WebHdfsFileSystem.java:549) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920) at org.apache.hadoop.hdfs.web.WebHdfsFileSystem$AbstractRunner.run(WebHdfsFileSystem.java:545) at org.apache.hadoop.hdfs.web.WebHdfsFileSystem.create(WebHdfsFileSystem.java:1252) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:925) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:906) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:803) at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:368) at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:359) at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:341) at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:2057) at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:2025) at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1990) at com.cloudera.hdfs.nonekerberos.WebHDFSTest.main(WebHDFSTest.java:31) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:483) at com.intellij.rt*ex.e**cution.application.AppMain.main(AppMain.java:147)
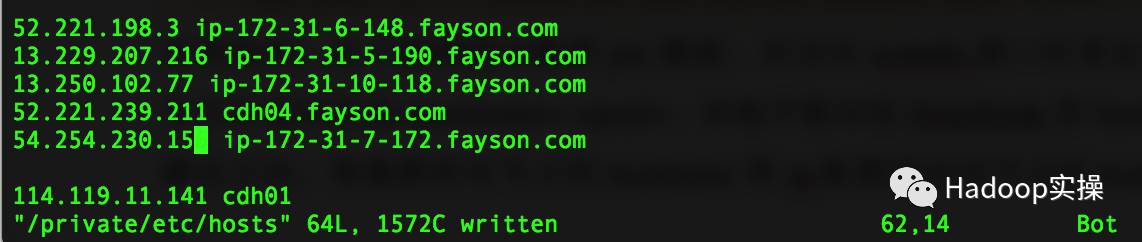
异常原因:由于跨网段向集群put数据,在访问wehdfs接口时重定向到具体DataNode节点时返回的是<hostname>:<port>,本地不能识别DataNode的hostname。
解决方法:将集群所有节点的hostname和外网ip配置到访问节点的hosts文件中
6.总结
- WebHdfs和HttpFS提供的API接口都可以在集群外的任意节点访问HDFS向集群Put文件及其它操作且不需要加载集群的配置信息(如hdfs-site.xml、core-site.xml等)。
- WebHdfs访问的限制有集群启用了高可用则必须访问Active状态的NameNode才可以访问HDFS。
- WebHdfs使用的是重定向的方式,访问具体的数据目录或其它操作时会重定向到集群的一个数据节点,这时就需要确保执行访问的节点和集群中所有的数据节点外网IP及端口是放通的,且需要配置本地hosts文件。比如Fayson在本文中使用的是AWS中DataNode的外网IP和hostname配置在本地。
- HttpFS提供的是一个独立的服务,在访问HDFS时只需要确保执行访问的节点和HttpFS服务所在节点的网络和端口是通的即可。
- 使用HttpFS访问HDFS时不需要考虑集群是否是高可用状态。
关于更多webhdfs的操作可以参考官网文档:http://hadoop.apache.org/docs/r1.0.4/webhdfs.html#CREATE
github地址:
https://github.com/fayson/cdhproject/blob/master/hdfsdemo/src/main/java/com/cloudera/hdfs/nonekerberos/HttpFSDemo.java
https://github.com/fayson/cdhproject/blob/master/hdfsdemo/src/main/java/com/cloudera/hdfs/nonekerberos/WebHDFSTest.java
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清*码无**套图,请使用手机打开并单击图片放大查看。
您可能还想看
安装
CENTOS6.5安装CDH5.12.1(一)
CENTOS6.5安装CDH5.12.1(二)
CENTOS7.2安装CDH5.10和Kudu1.2(一)
CENTOS7.2安装CDH5.10和Kudu1.2(二)
如何在CDH中安装Kudu&Spark2&Kafka
如何升级Cloudera Manager和CDH
如何卸载CDH(附一键卸载github源码)
如何迁移Cloudera Manager节点
如何在Windows Server2008搭建DNS服务并配置泛域名解析
安全
如何在CDH集群启用Kerberos
如何在Hue中使用Sentry
如何在CDH启用Kerberos的情况下安装及使用Sentry(一)
如何在CDH启用Kerberos的情况下安装及使用Sentry(二)
如何在CDH未启用认证的情况下安装及使用Sentry
如何使用Sentry管理Hive外部表权限
如何使用Sentry管理Hive外部表(补充)
如何在Kerberos与非Kerberos的CDH集群BDR不可用时复制数据
Windows Kerberos客户端配置并访问CDH
数据科学
如何在CDSW中使用R绘制直方图
如何使用Python Impyla客户端连接Hive和Impala
如何在CDH集群安装Anaconda&搭建Python私有源
如何使用CDSW在CDH中分布式运行所有R代码
如何使用CDSW在CDH集群通过sparklyr提交R的Spark作业
如何使用R连接Hive与Impala
如何在Redhat中安装R的包及搭建R的私有源
如何在Redhat中配置R环境
什么是sparklyr
其他
CDH网络要求(Lenovo参考架构)
大数据售前的中年危机
如何实现CDH元数据库MySQL的主备
如何在CDH中使用HPLSQL实现存储过程
如何在Hive&Impala中使用UDF
Hive多分隔符支持示例
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。

原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操