
当说不同语言的人聚在一起聊天时,他们会尝试使用当中每个人都能理解的语言。
为了实现这一目标,每个人都必须将他们通常以其本国语言表达的思想翻译成通用的语言。但是,这种语言的“编码和解码”会导致效率,速度和精度的损失。
在计算机系统及其组件中存在相同的概念。如果不需要我们直接了解他们在说什么,为什么我们应该以XML,JSON或任何其他人类可读格式发送数据?只要明确需要,我们仍然可以将其转换为可读的格式。
协议缓冲区是一种在传输之前对数据进行编码的方法,它可以有效地缩小数据块,从而在发送数据时提高速度。它将数据抽象为与语言和平台无关的格式。
为什么要使用协议缓冲区?
协议缓冲区的最初目的是简化请求/响应协议的工作。在ProtoBuf之前,Google使用了一种不同的格式,该格式需要对发送的邮件进行其他封送处理。
除此之外,以前格式的新版本要求开发人员在替换旧版本之前先确保已理解新版本,这使得使用起来很麻烦。
这项开销促使Google设计了一个可以准确解决这些问题的界面。
ProtoBuf允许在不破坏兼容性的情况下对协议进行更改。而且,服务器可以传递数据并在不修改其内容的情况下对数据执行读取操作。
由于格式有些自描述,因此ProtoBuf用作序列化器和反序列化器自动代码生成的基础。
另一个有趣的用例是Google如何将其用于短暂的远程过程调用(RPC)并将数据持久存储在Bigtable中。由于其特定的用例,他们将RPC接口集成到ProtoBuf中。这样可以快速而直接地生成代码存根,可用作实际实现的起点。(有关ProtoBuf RPC的更多信息。)
ProtoBuf有用的其他示例是通过移动网络连接的IoT设备,其中必须将发送的数据量保持在很小的水平,或者用于仍然很少使用高带宽的国家/地区的应用。以优化的二进制格式发送有效载荷会导致操作成本和速度上的明显差异。
gzip在HTTPS通信中使用压缩可以进一步改善这些指标。
什么是协议缓冲区,它们如何工作?
一般来说,协议缓冲区是用于结构化数据序列化的已定义接口。它定义了一种完全独立于语言和平台的标准化通信方式。
协议缓冲区是Google的与语言无关,与平台无关,可扩展的机制,用于对结构化数据进行序列化(例如XML),但更小,更快,更简单。
ProtoBuf接口描述了要发送的数据的结构。有效载荷结构在所谓的“原始文件”中定义为“消息”。这些文件始终以.proto 扩展名结尾。
例如,todolist.proto文件的基本结构如下所示。我们还将在下一部分中查看完整的示例。
然后,使用这些文件使用协议编译器中的代码生成器为您选择的语言生成集成类或存根。当前版本Proto3已经支持所有主要的编程语言。支持更多的第三方开源。
生成的类是协议缓冲区的核心元素。它们允许通过实例化基于.proto文件的新消息来创建元素,然后将这些文件用于序列化。在下一节中,我们将详细介绍如何使用Python完成此操作。
消息与序列化语言无关,被序列化为非自描述的二进制格式,如果没有初始结构定义,该格式几乎没有用。
然后可以存储二进制数据,通过网络发送和使用其他任何人类可读数据(如JSON或XML)的方式。传输或存储后,可以使用从.proto文件生成的任何特定于语言的已编译protobuf类对字节流进行反序列化和还原。
以Python为例,该过程如下所示:
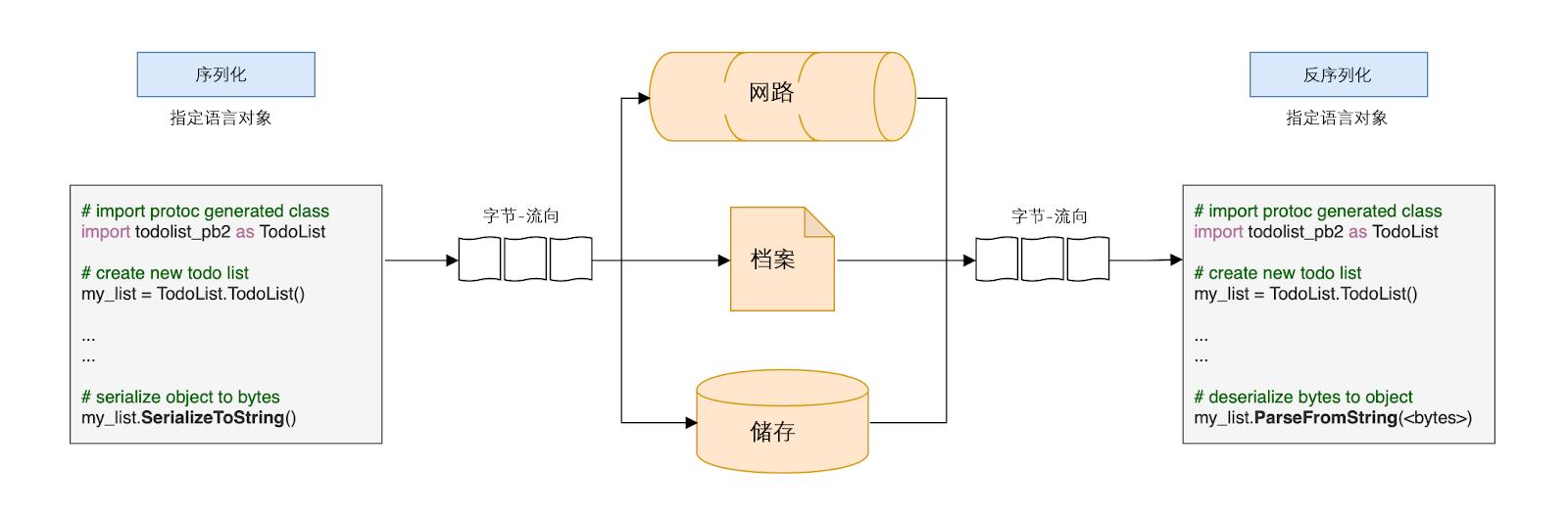
首先,我们创建一个新的待办事项列表,并填充一些任务。然后,此待办事项列表将被序列化并通过网络发送,保存在文件中或永久存储在数据库中。
使用我们特定于语言的已编译类的parse方法对发送的字节流进行反序列化。
当前的大多数体系结构和基础结构(尤其是微服务)都基于REST,WebSocket或GraphQL通信。但是,当速度和效率至关重要时,低级RPC可能会产生很大的不同。
代替高开销协议,我们可以使用快速而紧凑的方式在不同实体之间将数据移动到我们的服务中,而不会浪费很多资源。
但是为什么它还没有在所有地方使用呢?
协议缓冲区比其他人类可读格式要复杂一些。这使得它们更难调试和集成到您的应用程序中。 工程中的迭代时间也趋于增加,因为数据更新需要在使用前更新原型文件。 由于ProtoBuf在许多情况下可能是过度设计的解决方案,因此必须谨慎考虑。
有什么其他的选择?
Google的Flatbuffers和称为Cap'n Proto的第三方实现更着重于消除解析和拆包步骤,这是使用ProtoBufs时访问实际数据所必需的。它们是为性能关键型应用程序明确设计的,因此与ProtoBuf相比,它们甚至更快,内存效率更高。
当关注ProtoBuf(与gRPC一起使用)的RPC功能时,其他大型公司(例如Facebook(Apache Thrift)或Microsoft(Bond协议))的项目可以提供替代方案。
Python和协议缓冲区
Python已经使用了一些数据持久化的方法。仅在Python的应用程序中有很大的作用。它不适用于其他语言共享数据或更改架构的更复杂的场景。 相反,协议缓冲区正是针对这些情况而开发的。我们之前已经快速介绍了这些.proto文件,这些文件允许用户生成许多受支持语言的代码。 要将.proto 文件编译作为我们选择的语言类,可以使用protoc,即proto编译器。 如果你没有安装protoc编译器,那么可以这样做:
MacOS / Linux
视窗
一旦在系统上安装了协议,就可以使用之前的待办事项列表结构的扩展示例,并从中生成Python集成类。
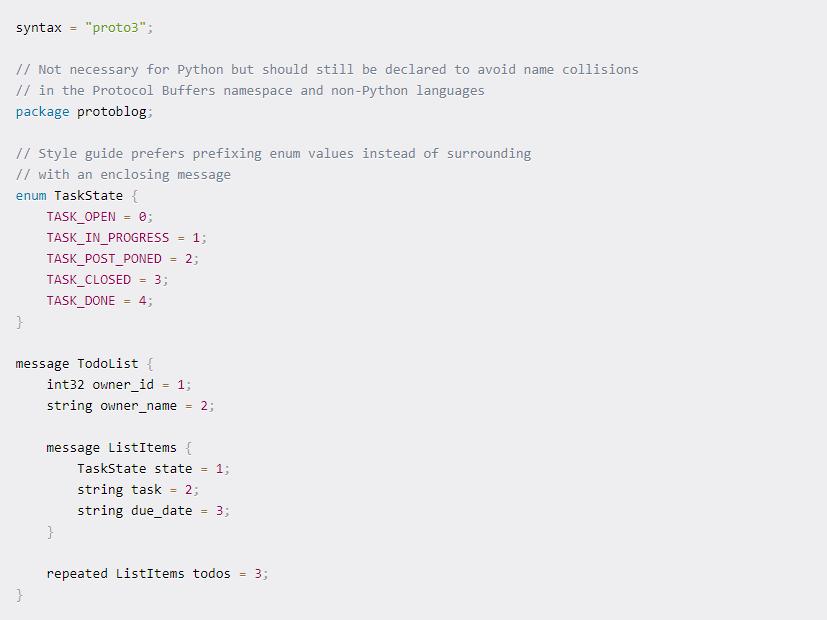
让我们更详细.proto地了解文件的结构以了解它。 在proto文件的第一行中,我们定义是使用Proto2还是3。在这种情况下,我们使用Proto3。
原始文件中最不常见的元素是分配给消息的每个实体的编号。这些专用数字使每个属性唯一,并用于标识二进制编码输出中的分配字段。
要掌握的一个重要概念的是,只有值1-15会用少一个字节(Hex)进行编码,这对理解很有用,因此我们可以为使用频率较低的实体分配较高的数字。数字既不定义编码顺序也不定义给定属性在编码消息中的位置。
程序包定义有助于防止名称冲突。在Python中,软件包由其目录定义。因此,提供package属性对生成的Python代码没有产生任何影响。
请注意,对于其他语言(例如Java),仍应声明该名称以避免协议缓冲区相关的名称冲突。
在这种情况下,我们为待办事项列表上每个任务的可能状态定义一个Enum。 看一下Python中的用法,我们将看到如何使用它们。 在示例中可以看到,我们还可以将消息嵌套在当中。 例如,如果我们想要与给定的待办事项列表关联的待办事项列表,则可以使用重复关键字,该关键字与动态调整大小的数组相当。
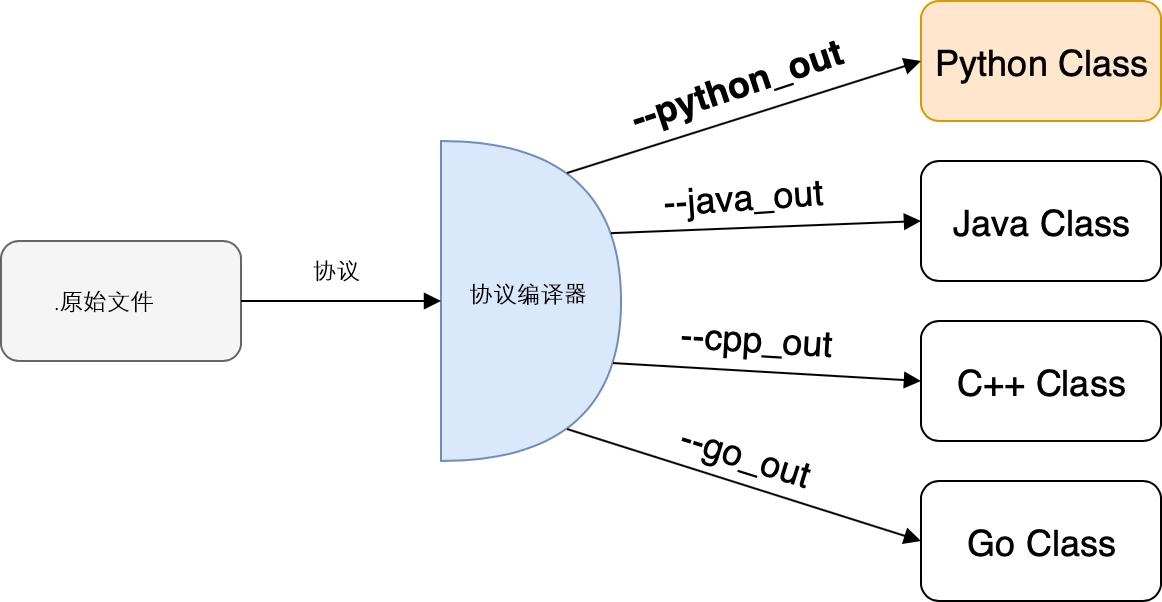
为了生成可用的集成代码,我们使用proto编译器将给定的.proto文件编译为特定于语言的集成类。在我们的例子中,我们使用--python-out参数生成特定于Python的代码。 protoc -I=. --python_out=. ./todolist.proto 在终端中,我们使用三个参数调用协议编译器:
-I:定义在其中搜索任何依赖项的目录(我们使用。作为当前目录)
--python_out:定义要在其中生成Python集成类的位置(再次使用。这是当前目录)
最后一个未命名的参数定义将要编译的.proto文件(我们在当前目录中使用todolist.proto文件)
这将创建一个名为<name_of_proto_file> _pb2.py的新Python文件。在我们的例子中,它是todolist_pb2.py。当仔细查看此文件时,我们无法立即了解其结构。这是因为生成器不会产生直接的数据访问元素,而是会使用元类和每个属性的描述符进一步简化复杂性。它们描述了一个类的行为方式,而不是该类的每个实例。
更加令人兴奋的部分是如何使用此生成的代码来创建,构建和序列化数据。以下是与我们最近生成的类进行的直接集成:
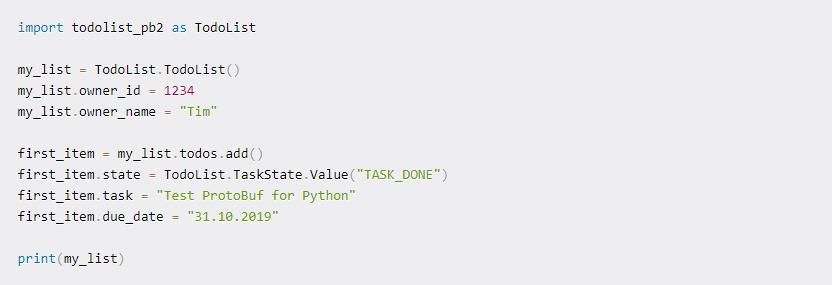
它仅创建一个新的待办事项列表并向其中添加一个项目。然后,我们打印待办事项列表元素本身,并可以看到我们在脚本中刚刚定义的数据的非二进制,非序列化版本。

每个协议缓冲区类都有使用特定于协议缓冲区的编码来读写消息的方法,该编码将消息编码为二进制格式。这两种方法是SerializeToString()和ParseFromString()。

在上面的代码示例中,我们使用wb标志将字节序列化字符串写入文件。由于我们已经写了文件,因此可以读回内容并使用ParseFromString对其进行解析。ParseFromString使用rb标志调用序列化类的新实例并对其进行解析。如果我们将此消息序列化并在控制台中打印,我们将获得如下所示的字节表示形式。
b'\x08\xd2\t\x12\x03Tim\x1a(\x08\x04\x12\x18Test ProtoBuf for Python\x1a\n31.10.2019'
请注意引号前面的b。这表明以下字符串由Python中的字节八位字节组成。如果直接将其与XML进行比较,我们可以看到ProtoBuf序列化对大小的影响。

JSON表示如下所示。
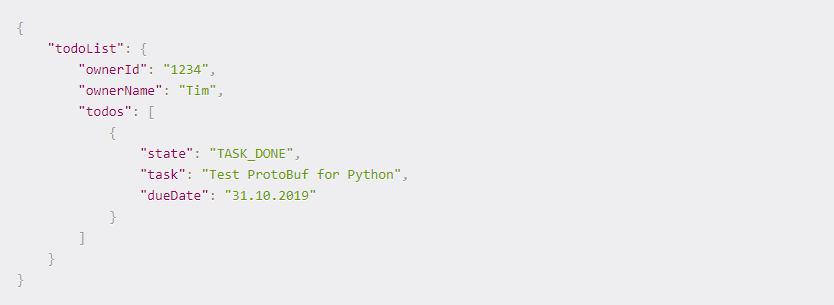
仅通过使用的字节总数来判断不同的格式,而忽略格式化它所需的内存,可以看到它们的不同之处。但是除了用于数据的内存外,ProtoBuf中还有12个额外的字节用于格式化序列化数据。与XML相比,我们在XML中有171个额外的字节用于格式化序列化数据。没有Schema,我们需要JSON中的136个额外字节来 格式化 序列化数据。
如果我们谈论的是通过网络发送或存储在磁盘上的数千条消息,ProtoBuf可以有所作为。但是,有一个陷阱。Auth0.com平台在ProtoBuf和JSON之间进行了广泛的比较。它表明压缩后,两者之间的大小差异可能很小(仅9%左右)。如果你对确切的数字感兴趣,请参阅整篇文章,其中详细分析了一些因素,例如大小和速度。
一个有趣的注释是,每种数据类型都有一个默认值。如果未分配或更改属性,则它们将保留默认值。在我们的情况下,如果我们不更改ListItem的TaskState,则默认情况下其状态为“ TASK_OPEN”。这样明显着优点是未设置的值不会被序列化,从而节省了额外的空间。例如,如果我们将任务的状态从TASK_DONE更改为TASK_OPEN,它将不会被序列化。

b'\x08\xd2\t\x12\x03Tim\x1a&\x12\x18Test ProtoBuf for Python\x1a\n31.10.2019'
最后说明
如我们所见,协议缓冲区在处理数据时的速度和效率方面非常方便。由于其强大的特性,即使定义新消息的语法很简单,也要花一些时间才能习惯ProtoBuf系统。
最后一点,我想指出的是,关于协议缓冲区是否对常规应用程序“有用”的讨论正在进行中。它们是针对Google想到的问题而明确开发的。