在和身边的人沟通自动驾驶的数据闭环时,会碰到两类典型的人:第一类,当你给他讲数据闭环的时候,他的眼神是迷茫的,好像没有引起太多的重视和共鸣,甚至有人会反馈:“嗯,这个没什么,我们以前干的差不多”;第二类,他会觉得数据闭环,能解决一切问题,而且,数据闭环是一种全新的工作方式。
第一类人低估了数据闭环的重要性,第二类人高估了数据闭环的重要性。
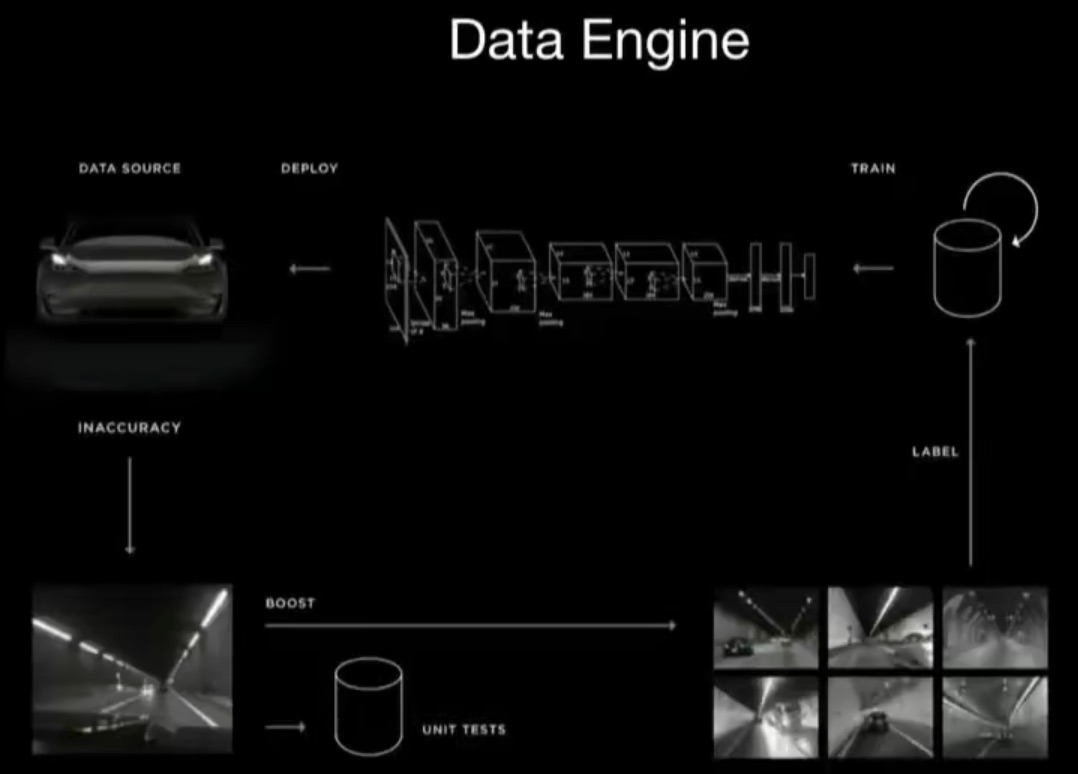
图1 特斯拉AI高级总监Andrej Karpathy 2020年2月提到的Data Engine引起热议
虽然,特斯拉AI高级总监 Andrej Karpathy 2020年2月“AI for Full-Self Driving”的演讲,是数据闭环热潮的起点,引起汽车行业的热议,但是,实际上, 数据闭环是一直是软件工程领域的一种成熟的工作方式,在人工智能时代,数据闭环并没有从根本上改变“整体”软件工程的工作方法,但是,对管理、运营和工具带来了全新挑战,因此,我们必须比以前更加重视数据闭环。
传统数据闭环已经被应用了超过20年
无论是早期的windows,还是最近的安卓,我们在系统使用的过程当中,都会被问到是否允许微软或者是谷歌收集你的数据[1],帮助改进用户体验。这就是传统的数据闭环。
图3 Google Fixel 2 Android手机的收集数据的选项界面
在微软Office软件崩溃(Crash)后,你也能够看到一个弹出对话框,问你是否允许上传本次崩溃的信息,帮助微软改进Office。 那这就是最经典的数据闭环。
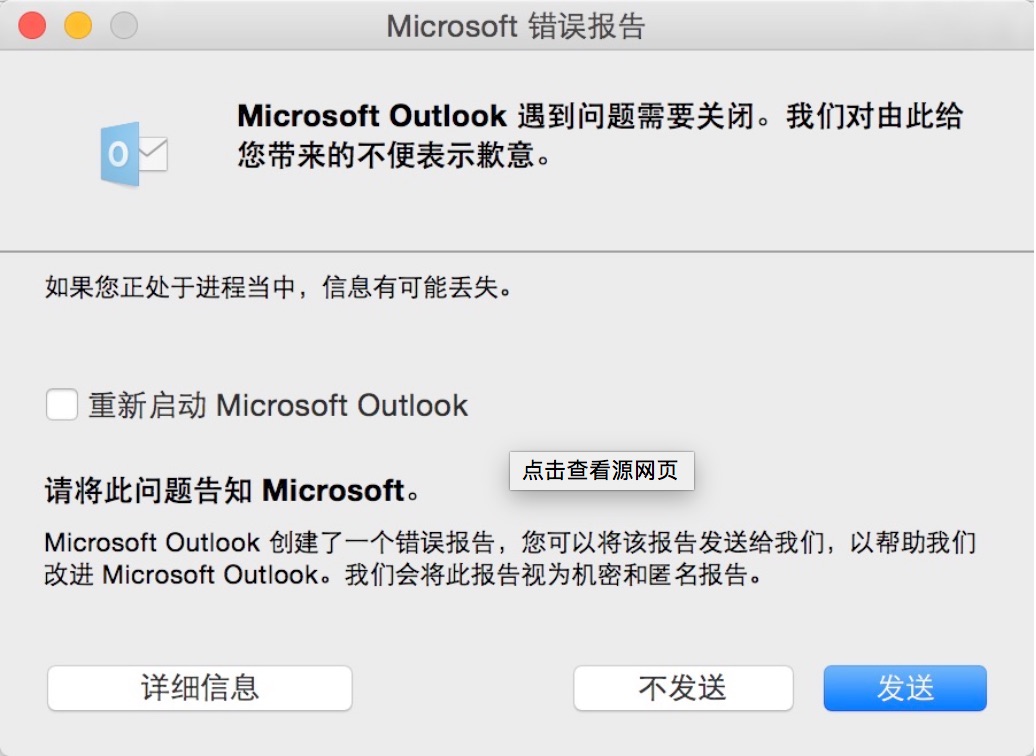
我们可以看一下,经典的数据闭环是一个什么样的工作流程?

图6 传统的数据避免的工作流程
比如,终端产品(Office)捕捉到一个崩溃的问题后,软件上传现场数据。
然后,软件厂商的工程师根据这些数据,分析和解决问题。
只有有了这些现场数据,软件厂商的工程师才能够了解这到底是什么问题,才能够解决这样的崩溃问题。我们在传统的软件工程当中,常说的一句话就是,复现一个问题,等于解决问题的50%。主要是因为传统的软件代码,太过复杂, 用户操作可能会引发各种Corner Cases ,对于各种Crash的异常行为,是无法通过阅读代码来发现问题的。最有效的解决方法,就是能够复现问题,然后依赖调试信息,发现问题所在的模块,然后找到了对应的问题的位置,解决它就相对比较容易了。
软件工程师解决问题之后,然后要进行测试。因为,软件代码解决问题,也常常会导致其他地方产生新问题,这主要是因为软件的复杂度大,规模上升。
测试通过之后,发布新软件版本:更新文件拷贝,或者OTA升级。然后,终端产品验证问题和继续反馈数据。
这就是 传统软件的数据闭环,我们已经应用了这种方法超过了20年 (从2000年互联网大规模应用开始)。
人工智能时代,数据闭环发生了什么改变?
我们来看一个例子,在人工智能时代,数据闭环的工作流程是怎么样的?
小鹏P7曾经有一起事故,在开启NGP模式下以120码时速无减速撞到了前方约60时速的载物板车[2]。我们以这个例子,看看数据闭环如何帮助小鹏汽车改进。

图7 小鹏P7在开启NGP模式下以120码时速无减速撞到了前方约60时速的板车
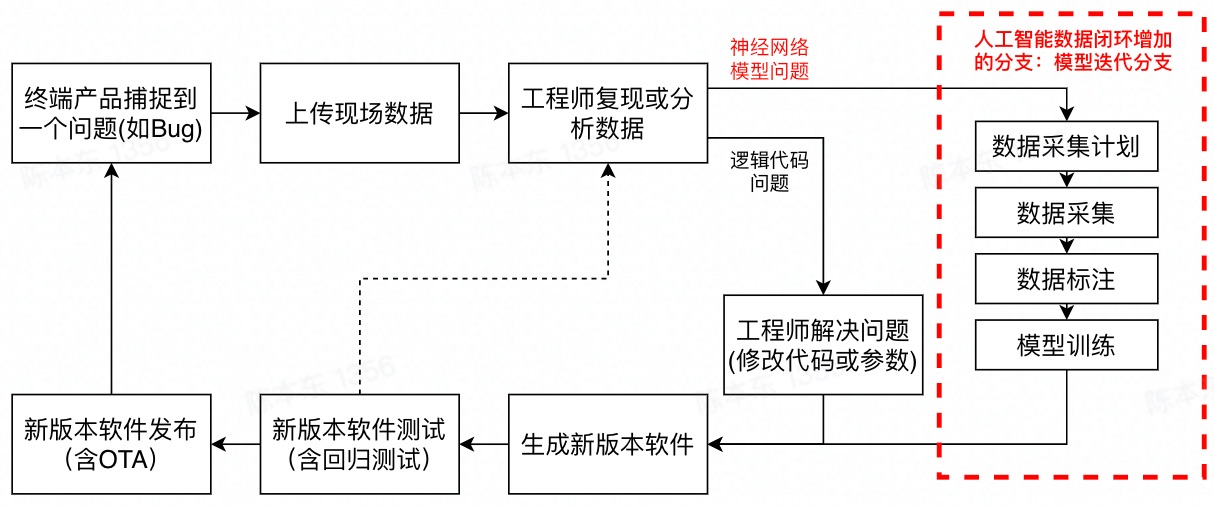
图8 人工智能的数据闭环的工作流程(无初步模型)
首先,在汽车终端设定一个触发程序,在特定情况时,比如说撞车的时候,把汽车的现场的数据,上传到服务器端。除了图像之外,还有地理位置、速度、刹车等数据信息。
然后仍然需要一位工程师,在后台分析这些数据,看看这些问题到底在哪里。因为,问题不一定是AI模型的问题,也可能是逻辑代码的问题。比如说前处理、后处理、规划控制算法出了问题(规划控制算法现在大部分仍是传统软件)。
如果这个工程师分析问题的原因不是模型的问题,而是逻辑代码的问题(如前处理、后处理、传统规划控制代码),那么, 数据闭环的使用方式,和传统的数据闭环完全一致,100%一致。解决问题的成本也是类似的 。
这种情况是完全有可能发生的。比如说某造车新势力汽车的一次撞车事故当中,据悉分析出的原因,Mobileye的感知算法没有问题,而是某造车新势力汽车自己的控制算法有问题。
但是有另一种可能性,就是经过这个工程师的分析后,发现在这个问题是感知模型的问题。如在小鹏汽车的这起事故中,参考文献3认为,因为视觉感知系统不能检测到前方异形车,导致了这次撞车事故。也就是说,要解决这个问题,必须重新训练人工智能模型。 在这种情况下,人工智能的数据闭环和传统的数据闭环在流程上就会有区别 。

图9 人工智能的数据闭环的工作流程
由于小鹏汽车的自动驾驶系统不能检测到这种板车,所以,系统之前是没有上传这种板车的数据的。小鹏的工程师要把这个问题反馈给自动驾驶产品经理,产品经理要做出数据采集计划:这个异形车是什么型号?在中国市场,类似的车哪些常用?从哪些渠道可以采集到数据?采集速度怎么样?自动和人工采集各占多大比例?
再下一步,是根据数据采集计划,去采集这种异形车的数据。
然后,对采集到的数据安排标注。一般标注环节是少不了人工参与的,虽然机器辅助标注的方法,在后期可能会提高效率。
标注之后,把数据提交给算法工程师,算法工程师训练新的模型。理想情况下,新训练的模型就具备了识别这样的异形车的能力。
但是现实世界中,都是非理想情况。所以,和特斯拉的Data Engine一样,小鹏汽车经过上面的步骤,只能得到一个 “初步的检测器”(approximate detector) ,即这个模型仍然有很多“板车”不能识别( Corner Cases),这个时候,仍然需要数据闭环,把“初步的检测器”判定为“ 疑似板车 ”的数据上传到服务器,作为“自动”的数据采集,经过筛选后,进入到数据标注环节。
注意,即使有了“初步的检测器”,小鹏汽车的产品经理仍可能计划人工数据采集,加快项目进度。因为,有可能小鹏汽车不能识别“板车”的舆论压力很大,等待“初步的检测器”自动上传足够的数据来不及。
大家可以看到,人工智能数据闭环和传统数据闭环比较,多了一个分支,在这个分支下,需要通过数据解决模型的问题,包含数据采集计划、数据采集、数据筛选、数据标注、模型训练、生成“初步的检测器”、生成量产模型等步骤。
我们把这个分支叫做“模型迭代分支” 。
所以, 人工智能数据闭环,就是在传统数据闭环上,增加了一个“模型迭代分支”,和传统数据闭环的“工程师解决问题(修改代码或参数)”并列 ,这就是人工智能的数据闭环的完整流程图。
人工智能数据闭环对管理、运营和工具带来了全新挑战
以前,所有的问题、代码的质量,都是由软件工程师的能力决定的。现在,有很大比例的问题,要靠数据闭环的运营效率决定了。
人工智能数据闭环对我们的影响很大,因为对管理、运营和工具带来全新的挑战。
对于传统数据闭环的分支,解决问题的是“工程师”。对于“模型迭代分支”,解决问题的变成了“数据采集人员+数据标注人员+工程师”。由于“数据采集人员+数据标注人员”的数量是工程师的数倍,这 不光要求团队招聘新的角色,还彻底改变了团队的人员结构,给管理、运营和工具带来全新挑战 。
比如,在2020年特斯拉CEO马斯克的采访中,他指出,整个 Autopilot 团队 软件端不到 200 人 ,但是,“ 光是打标签这项工作,我们都投入了 500 多名熟练工 ”,并且,“我们准备将 打标签的团队扩充到 1000 人 ,而且人人都是行内高手。”
即Autopilot团队软件端(注意不只是“算法工程师”)和标签团队的人数比例是2:5到1:5之间。
第一个挑战,是管理。 就像一个以前做研发的团队,突然增加了70%人数的生产线工人,如何有效管理(组织架构、激励、考核)对这个团队的领导带来全新的挑战,整个团队的心态也要进行调整(高科技团队To数据工厂)。
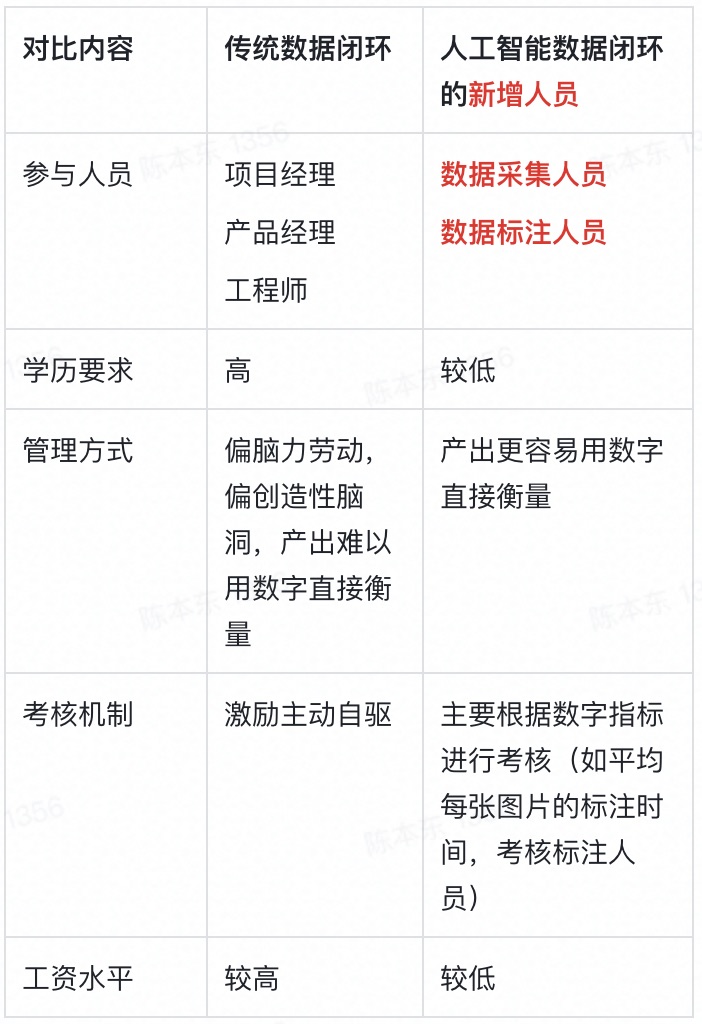
表1 人工智能数据闭环的新增人员的管理方式变化

图10 如何有效利用数据采集、数据标注员工,是管理人员面临的新挑战
团队的领导要回答2个问题:
- 新增人员的实体组织怎么安排?是汇报给研发领导,还是成立独立的部门?是否异地办公?是否用临时工?是大量使用外包员工?是否设立自己的子公司?招聘、日常管理、激励和考核都要重新安排。
- 新增人员和在项目维度怎么管理?原来的项目经理直接管理标注团队,还是增加一个子项目经理,专门作为新增团队的接口人?
第二个挑战,是运营 。团队领导 怎么确保团队的工作量稳定?避免有时忙不过来,有时没活干?
以前,传统数据闭环没反馈数据时,工程师就去写新代码、开发新功能了,没有人力浪费。现在,人工智能数据闭环没反馈数据,团队大量人员就没活干了。
这要求设备端上传的数据量要较平稳,不要忽多忽少,数据量和人员的规模匹配。对于自动驾驶,这主要是要求规划好车队数量,运营好车队的驾驶里程、路线、和配置好触发器。
第三个挑战,是工具 。工欲善其事必先利其器。如果工具不稳定、不高效,就会直接导致数据采集、数据标注团队效率低下。
所以,人工智能数据闭环,要求 管理分层,运营稳定,工具高效。
有2个方案:
方案一:循序渐进
在从0到1的阶段,研发团队和采集、标注团队都在研发体系,此时采集、标注的人数也较少(10人左右),双方密切沟通,频繁迭代工具,直到把工具打磨好,工作效率达到业界一流。
现在很多公司都有专门的团队做工具开发,这块的工作量不小。
方案二:引进方案
通过购买其他公司的数据采集、数据标注方案,在第一步时,就建立独立的数据采集、数据标注团队(数十人)。
这种方案的优势是避免了重复造轮子,大大缩短了建立人工智能的数据闭环的时间。
所以,由于管理、运营和工具上的挑战, 人工智能的数据闭环的运营成本大大增加 。这导致人工智能数据闭环,只能在“辅助驾驶”和“自动驾驶”类似的附加值较高的行业,得到运用。如果是价值较小的行业,比如考勤系统的人脸识别系统,通常软件出厂前,集中采集或标注几批数据就够用了, 软件出厂后,厂家使用数据闭环“持续”进行性能改善、体验提升的动力不足,因为经济上投入产出比(ROI)小 。
这里要特别提示一下,技术壁垒并不是人工智能数据闭环的广泛应用的障碍。有两个原因:
- “模型迭代分支”需要的工程师水平,并不一定比传统数据闭环的更高。因为,在传统的数据闭环当中,要解决客户上报的问题,作出正确的分析和判断,并有效的解决,也需要非常资深的工程师,也需要较高的成本。比如,微软或谷歌解决Office、Android问题的工程师同样要求水平高。
- 理论上,神经网络模型的运用,会降低对于工程师经验的要求。也就是说, 如果数据闭环有效运用,“模型迭代分支”的工程师要求,应该大大低于运营传统数据闭环的工程师要求,甚至可能不需要工程师 。
人工智能的数据闭环,完全自动化仍然不可能
第一,任何一个软件系统,都不可能只有神经网络(2.0 code),必须还有逻辑代码(1.0 code),只要有逻辑代码,就需要依赖于传统的数据闭环,就需要人工参与。
人工智能的任务,比如图像的检测分割,都包含数据的前处理、后处理,神经网络只是中间的骨干网络(backbone)。而前处理和后处理都是传统软件的逻辑代码,也是最关键和核心的环节之一,包含很多的技巧,可能需要优化。
无论是智能驾驶还是智能座舱,要形成一个完整的用户体验,还不能只有人工智能的任务,还需要有其他代码,如规划控制、安全兜底逻辑、人机交互应用。这部分现在还没有办法完全通过人工智能任务处理,还是需要有一些的传统的软件代码(逻辑代码)。这一点在特斯拉FSD的公开演讲当中讲得很清楚。随着时间的流逝, 神经网络(2.0 code)的比例会越来越大,但是,目前很大部分代码是传统的代码,下面的图中看的很清楚 。在人类科学取得本质突破前,无法做到完全替代。
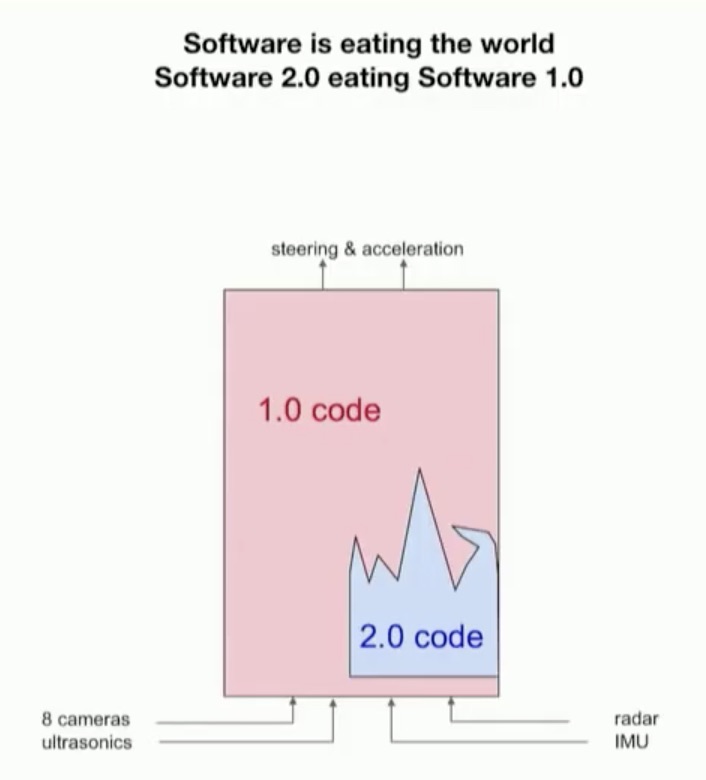
图11 2020年2月特斯拉Full-Self Driving的软件栈中,逻辑代码(1.0 code)仍然占较大比例[4]
所有从客户端上报的问题,首先要依赖于传统数据闭环的工作流程,进行问题的区分,是神经网络的模型问题,还是非神经网络的模型问题。
有的公司,这个步骤叫“分锅”。
这个特点,是人工智能时代的数据闭环没有脱离传统数据闭环的工作方式的根本原因之一。
如果等到有一天,人工智能时代的数据闭环能够能够跳过这一步,那我们可以认为人类的人工智能科学进入到了一个全新的阶段,所有的代码都是2.0 code了。
第二,即使在数据闭环的“模型迭代分支”,数据采集、数据标注的工作,无论怎样提升自动化率,总体规划、冷启动、检查和监督的工作,仍然需要人工参与。
目前,业界也在努力提升数据采集、数据标注的自动化程度,以降低成本。比如通过数据埋点自动收集有价值的数据,通过预训练模型(初步模型)提高标注效率。但是无论怎样,仍然需要人工参与的。

图12 特斯拉数据闭环通过“初步的检测器”收集“长尾数据”仍需要人工参与
第三,虽然“自动化测试”比例不断提升,但是,对于量产软件版本的发布,仍然需要人工参与测试和把关。
第四,数据闭环本身绝大部分是逻辑代码(1.0 code)。
那么,为什么仍然有人坚称,数据闭环不再需要工程师,能完全自动化了呢?因为这是“算法工程师视角”。 算法工程师接触的模型训练、模型测试,完全自动化是可能的 (实际上,只是工作转移到了数据采集、数据标注工程师和测试工程师)。但是,当你把视角放到整个数据闭环,就会发现,完全自动化仍然不可能。
数据闭环并不能解决所有问题
人工智能的数据闭环必不可少,但并不是救命稻草,不能指望数据闭环解决所有问题。
第一,Windows和Office都采用了数据闭环,但是,我们可以看到,Windows的蓝屏崩溃,Office的闪退崩溃,仍然经常出现。
第二,神经网络自身的特性决定了准确率不能做到100%。
所以,我们在自动驾驶等实际产品中遇到的问题,需要通过数据闭环、软件规范、合理的软件和硬件架构、法律法规等,协同和立体的解决。
总结
有人说,对于只工作在神经网络领域的人,通常高估人工智能数据闭环作用,因为对软件工程整体缺乏认知;对于只工作在软件工程领域的人,通常低估人工智能数据闭环作用,因为对于数据和模型的性能之间的关系、数据采集和标注带来的挑战还缺少深刻的体会,所以,导致人工智能时代的数据闭环,要么被低估了,要么被高估了。
这样的观点肯定是以偏概全,但是我们可以引以为戒。
如果你只工作在神经网络算法领域,那么你对数据闭环的期望要降低50%。因为,数据闭环并不会解决所有问题。数据闭环在传统的软件工程领域早已运用了超过20年,人工智能时代的数据闭环仍然没有脱离传统数据闭环的流程,有部分问题仍然需要走传统的数据闭环的流程解决。
如果你以前工作在软件工程领域,那么你对数据闭环的重要性认知要提升10倍。因为在人工智能时代,数据的质量,直接决定了人工智能模型的质量,决定了软件质量。而高质量数据的获取,对管理、运营和工具带来了全新挑战,我们必须认真对待。
参考文献:
- 多出 20 倍?Android 收集的用户数据量远超 iPhone,谷歌官方对测试结果提出质疑 https://zhuanlan.zhihu.com/p/361285373
- 蔚来之后,小鹏汽车辅助驾驶也出事了 https://m.thepaper.cn/baijiahao_14706745
- 辅助驾驶又出事故?小鹏汽车高速公路撞上前方挂车,车主:差点没命 https://page.om.qq.com/page/OMZj0kBYCcc3K3Pt7C-gUKjw0
- 双语字幕 特斯拉AI高级总监 Andrej Karpathy 2020年2月演讲:AI for Full-Self Driving https://www.bilibili.com/video/BV1GA411B7V7
- 用户思维与数据闭环的威力 https://xueqiu.com/5189737826/157401195
- 蔚来ES8开L2撞人又撞车,为啥装24个传感器都躲不开? https://xueqiu.com/5669246763/170896540
- 货拉拉携⼿神策数据,数据赋能企业,实现颠覆式创新 https://www.sensorsdata.cn/blog/20190212/
注:本文仅代表个人观点,与任何组织和单位都无关。