#挑战30天在头条写日记#
前言
本文讲一下Stable Diffusion的Automatic1111的图生图(img2img,简称i2i)功能。
在图生图的页面上,大部分的功能跟文生图的功能一样,请直接查阅 AI绘图|Stable Diffusion基础篇—— 文生图(txt2img) ,这边就不复述了。这边来讨论不一样的功能:
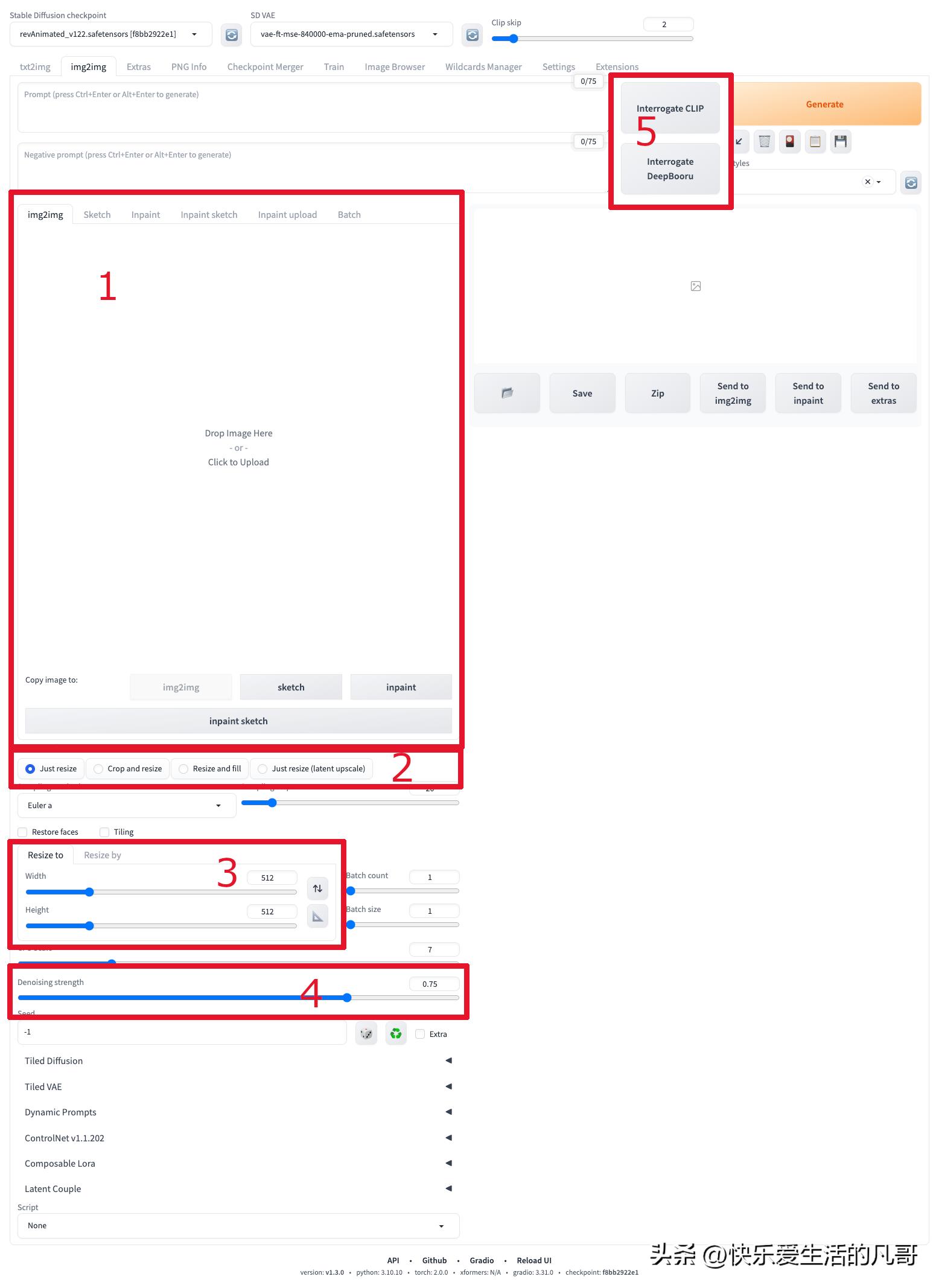
img2img的页面与功能分区
这边最重要的功能是1(图片放置区)跟4(Denoising strength)。我们之后会常常用到。
功能分区
- 图片放置区: 这个区域我们有三个重要的次要区域在这边, 第一个是分页标签, 里面有图生图(img2img),涂鸦(sketch),局部修改(inpaint)等等,我们这边主要聚焦于图生图这功能。 第二区是图片放置区, 在这里我们可以用拖拽或者点击打开文件选择器,把自己要修改的图放入。 第三区是拷贝图片到其他区域, 在这边我们可以把同一张图自由切换到不同功能去,例如你用img2img载入图片,突然发现其实你要的只是局部修改某个区域,就可以直接按Copy image to Inpaint把图直接送进inpaint分页来修改。
- 尺寸变动选项: 当你的输出尺寸设定与原先图片尺寸不一致时,Automatic1111就会依照这边选取的选项来调整画面: Just resize: 无视比例,直接把图片缩放成目标尺寸(原图内容无损失,但比例可能扭曲)。 Crop and resize: 依照目标尺寸的比例,先把多余的内容都去除掉再缩放到目标尺寸(会损失原图的内容)。 Resize and fill: 依照目标尺寸的比例,在不足的地方填充杂讯,然后缩放到目标尺寸,接下来靠img2img来把杂讯转换成有意义的内容(会增加原图的内容)。 Just resize (latent upscale): 与第一个功能Just resize相同,但是Just resize是直接缩放,而这个选项是使用AI放大演算法来缩放图片,所以需时较久,但是在放大后可能产生比较多的细节(原图内容无损失,但比例可能扭曲)。
- 输出尺寸设定: 我们可以在img2img的时候指定成品图的新尺寸,有两种方法: Resize to: 直接指定成品图的长与宽。 Resize by: 指定成品图的放大或缩小倍率,预设是1,也就是不变动。
- 去躁力度(Denosing strength): 输出图片的变动程度。在img2img的第一步,Stable Diffusion会将噪讯加进输入图片中,然后依照提示词的内容来产生图片。数值越大的话,第一步加入的噪讯就会越多,输出图片会差异越大。例如0.1到0.2时,只会在细微的图样,阴影产生变化。到了0.4以上,就会对画面中的小物品产生明显变化,到了0.6以上会对整张图的组成产生很明显的影响,例如人物姿势与位置,甚至整个构图都会不一样。到了1就会产生一个跟输入图毫无关联的图,其实就等于纯粹的文生图。除此之外,AI跑新图的时间也与去噪力度有关,数值越大就会跑越久。当你设定要跑100步,但是去噪力度为0.1时,它实际上只跑了100*0.1=10步。
- 提示词提取按钮: 让使用者可以从输入图提取可能的提示词。Automatic1111提供了两种不同的演算法来提取提示词。 Interrogate CLIP: 使用OpenAI开发的CLIP演算法来提取提示词。使用这个方法提取的提示词使用的是自然英语的语法。由于大部分的网路图片都是自然英文,而Stable Diffusion使用的是网上图片以及其叙述来训练基本模型,所以理论上使用这个方法得到的提示词在生成真实世界照片时效果较佳。 Interrogate DeepBooru: 针对2D动画的模型,例如Waifu-Diffusion或NovalAI都是从DanBooru这个网站抓图下来训练,而这个网站使用的分类标签系统,就成了DeepBooru这个演算法的基本资料。使用这个方法会提取出以标签为主的提示词,以逗号分隔。常用的提示词如1girl,long hair都是这个提示词演算法引入的。也因此只有在动漫画相关的模型里面,这样的提示词才有明显作用。如果是纯粹的Stable Diffusion基本模型,应该没有自然英文语法来得好用。
下面是一个原版图片,依照不同的提示词与0.65的Denoising strength来重绘的比较图:
