
这是为那些想要进入数据科学的人,他们有一些知识,但正在有困难的时候,提出你的第一个数据科学项目。这就是为什么我创建了一个逐步指南来完成你的第一个端到端机器学习模型!接下来,你会学到很多新技能。
我使用了 Kaggle 的二手车数据集,因为它有各种各样的分类数据和数值数据,并允许您探索处理丢失数据的不同方法。我把我的项目分为三部分:
- 探索性数据分析
- 数据建模
- 功能重要性
探索性数据分析
理解我的数据
# Importing Libraries and Data
import numpy as np
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))df = pd.read_csv("../input/craigslist-carstrucks-data/vehicles.csv")# Get a quick glimpse of what I'm working with
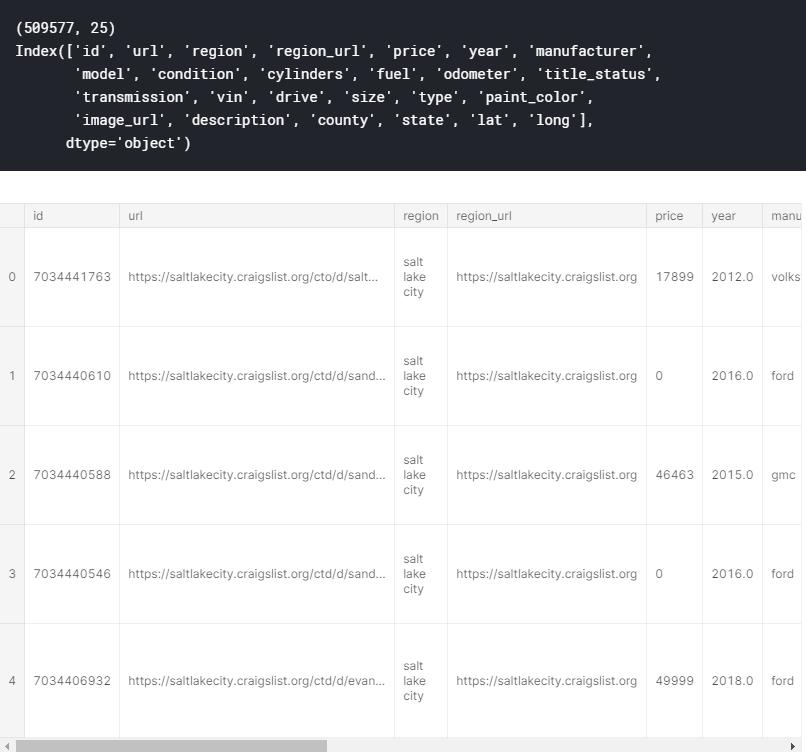
print(df.shape)
print(df.columns)
df.head()
在处理数据科学问题时,我经常做的第一件事是了解我正在处理的数据集。使用df.shape,df.columns,和df.head(),我可以看到我使用的是什么特性以及每个特性需要什么。
探索分类数据
df.nunique(axis = 0)
我喜欢用df.nunique(axis=0),查看每个变量有多少唯一值。使用这个,我可以看到是否有任何蓝色的东西,并确定任何潜在的问题。例如,如果它表明有60个州,那就会升起一面红旗,因为只有50个州。

探索数值数据
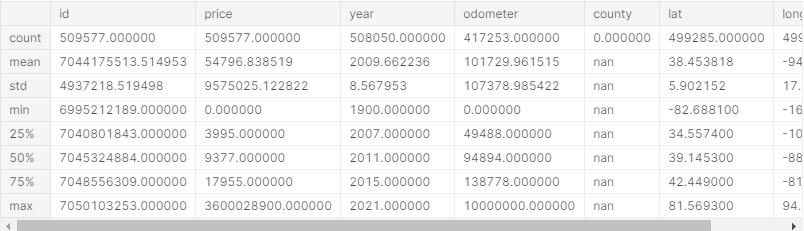
df.describe().apply(lambda s: s.apply(lambda x: format(x, 'f')))
对于数值数据,我使用df.describe()可以快速了解我的数据。例如,我可以立即看到价格问题,因为最低价格是0美元,最高价格是3,600,028,900美元。
稍后,你会看到我如何处理这些不现实的离群值。
空值过多的列
NA_val = df.isna().sum()def na_filter(na, threshold = .4): #only select variables that passees the threshold
col_pass = []
for i in na.keys():
if na[i]/df.shape[0]<threshold:
col_pass.append(i)
return col_passdf_cleaned = df[na_filter(NA_val)]
df_cleaned.columns
在继续我的 EDA 的其余部分之前,我使用上面的代码删除超过40%的值为空的所有列。这让我剩下的几列在下面。

移除异常值
df_cleaned = df_cleaned[df_cleaned['price'].between(999.99, 250000)] # Computing IQR
Q1 = df_cleaned['price'].quantile(0.25)
Q3 = df_cleaned['price'].quantile(0.75)
IQR = Q3 - Q1# Filtering Values between Q1-1.5IQR and Q3+1.5IQR
df_filtered = df_cleaned.query('(@Q1 - 1.5 * @IQR) <= price <= (@Q3 + 1.5 * @IQR)')
df_filtered.boxplot('price')
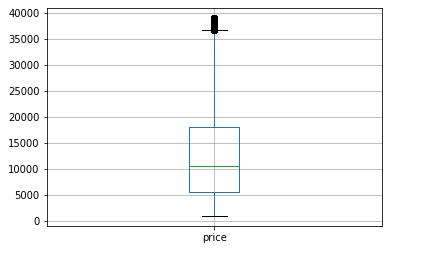
在使用 Interquartile ( IQR )方法删除离群值的价格之前,我决定将价格范围设置为更符合实际的数字,以便将标准差计算为比9,575,025更现实的数字。
IQR (也称为中间扩散)是一种统计分散度的度量,可用于识别和删除离群值。IQR 范围规则的理论如下:
- 计算 IQR (=第三个四分位数-第一个四分位数)
- 查找范围的最小数(=第一个四分位数-1.5* IQR )
- 查找范围的最大数量(=第三个四分位数+1.5* IQR )
- 删除此范围之外的任何值。
您可以在上面的 boxplot 中看到,我使用这种方法大大减少了价格范围。
df_filtered.describe().apply(lambda s: s.apply(lambda x: format(x, 'f')))
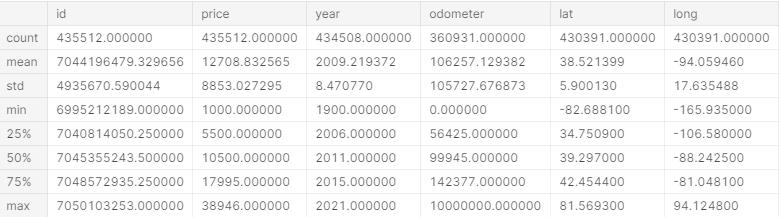
再次使用.describe(),我们可以看到价格范围似乎比最初要现实得多,但是年份和里程表似乎有些偏离(例如,年份的最大值是2021)。
我使用下面的代码来设置1900-2020年和里程表为0-271,341.5年的范围。
# cant be newer than 2020
df_filtered = df_filtered[df_filtered['year'].between(1900, 2020)]# = 140000 + 1.5 * (140000-52379)
df_filtered = df_filtered[df_filtered['odometer'].between(0, 271431.5)]
删除剩余的列
df_final = df_filtered.copy().drop(['id','url','region_url','image_url','region','description','model','state','paint_color'], axis=1
df_final.shape
通过部分使用我的直觉和部分猜测和检查,我删除了以下列:
- url, id, region_url, image_url:它们与正在进行的分析完全无关
- 描述:描述可以使用自然语言处理,但超出了此项目的范围,被忽略
- 地区,州:我摆脱了这些,因为它们本质上与纬度和经度相同
- 模型:我摆脱了这一点,因为有太多的不同的值把它转换成虚拟变量。此外,我无法使用标签编码,因为这些值没有排序
- 最后,我在进行了功能重要性(稍后将会看到)之后,消除了这一点。由于特征的重要性表明,油漆颜色在确定价格方面的重要性不大,所以我删除了它,并提高了模型的准确性
可视化变量和关系
import matplotlib.pylab as plt
import seaborn as sns
# calculate correlation matrix
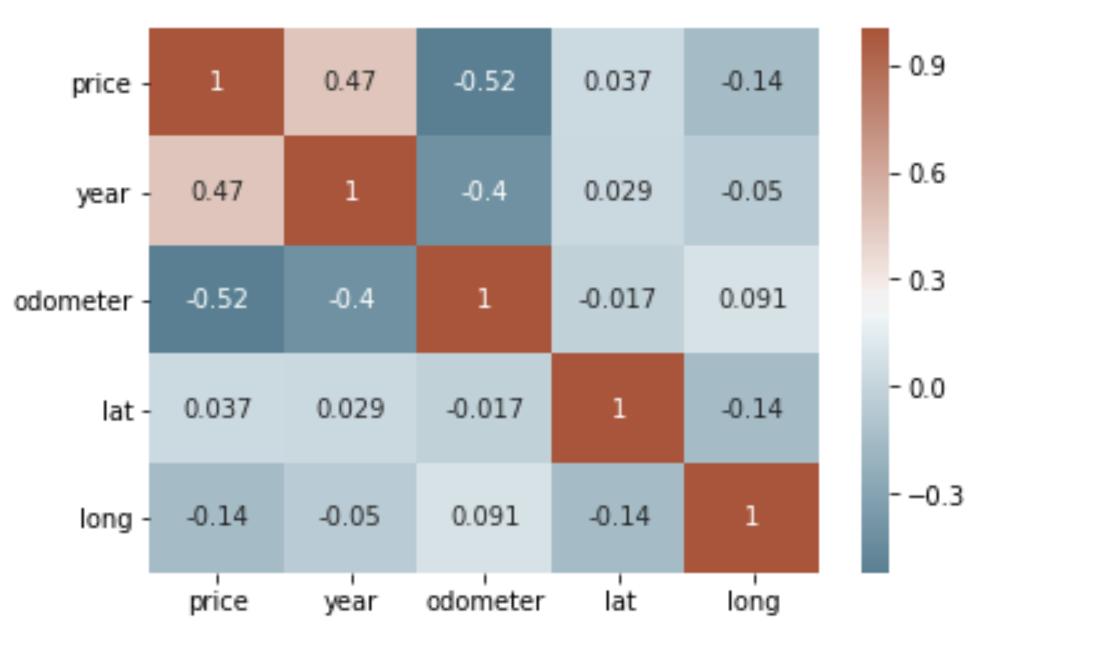
corr = df_final.corr()# plot the heatmap
sns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns, annot=True, cmap=sns.diverging_palette(220, 20, as_cmap=True))
清理完数据后,我想可视化我的数据,更好地理解不同变量之间的关系。使用 sns.heatmap(),我们可以看到,这一年与价格正相关,里程表与价格负相关——这是有道理的!看来我们走在了正确的轨道上。
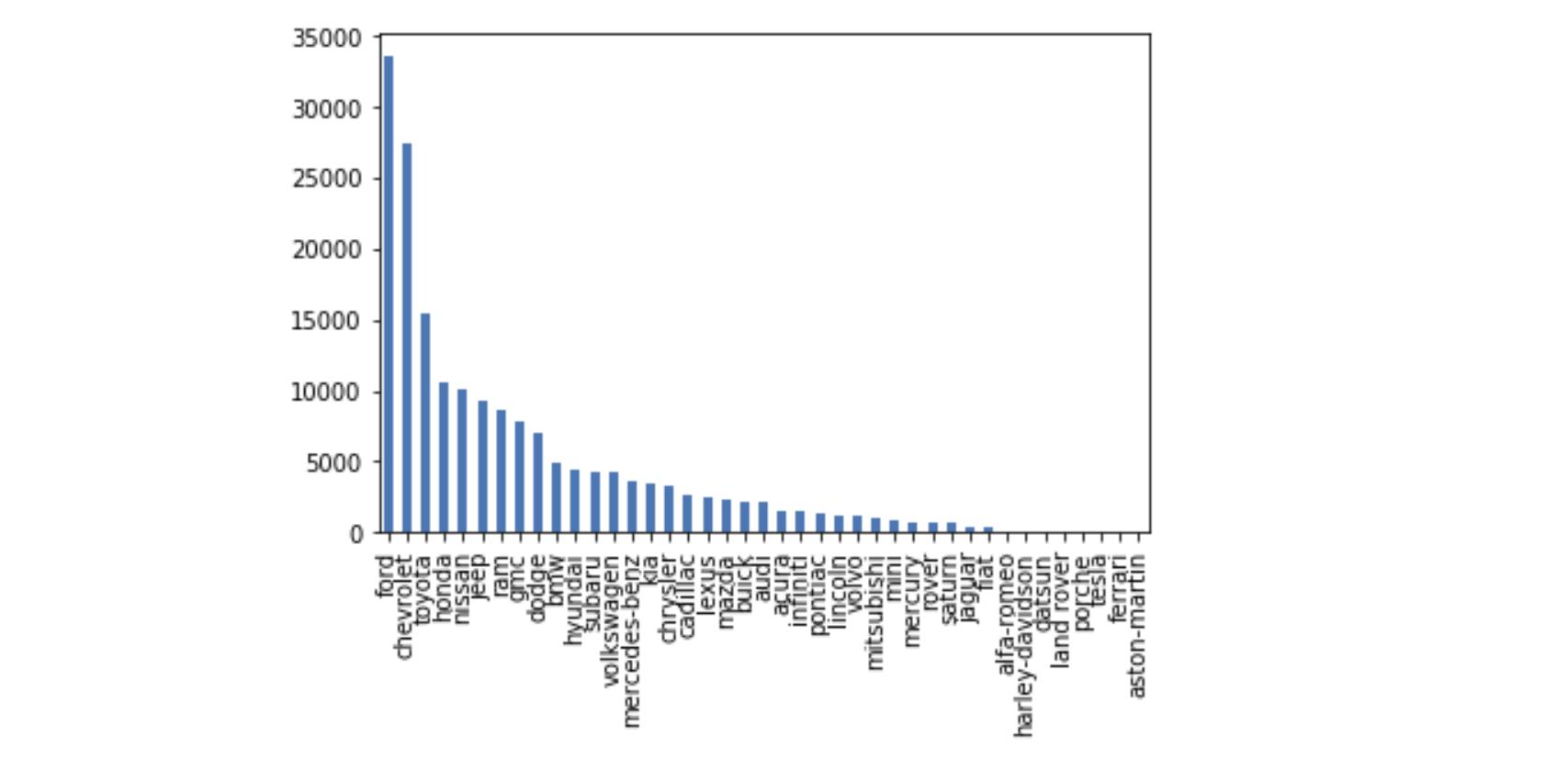
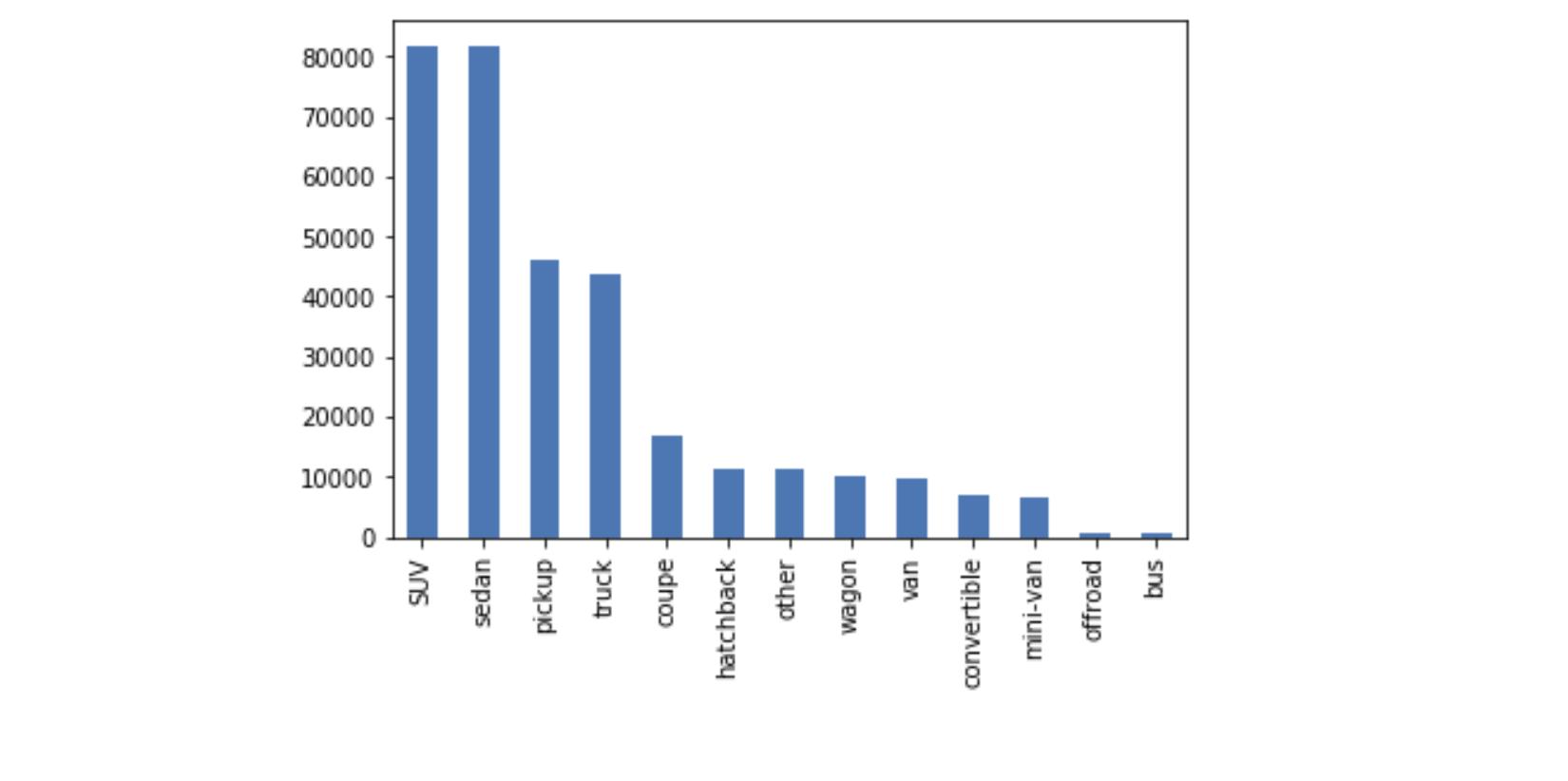
df_final['manufacturer'].value_counts().plot(kind='bar')df_cleaned['type'].value_counts().plot(kind='bar')
为了我自己的兴趣,我用条形图绘制了一些分类属性(见下图)。你可以做更多的可视化来了解你的数据集,比如散点图和 boxplot ,但是我们将继续到下一个部分,数据建模!
数据建模
虚拟变量
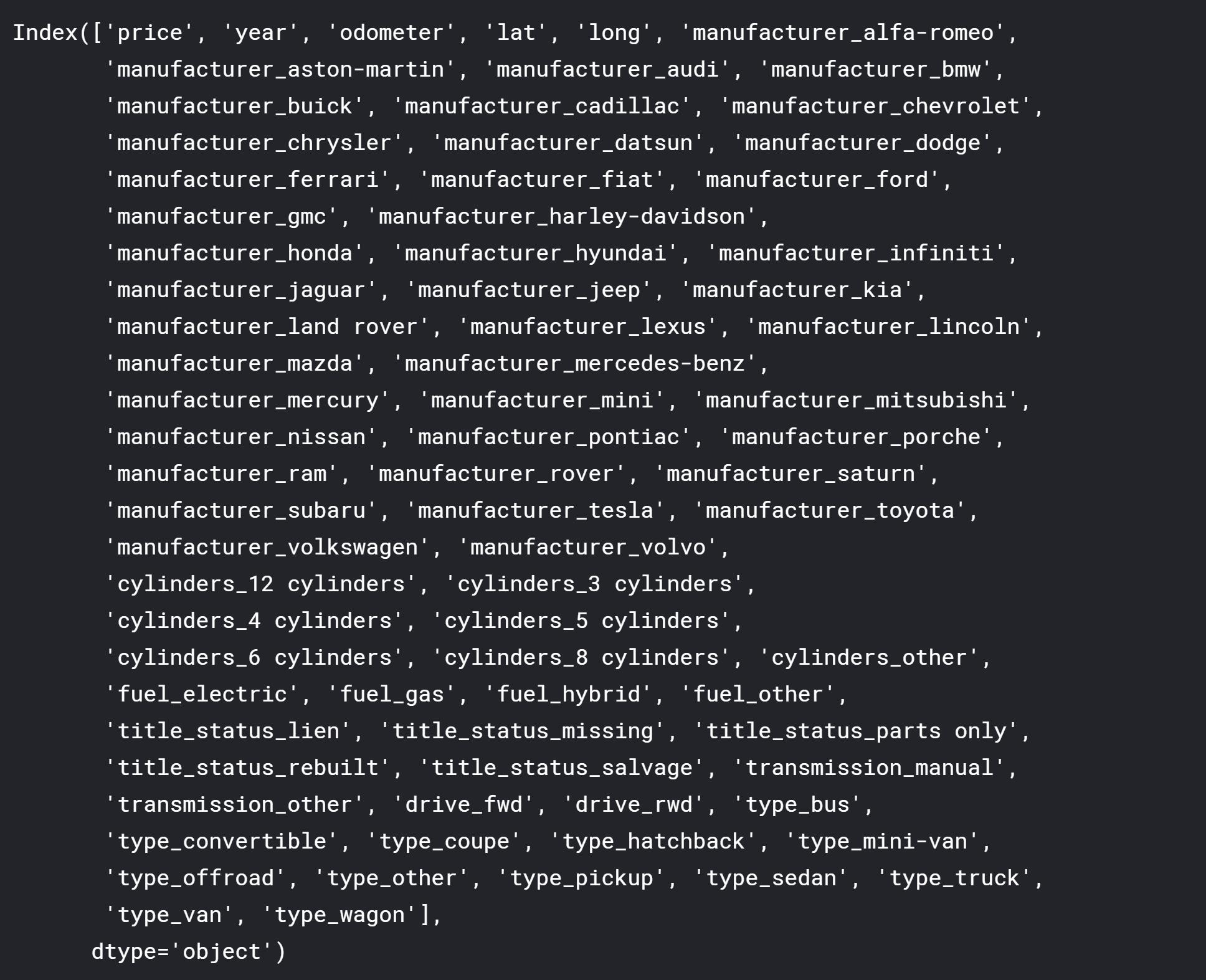
df_final = pd.get_dummies(df_final, drop_first=True)
print(df_final.columns)
为了能够在随机森林型号中使用分类数据,我使用了pd.get_dummies()。这实际上将变量的每个唯一值转换为它自己的二值变量。例如,如果其中一个制造商是本田,那么将创建一个新的虚拟变量‘ manufacturer_honda’,如果它是本田,则等于1,如果不是,则等于0。
缩放数据
from sklearn.preprocessing import StandardScaler
X_head = df_final.iloc[:, df_final.columns != 'price']
X = df_final.loc[:, df_final.columns != 'price']
y = df_final['price']
X = StandardScaler().fit_transform(X)
接下来,我使用 StandardScaler 对数据进行了缩放。Prasoon 在这里提供了一个很好的答案,为什么我们缩放(或规范化)我们的数据,但本质上,这是这样做的,这样我们的独立变量的规模不会影响我们的模型的组成。例如,年的最大数字是2020年,里程表的最大数字超过20万。如果我们不调整数据,里程表的小变化将比一年的变化产生更大的影响。
创建模型
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.25, random_state=0)
model = RandomForestRegressor(random_state=1)
model.fit(X_train, y_train)
pred = model.predict(X_test)
我决定使用随机森林算法是出于以下几个原因:
- 它处理高维度非常好,因为它需要数据的子集
- 它非常通用,只需要很少的预处理
- 由于每个决策树的偏差都较小,因此可以很好地避免过度拟合
- 它使您可以检查功能的重要性,这将在下一部分中看到!
检验模型的准确性
print(mae(y_test, pred))
print(df_final['price'].mean())model.score(X_test,y_test)
总体而言,我的模型获得了1,590美元的平均价格约12600美元,并有90.5%的准确性!

MAE和平均价格

模型精度
功能重要性
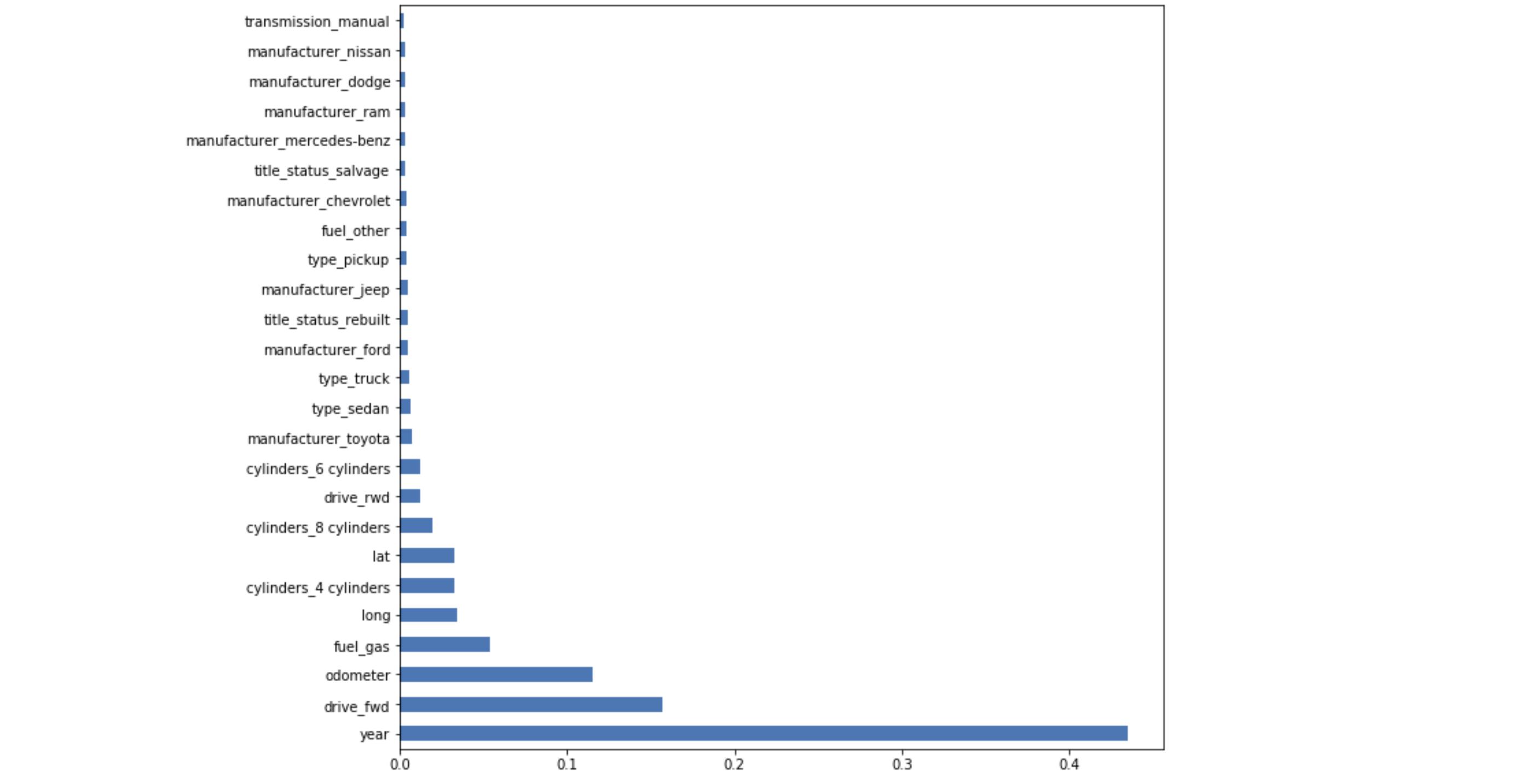
feat_importances = pd.Series(model.feature_importances_, index=X_head.columns)
feat_importances.nlargest(25).plot(kind='barh',figsize=(10,10))
我花了很多时间来寻找特征重要性的最佳定义, Christoph Molnar 提供了最好的定义(见这里)。他说:
“我们通过计算模型在对特征进行置换后的预测误差的增加来测量特征的重要性。如果打乱顺序的值增加了模型错误,则特征是“重要的”,因为在这种情况下,模型依赖于该特征进行预测。如果打乱顺序的值使模型错误保持不变,则特征“不重要”,因为在这种情况下,模型忽略了预测的特征。”
考虑到这一点,我们可以看到,在确定价格时,最重要的三个特征是年、驾驶(如果是前轮驱动)和里程表。功能重要性是一种很好的方式,使您的模型合理化,并向非技术人员解释。如果你需要减少你的维度,这对于特征选择也是很好的。
这就是我的项目!我希望这能激励那些想进入数据科学的人真正开始。让我知道你希望在评论中看到的其他有趣的项目:
本文由未艾信息(www.weainfo.net)编译,
想看更多译文,欢迎大家点击上面的链接进行查看~
也可以关注我们的公众号:为AI呐喊