读数据压缩入门笔记05_字典转换
🏷️ 躺着的柒
✍️ 书读薄读厚1. 输出才能检验输入;2. 分享才能集思广益;3. 完成才能完善,无限完善才能逼近完美;4. 万事开头难,坚持更难,长期坚持难上加难。
📅 2026-03-18T00:52:17+00:00
1. 瓶颈
1.1. 在网络带宽有限、存储昂贵的时期
1.2. 移动设备正日益成为人们访问互联网的首选的今天
1.3. 数据压缩成了缓解这些瓶颈的关键
2. 字典转换
2.1. dictionary transforms
2.2. 完全改变了人们对数据压缩的认知
2.2.1. 压缩变成了一种对各种类型的数据都有用的算法
2.3. 事实上今天所有的主流压缩算法(比如GZIP或者7-Zip)都会在核心转换步骤中使用字典转换
3. 基本字典转换
3.1. 统计压缩主要关注数据流中单个符号的出现概率
3.2. 这一概率与其周围可能出现的符号无关
3.3. 符号字典
3.4. 任何出现可以重复使用的相似内容分组的地方,都会有“短语”存在
3.5. 步骤
3.5.1. 给定源数据流
3.5.2. 构建出单词字典(而不是符号字典)
3.5.3. 再将统计压缩应用到字典中的单词上
3.6. 字典转换并非是要去替代统计编码
3.6.1. 只是你先应用到数据流上的一个转换,这样统计编码算法就能更有效地对其编码
3.7. 实际是一个数据流的预处理阶段
3.7.1. 生成的数据*会集**更小,比源数据流压缩率更高
3.8. 当能识别出那些经常重复使用的长字符串,并为它们分配最短的码字时,字典转换的效率最高
4. 分词
4.1. tokenization
4.2. 是信息论领域的一个研究分支
4.3. 一种*力暴**方法是读取一组符号并搜索字符串的剩余部分来确定该组符号的出现频次
4.3.1. 对所有真实的数据流而言,这样做不仅需要大量的内存,同时还需要花费很长的时间
4.4. 为了找到数据流的理想分词,我们需要有某种方法来处理现有的和那些还没有遇到的符号,并能以一种高效的方式将两者合并为尽可能长的符号集
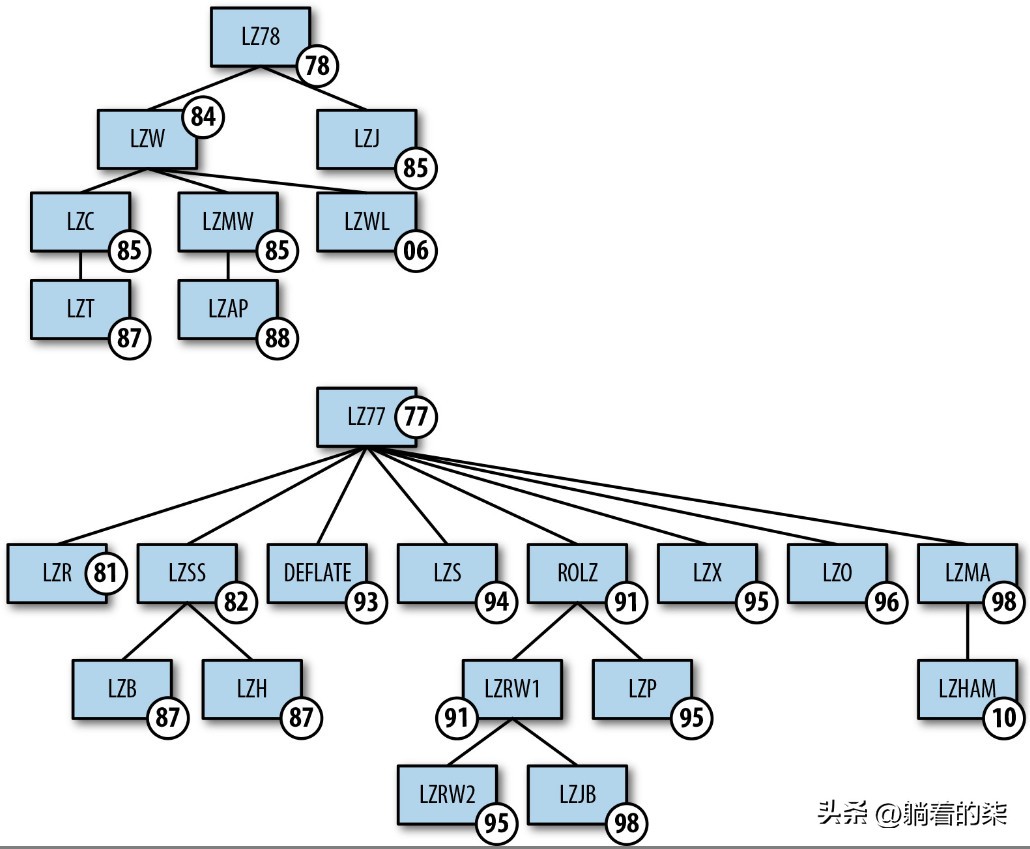
5. LZ算法
5.1. 1977年,Abraham Lempel和Jacob Ziv提出
5.1.1. Jacob Ziv大学毕业于以色列理工学院,随后于1961年获得了麻省理工学院信息论专业的博士学位
5.1.2. Abraham Lempel在以色列理工学院获得了学士、硕士和博士学位
5.1.3. 1997年获得了IEEE信息理论学会的香农奖
5.2. LZ77 和LZ78
5.2.1. 找出最佳分词方面非常高效,30多年来还没有其他算法可以取代它们
5.3. 衍生算法
5.3.1. 每一种变体都是根据特殊的需要、性能要求的不同或者用例的不同,对LZ77基本算法进行了一些小调整
5.3.1.1. 对数据集越了解,你就越能从中选择出最适合的LZ变换
5.3.2. GIF图像格式中使用的LZW(即Lempel-Ziv-Welch)算法
5.3.2.1. Terry Welch于1984年提出的,它采用了LZ78算法的思想
5.3.2.2. 首个在计算机中广泛采用的通用数据压缩方法
5.3.3. 应用于7-Zip、xz等压缩工具的LZM(即Lempel-Ziv-Markov chain)算法
5.3.4. DEFLATE又应用于PNG图像格式、PKZIP、GZIP等压缩工具及zlib库中
5.3.5. PKZip、ARJ、RAR、ZOO和LHarc使用LZSS算法
5.3.6. 图
5.4. 真正吸引人的地方还在于它可以和统计编码结合使用
5.4.1. 将记号中的偏移量、长度值以及字面值分开后,再按照类型合并,组成单独的偏移量集、长度值集和字面值集,然后再对这些数据集进行统计压缩
6. LZ算法的工作原理
6.1. 通过在读取的字符串中寻找当前单词的匹配来分词
6.2. 与读取一组符号然后向后查找它是否重复出现不同
6.2.1. LZ算法向前查找当前单词是否出现过
6.3. 在数据流的前半部分,由于我们见过的单词很少,因此出现新单词的可能性很大
6.4. 数据流的后半部分,由于已经有了很大的缓冲区,因此出现匹配的可能性更大
6.5. 向前寻找匹配可以让我们找出“最长的匹配词”