

作者 | 天元浪子
责编 | 郭芮
出品 | CSDN 博客
大约七八年前,我曾经用 pyOpenGL 画过地球磁层顶的三维模型,这段代码至今仍然还运行在某科研机构里。在那之前,我一直觉得自己是一个合(you)格(xiu)的 Python 程序员,似乎无所不能。但磁层顶模型的显示效果令我沮丧——尽管这个模型只有十几万个顶点,拖拽、缩放却非常卡顿。
最终,我把顶点数量删减到两万左右,以兼顾模型质量和响应速度,才勉强交付了这个任务。从此我开始怀疑 Python 的性能,甚至一度怀疑 Python 是否还是我的首选工具。
幸运的是,后来我遇到了 NumPy 这个神器。NumPy 是 Python 科学计算的基础软件包,提供多维数组对象,多种派生对象(掩码数组、矩阵等)以及用于快速操作数组的函数及 API,它包括数学、逻辑、数组形状变换、排序、选择、I/O 、离散傅立叶变换、基本线性代数、基本统计运算、随机模拟等等。

了解 NumPy 之后,我才想明白当初磁层顶的三维模型之所以慢,是因为使用了 list(Python 数组)而不是 ndarray(NumPy 数组)存储数据。有了 NumPy,Python 程序员才有可能写出媲美 C 语言运行速度的代码。熟悉 NumPy,才能学会使用 PyOpenGL / PyOpenCV / Pandas / Matplotlib 等数据处理及可视化的模块。
事实上,NumPy 的数据组织结构,尤其是数组(numpy.ndarray),几乎已经成为所有数据处理与可视化模块的标准数据结构了(这一点,类似于在机器学习领域 Python 几乎已经成为首选工具语言)。越来越多的基于 Python 的科学和数学软件包使用 NumPy 数组,虽然这些工具通常都支持 Python 的原生数组作为参数,但它们在处理之前会还是会将输入的数组转换为 NumPy 的数组,而且也通常输出为 NumPy 数组。在 Python 的圈子里,NumPy 的重要性和普遍性日趋增强。换句话说,为了高效地使用当今科学/数学基于 Python 的工具(大部分的科学计算工具),你只知道如何使用 Python 的原生数组类型是不够的,还需要知道如何使用 numpy 数组。
在这个 AI 和 ML 霸屏的时代,如果不懂 NumPy,请别说自己是 Python 程序员。

list VS ndarray
numpy 的核心是 ndarray 对象(numpy 数组),它封装了 python 原生的同数据类型的 n 维数组(python 数组)。numpy 数组和 python 数组之间有几个重要的区别:
-
numpy 数组一旦创建,其元素数量就不能再改变了。增删 ndarray 元素的操作,意味着创建一个新数组并删除原来的数组。python 数组的元素则可以动态增减。
-
numpy 数组中的元素都需要具有相同的数据类型,因此在内存中的大小相同。python 数组则无此要求。
-
numpy 数组的方法涵盖了大量数*运学**算和复杂操作,许多方法在最外层的 numpy 命名空间中都有对应的映射函数。和 python 数组相比,numpy 数组的方*功法**能更强大,执行效率更高,代码更简洁。
然而,以上的差异并没有真正体现出 ndarray 的优势之所在,ndarray 的精髓在于 numpy 的两大特征:矢量化(vectorization)和广播(broadcast)。矢量化可以理解为代码中没有显式的循环、索引等,广播可以理解为隐式地对每个元素实施操作。矢量化和广播理解起来有点抽象,我们还是举个栗子来说明一下吧。
例题:a 和 b 是等长的两个整数数组,求 a 和 b 对应元素之积组成的数组。
1、用 python 数组实现:
c = listfor i in range(len(a)):c.append(a[i]*b[i])
2、用 numpy 数组实现:
c = a*b
这个栗子是不是体现了矢量化和广播的强大力量呢?请仔细体会!
总结:
-
矢量化代码更简洁,更易于阅读;
-
更少的代码行通常意味着更少的错误;
-
代码更接近于标准的数学符号;
-
矢量化代码更 pythonic。

dtype AND shape
子曰:找对象先了解品行,学对象先了解属性。ndarray 对象有很多属性,详见下表。
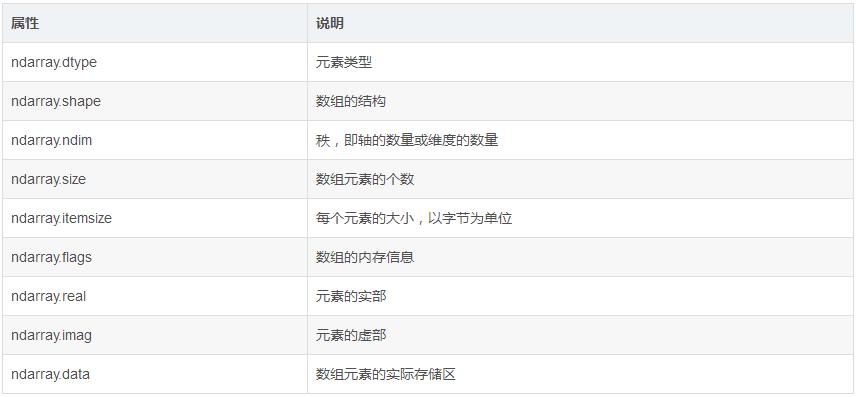
基于以下三个原因,我认为,dtype 和 shape 是 ndarray 最重要的两个属性,重要到几乎可以忽略其他的属性。
-
我们趟过的坑,几乎都是 dtype 挖的;
-
我们的迷茫,几乎都是因为 shape 和我们期望的不一样;
-
我们的工作,很多都是在改变 shape。
ndarray.astype 可以修改元素类型,ndarray.reshape 可以重新定义数组的结构,这两个方法的重要性和其对应的属性一样。记住这两个属性和对应的两个方法,就算是登堂入室了。想了解 numpy 支持的元素类型,请点击《数学建模三剑客MSN》(https://blog.csdn.net/xufive/article/details/52449255)。

创建数组
(1) 创建简单数组
numpy.array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)numpy.empty(shape, dtype=float, order=’C’)numpy.zeros(shape, dtype=float, order=’C’)numpy.ones(shape, dtype=float, order=’C’)numpy.eye(N, M=None, k=0, dtype=float, order=’C’)
应用示例:
>>> import numpy as np>>>> np.array([1, 2, 3])array([1, 2, 3])>>> np.empty((2, 3))array([[2.12199579e-314, 6.36598737e-314, 1.06099790e-313],[1.48539705e-313, 1.90979621e-313, 2.33419537e-313]])>>> np.zeros(2)array([0., 0.])>>> np.ones(2)array([1., 1.])>>> np.eye(3)array([[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
(2) 创建随机数组
numpy.random.random(size=None)numpy.random.randint(low, high=None, size=None, dtype=’l’)
应用示例:
>>> np.random.random(3)array([0.29334156, 0.45858765, 0.99297047])>>> np.random.randint(2, size=10)array([1, 0, 0, 0, 1, 1, 0, 0, 1, 0])>>> np.random.randint(5, size=(2, 4))array([[4, 0, 2, 1],[3, 2, 2, 0]])>>> np.random.randint(3,10,(2,4))array([[4, 8, 9, 6],[7, 7, 7, 9]])
(3) 在数值范围内创建数组
numpy.arange(start, stop, step, dtype=None)numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
应用示例:
>>> np.arange(5)array([0, 1, 2, 3, 4])>>> np.arange(0,5,2)array([0, 2, 4])>>> np.linspace(0, 5, 5)array([0. , 1.25, 2.5 , 3.75, 5. ])>>> np.linspace(0, 5, 5, endpoint=False)array([0., 1., 2., 3., 4.])>>> np.logspace(1,3,3)array([ 10., 100., 1000.])>>> np.logspace(1, 3, 3, endpoint=False)array([ 10. , 46.41588834, 215.443469 ])
(4) 从已有数组创建数组
numpy.asarray(a, dtype=None, order=None)numpy.empty_like(a, dtype=None, order=’K’, subok=True)numpy.zeros_like(a, dtype=None, order=’K’, subok=True)numpy.ones_like(a, dtype=None, order=’K’, subok=True)[source]
应用示例:
>>> np.asarray([1,2,3])array([1, 2, 3])>>> np.empty_like(np.asarray([1,2,3]))array([0, 0, 0])>>> np.zeros_like(np.asarray([1,2,3]))array([0, 0, 0])>>> np.ones_like(np.asarray([1,2,3]))array([1, 1, 1])
(5) 构造复杂数组
[1] 重复数组 tile
>>> a = np.arange(3)>>> aarray([0, 1, 2])>>> np.tile(a, 2)array([0, 1, 2, 0, 1, 2])>>> np.tile(a, (2,3))array([[0, 1, 2, 0, 1, 2, 0, 1, 2],[0, 1, 2, 0, 1, 2, 0, 1, 2]])
[2] 重复元素 repeat
>>> a = np.arange(3)>>> aarray([0, 1, 2])>>> a.repeat(2)array([0, 0, 1, 1, 2, 2])
[3] 一维数组网格化: meshgrid
>>> lon = np.arange(30, 120, 10)>>> lonarray([ 30, 40, 50, 60, 70, 80, 90, 100, 110])>>> lat = np.arange(10, 50, 10)>>> latarray([10, 20, 30, 40])>>> lons, lats = np.meshgrid(lon, lat)>>> lonsarray([[ 30, 40, 50, 60, 70, 80, 90, 100, 110],[ 30, 40, 50, 60, 70, 80, 90, 100, 110],[ 30, 40, 50, 60, 70, 80, 90, 100, 110],[ 30, 40, 50, 60, 70, 80, 90, 100, 110]])>>> latsarray([[10, 10, 10, 10, 10, 10, 10, 10, 10],[20, 20, 20, 20, 20, 20, 20, 20, 20],[30, 30, 30, 30, 30, 30, 30, 30, 30],[40, 40, 40, 40, 40, 40, 40, 40, 40]])
[4] 指定范围和分割方式的网格化: mgrid
>>> lats, lons= np.mgrid[10:50:10, 30:120:10]>>> latsarray([[10, 10, 10, 10, 10, 10, 10, 10, 10],[20, 20, 20, 20, 20, 20, 20, 20, 20],[30, 30, 30, 30, 30, 30, 30, 30, 30],[40, 40, 40, 40, 40, 40, 40, 40, 40]])>>> lonsarray([[ 30, 40, 50, 60, 70, 80, 90, 100, 110],[ 30, 40, 50, 60, 70, 80, 90, 100, 110],[ 30, 40, 50, 60, 70, 80, 90, 100, 110],[ 30, 40, 50, 60, 70, 80, 90, 100, 110]])>>> lats, lons = np.mgrid[10:50:5j, 30:120:10j]>>> latsarray([[10., 10., 10., 10., 10., 10., 10., 10., 10., 10.],[20., 20., 20., 20., 20., 20., 20., 20., 20., 20.],[30., 30., 30., 30., 30., 30., 30., 30., 30., 30.],[40., 40., 40., 40., 40., 40., 40., 40., 40., 40.],[50., 50., 50., 50., 50., 50., 50., 50., 50., 50.]])>>> lonsarray([[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.],[ 30., 40., 50., 60., 70., 80., 90., 100., 110., 120.]])
上面的例子中用到了虚数。构造复数的方法如下:
>>> complex(2,5)(2+5j)

数组操作
(1) 切片和索引
对于一维数组的索引和切片,numpy和python的list一样,甚至更灵活。
a = np.arange(9)>>> a[-1] # 最后一个元素8>>> a[2:5] # 返回第2到第5个元素array([2, 3, 4])>>> a[:7:3] # 返回第0到第7个元素,步长为3array([0, 3, 6])>>> a[::-1] # 返回逆序的数组array([8, 7, 6, 5, 4, 3, 2, 1, 0])
假设有一栋2层楼,每层楼内的房间都是3行4列,那我们可以用一个三维数组来保存每个房间的居住人数(当然,也可以是房间面积等其他数值信息)。
>>> a = np.arange(24).reshape(2,3,4) # 2层3行4列>>> aarray([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]], [[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23]]])>>> a[1][2][3] # 虽然可以这样23>>> a[1,2,3] # 但这才是规范的用法23>>> a[:,0,0] # 所有楼层的第1排第1列array([ 0, 12])>>> a[0,:,:] # 1楼的所有房间,等价与a[0]或a[0,...]array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])>>> a[:,:,1:3] # 所有楼层所有排的第2到4列array([[[ 1, 2],[ 5, 6],[ 9, 10]], [[13, 14],[17, 18],[21, 22]]])>>> a[1,:,-1] # 2层每一排的最后一个房间array([15, 19, 23])
提示:对多维数组切片或索引得到的结果,维度不是确定的。
(2) 改变数组的结构
numpy 数组的存储顺序和数组的维度是不相干的,因此改变数组的维度是非常便捷的操作,除 resize 外,这一类操作不会改变所操作的数组本身的存储顺序。
>>> a = np.array([[1,2,3],[4,5,6]])>>> a.shape # 查看数组维度(2, 3)>>> a.reshape(3,2) # 返回3行2列的数组array([[1, 2],[3, 4],[5, 6]])>>> a.ravel # 返回一维数组array([1, 2, 3, 4, 5, 6])>>> a.transpose # 行变列(类似于矩阵转置)array([[1, 4],[2, 5],[3, 6]])>>> a.resize((3,2)) # 类似于reshape,但会改变所操作的数组>>> aarray([[1, 2],[3, 4],[5, 6]])
np.rollaxis 用于改变轴的顺序,返回一个新的数组。用法如下:
numpy.rollaxis(a, axis, start=0)
-
a:数组;
-
axis:要改变的轴,其他轴的相对顺序保持不变;
-
start:要改变的轴滚动至此位置之前,默认值为0。
应用示例:
>>> a = np.ones((3,4,5,6))>>> np.rollaxis(a, 3, 1).shape(3, 6, 4, 5)>>> np.rollaxis(a, 2).shape(5, 3, 4, 6)>>> np.rollaxis(a, 1, 4).shape(3, 5, 6, 4)
(3) 数组合并
[1] append
对于刚刚上手 numpy 的程序员来说,最大的困惑就是不能使用 append 方法向数组内添加元素了,甚至连 append 方法都找不到了。其实,numpy 仍然保留了 append 方法,只不过这个方法不再是 numpy 数组的方法,而是是升级到最外层的 numpy 命名空间了,并且该方法的功能不再是追加元素,而是合并数组了。
>>> np.append([1, 2, 3], [[4, 5, 6], [7, 8, 9]])array([1, 2, 3, 4, 5, 6, 7, 8, 9])>>> np.append([[1, 2, 3]], [[4, 5, 6]], axis=0)array([[1, 2, 3],[4, 5, 6]])>>> np.append(np.array([[1, 2, 3]]), np.array([[4, 5, 6]]), axis=1)array([[1, 2, 3, 4, 5, 6]])
[2] concatenate
concatenate 和 append 的用法非常类似,不过是把两个合并对象写成了一个元组 。
>>> a = np.array([[1, 2], [3, 4]])>>> b = np.array([[5, 6]])>>> np.concatenate((a, b), axis=0)array([[1, 2],[3, 4],[5, 6]])>>> np.concatenate((a, b.T), axis=1)array([[1, 2, 5],[3, 4, 6]])>>> np.concatenate((a, b), axis=None)array([1, 2, 3, 4, 5, 6])
[3] stack
除了 append 和 concatenate ,数组合并还有更直接的水平合并(hstack)、垂直合并(vstack)、深度合并(dstack)等方式。假如你比我还懒,那就只用 stack 吧,足够了。
>>> a = np.arange(9).reshape(3,3)>>> b = np.arange(9,18).reshape(3,3)>>> aarray([[0, 1, 2],[3, 4, 5],[6, 7, 8]])>>> barray([[ 9, 10, 11],[12, 13, 14],[15, 16, 17]])>>> np.hstack((a,b)) # 水平合并array([[ 0, 1, 2, 9, 10, 11],[ 3, 4, 5, 12, 13, 14],[ 6, 7, 8, 15, 16, 17]])>>> np.vstack((a,b)) # 垂直合并array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11],[12, 13, 14],[15, 16, 17]])>>> np.dstack((a,b)) # 深度合并array([[[ 0, 9],[ 1, 10],[ 2, 11]], [[ 3, 12],[ 4, 13],[ 5, 14]], [[ 6, 15],[ 7, 16],[ 8, 17]]])
stack 函数原型为 stack(arrays, axis=0),请注意体会下面例子中的 axis 的用法。
>>> a = np.arange(60).reshape(3,4,5)>>> b = np.arange(60).reshape(3,4,5)>>> a.shape, b.shape((3, 4, 5), (3, 4, 5))>>> np.stack((a,b), axis=0).shape(2, 3, 4, 5)>>> np.stack((a,b), axis=1).shape(3, 2, 4, 5)>>> np.stack((a,b), axis=2).shape(3, 4, 2, 5)>>> np.stack((a,b), axis=3).shape(3, 4, 5, 2)
(4) 数组拆分
拆分是合并的逆过程,概念是一样的,但稍微有一点不同:
>>> a = np.arange(4).reshape(2,2)>>> aarray([[0, 1],[2, 3]])>>> x, y = np.hsplit(a, 2) # 水平拆分,返回list>>> xarray([[0],[2]])>>> yarray([[1],[3]])>>> x, y = np.vsplit(a, 2) # 垂直拆分,返回list>>> xarray([[0, 1]])>>> yarray([[2, 3]])>>> a = np.arange(8).reshape(2,2,2)>>> aarray([[[0, 1],[2, 3]], [[4, 5],[6, 7]]])>>> x,y = np.dsplit(a, 2) # 深度拆分,返回list>>> xarray([[[0],[2]], [[4],[6]]])>>> yarray([[[1],[3]], [[5],[7]]])
(5) 数组排序
排序不是 numpy 数组的强项,但 python 数组的排序速度依然只能望其项背。
[1] numpy.sort
numpy.sort 函数返回输入数组的排序副本。
numpy.sort(a, axis=-1, kind=’quicksort’, order=None)
-
a:要排序的数组;
-
axis:沿着它排序数组的轴,如果没有,数组会被展开,沿着最后的轴排序;
-
kind:排序方法,默认为’quicksort’(快速排序),其他选项还有 ‘mergesort’(归并排序)和 ‘heapsort’(堆排序);
-
order:如果数组包含字段,则是要排序的字段。
应用示例:
>>> a = np.array([3, 1, 2])>>> np.sort(a)array([1, 2, 3])>>> dt = np.dtype([(’name’, ’S10’),(’age’, int)])>>> a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)>>> aarray([(b’raju’, 21), (b’anil’, 25), (b’ravi’, 17), (b’amar’, 27)],dtype=[(’name’, ’S10’), (’age’, ’<i4’)])>>> np.sort(a, order=’name’)array([(b’amar’, 27), (b’anil’, 25), (b’raju’, 21), (b’ravi’, 17)],dtype=[(’name’, ’S10’), (’age’, ’<i4’)])
[2] numpy.argsort
函数返回的是数组值从小到大的索引值。
numpy.argsort(a, axis=-1, kind=’quicksort’, order=None)
-
a:要排序的数组;
-
axis:沿着它排序数组的轴,如果没有,数组会被展开,沿着最后的轴排序;
-
kind:排序方法,默认为’quicksort’(快速排序),其他选项还有 ‘mergesort’(归并排序)和 ‘heapsort’(堆排序);
-
order:如果数组包含字段,则是要排序的字段。
应用示例:
>>> a = np.array([3, 1, 2])>>> np.argsort(a)array([1, 2, 0], dtype=int64)
(6) 查找和筛选
[1] 返回数组中最大值和最小值的索引
numpy.argmax(a, axis=None, out=None)numpy.argmin(a, axis=None, out=None)
[2] 返回数组中非零元素的索引
numpy.nonzero(a)
[3] 返回数组中满足给定条件的元素的索引
numpy.where(condition[, x, y])
应用示例:
>>> a = np.arange(10)>>> aarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])>>> np.where(a < 5)(array([0, 1, 2, 3, 4], dtype=int64),)>>> a = a.reshape((2, -1))>>> aarray([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])>>> np.where(a < 5)(array([0, 0, 0, 0, 0], dtype=int64), array([0, 1, 2, 3, 4], dtype=int64))>>> np.where(a < 5, a, 10*a)array([[ 0, 1, 2, 3, 4],[50, 60, 70, 80, 90]])
[4] 返回数组中被同结构布尔数组选中的各元素
numpy.extract(condition, arr)
应用示例:
>>> a = np.arange(12).reshape((3, 4))>>> aarray([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])>>> condition = np.mod(a, 3)==0>>> conditionarray([[ True, False, False, True],[False, False, True, False],[False, True, False, False]])>>> np.extract(condition, a)array([0, 3, 6, 9])
(7) 增减元素
[1] 在给定索引之前沿给定轴在输入数组中插入值,并返回新的数组
numpy.insert(arr, obj, values, axis=None)
应用示例:
>>> a = np.array([[1, 1], [2, 2], [3, 3]])>>> aarray([[1, 1],[2, 2],[3, 3]])>>> np.insert(a, 1, 5)array([1, 5, 1, 2, 2, 3, 3])>>> np.insert(a, 1, 5, axis=0)array([[1, 1],[5, 5],[2, 2],[3, 3]])>>> np.insert(a, 1, [5,7], axis=0)array([[1, 1],[5, 7],[2, 2],[3, 3]])>>> np.insert(a, 1, 5, axis=1)array([[1, 5, 1],[2, 5, 2],[3, 5, 3]])
[2] 在给定索引之前沿给定轴删除指定子数组,并返回新的数组
numpy.delete(arr, obj, axis=None)
应用示例:
>>> a = np.array([[1, 2], [3, 4], [5, 6]])>>> aarray([[1, 2],[3, 4],[5, 6]])>>> np.delete(a, 1)array([1, 3, 4, 5, 6])>>> np.delete(a, 1, axis=0)array([[1, 2],[5, 6]])>>> np.delete(a, 1, axis=1)array([[1],[3],[5]])
[3] 去除重复元素
numpy.unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None)
-
arr:输入数组,如果不是一维数组则会展开;
-
return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储;
-
return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储;
-
return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数。
应用示例:
>>> a = np.array([[1, 0, 0], [1, 0, 0], [2, 3, 4]])>>> np.unique(a)array([0, 1, 2, 3, 4])>>> np.unique(a, axis=0)array([[1, 0, 0],[2, 3, 4]])>>> u, indices = np.unique(a, return_index=True)>>> uarray([0, 1, 2, 3, 4])>>> indicesarray([1, 0, 6, 7, 8], dtype=int64)>>> u, indices = np.unique(a, return_inverse=True)>>> uarray([0, 1, 2, 3, 4])>>> indicesarray([1, 0, 0, 1, 0, 0, 2, 3, 4], dtype=int64)>>> u, num = np.unique(a, return_counts=True)>>> uarray([0, 1, 2, 3, 4])>>> numarray([4, 2, 1, 1, 1], dtype=int64)
(8) 数组IO
numpy 为 ndarray 对象引入了新的二进制文件格式,用于存储重建 ndarray 所需的数据、图形、dtype 和其他信息。.npy 文件存储单个数组,.npz 文件存取多个数组。
[1] 保存单个数组到文件
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
-
file:要保存的文件,扩展名为 .npy,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上;
-
arr:要保存的数组;
-
allow_pickle:可选,布尔值,允许使用 python pickles 保存对象数组,python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化;
-
fix_imports:可选,为了方便 pyhton2 读取 python3 保存的数据。
[2] 保存多个数组到文件
numpy.savze 函数用于将多个数组写入文件,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npz 的文件中。
numpy.savez(file, *args, **kwds)
-
file:要保存的文件,扩展名为 .npz,如果文件路径末尾没有扩展名 .npz,该扩展名会被自动加上;
-
args:要保存的数组,可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为 arr_0, arr_1…
-
kwds:要保存的数组使用关键字名称。
[3] 从文件加载数组
numpy.load(file, mmap_mode=None, allow_pickle=True, fix_imports=True, encoding=’ASCII’)
-
file:类文件对象(支持 seek() 和 read()方法)或者要读取的文件路径;
-
arr:打开方式,None | ‘r+’ | ‘r’ | ‘w+’ | ‘c’;
-
allow_pickle:可选,布尔值,允许使用 python pickles 保存对象数组,python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化;
-
fix_imports:可选,为了方便 pyhton2 读取 python3 保存的数据;
-
encoding:编码格式,‘latin1’ | ‘ASCII’ | ‘bytes’。
应用示例:
a = np.array([[1,2,3],[4,5,6]])b = np.arange(0, 1.0, 0.1)c = np.sin(b)# c 使用了关键字参数 sin_arraynp.savez("runoob.npz", a, b, sin_array = c)r = np.load("runoob.npz")print(r.files) # 查看各个数组名称print(r["arr_0"]) # 数组 aprint(r["arr_1"]) # 数组 bprint(r["sin_array"]) # 数组 c
[4] 使用文本文件存取数组
numpy 也支持以文本文件存取数据。savetxt 函数是以简单的文本文件格式存储数据,对应的使用 loadtxt 函数来获取数据。
应用示例:
a = np.array([1,2,3,4,5]) np.savetxt(’out.txt’,a)b = np.loadtxt(’out.txt’)print(b)

常用函数
(1) 舍入函数
[1] 四舍五入
numpy.around(a, decimals=0, out=None)
应用示例:
>>> np.around([-0.42, -1.68, 0.37, 1.64])array([-0., -2., 0., 2.])>>> np.around([-0.42, -1.68, 0.37, 1.64], decimals=1)array([-0.4, -1.7, 0.4, 1.6])>>> np.around([.5, 1.5, 2.5, 3.5, 4.5]) # rounds to nearest even valuearray([ 0., 2., 2., 4., 4.])
[2] 去尾和进一
numpy.floor(a)numpy.ceil(a)
应用示例:
>>> np.floor([-0.42, -1.68, 0.37, 1.64])array([-1., -2., 0., 1.])>>> np.ceil([-0.42, -1.68, 0.37, 1.64])array([-0., -1., 1., 2.])
(2) 数学函数
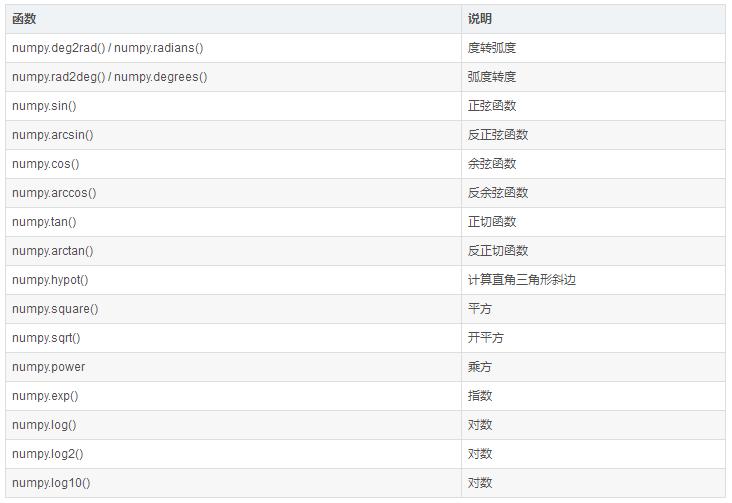
(3) 统计函数
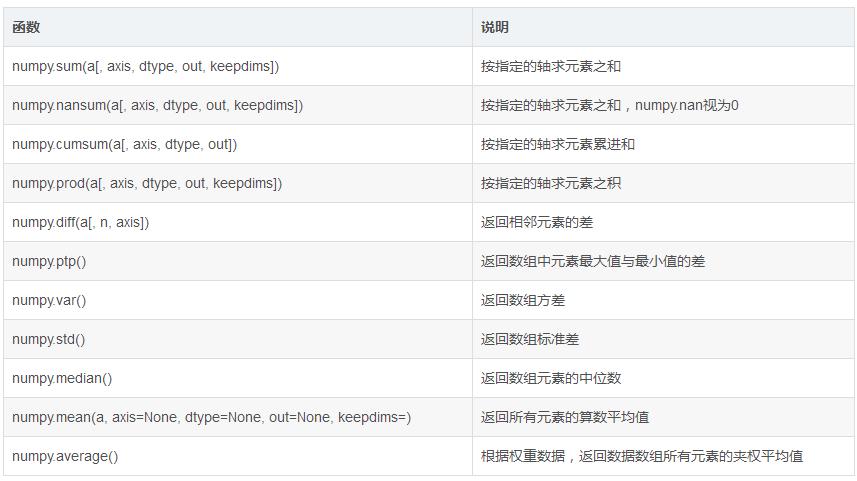

牛刀小试
例题:vertices 是若干三维空间随机点的集合,p 是三维空间的一点,找出 vertices 中距离 p 点最近的一个点,并计算它们的距离。
1、用 python 数组实现:
import mathvertices = [[3,4,5], [7,8,9], [4,9,3]]p = [2,7,4]d = listfor v in vertices:d.append(math.sqrt(math.pow(v[0]-p[0], 2)+math.pow(v[1]-p[1], 2)+math.pow(v[2]-p[2], 2)))print(vertices[d.index(min(d))], min(d))
2、用 numpy 数组实现:
import numpy as npvertices = np.array([[3,4,5], [7,8,9], [4,9,3]])p = np.array([2,7,4])d = np.sqrt(np.sum(np.square((vertices-p)), axis=1))print(vertices[d.argmin()], d.min)
用随机方式生成1000个点,比较两种方法的效率。
作者:天元浪子,本文精选自CSDN博客
原文https://blog.csdn.net/xufive/article/details/87396460。
【End】
