2022年11月,OpenAI推出ChatGPT聊天机器人,以对话的形式与用户进行连续性的交互,上线2个月后用户数超过1亿,用户数量增长迅猛。ChatGPT 属于 AIGC 的具体应用,相比过去的 AI 产品,在模型类型、应用领域、商业化等层面也呈现出新的特点。
发源于OpenAI,成名于生成式语言
OpenAI 是一家世界领先的非营利性人工智能研究公司。OpenAI 于 2015 年在旧金山成立,是一家非营利的人工智能研究公司,公司的目标是以最有可能造福全人类的方式推进人工智能,而不受财务回报需求的约束。OpenAI 创始人背景深厚,由埃隆·马斯克与硅谷孵化器 Y Combinator 投资人山姆·阿尔特曼等人联合创立。公司研究人员经验丰富,包括前Google Brain 研究科学家伊利亚·苏茨凯弗与前 Stripe 首席技术官格雷格·布罗克曼等世界一流研究工程师与科学家。
2018 年,随着特斯拉对 AI 的应用深入,为避免潜在利益冲突,马斯克主动离任董事会,仅保留捐资人和顾问的身份。由于 AI 训练花费金额巨大,2019 年公司从非营利性公司转向部分盈利公司,成立了 OpenAI LP 利润上限子公司,即任何对 OpenAI LP 投资的收益都将统一转移至一家非盈利公司,回报达到投资的 100 倍后进行利润分配。
同年,OpenAI 收到微软注资 10 亿美元,就 Azure 业务开发人工智能技术。2020 年发布 GPT-3 语言模型,由微软获得独家授权。2022 年发布 ChatGPT 的自然语言生成式模型,带来更大潜在应用空间。2023 年,微软拟对 OpenAI 追加数十亿美元投资,利用自身算力基础设施资源发挥与 OpenAI 业务协同效应,深入布局生成式 AI 技术。
2016 年,推出用于开发和比较强化学习算法的工具包 OpenAI Gym,加速公开社会中 RL 研究进度。同时推出 Universe 软件平台,用于测试和训练 AI 在全球游戏、网站和其他应用程序中的智能程度。2019 年,OpenAI 推出深度神经网络 MuseNet,可以使用 4 种不同的乐器生成 10分钟的音乐作品以及最终模型版本的 GPT-2。2020 年,研发团队在 GPT-2 的基础上拓展参数,发布了 GPT-3 语言模型。2021 年,发布了转换器语言模型 DALL·E,从文本描述生成图像。2022 年,OpenAI 在 GPT-3.5 的基础上推出了 ChatGPT,强化了人工智能的语言对话能力,引起社会广泛关注。

ChatGPT(图片来自网络)
OpenAI 产品
OpenAI 当前盈利主要通过付费 API 接口,并尝试拓展盈利模式。目前,OpenAI 提供 GPT-3、Codex 以及 DALL·E 的 API 数据接口,分别执行用户自然语言任务、自然语言转换为代码的任务以及创建和编辑图像的任务。API 接口根据类型不同以流量收费,比如图像模型以分辨率分类按张数收费,语言模型则以基于的子模型型号按字符数收费。OpenAI API 盈利情况较好,据路透社数据,OpenAI 2022 年收入数千万美元,公司预计 2023 与 2024 年收入分别为 2 亿美元和 10 亿美元。同时,OpenAI 正尝试拓展自身盈利模式,2023 年 1 月试点推出订阅制 ChatGPT Plus,收取每月 20 美元的会员费以得到各类优先服务。

ChatGPT(图片来自网络)
OpenAI API 价格
ChatGPT 使用来自人类反馈的强化学习 (RLHF) 来训练该模型。首先使用监督微调训练了一个初始模型:人类 AI 训练员提供对话,他们在对话中扮演双方——用户和 AI 助手。其次,ChatGPT 让标记者可以访问模型编写的建议,以帮助他们撰写回复。最后,ChatGPT 将这个新的对话数据集与原有数据集混合,将其转换为对话格式。具体来看,主要包括三个步骤:
1)第一阶段:训练监督策略模型。在 ChatGPT 模型的训练过程中,需要标记者的参与监督过程。首先,ChatGPT 会从问题数据集中随机抽取若干问题并向模型解释强化学习机制,其次标记者通过给予特定奖励或惩罚引导 AI 行为,最后通过监督学习将这一条数据用于微调 GPT3.5 模型。
2)第二阶段:训练奖励模型。这一阶段的主要目标,在于借助标记者的人工标注,训练出合意的奖励模型,为监督策略建立评价标准。训练奖励模型的过程同样可以分为三步:1、抽样出一个问题及其对应的几个模型输出结果;2、标记员将这几个结果按质量排序;3、将排序后的这套数据结果用于训练奖励模型。
3)第三阶段:采用近端策略优化进行强化学习。近端策略优化(Proximal Policy Optimization)是一种强化学习算法,核心思路在于将 Policy Gradient 中 On-policy 的训练过程转化为Off-policy,即将在线学习转化为离线学习。具体来说,也就是先通过监督学习策略生成 PPO模型,经过奖励机制反馈最优结果后,再将结果用于优化和迭代原有的 PPO 模型参数。往复多次第二阶段和第三阶段,从而得到参数质量越来越高的 ChatGPT 模型。

ChatGPT(图片来自网络)
ChatGPT 模型原理
从 ChatGPT 的训练原理中,我们不难发现,这一训练过程存在几个特点:
1)采用的是单一大模型。在 GPT 模型兴起之前,大多数 AI 模型主要是针对特定应用场景需求进行训练的小模型,存在通用性差、训练数据少、适应范围小的弊端。而我们看到,ChatGPT 虽然在过程中使用了奖励模型等辅助手段,但最终用于实现自然语言理解和生成式功能的主模型只有一个,但却在语义理解、推理、协作等方面表现出了更强能力。因此,ChatGPT 的成功,验证了参数增长、训练数据量增大,对 AI 模型的重要意义。
2)采用的是小样本学习方法。在小样本学习(Few-shot Learning)方法下,AI 预训练模型在不必使用大量标记的训练数据,就可以建立起比较通用的泛化能力。简单来说,小样本学习即是在给定有限信息和较少训练数据的情况下,尝试对总体规律进行理解和预测,这一过程类似于“学习如何去学习”。对于小样本学习在 ChatGPT 中的应用,我们认为,这一方法解决了大模型数据标注工作量巨大的问题,是模型得以迅速迭代的基础。
3)采用人类反馈微调监督学习。ChatGPT 是从 GPT3.5(即 InstructGPT)改进而来的版本,相比于前代,ChatGPT 主要变化在于采用了人类反馈机制,对监督学习过程进行微调。本质上来说,无论是大模型还是小样本学习,解决的目标都是提升训练的效率,但真正令ChatGPT 实现结果准确、合理的关键技术,还是在于加入了人类反馈。据 Long Ouyang等人 2022 年发表的《Training language models to follow instructions with humanfeedback》,InstructGPT 仅用 13 亿个参数就实现了比 1750 亿个参数的 GPT-3 更优的输出解雇,显著提升了真实性、减少了有害信息的输出。
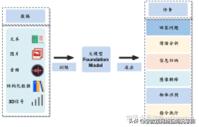
ChatGPT(图片来自网络)
参考资料:
[1] https://zhuanlan.zhihu.com/p/615331483
[2] https://baijiahao.baidu.com/s?id=1752806597140118817&wfr=spider&for=pc
[3] https://blog.csdn.net/duck251/article/details/130001652