上一篇介绍了如何在EXCEL中用正则表达式抓取网页中的信息,文章链接:用EXCEL像Python一样优雅的抓取网页中的信息,但有的人说,正则表达式那么难我不会啊,VBA太难我也不会,不想编程,有没有更简单的方法。所以这篇文章为大家介绍一款EXCEL插件,seotoolsforexcel,安装这个插件后就可以用Xpath爬取网页信息了。
1.先打开浏览器检查,选中需要抓取的元素,拷贝Xpath表达式,这里就抓取百度首页"百度一下"四个字符吧。其它网页原理一样。拷贝下的表达式为“//*[@id="su"]”
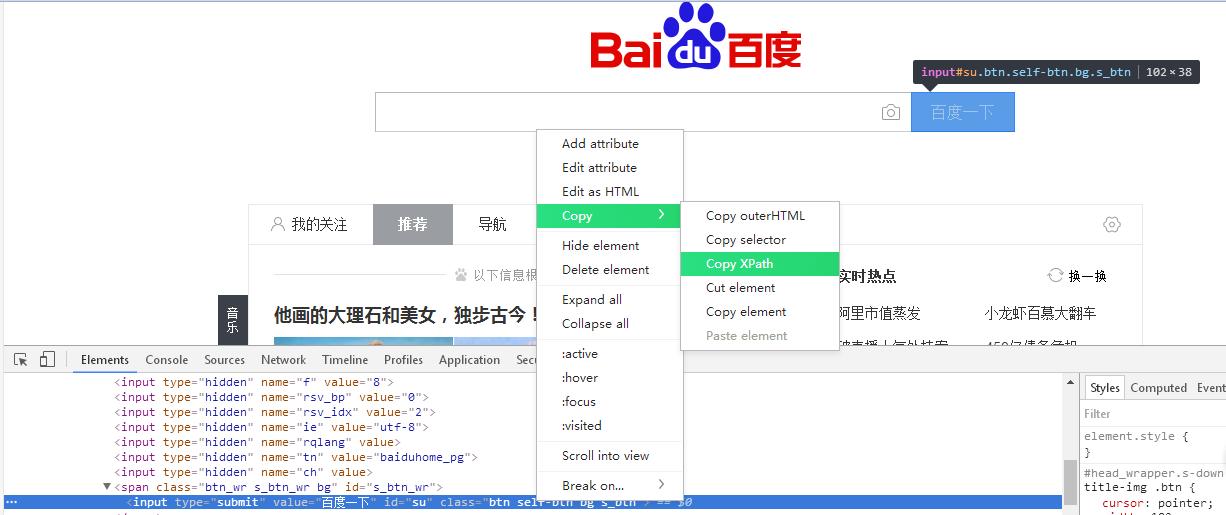
copy Xpth
2.安装好seotoolsforexcel后点击SeoTools选项卡-HTTP按钮-XPathOnUrl函数
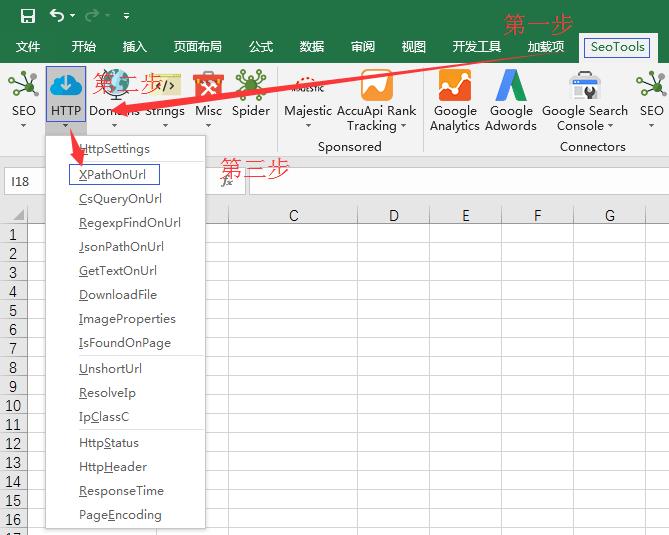
XPathOnUrl
3."百度一下"这四个字符所在的html段是<input type="submit" id="su" value="百度一下" class="bg s_btn">在弹出的XPathOnUrl属性中分别填入"https://www.baidu.com”,".//*[@id=’su’]",value即可,具体填写方法和爬取效果如下图
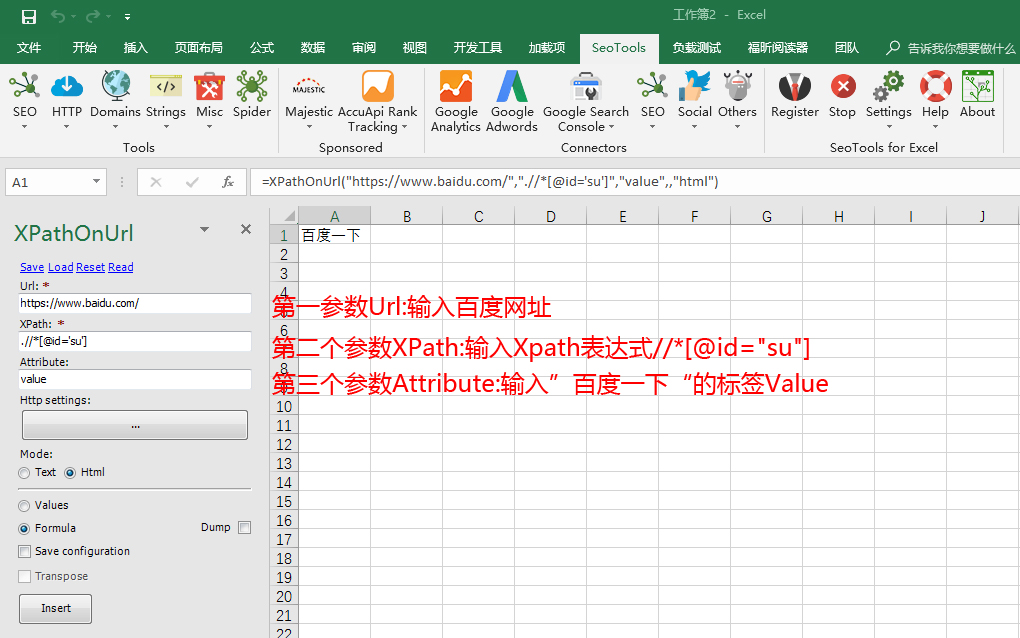
XPathOnUrl填写方法
4.点击Http settings 在弹出的Http settings 对话框中还可以定义请求头、定义认证信息、设置随机requests请求等,非常强大有木有
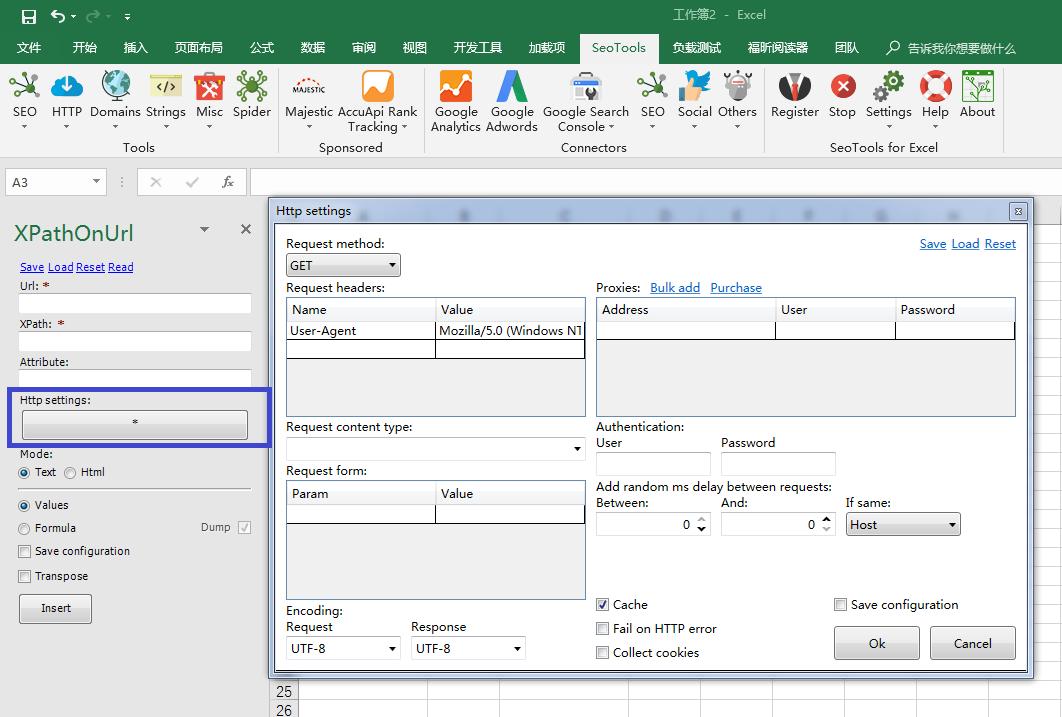
Http settings
5.其实XPathOnUrl只是seotoolsforexcel中其中一个函数而已,它还有很多强大的功能比如解析JSON的函数JsonPathOnUrl、爬虫工具Spider等,读者可以自己摸索一下,下图给大家参考一下。
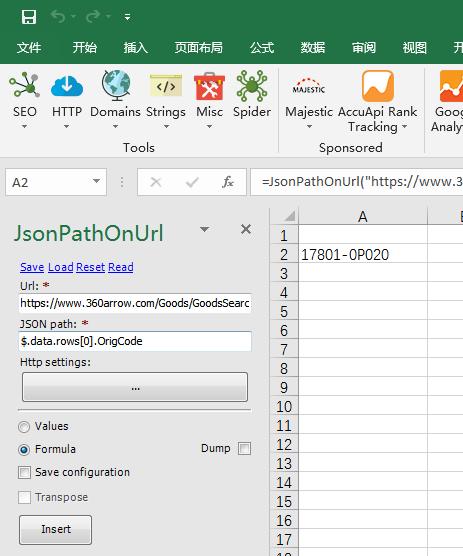
JsonPathOnUrl
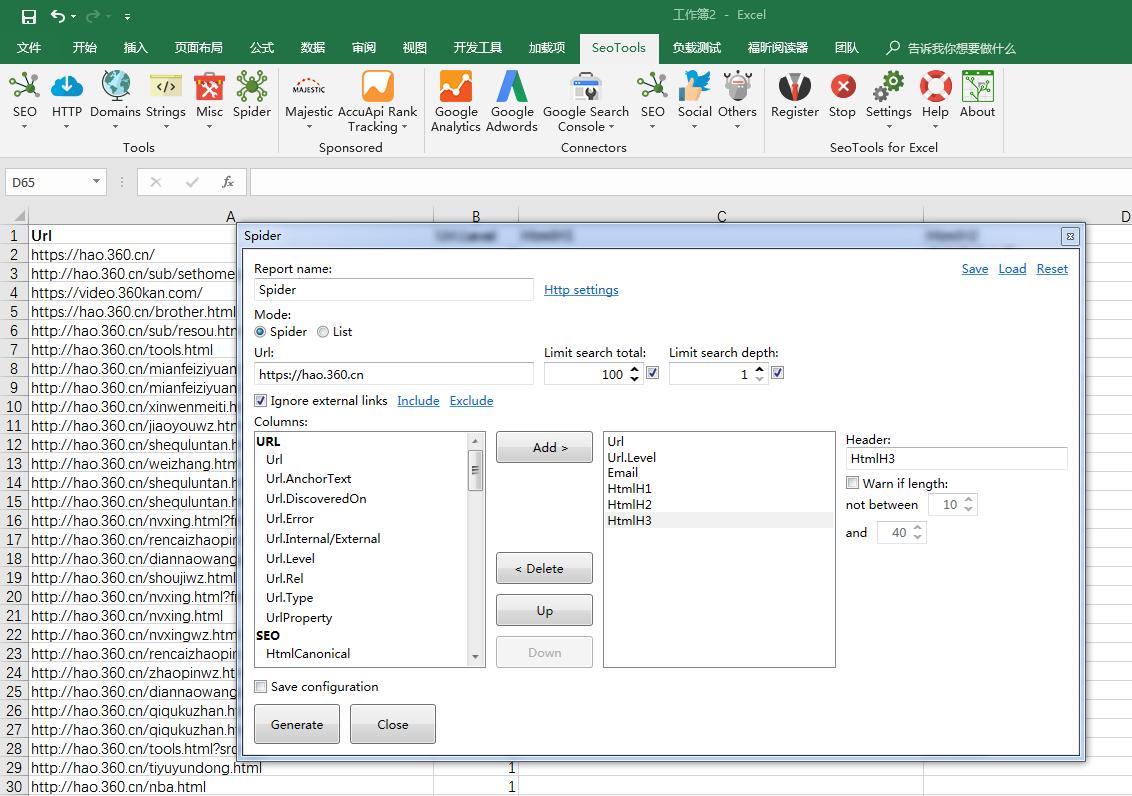
爬虫工具Spider
6.教程到此结束,有不懂得地方可以留言一起讨论下。*载下**方式如下
*今条头日**APP里通过私信给回复:seotoolsforexcel、获取*载下**链接!!!