大数据之-Hadoop之HDFS_HDFS_副本数量设置---大数据之hadoop工作笔记0053
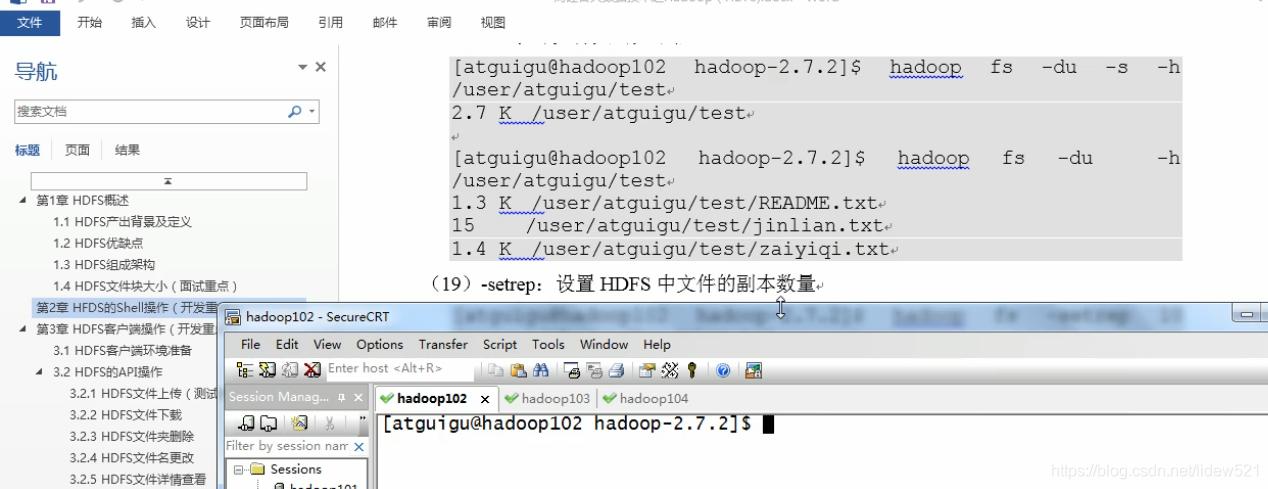

然后我们再来可以通过-setrep来设置hdfs中文件存的副本的个数,以前我们设置
是通过配置文件设置的对吧,现在我们直接通过,命令就可以设置了,不用再去配置文件了,太麻烦了,配置以后还得重启.
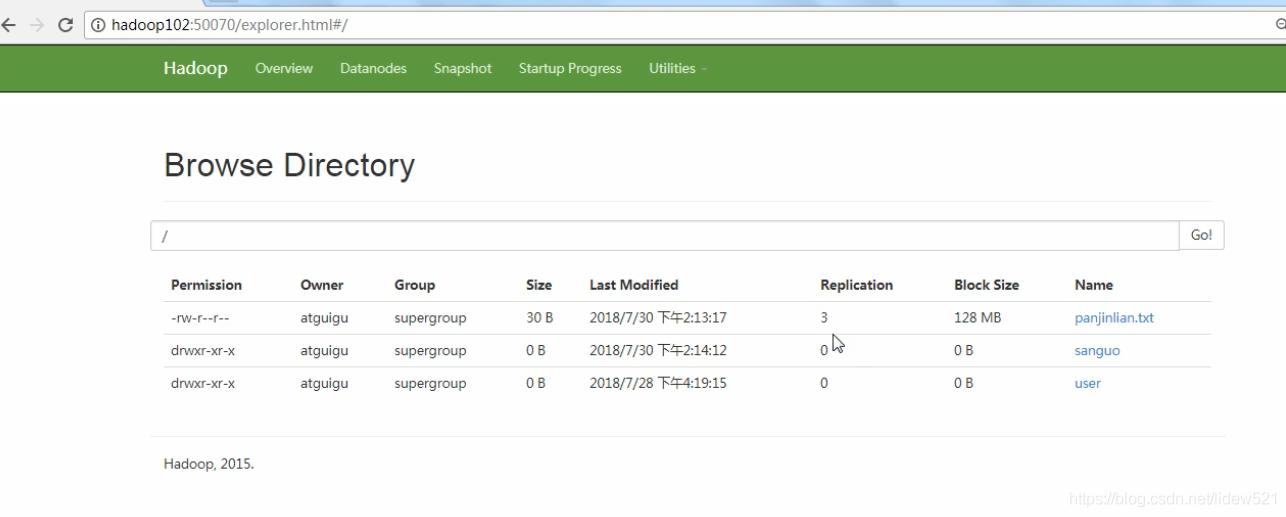

我们先去看看,副本数量,默认的是3个
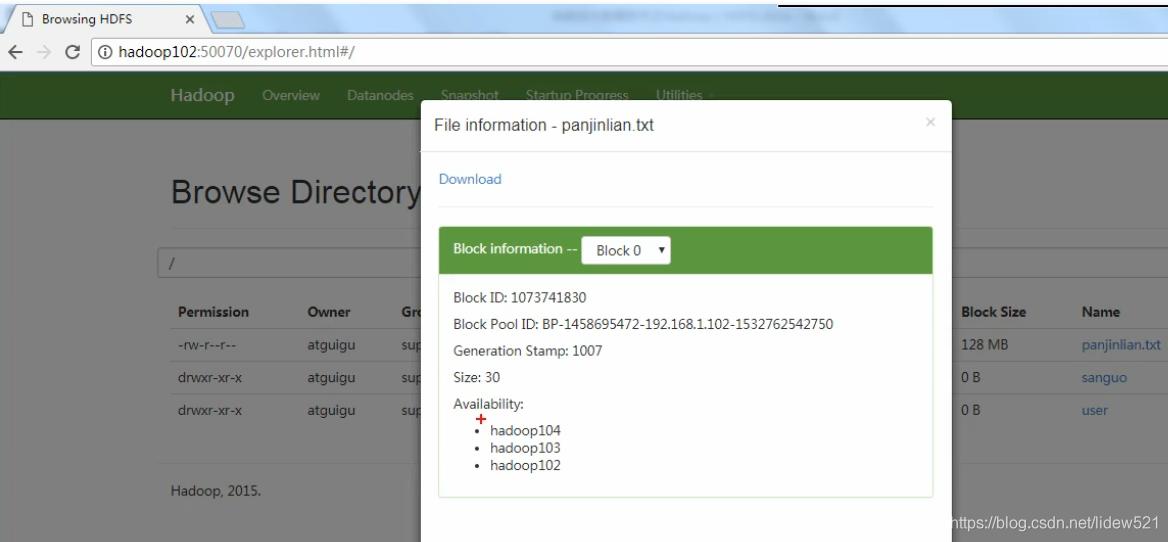

去看看这个panjinlian.txt可以看到
block0这个块,在hadoop104,103,102上面都存了副本
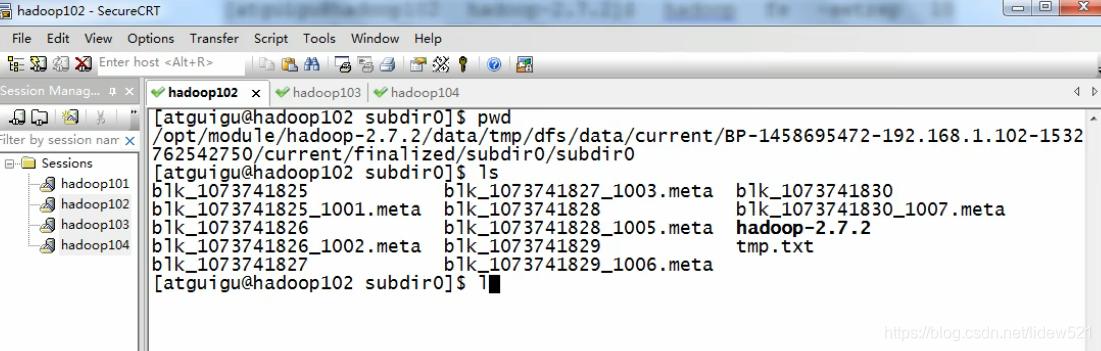

我去对应的目录,去看看,可以看到有好几个文件,上面那个目录比较长,之前我们已经看过了.
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-1458695472-192.168.1.102-1532762542750/current/finalized/subdir0/subdir0
但是这几个文件,哪个才是panjinlian.txt呢?不知道对吧
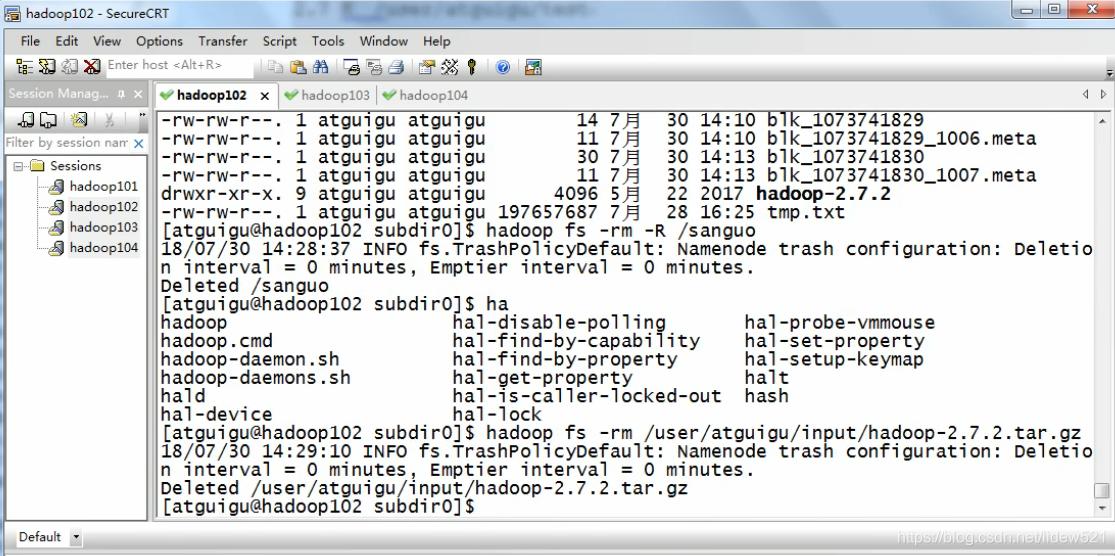

我们可以先去hadoop fs -rm -R /sanguo 先把sanguo这个文件夹删除
然后再
hadoop fs -rm /user/atguigu/input/hadoop-2.7.2.tar.gz 再把这个文件删除.
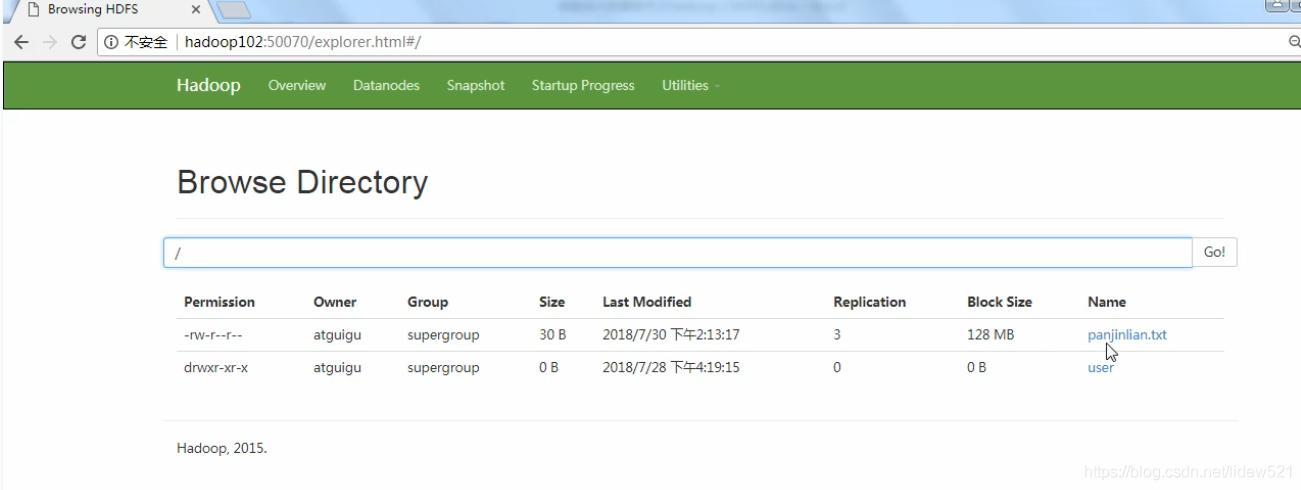

可以看到已经删除了没有用的文件,现在就剩根目录下的panjinlian.txt和
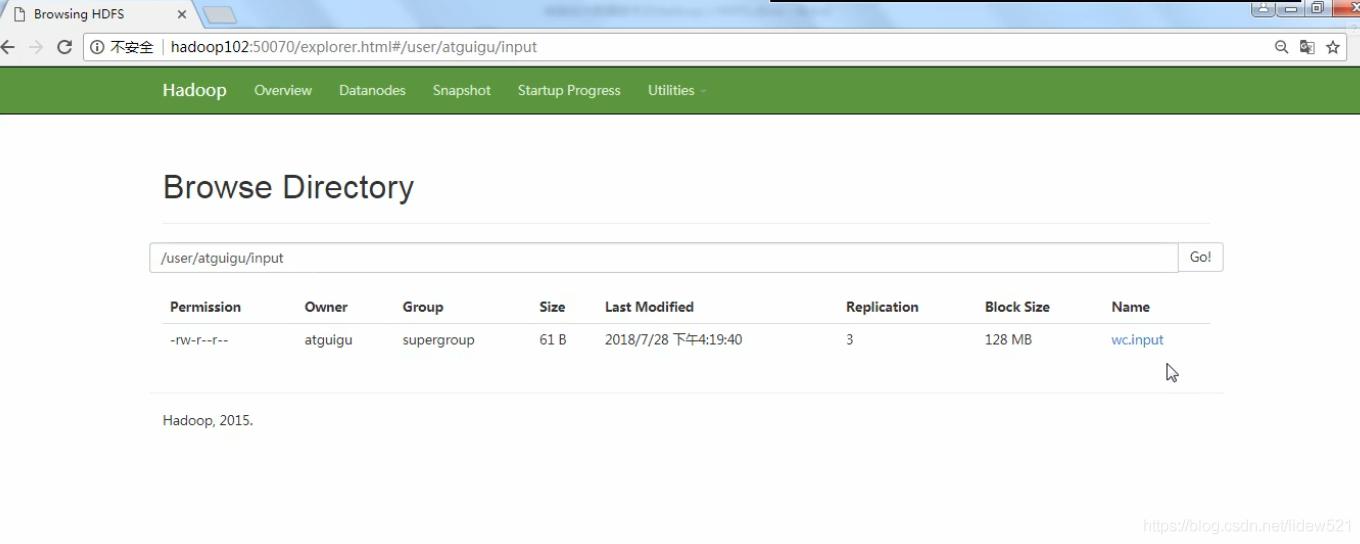

user/atguigu/input文件夹下的wc.input文件
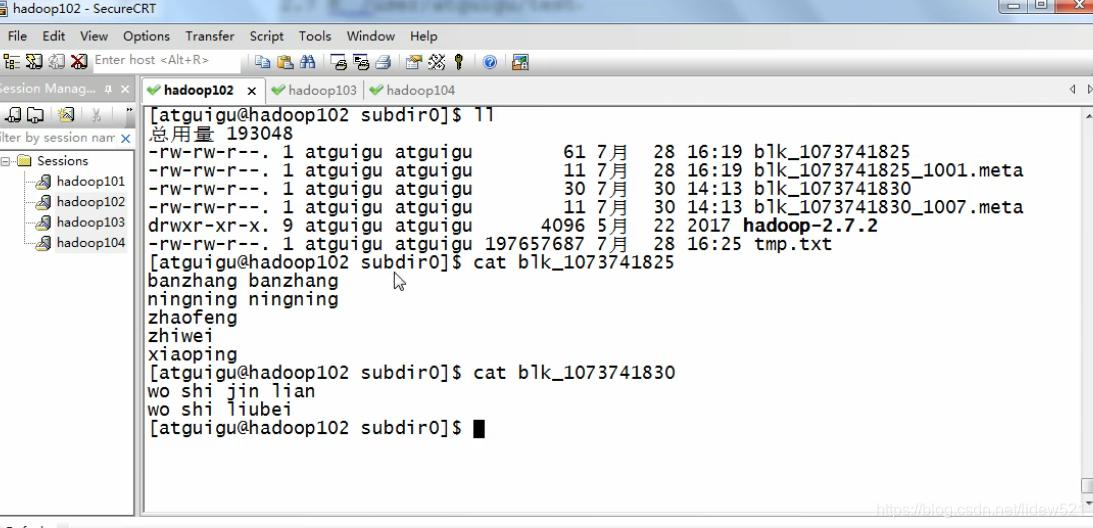

然后我们去看
cat blk_1073741825 去看看
这个内容是wc.input文件对吧.
然后我们再看一下
cat blk_1073741830
可以看到这个内容是panjinlian.txt对吧
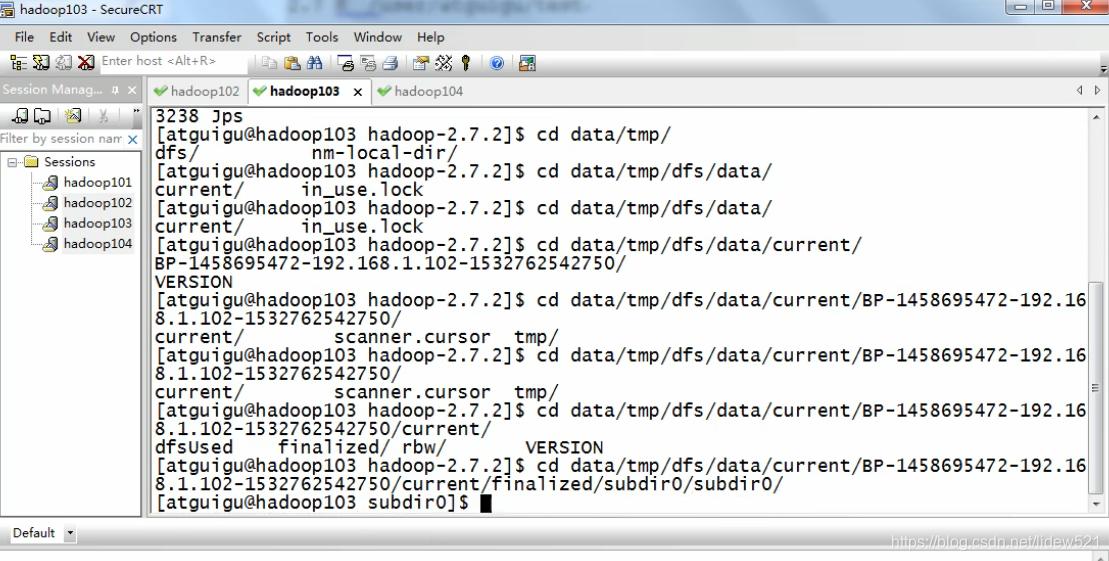

然后我们再从hadoop103这个机器上去看看
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-1458695472-192.168.1.102-1532762542750/current/finalized/subdir0/subdir0
进入这个目录
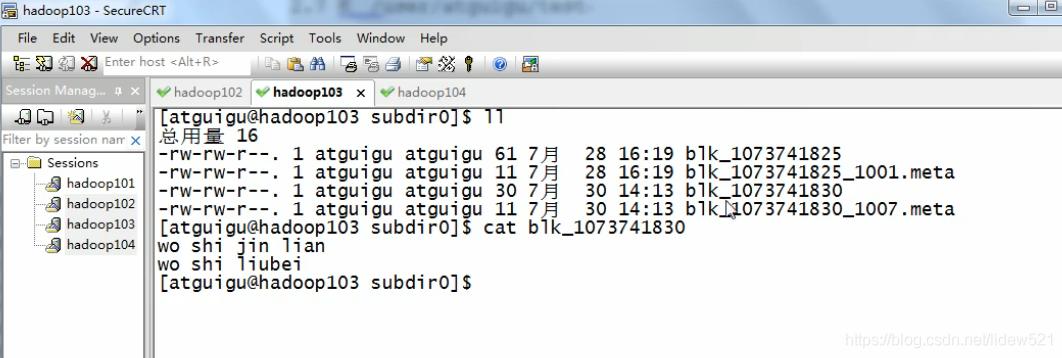

可以看到也有panjinlian.txt这个文件对吧
cat blk_1073741830去看看,没问题
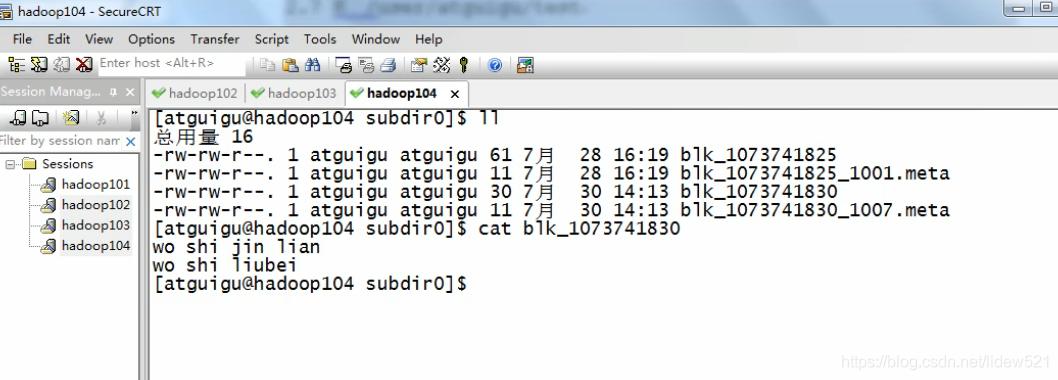

然后我们去104机器上去看看,依然有这个文件
cat blk_1073741830去看看,没问题
说明什么?
这一个block块,在3个机器上都有了就是存在3个副本了.没问题,跟显示的是一样的.
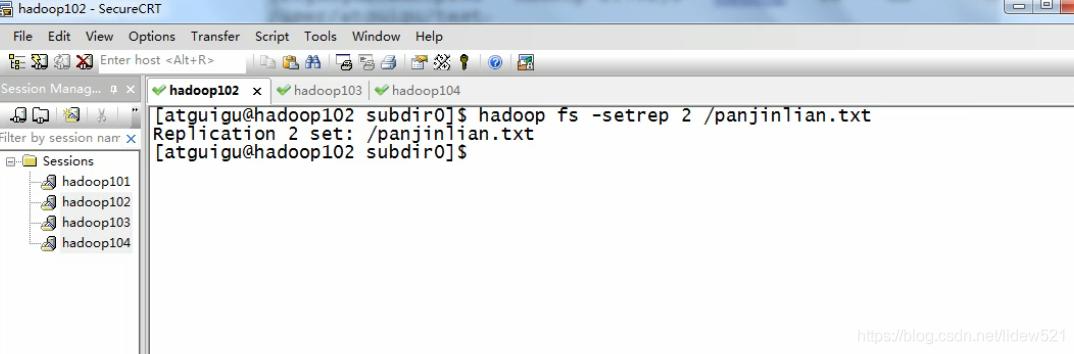

然后我们再去把panjinlian.txt的副本数设置成2
hadoop fs -setrep 2 /panjinlian.txt
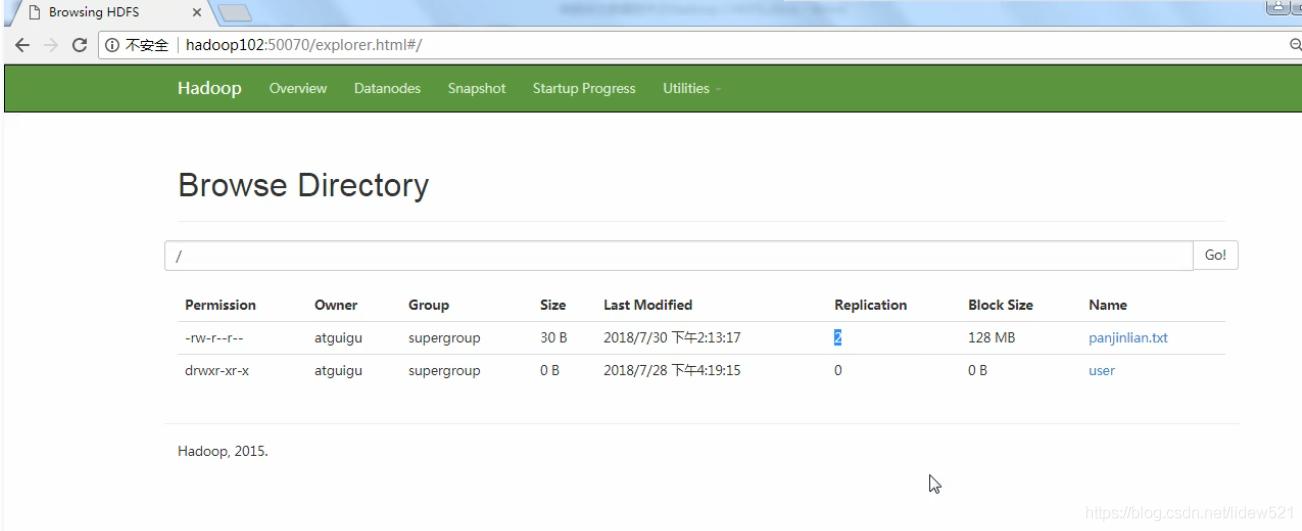

可以看到hdfs web端显示 panjinlian.txt还有2个副本
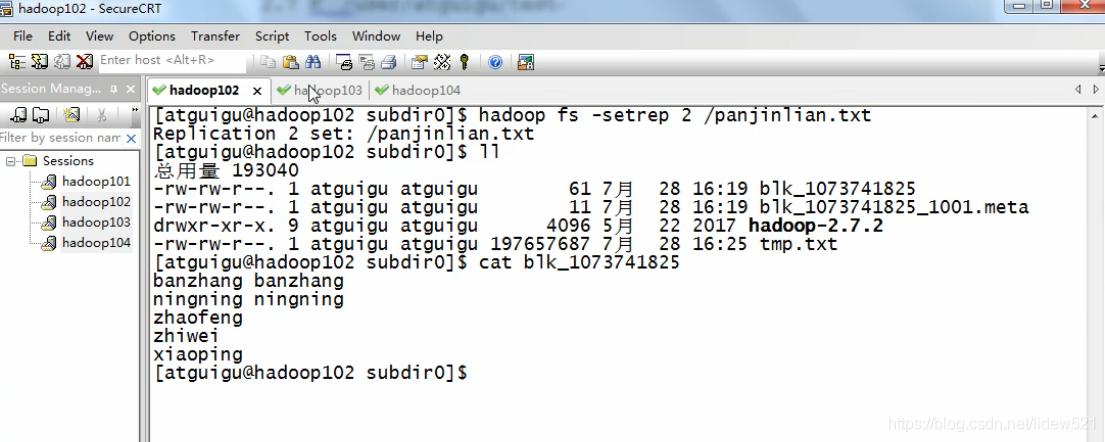

我们先去看看102这个机器,去看看ll
cat blk_1073741830 这个文件已经没了对吧.
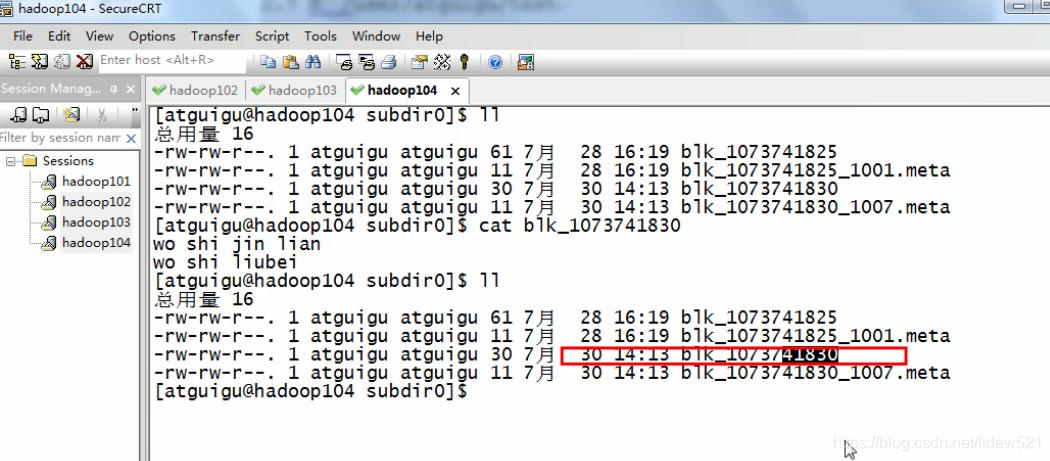

但是我们去看看104,这个机器上还有
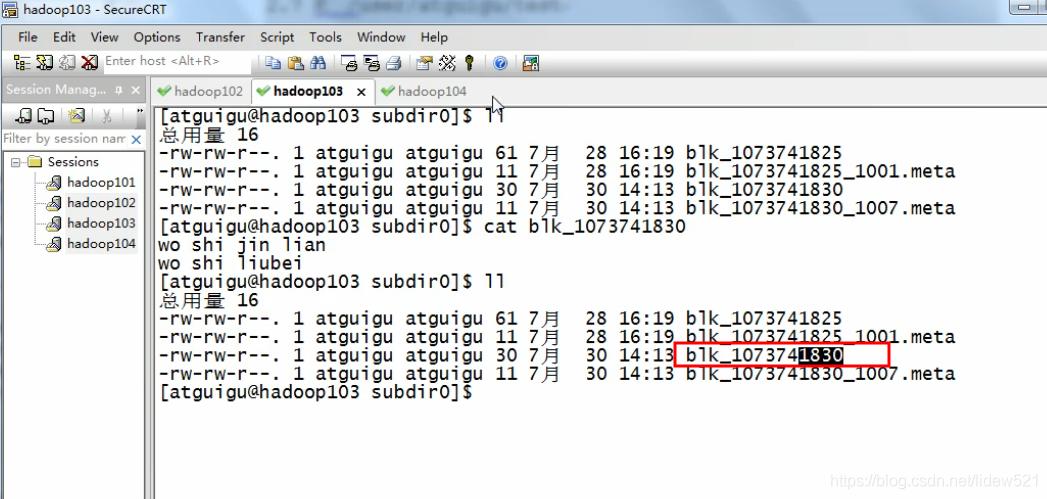

103上也有,说明,也没问题,副本变成了2个了.

然后我们顺手把102上的,这个
rm -rf hadoop-2.7.2/ tmp.txt
把hadoop-2.7.2/ 这文件夹,以及tmp.txt 这个文件删除,是以前残留的.
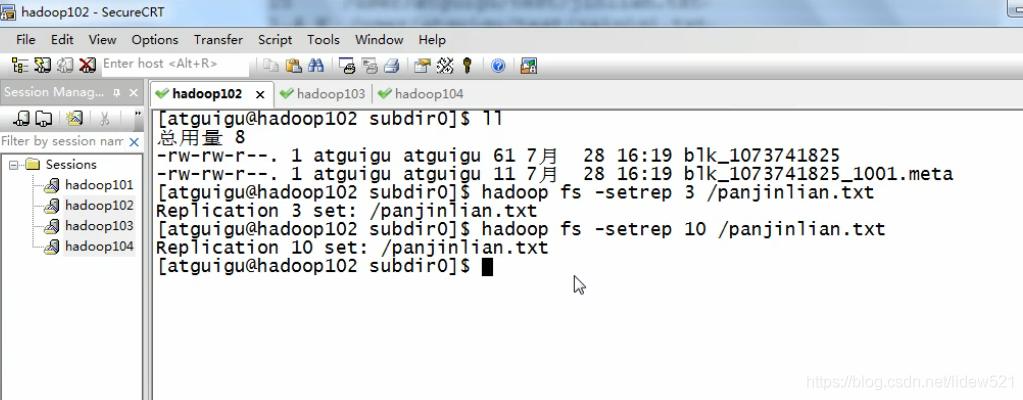

然后我们再去,把副本
hadoop fs -setrep 3 /panjinlian.txt 先设置成3 ,然后
hadoop fs -setrep 10 /panjinlian.txt 再设置成10
这样我们就有10个副本了对吧.
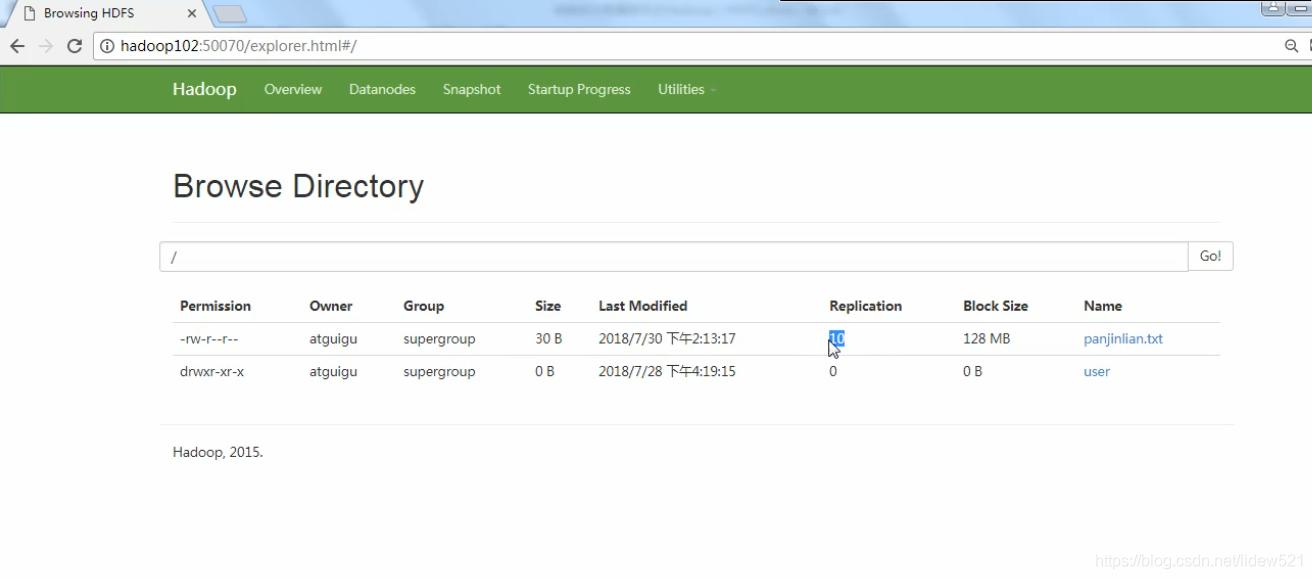

.我们去看看hdfs web端,显示有10个panjinlian.txt文件副本了.
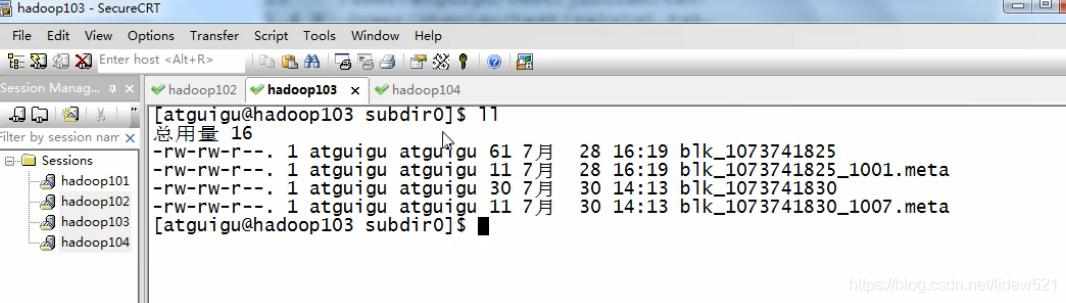

然后我们去看看103,有对吧
blk_1073741830
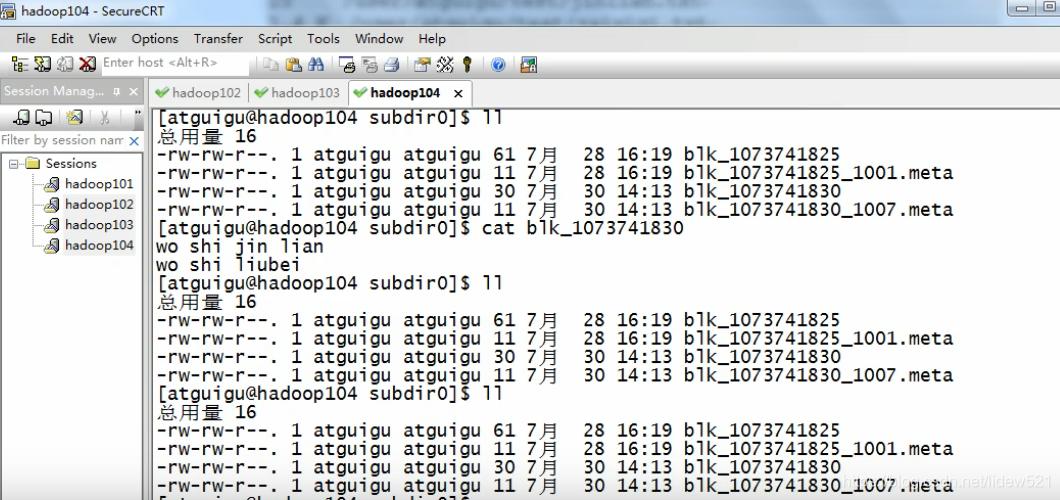

去104去看看
blk_1073741830 也有对吧.
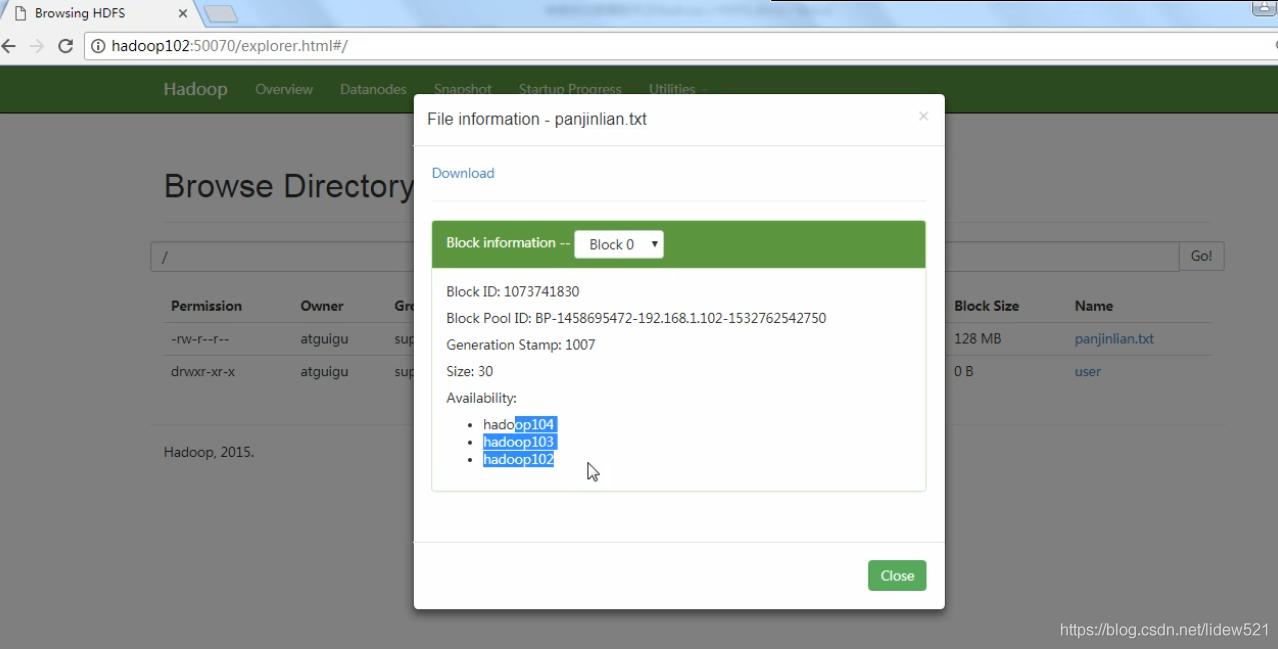

然后去hdfs web端看看,显示block0 这个块在,102,103,104上都有副本对吧,
我们看了103,104上有


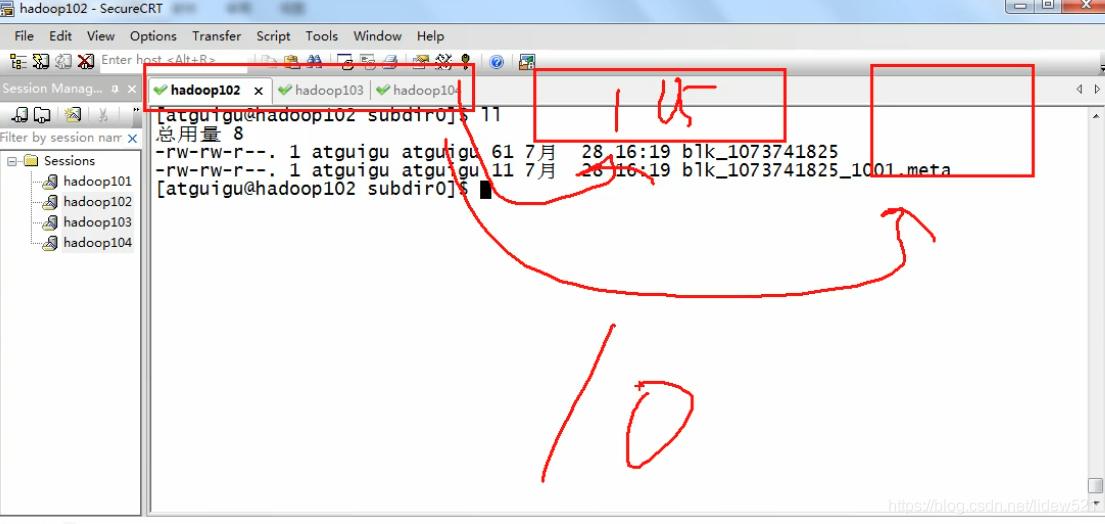
我们再去看看102上,还是没有对吧,说明什么,
他需要点时间,去处理一会就可以看到了.

那么现在有个问题就是,我们设置了10副本,但是呢?
我们现在只有3台机器,他会怎么做?
他会,等待,当我们把第4台机器,接入进来的是,他会把副本再copy到,第4台机器上..
就这样,直到维持够10个副本为止...他会这样来处理.
技术交流QQ群【JAVA,C++,Python,.NET,BigData,AI】:170933152开通了个人技术微信公众号:credream,CSDN账号:credreamer 有需要的朋友可以添加相互学习