上一篇文章"一文参透神经网络及其实现,揭开深度学习的神秘面纱"我们介绍了单层神经网络--线性回归,本文将继续介绍另外两个单层神经网络。

文章大纲
1. 二分类神经网络--逻辑回归
1.1 从线性回归到逻辑回归
线性回归是通过拟合一条直线来描述数据之间的线性关系,但是现实中的大部分数据并不符合线性关系。
我们生活中存在着大量的分类问题,比如通过苹果的颜色判断苹果甜不甜,判断一封电子邮件是否为垃圾邮件等等。如果我们要用线性回归来解决分类问题,我们希望预测的结果为0或1,而线性回归的预测却远超出这个范围,因此线性回归并不能很好的完成分类任务,所以我们就要想办法将预测的值限定在一个范围内。
1.2 逻辑回归是什么
1.2.1 引入sigmoid函数
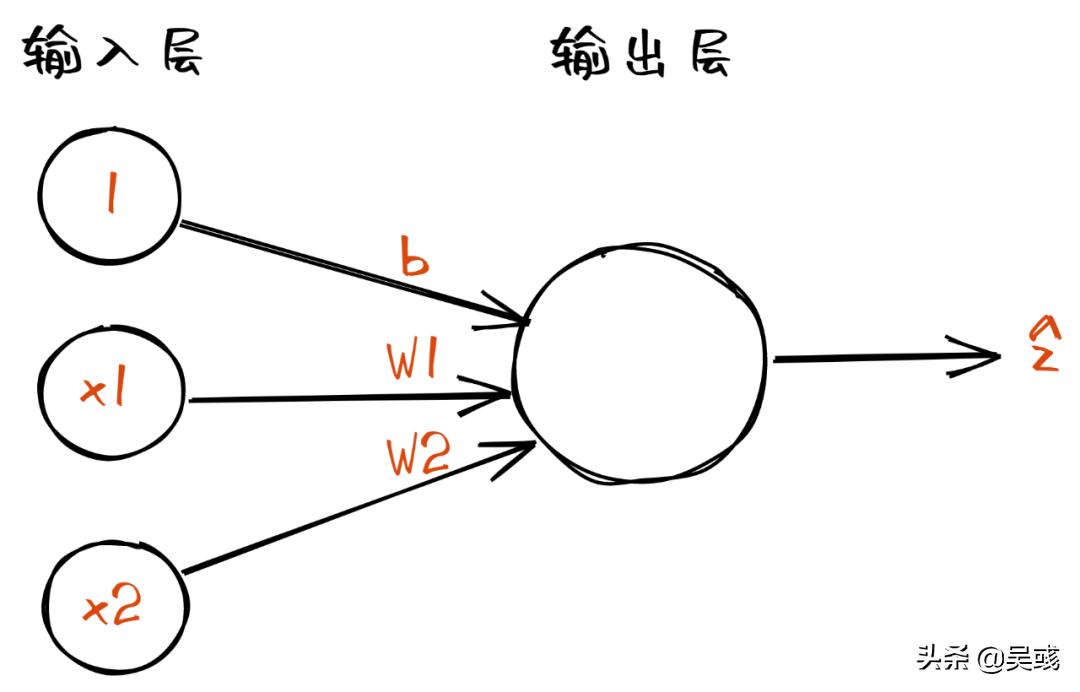
通过之前线性回归神经网络的架构图我们可以知道,其在输出层做的是累加求和的工作,也就是线性映射,并没有对输出的连续型数值做改动,那么我们就可以考虑可不可以在此基础上 做一个非线性映射,将输出的连续型变量映射到一个区间内,以此将之前输出的连续型变量转换为离散型变量 。那么说到输出的值在特定区间里,我们就想到了上篇文章中提到的 单位阶跃函数 。
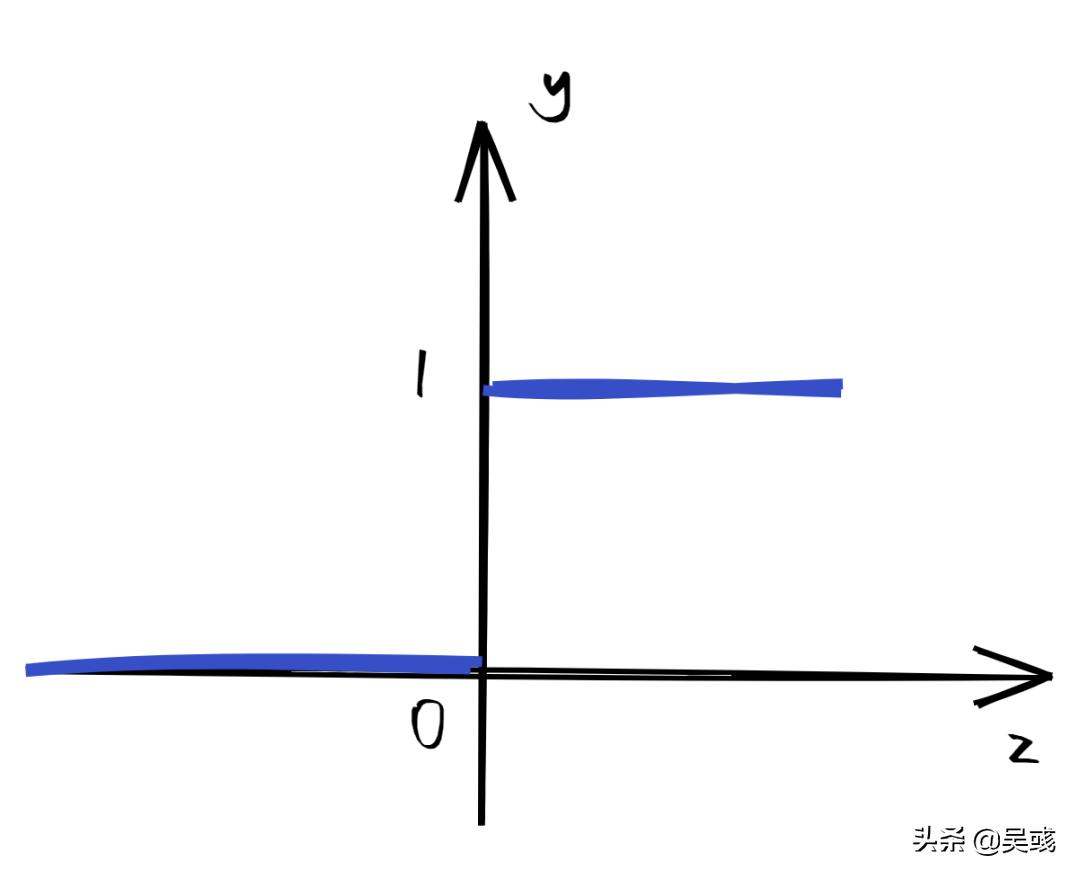
这个函数就完美的将输出限定在[0,1]之间,但是仔细观察我们可以发现,这个单位阶跃函数在0点是间断的♂️,这就导致了该函数在0处 不可微 ,而后续我们建立神经网络使用 反向传播算法(BP, Back propagation) 时,是需要计算梯度的,因此单位阶跃函数的数学性质并不好。后来科学家发现了一个宝藏函数✨---Logistic函数,因为函数图形形式“S”,又被称为 sigmoid函数 (S型曲线),如图
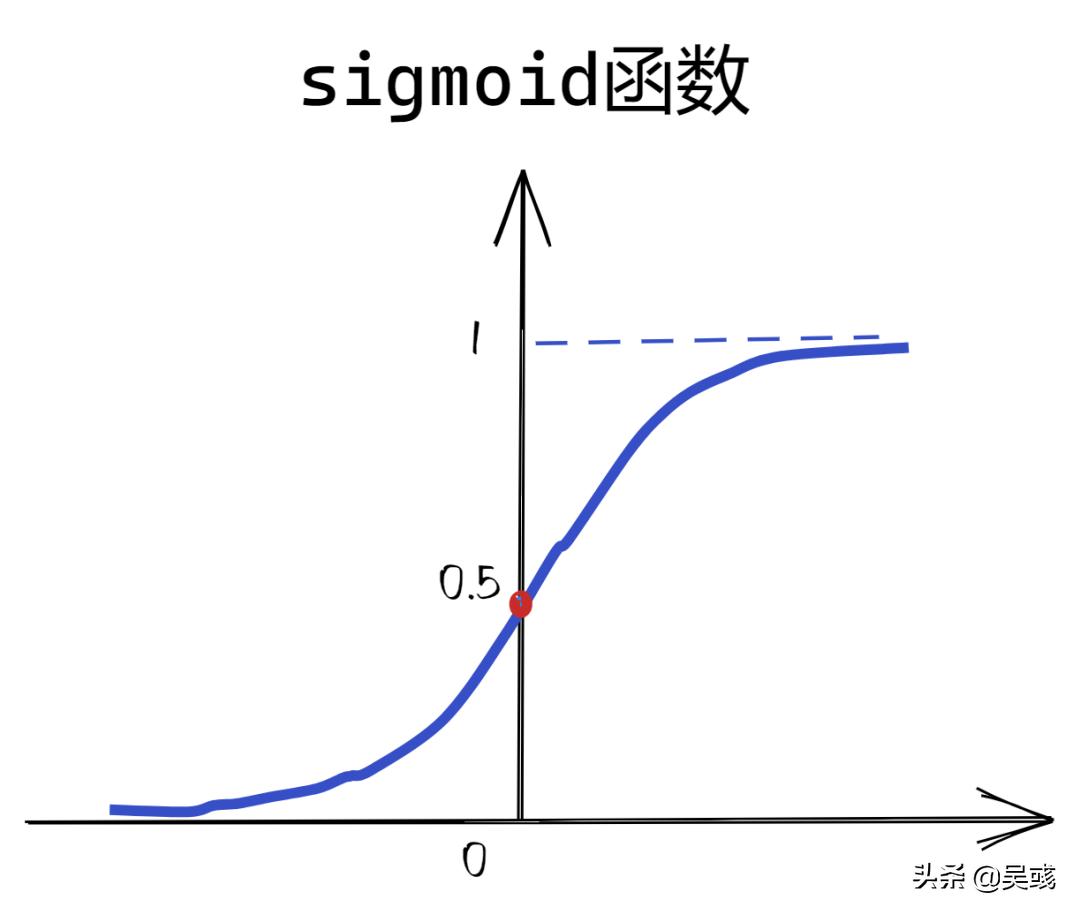
1.2.2 sigmoid函数介绍
可以看到该函数与阶跃函数最大的不同是在整个区间上是 光滑 的,因此在区间上也就 具有可微性 。而且sigmoid函数在0处的斜率最大,也就是说当输入值为0的时候,其输出值的增加或减少的速率最大,这样就能避免难以抉择分类为0还是1。整个函数的输出限定在(0,1)之间,当输入值z趋向于无穷时,输出值趋向于1,反之,趋向于0。使用sigmoid函数就可以将线性回归的输出映射到(0,1)之间,达到二分类的效果。
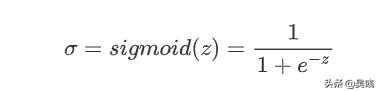
上式为sigmoid函数的表达式,线性回归输出的z=Xw ,我们将该式代入得到
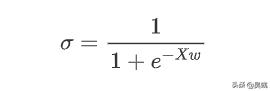
那么你一定也好奇逻辑回归的名字是怎么来的。我们知道 几率 是表示某件事发生的可能性大小的一个量,常把必然发生的事件的概率定为1,把不可能发生的事件的概率定为0,而一般随机事件的概率是介于0与1之间的一个数,用p来表示概率的话,几率就表示为 p/1-p,因为sigmoid函数的输出值σ也是介于0到1之间,那么我们可以将σ看作是一个概率的形式(注:这里σ并不是概率),所以我们就尝试着把σ用几率的形式表示出来,即
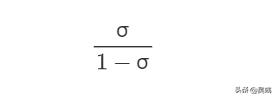
σσ我们继续观察sigmoid表达式,其为分式且含有 指数形式,那么如果加了对数的形式是否可以让除法变减法,指数变系数呢?我们开始推导这个变化(墙裂建议当场手推一遍):

推导的最后结果居然变成了线性回归的输出!!因此 让sigmoid函数两边取对数几率就被称为“ 对数几率回归 ”,即 Logistic Regression ,就是逻辑回归。
1.3 怎么实现逻辑回归
1.3.1 使用tensor实现二分类神经网络
下面给出一组“与门”数据来实现二分类神经网络,“与门”即数据之间做“与”运算,当输入特征都为1时,预测为1,其余都预测为0,数据如下
|
x0 |
x1 |
x |
z |
|
1 |
0 |
0 |
0 |
|
1 |
0 |
1 |
0 |
|
1 |
1 |
0 |
0 |
|
1 |
1 |
1 |
1 |
二分类神经网络的网络结构如下
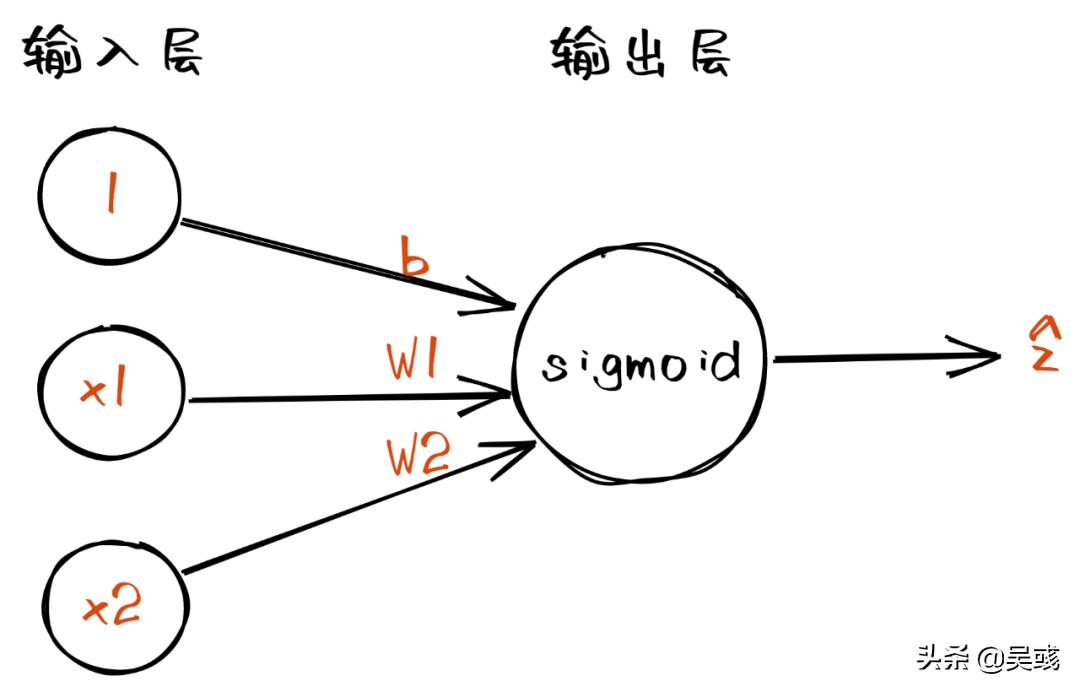
其中权重是 w1,w2 ,w3 ,即 z=σ (-3 + 2x_1 + 2x_2)
使用tensor实现,代码如下
import torch
X = torch.tensor([[1,0,0],[1,1,0],[1,0,1],[1,1,1]], dtype = torch.float32)
z = torch.tensor([[0],[0],[0],[1]], dtype = torch.float32)
w = torch.tensor([-3,2,2], dtype = torch.float32)
def LR(X,w):
t = torch.mv(X,w)
sigma = torch.sigmoid(t)
# 将阈值设为0.5,大于0.5判断为1,否则为0
zhat = torch.tensor([int(x) for x in sigma >= 0.5], dtype = torch.float32)
return sigma, zhat
在jupyter lab中运行
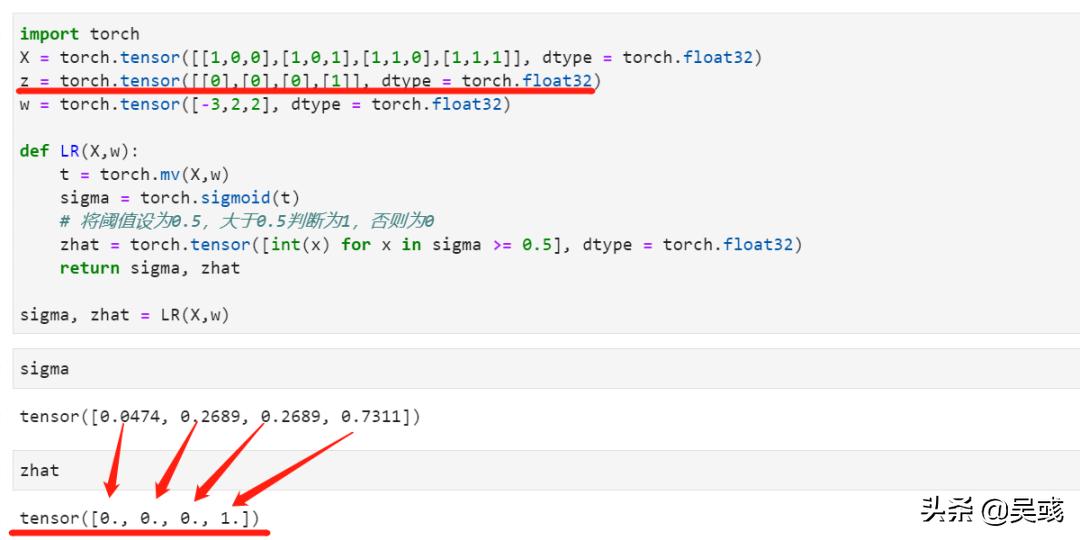
可以看到结果 ,这样我们就把线性回归的连续性变量转换为了二分类的离散型变量。
1.3.2 使用torch.nn实现二分类神经网络
经过上面的分析和简单实现,与上文中的线性回归网络的区别仅仅是在输出层加了一个非线性映射,因此代码基本框架不改变,我们把上篇文章的代码改一下
import torch
from torch.nn import functional as F
torch.random.manual_seed(55) # 设置随机种子
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]], dtype = torch.float32)
linear = torch.nn.Linear(2,1)
t = linear(X)
sigma = F.sigmoid(t)
zhat = [int(x) for x in sigma > 0.5]
为了保证结果的可复现性,这里我们设置了随机数种子。
nn.Linear中的参数是(上一层的神经元数,本层神经元数)
使用框架定义神经网络会自动生成权重和偏置
在jupyter lab中运行
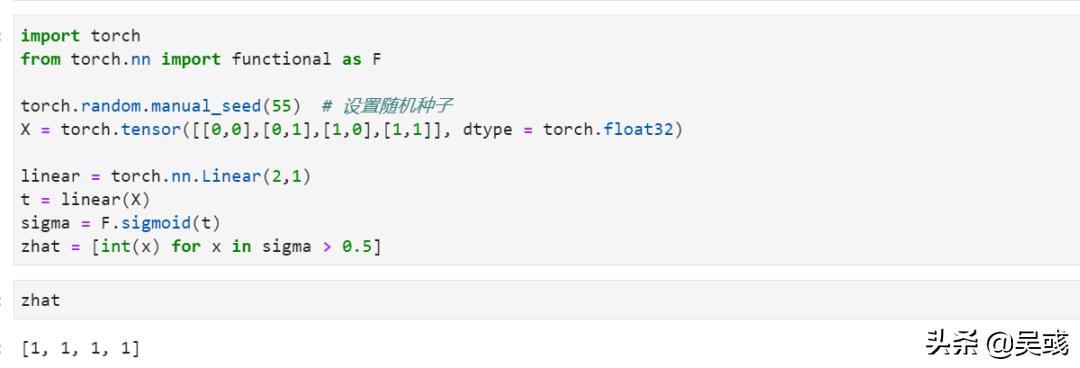
由于权重矩阵的随机性,这里的输出结果与我们给出的“与”门数据并不相同,但是这并不妨碍我们认为神经网络已经起了作用。
这里仅是使用了sigmoid激活函数作非线性映射,当然还有其它的激活函数,比如 sign 函数, than 函数,还有很火的 ReLu 函数等,有时间我会把常用的激活函数做一个总结️,这里就不再深究。
2. 多分类神经网络--softmax回归
2.1 从逻辑回归到softmax回归
在NLP中有一个文本分类的任务,比赛中常见到新闻文本分类,那么假设给你一些新闻,让你判断一个新闻是属于体育类、财经类、明星八卦类还是其它的类别,这个时候二分类神经网络就显得有些捉襟见肘了,所以我们还需要更强大的分类网络--- 多分类神经网络 。不同于二分类的通过输出层的一个神经元输出预测为1还是0,多分类神经网络的输出层有多个神经元,任务要分几类就有几个神经元,因此可以有三分类、十分类等等。
2.2 softmax函数介绍
2.2.1 为什么引入softmax函数
softmax函数 也叫归一化指数函数,顾名思义,该函数做了归一化且含有指数函数,是逻辑函数的一种推广。softmax可以拆开两个单词来看,soft和max。soft意为“软”,max意为“最大值“,那么合起来就是”软的最大值“,我们从与之相对应的”硬的最大值“开始理解。常见的求一组数中的最大值就是hard max,只有一个最大的,但是这种方法在多分类问题中是有很大的缺陷,因为它忽略了其它类别的重要性。
比如给出一个新闻文本,这个文本中含有体育类和明星类等多种信息,这时候我们在评判该文本属于哪一个类别的时候更希望的是能给出属于各个类别的概率值,比如类别为体育类概率是0.5,明星类0.4,财经类0.1等,返回这种概率值我们就可以取前两个概率最大的类别作为一个新闻文本的标签,这种多标签问题就也考虑了其它类别的重要性。在我们的多分类任务中,还是返回所有概率中最大的那个类别。
2.2.2 softmax公式介绍
softmax函数公式如下:
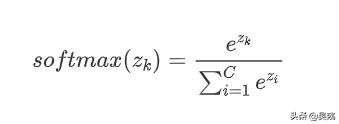
其中C为分类的类别个数, 还是类似逻辑回归中的来自线性层的输出。由公式可以看出,softmax是计算被分为当前类的指数函数值与所有类别指数函数值的比值,这也就使得所有softmax的值在0,1之间,并且所有函数值相加为1。这样一来softmax的结果就代表了样本类别为k的“概率”(和认为sigmoid返回的结果是概率有异曲同工之妙)。
2.2.3 优缺点
softmax引入了指数函数, 虽然有易于求导的数学性质,但是其缺点也是非常明显的,那就是在增长速度贼快,很容易就会得到一个巨量的数值,在计算机中导致“溢出”的错误。指数函数增长快的秘密在于指数,因此解决这个问题的就从指数下手,我们在其指数位置上引入一个与max(z_k) 差不多的常数作减法,这样就可以缩小指数,控制函数的巨量增长。具体推导如下
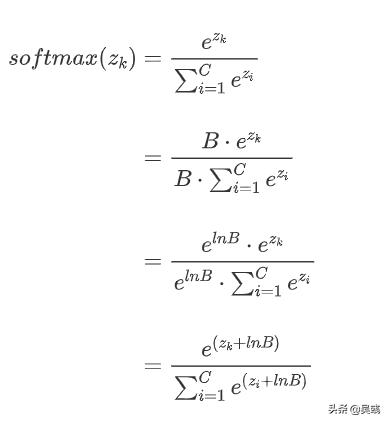
这样一来,指数函数的增长就让我们拉住了。上面的解决方法在pytorch中已实现,我们直接调用torch.softmax就可以。
多说一个题外话,写到softmax让我想到了word2vec中的skip-gram模型,它是通过中心词来预测两边的词出现的概率,从中获得词之间的关系和语义信息,得到词向量。这其中就用到了softmax方法,将生成的两个中心词矩阵和context矩阵作为指数,以此计算一句话中的每个词作为中心词后其context出现的概率,形式化的定义条件概率分布。写到这里突然想起来就写上了,仅是举例,不必深究。另外,能感受到做输出很大的一个好处就是输出的同时要去串联学习过的知识,不断的做梳理、做总结,加深理解。
2.3 怎么实现softmax回归
2.3.1 使用torch.nn实现多分类神经网络
作为例子,我们还是用之前的“与”数据,实现三分类。数据如下
|
x1 |
x2 |
|
0 |
0 |
|
0 |
1 |
|
1 |
0 |
|
1 |
1 |
网络结构如下
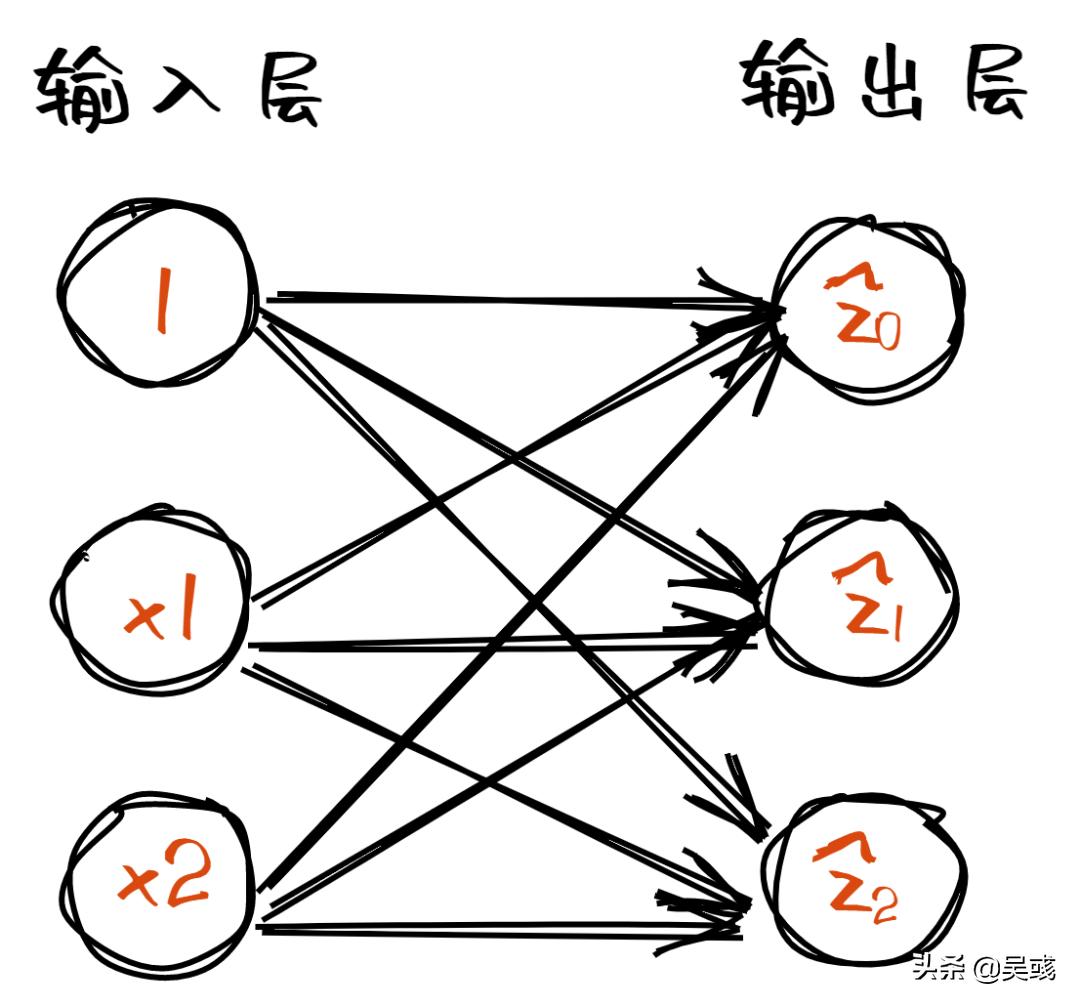
代码如下
import torch
from torch.nn import functional as F
torch.random.manual_seed(55)
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]], dtype = torch.float32)
linear = torch.nn.Linear(2,3)
t = linear(X)
zhat = F.softmax(t,dim=1)
softmax函数的第二个参数dim指的是在张量的哪个维度做softmax
jupyter lab中运行如下
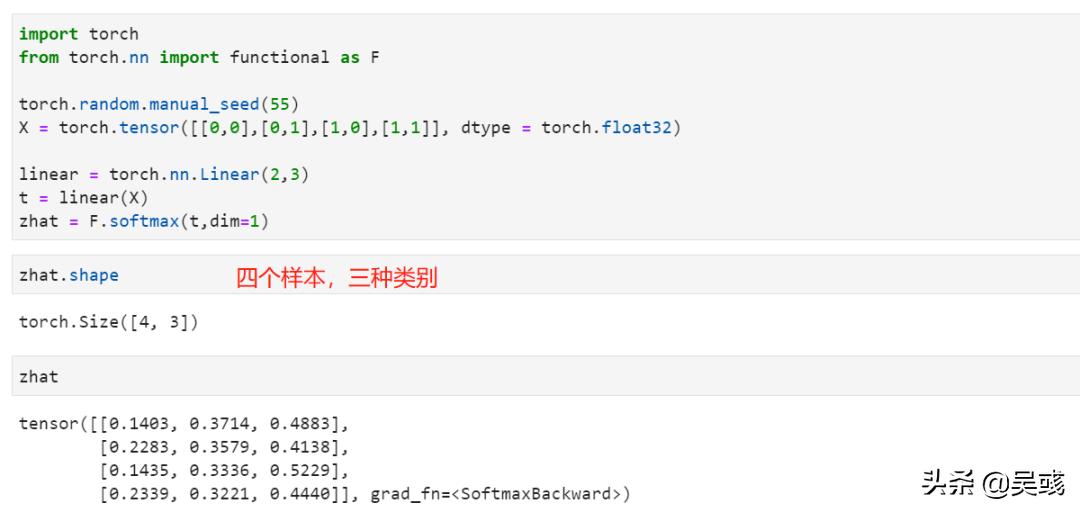
运行结果zhat表示当前样本分别被分为三个类别的概率大小,由此选出概率最大的作为该样本的类别。

这样我们就把简单的单层神经网络全部实现了,再去理解复杂的深层神经网络也就不那么难了,仅是在此基础上增加层数罢了,万变不离其宗。
我是吴彧,感谢关注。
- THE END -