- 列式存储数据库,更适合分析类报表查询,查询某些列,减小磁盘I/O
- 列式存储方便数据压缩,更容易载入内存处理
- 列式存储方便使用向量引擎执行SIMD(Single Instruction Multiple Data,单指令多数据流)操作,提高CPU处理效率
- 支持多种表引擎,应用广泛的是MergeTree以及在此基础上衍生的MergeTree引擎
本文重点讲解MergeTree引擎,当采用以下建表语句时,就代表该表使用了mergetree引擎:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
数据分片:
当我们往这个表中批量添加数据时,就会生成数据分片(DATA PART),这个数据分片在文件系统中是以文件目录形式存在的,DATA PART文件目录命名规则如下:
PartitionID_MinBlockNum_MaxBlockNum_Level,例如 202010_1_1_0
PartitionID: 分区 ID
MinBlockNum: 最小数据块编号,表内全局累加,从 1 开始
MaxBlockNum: 最大数据块编号,表内全局累加,从 1 开始
Level: 分区合并次数,从 0 开始
系统后台在默认 10-15 分钟后自动合并分区相同的多个part,也可以手动执行 optimize 语句,合并成功后,旧分区目录被置为非激活状态,在默认 8 分钟后被后台删除
合并后新目录的命名规则:
MinBlockNum: 所有合并目录中的最小 MinBlockNum
MaxBlockNum: 所有合并目录中的最大 MaxBlockNum
Level: 所有合并目录中的最大 Level 值并加 1
举例:
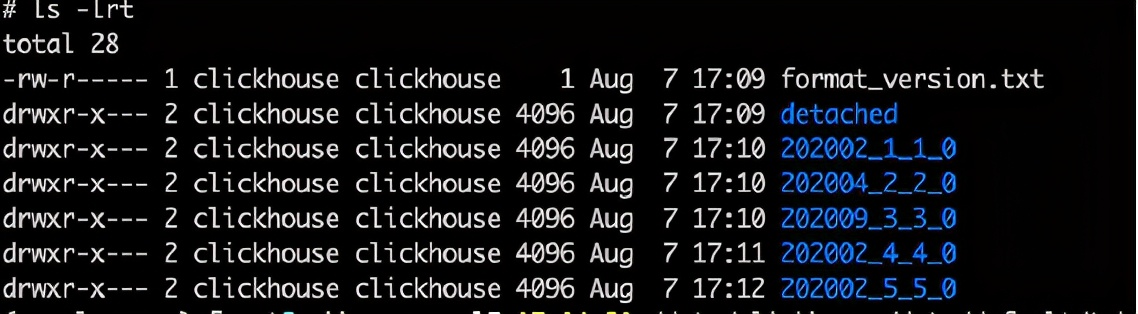
上图中的202002_1_1_0 202002_4_4_0 202002_5_5_0 合并之后生成了 202002_1_5_1
数据分片的目录格式:
├─ partition_{index} DIR #数据分片目录
│ ├─ checksums.txt BIN #各类文件的尺寸以及尺寸的散列
│ ├─ columns.txt TXT #列信息
│ ├─ count.txt TXT #当前分区目录下数据总行数
│ ├─ primary.idx BIN #稀疏索引文件
│ ├─ {column}.bin BIN #经压缩的列数据文件,以字段名命名
│ ├─ {column}.mrk BIN #列字段标记文件
│ ├─ {column}.mrk2 BIN #使用自适应索引间隔的标记文件
│ ├─ partition.dat BIN #当前分区表达式最终值
│ ├─ minmax_{column}.idx BIN #当前分区字段对应原始数据的最值
│ ├─ skp_idx_{column}.idx BIN #跳数索引文件
│ └─ skp_idx_{column}.mrk BIN #跳数索引表及文件
接下来介绍这个目录中文件以及文件的查找和写入
分区索引文件:
partition.dat BIN #当前分区表达式最终值
minmax_{column}.idx BIN #当前分区字段对应原始数据的最值
例如如果以月份为分区
partition.dat 中的内容为 202012
minmax_{column}.idx 为 20201201 20201214
在包含分区查询条件时,分区索引会过滤掉不相关的数据分区data part
一级索引文件:
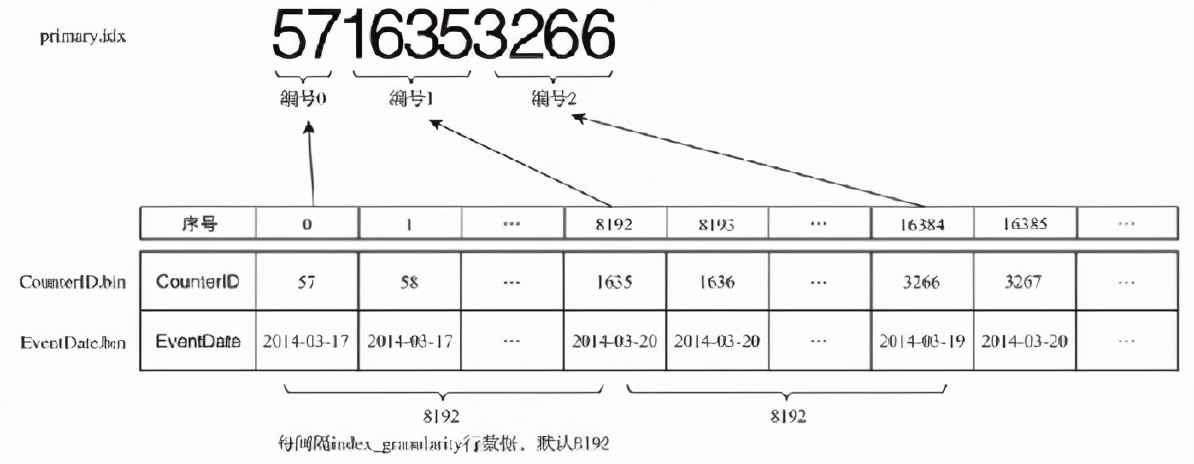
primary.idx 稀疏索引文件
一级索引是稀疏索引,间隔 index_granularity (默认 8192) 行数据生成一条索引记录,常驻内存,primary.idx中保存了每一个有序间隔区间的第一个值。稀疏索引可以减小索引数量,因此可以常驻内存,提高数据查找的效率。
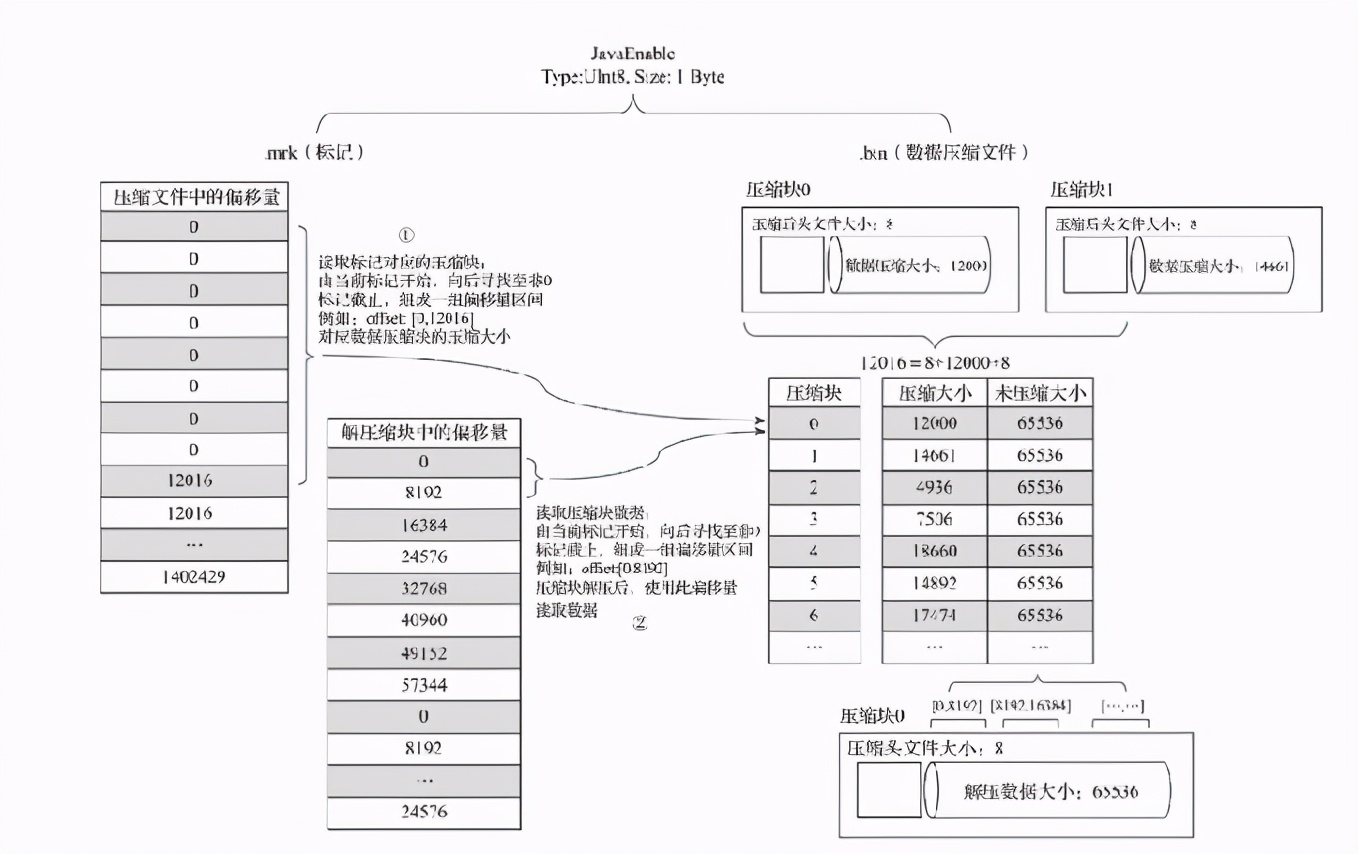
bin文件,即数据压缩块:
.bin文件每一列有一个相应的bin文件,存储该列的数据,数据回以orderby的顺序,以压缩块(默认LZ4压缩)形式写入 .bin 文件。
数据写入规则如下:
会按照索引粒度间隔默认8192,每次取8192行数据
单批次数据 < 64KB,继续获取下一批数据
64KB <= 单批次数据 <= 1MB,直接生成压缩数据块写入 .bin 文件
单批次数据 > 1MB,按照 1MB 大小截断并生成数据块写入 .bin 文件,剩余数据继续按前面规则执行数据
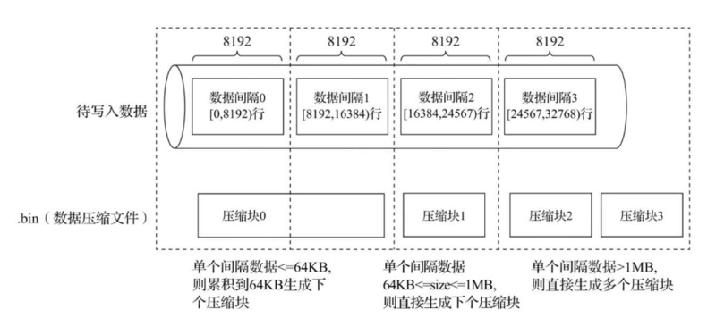
那每一个压缩数据块的结构如下:
一个数据压缩块是由头部和数据部分组成,其中头部占9个字节,一个字节表示压缩类型,另外有两个四字节整数表示压缩前后的数据大小。
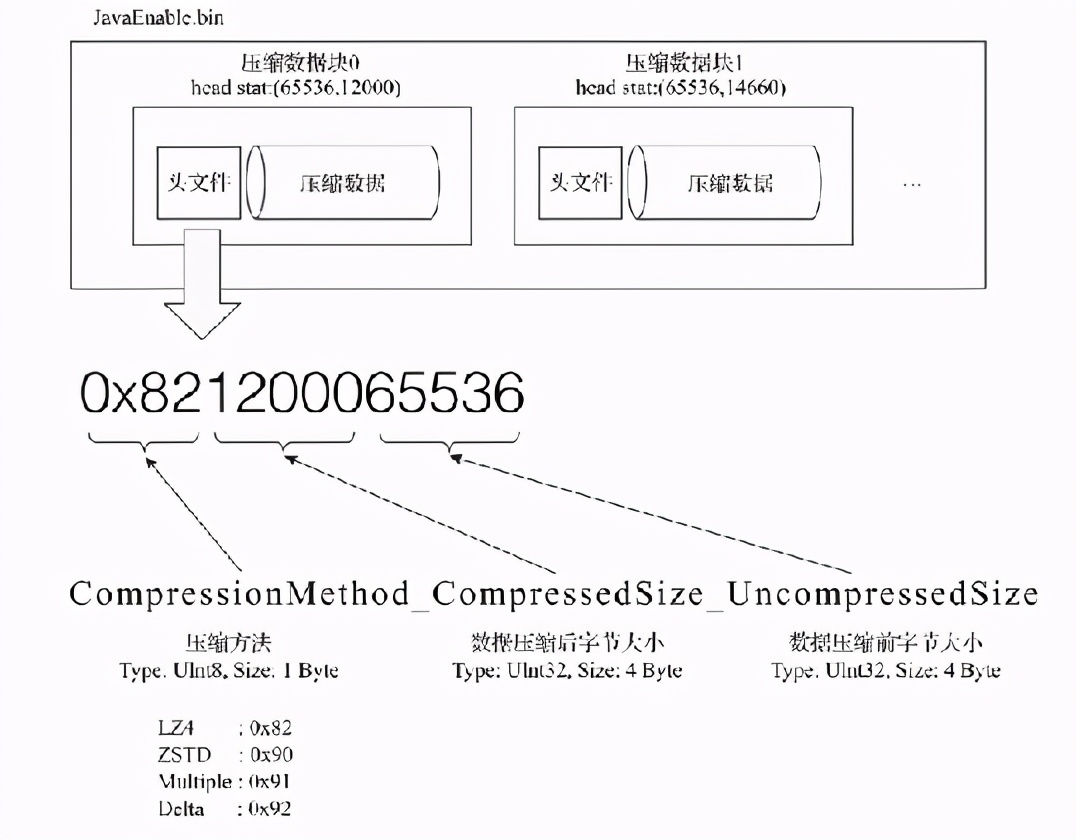
mrk文件,数据标记文件:
数据标记文件是索引文件和数据文件的桥梁,通过这个桥梁可以定位到数据所在的区间,数据标记和索引区间的编号是对齐的。
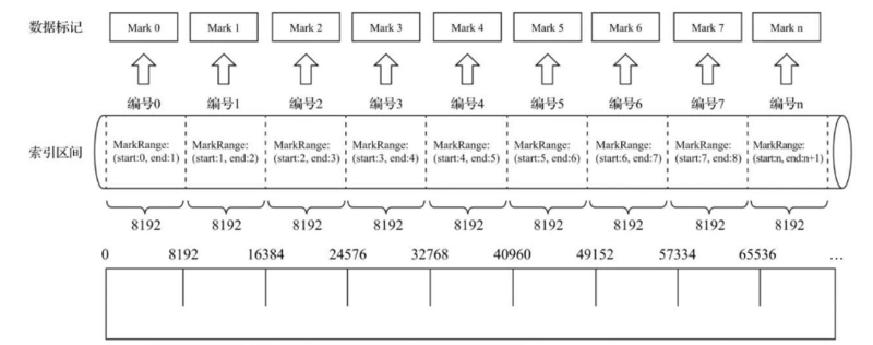
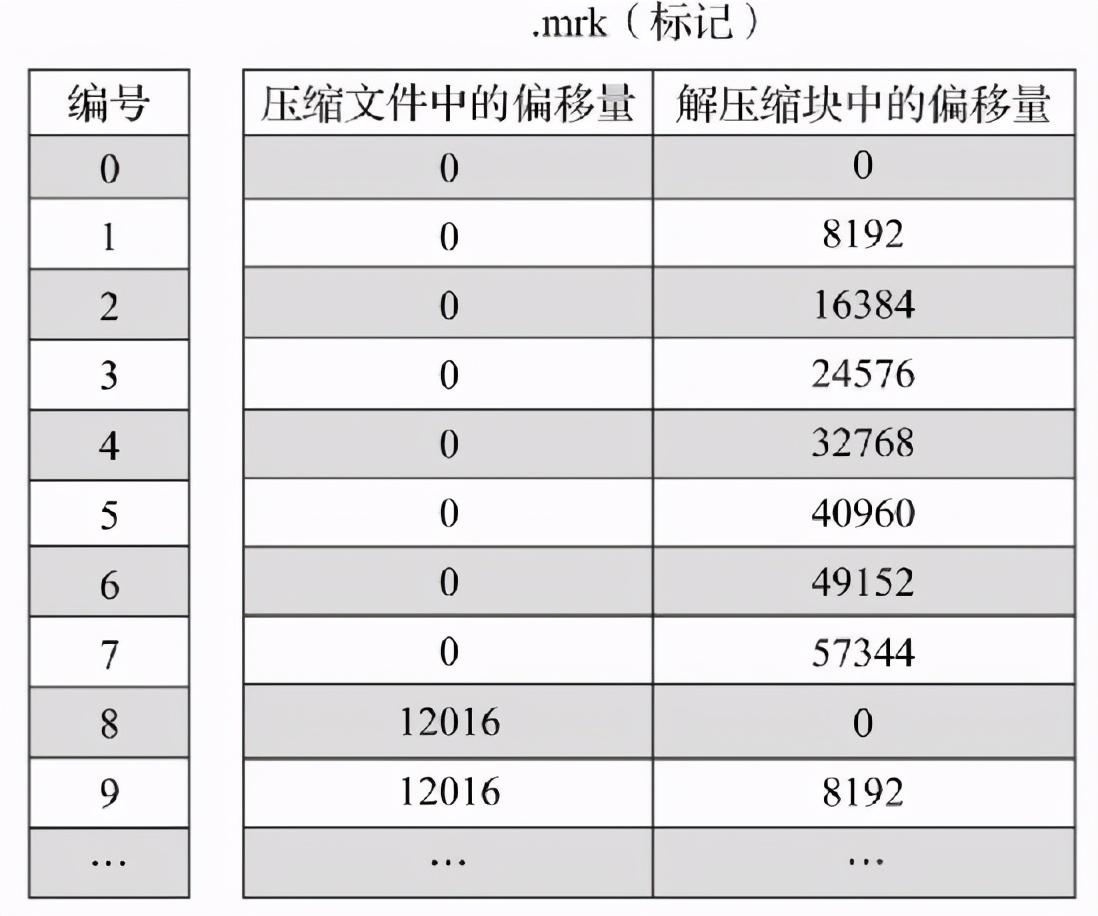
同时数据标记文件还要和数据bin文件建立关联,rmk文件中的格式如下,该文件无法常驻内存,采用LRU缓存策略。
上述目录结构介绍完了,那如何利用mergeTree的这些结构来实现数据查找呢?
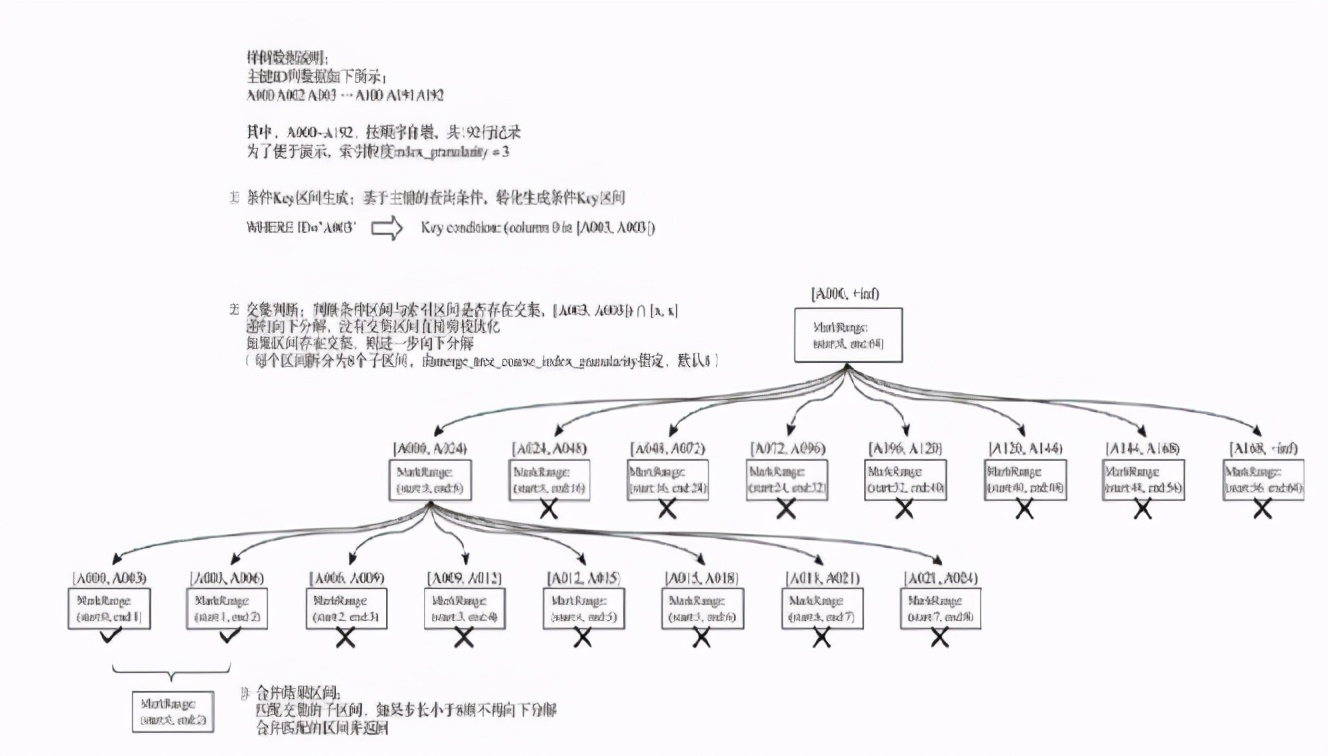
首先将查询条件转化成区间条件展开查询,例如:

首先查找一级索引文件primary.idx,将查询条件转化为区间查询,采用递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。
如果存在交集,且MarkRange步长大于8(end - start),则将此区间进一步拆分成8个子区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断。
如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
这样就获取到了查询数据所在的编号列表。
然后根据编号查找mrk文件,找到对应的压缩数据块偏移量,然后根据偏移量查找bin文件,把在该偏移量范围内的压缩数据块加载到内存解压查找。