想必大家都知道python有个好玩的东西叫做爬虫,会玩的人能在网上爬取想要的任何资源的,今天小编也简单的带大家来玩一玩爬虫。
这次我们使用Requests这个库
# -*- coding:utf-8 -*-
import time
import requests
from bs4 import BeautifulSoup
然后网址,请求头
url = 'http://www.win4000.com/hj/2018cxyx.html'
headers = { #请求头
'User-Agent':
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4208.400",
"Connection":"close"}
img = [] #用于存储图片地址的列表
请求头可以直接抄浏览器的:F12->Network->F5->Headers

获取网页源代码的函数...打印req.text显示的和浏览器里右键查看源代码一样,打印req.concent是一堆二进制字符
http状态码:2成功 3重定向 4错误 5、6服务器宕机
def get_url(url):#获取网页源代码
req = requests.get(url, headers=headers,verify=False)
#verify=False:关闭SSL验证
req.raise_for_status()
#判断返回的response类型的状态是不是200
#如果不是,则会产生一个requests.HTTPError异常
req.encoding = 'utf-8'
return req.content
#.text 返回的是unicode 型的数据,一般是在网页的header中定义的编码形式
#.content返回的是bytes,二级制型的数据
#也就是说如果想要提取文本就用text
#但是如果想要提取图片、文件,就要用到content
获取图片地址的函数,data-original里的是真实地址
def get_html(html):#查找所有图片的地址并加入列表
soup = BeautifulSoup(html, 'html.parser')
html_ = soup.find_all('img')#顾名思义应该是查找所有img标签
for item in html_:
attrs = item.attrs #这是什么玩意还没研究明白
for attr in attrs:
if attr == 'data-original':
#不知道原理,反正这样就把'data-original='后边的链接提取出来了
img.append(str(item[attr]))
*载下**、保存图片文件的函数
a="https:"#有些网站里的图片地址提取出来没有http头
root = r'D:\pic\\' #保存路径
def get_png(list):
num = 1
for item in list: # 循环将图片*载下**
item_ = get_url(item) #没http头的换成a+item
print('*载下**第' + str(num) + '张图片')
num = num + 1
with open(root+str(num-1) + '.jpg', 'wb') as f:
f.write(item_)
time.sleep(1)
运行:
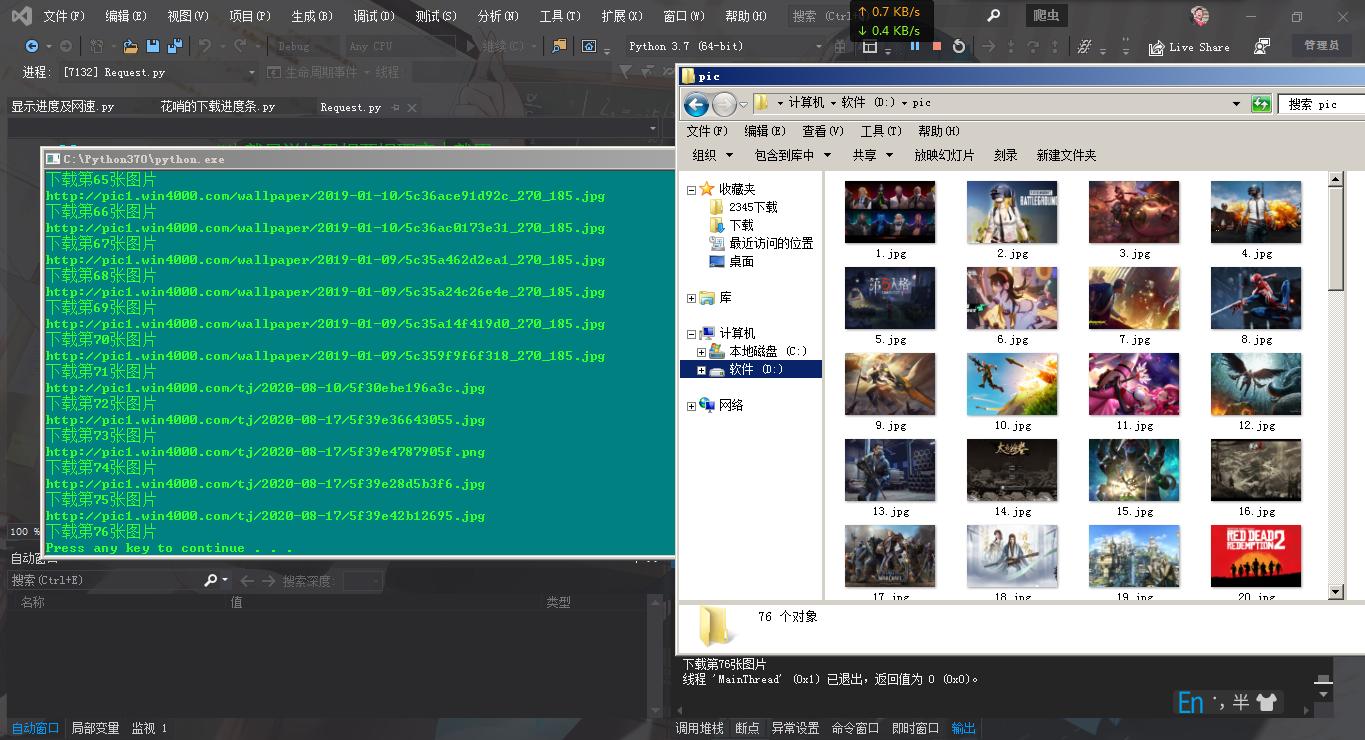
结尾
最后多说一句,小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以关注小编,并在后台私信小编:“01”即可领取。