
华为盘古大模型是一款直接对标ChatGPT的多模态千亿级大模型产品,名为“盘古Chat”。预计华为盘古Chat将于今年7月7日举行的华为云开发者大会 (HDC.Cloud 2023) 上对外发布以及内测,产品主要面向To B/G政企端客户。

此外,华为云还发布了盘古系列超大规模预训练模型,包括30亿参数的全球最大视觉(CV)预训练模型,以及与循环智能、鹏城实验室联合开发的千亿参数、40TB训练数据的全球最大中文语言(NLP)预训练模型5。这些预训练大模型可以实现一个AI大模型在众多场景通用、泛化和规模化复制,减少对数据标注的依赖,并使用ModelArts平台,让AI开发由作坊式转变为工业化开发的新模式。

盘古大模型是一个涵盖了多个领域的超大规模预训练模型系列,包括自然语言处理(NLP)、计算机视觉(CV)、多模态、科学计算等方向。
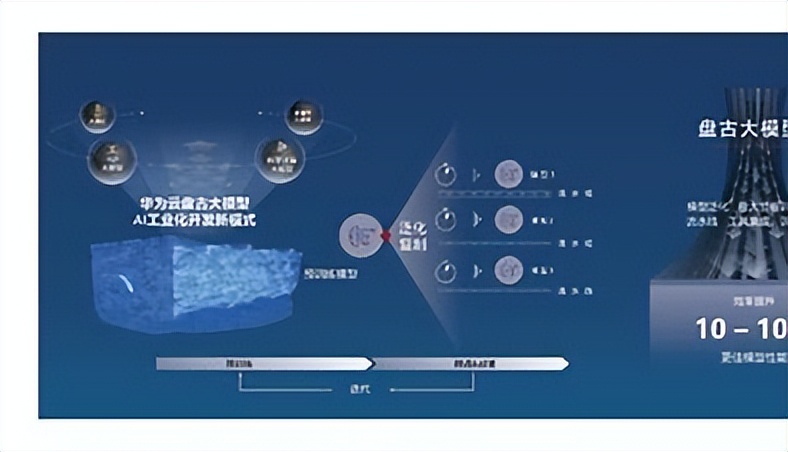
盘古大模型的目标是通过预训练,提高AI模型的泛化能力和智能水平,降低AI开发的门槛和成本,加速AI在各行各业的落地应用。
盘古大模型的应用场景包括智能客服、机器翻译、语音识别、工业质检、物流仓库监控、时尚辅助设计、智能文档检索、智能ERP、小语种大模型、气象预报、海浪预测等领域。
盘古大模型的优势在于其规模、结构和效果。

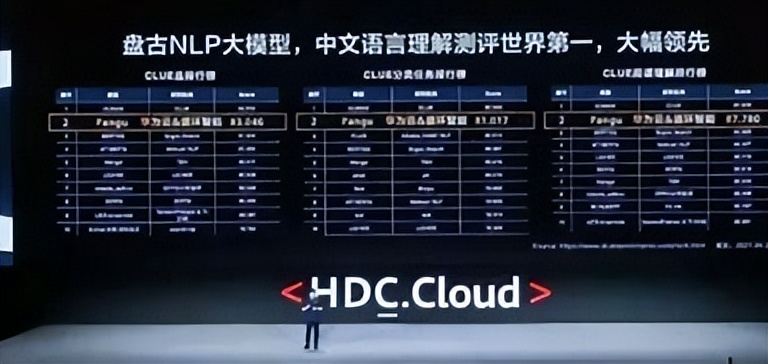
- 规模:盘古大模型拥有千亿级别的参数量,是目前全球最大的中文NLP预训练模型,也是全球最大的CV预训练模型,以及全球首个图文音三模态大模型。
- 结构:盘古大模型采用了创新的网络架构设计,如深度残差网络(DRN)、多头注意力机制(MHA)、自适应注意力机制(AAN)等,提高了并行优化效率和计算性能。
- 效果:盘古大模型在多个公开数据集和行业数据集上均取得了领先的结果,如在ImageNet上小样本学习能力达到业界第一,在气象预报上精度超过传统数值方法,速度提升1000倍等。
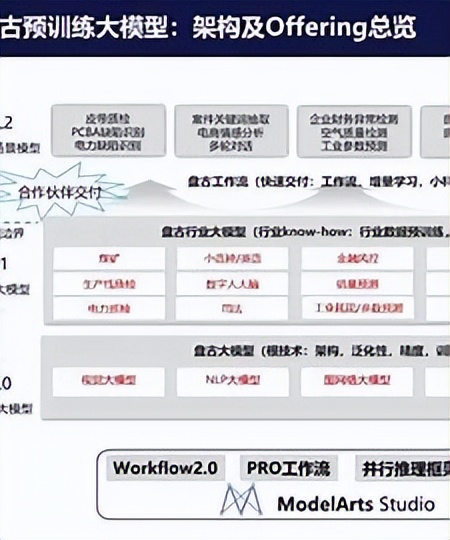
盘古大模型的技术细节主要包括以下几个方面:
网络架构:盘古大模型采用了创新的网络架构设计,如深度残差网络(DRN)、多头注意力机制(MHA)、自适应注意力机制(AAN)等,提高了并行优化效率和计算性能。
数据规模:盘古大模型使用了海量的数据进行预训练,如中文语言大模型使用了超过40TB的文本数据,视觉大模型使用了超过10亿张图像数据,气象大模型使用了超过100TB的气象数据等。
预训练方法:盘古大模型采用了不同的预训练方法,针对不同的领域和场景,如自然语言处理(NLP)使用了Encoder-Decoder架构,兼顾语言理解和生成能力;计算机视觉(CV)使用了全局对比度自监督学习方法,提高了小样本学习能力;多模态使用了图文音三模态融合技术,提高了跨模态理解和生成能力;科学计算使用了图网络融合技术,提高了科学问题求解能力等。

模型抽取和蒸馏:盘古大模型通过模型抽取和蒸馏技术,可以根据不同的应用需求,自适应地抽取不同规模的模型,并保持较高的精度。例如,视觉大模型可以根据不同的图像分辨率和运行速度需求,抽取不同大小的模型,并在ImageNet上达到业界第一的小样本学习能力。