

随着ChatGPT的横空出世,全球掀起了AI大模型热潮,各类“AI+”应用层出不穷。与此同时,以GPU为代表的算力芯片供不应求。
6月14日,中国GPU新厂沐曦MetaX官宣,自研曦云 MXC500 系列 GPU 成功点亮,只用 5 个小时就完成了芯片功能测试。 消息一经发布,迅速引起业界的高度关注与讨论。

6月14日凌晨1点,AMD 举办“AMD 数据中心和人工智能技术首映式 ”展示最新的数据中心和人工智能产品。 其中包括即将推出的Instinct MI300 GPU、配备AI引擎的 Ryzen 7040 系列处理器、以及一系列数据中心SoC/ HPC加速器。

AMD的发布,成功对标英伟达,势必要在算力芯片领域掀起一场“腥风血雨”。 在英伟达GPU把持的AI时代,大家希望AMD的这系列芯片能成为万亿芯片巨头的最强竞争者。

高性能服务器GPU芯片设计新星
沐曦横空出世
沐曦集成电路成立于2020年,公 司创始团队处于国内顶尖行列 —— 创始人陈维良,曾任AMD全球GPGPU设计总负责人, 负责全球通用计算GPU产品线的整体设计与管理,主导并完成15款高性能GPU产品的流片与量产。
杨建,AMD大中华区第一位科学家(Fellow), 参与及主导数十余款GPU产品(55nm至7nm) 量产全流程三维图形与高性能计算生态专家。
彭莉AMD全球首位华人女科学家, 历任AMD首席SOC架构师、系统架构师、GFXIP架构师等职务,主导过多款GPU产品从架构到量产的全流程。
沐曦致力于为异构计算提供全栈GPU芯片及解决方案,可广泛应用于人工智能、智慧城市、数据中心、云计算、自动驾驶、数字孪生、元宇宙等前沿领域,为数字经济发展提供强大的算力支撑。
公司首款人工智能推理GPU曦思®MXN100已进入量产销售阶段。 本次旗舰产品MXC500 就是曦云系列的最新产品,号称是对标英伟达 A100 / A800 的算力芯片,目标 FP32 算力 15 TFLOPS(英伟达 A100 的 FP32 性能为 19.5 TFLOPS),采用通用 GPU 架构,兼容CUDA,预计年底规模出货。

AMDMI300X细节曝光
正面决战英伟达H100
作为AI的基础设施,算力芯片环节的“一家独大”显然不是有利于行业长远发展的生态。因此,市场不免将更多的期待寄托于GPU“二号玩家”AMD身上。
同时作为英伟达的老对手,AMD亦想重现当年的逆风翻盘,在福布斯的最新采访中,苏妈毫不掩饰地表达了想要摘取“英伟达AI王冠”的野心。

此次发布会,其中最重磅的新品当属ADM最先进GPU Instinct MI300,主要包括MI300A、MI300X两个版本,以及集合了8个MI300X的Instinct Platform。
针对于MI300A,是全球首款数据中心APU。拥有13个小芯片,总共包含1460亿个晶体管,24个Zen 4 CPU核心,1个CDNA 3图形引擎和128GB HBM3内存。现在MI300A已经用于超级计算机,并将在劳伦斯利弗莫尔国家实验室的EL CAPITAN系统中使用。

MI300X则是AMD针对大语言模型优化的版本,该产品基于最新一代AMD CDNA3架构,支持最多192GB HBM3内存,可以提供大型语言模型推理和生成式AI工作负载所需的计算和内存效率。借助MI300X的大内存,用户可以在一颗MI300X GPU上装载如Falcon-40B这样拥有多达400亿条参数的大型语言模型。

AMD还发布了Instinct平台,该平台由8块MI300X加速器组成,是一个工业标准设计,主要执行生成式AI的推理与训练工作。MI300X将在今年第三季度为关键客户提供样品。

与英伟达H100相比,MI300X将三个 Zen 4 芯片替换为三个 CDNA 3 芯片,并增加了 64GB 的 HBM3,总容量为 192GB。
MI300X由 12 个不同的小芯片组成,其中包括八个 GPU 和几个 I/O 芯片,总共有令人惊讶的 1530 亿个晶体管。
MI300X 的一个模块具有处理 LLM 的“Falcon-40B”400 亿参数的能力。提供了 192GB 的 HBM3、5.2TB/s 的带宽和 896GB/s 的 Infinity Fabric 带宽。
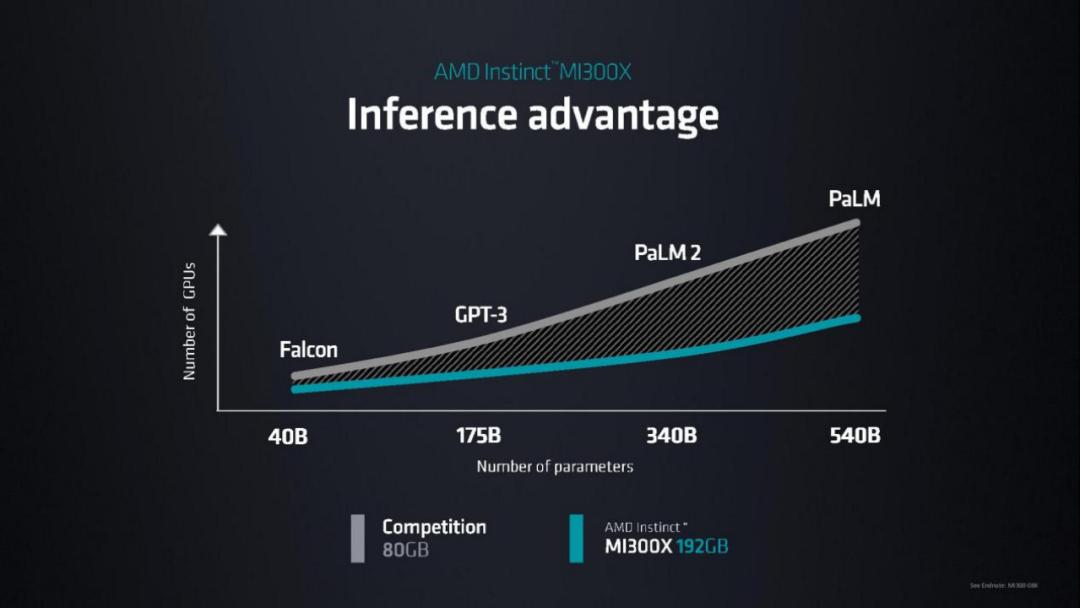
MI300X 提供的 HBM 密度是 Nvidia H100 的 2.4 倍,HBM 带宽是 H100 的 1.6 倍,这意味着 AMD 可以运行比 Nvidia 芯片更大的模型。

Lisa Su在MI300X上演示了一个Hugging Face的AI模型,让大模型写一首关于San Francisco的诗。这是第一次在单颗GPU上运行这么大的模型,如果仅为FP16,单颗MI300X可以运行高达800亿参数的模型。这意味着使用MI300X可以更好地降低总成本。


计算:GPU为算力核心
服务器为重要载体
ChatGTP作为大语言模型,它的发布类似于Windows的诞生,将会起到信息系统入口的作用,同时,ChatGPT或将重塑目前的软件生态。
2022年,Windows在全球PC操作系统市占率约75%,应用数量3000万以上,是世界上生态规模最庞大的商业操作系统。围绕Windows所创造的桌面软件生态,诞生了现有的全球互联网巨头,亚马逊、谷歌、META、阿里巴巴、腾讯、百度等。
计算是AI算力的核心引擎,存储、网络、软件是AI算力的主要发展方向。
GPU是目前最广泛应用的Al芯片。Al芯片主要包括图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、神经拟态芯片(NPU)等。GPU属于通用型芯片,ASIC属于专用型芯片,而FPGA则是介于两者之间的半定制化芯片。2022年,我国GPU服务器占Al服务器的89%。
1)计算:GPU是ChatGPT训练和推理的核心支柱,AI服务器作为GPU的重要载体,预计其市场规模、渗透率将随着GPU放量迎来同步高增。
2)网络:已成为限制AI算力提升的主要瓶颈,英伟达推出InfiniBand架构下的NVLink、NVSwtich等方案,将GPU之间的通信能力上升到新高度。而800G、1.6T高端光模块作为AI训练的上游核心器件,将受益于大模型训练需求的增长。
3)存储:“内存墙”是制约算力提升的重要因素。NAND、DRAM等核心存储器在制程方面临近极限,不断探索“3D”等多维解决方案。HBM基于其高宽带特性,成为了高性能GPU的核心组件,市场前景广阔。

国产GPU厂家汇总
近年来,国产GPU频频传出好消息。在市场和政策的推动下,曾经蒙尘的国产GPU开始闪烁自己的光芒。
现如今,我国算力产业年增长率近30%,算力总规模位居全球第二,截至去年底,我国算力总规模达到180EFLOPS,存力总规模超过1000EB,国家枢纽节点间的网络单向时延降低到20毫秒以内,算力核心产业规模达到1.8万亿元。
目前已经聚集了约20家GPU领域的厂商,其中许多已经将其GPU 芯片投入量产。伴随着国内GPU赛道上一个又一个交出新产品,国产GPU正迅速走过“从无到有”,进入下一个“迭代时刻”。


总的来说,芯片不断的算力提升,还是依赖于整个摩尔定律的提高。因为每代芯片都会更换台积电最新一代的工艺,那么越到后面就应考虑是否会有一些更先进的封装,比如像Chiplet,或者像异质集成,或者像光电一体的计算,或者再往后更加远的一些新的计算。
目前,相比于前些年火热的AI芯片,GPU无疑在技术上有更高的门槛,虽然获得了庞大的资金涌入,但跟英伟达等国际芯片巨头还有一些差距。
另外,GPU芯片从最初设计到制造、流片、量产,周期通常不会低于18-24个月,需要经年累月的迭代和优化。同时还需要看下游的应用,来判断是不是一个很大的国产替代的机会,包括是不是一个很大的增量空间。GPU毫无疑问属于这样一个范畴,整个市场空间非常大,可能是个千亿人民币以上的市场。国产替代空间值得期待。