一、函数简介
1.1 作用
函数的主要作用就是将逻辑上可看作一个整体的多条语句进行封装,从而提高内聚性及代码的复用。其实,Python的函数就相当于Java中的方法。
1.2 使用步骤
函数定义和调用的语法如下:
# 函数的定义
def 函数名(参数):
代码1
代码2
...
# 函数的调用
函数名(参数)
需要说明的是,函数可没有参数,此时即所谓的无参函数。此外,函数必须先定义后使用。
下面以计算两个数的和为例进行演示:
# 声明函数
def add_num(a, b):
return a + b
# 进行调用
print(f"3 + 4的和为:{add_num(3, 4)}")
执行结果如下:

1.3 函数的说明文档
1.3.1 声明
函数的说明文档就是对该函数用途的描述。函数文档的语法格式如下:
def 函数名(参数)
"""说明文档"""
代码
....
下面给出对应的示例:
# 声明函数
def add_num(a, b):
"""
用于计算两个数的和
:param a: a
:param b: b
:return: 两数之和
"""
return a + b
1.3.2 查看
函数的描述文档通过help函数进行查看,其语法格式为:
help(函数名)
下面为对应的示例:
# 声明函数
def add_num(a, b):
"""
用于计算两个数的和
:param a: a
:param b: b
:return: 两数之和
"""
return a + b
help(add_num)
执行结果如下:

1.4 函数嵌套
所谓函数嵌套是指一个函数在执行过程中调用了其他的函数。其语法格式为:
def 函数A(参数):
代码
...
def 函数B(参数):
函数A(参数)
代码
...
下面给出对应的示例:
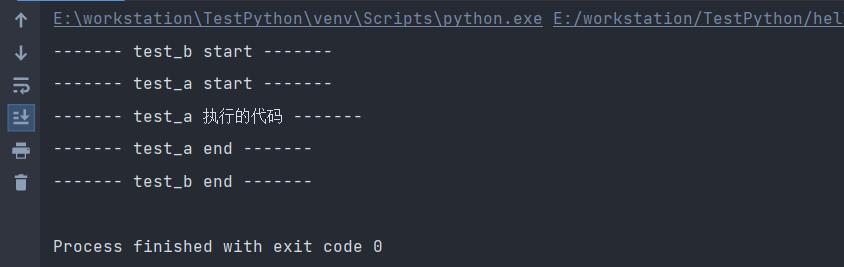
def test_a():
print("------- test_a start -------")
print("------- test_a 执行的代码 -------")
print("------- test_a end -------")
def test_b():
print("------- test_b start -------")
test_a()
print("------- test_b end -------")
test_b()
执行结果如下:
二、变量的作用域
所谓变量的作用域是指变量生效范围。主要分为两类,分别为:局部变量和全局变量。
2.1 局部变量
局部变量即定义在函数内部的变量,该变量只在函数内部生效。若试图在函数外访问局部变量,就会报错。比如下面的示例:
def test_a():
a = 100
print(f"test_a内部访问局部变量a的结果为:{a}")
test_a()
print(f"试图在函数外访问局部变量a的结果为:{a}")
执行结果如下:

2.2 全局变量
所谓全局变量就是在函数内部和外部都能被访问的变量。比如下面的例子:
a = 100
def test_a():
print(f"函数test_a内访问全局变量a的结果为:{a}")
def test_b():
print(f"函数test_b内访问全局变量a的结果为:{a}")
test_a()
test_b()
执行结果如下:

那么能否在函数内修改全局变量呢?当然可以,只不过在函数内需使用global关键字来提取进行声明,否则修改不会生效。比如下面的示例:
a = 100
def test_a():
a = 200
print("试图在test_a函数中修改全局变量a")
def test_b():
global a
a = 300
print("试图在test_b函数中修改全局变量a")
test_a()
print(f"执行test_a函数后,变量a的结果为:{a}")
test_b()
print(f"执行test_b函数后,变量a的结果为:{a}")
执行结果如下:

三、函数的返回值
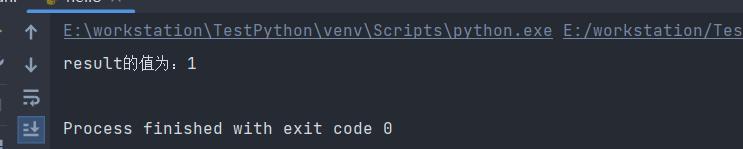
当函数中只声明一条返回语句时,该函数的返回值的就是该return语句指定的值。但若声明多条返回语句时,生效的是首条return语句。如下面的例子:
def return_num():
return 1
return 2
result = return_num()
print(f"result的值为:{result}")
执行结果如下:
需要说明的是,若在Java方法中试图声明多条return语句时,则无法通过编译。
那么,若确有返回多个值的需求时,可将待返回的多个值用逗号进行间隔即可,此时Python会自动将return指定的多个返回值封装为元组类型后进行返回。比如下面的示例:
def return_num():
return 1, 2
result = return_num()
print(f"result的值为:{result}")
print(f"result的类型为:{type(result)}")
执行结果如下:

当然,除使用该方式外,还可将待返回的多个值显式声明为列表、元组或字典。
四、函数的参数
下面将简单介绍一下函数的参数。
4.1 引用
在介绍函数参数前先说一下引用。所谓引用其实可理解为变量对应的内存编号。这点与Java的引用保持一致。而函数在调用时,其参数皆通过引用来进行传递。
下面给出一个例子:
def test1(a):
print(f"a做加法运算前的值为:{a}")
print(f"a做加法运算 前的标识为:{id(a)}")
a += a
print(f"a做加法运算后的值为:{a}")
print(f"a做加法运算后的标识为:{id(a)}")
# 整型计算
b = 100
test1(b)
# 列表计算
c = ["Tom", "Jerry", "Spike"]
test1(c)
上述例子的id函数用于获取某个对象的唯一标识值,感觉与Java中的System.idenfityHashCode(Object x)方法的效果一样。
执行结果如下:

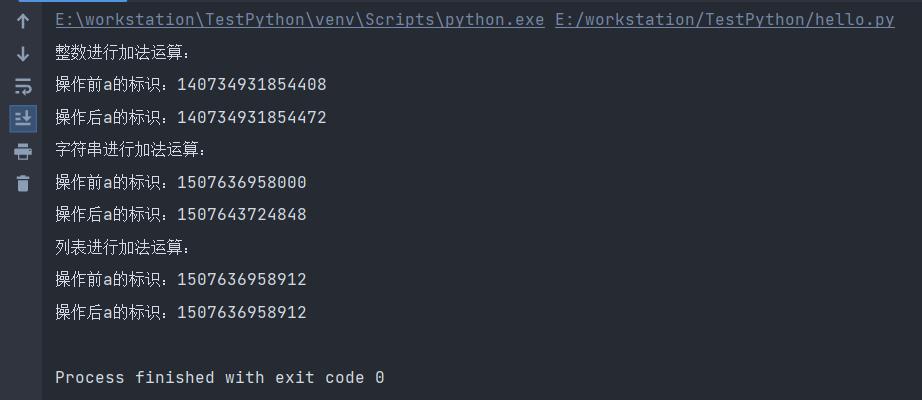
当然,对于传递的引用来说大致可分为可变类型和不可变类型两种。其区别在于数据是否可被修改。常见的可变类型有:列表、集合和字典;常见的不可变类型有:整型、浮点型、字符串和元组。
下面给出对应的例子:
def change(a, val):
print(f"操作前a的标识:{id(a)}")
a += val
print(f"操作后a的标识:{id(a)}")
# 整数
print("整数进行加法运算:")
n = 10
change(n, 2)
# 字符串
print("字符串进行加法运算:")
s = "hello"
change(s, "world")
# 列表
print("列表进行加法运算:")
l = ["Tom", "Jerry"]
change(l, ["Spike"])
执行结果如下:
4.2 位置参数
所谓位置参数是指调用函数时会根据函数的位置来传递相关参数。需要说明的是,传递参数时,传递顺序必须与参数定义顺序保持一致。
下面给出对应的示例:
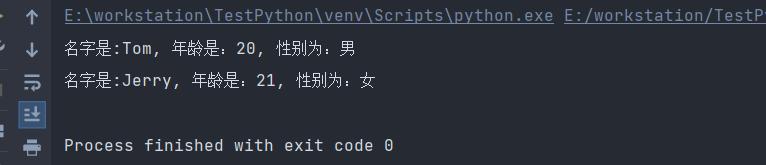
def user_info(name, age, gender):
print(f"名字是:{name}, 年龄是:{age}, 性别为:{gender}")
user_info("Tom", 20, "男")
执行结果如下:

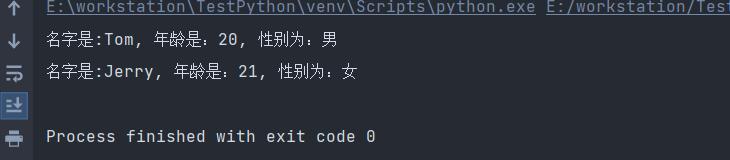
4.3 关键字参数
所谓关键字参数是指,函数调用时通过类似"键=值"的形式来指定对应参数。该种参数指定方式,语义更清晰,使用也更方便。
需要说明的是,当使用关键字参数时,其必须放在位置参数的后面。当然,关键字参数之间不存在先后顺序。
下面给出对应的例子:
def user_info(name, age, gender):
print(f"名字是:{name}, 年龄是:{age}, 性别为:{gender}")
user_info("Tom", age=20, gender="男")
user_info("Jerry", gender="女", age=21)
执行结果如下:
4.4 缺省参数
缺省参数也叫默认参数,主要用于为函数的参数提供默认值,当然,前提是调用函数时未指定该参数时。需要说明的是,缺省参数必须放在位置参数后面。
下面给出对应的示例:
def user_info(name, age, gender="男"):
print(f"名字是:{name}, 年龄是:{age}, 性别为:{gender}")
user_info("Tom", 20)
user_info("Jerry",21, "女")
执行结果如下:
4.5 可变参数
可变参数也叫不定长参数,若在调用函数时无法确定参数的个数,此时就可使用可变参数。当然,在Python中叫包裹参数,其大概分为两类,分别是:包裹位置参数和包裹关键字参数。其中,包裹位置参数使用一个"*"来表示,最后会被封装为元组,而包裹关键字参数使用"**"表示,最后会被封装为字典。
其语法格式为:
# 包裹参数
def 函数(*参数):
代码
# 包裹关键字
def 函数(**参数):
代码
下面给出对应的例子:
# 包裹位置参数
def user_info(*args):
print(args)
print(f"args的类型为:{type(args)}")
# 包裹关键字传递
def user_info_key(**kwargs):
print(kwargs)
print(f"kwargs的类型为:{type(kwargs)}")
user_info("Tom")
user_info("Tom", 18)
user_info_key(name="Tom", age=18, gender="男")
执行结果如下:

五、拆包和交换变量值
5.1 拆包
所谓拆包就是将函数的返回值还原为多个参数,当然,拆包也分为:元组拆包和字典拆包。需要说明的是,拆包时,指定的变量数量必须与元组数量或字典的键值对数量保持一致,否则会报错。下面给出对应的示例:
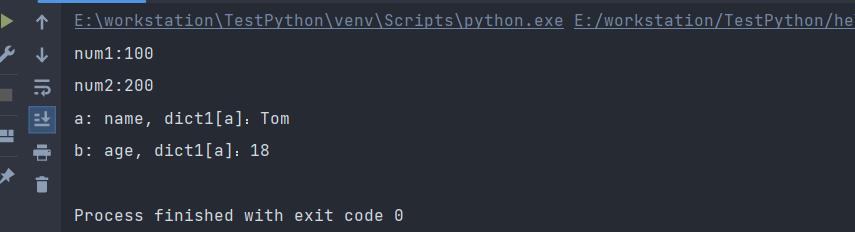
# 对元组进行拆包
def return_num():
return 100, 200
# 将返回值进行拆包
num1, num2 = return_num()
print(f"num1:{num1}")
print(f"num2:{num2}")
# 对字典进行拆包
dict1 = {"name": "Tom", "age": 18}
a, b = dict1
print(f"a: {a}, dict1[a]:{dict1[a]}")
print(f"b: {b}, dict1[a]:{dict1[b]}")
执行结果如下:
5.2 变量值交换
Python提供了专门的多变量交换语法,下面为对应的语法格式:
变量a,变量b=变量b,变量a
对于Java而言,若需进行变量交换,则只能通过额外的临时变量实现。
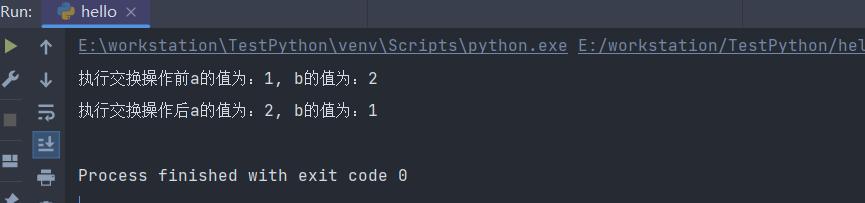
下面为对应的例子:
a, b = 1, 2
print(f"执行交换操作前a的值为:{a}, b的值为:{b}")
a, b = b, a
print(f"执行交换操作后a的值为:{a}, b的值为:{b}")
执行结果如下:
六、递归
所谓递归就是函数在运行过程中会调用到函数本身。对于递归而言,其必须满足如下几个特点:
- 递归过程中会不断调用自己
- 递归过程需存在终止条件,且不断向着终止条件进行递归
- 递归过程需存在一个无需进行计算就能得出的初始值。
当然,对于大多数编程语言来说,都会提供递归操作,python自然也不例外。下面给出在Python中进行递归的例子:
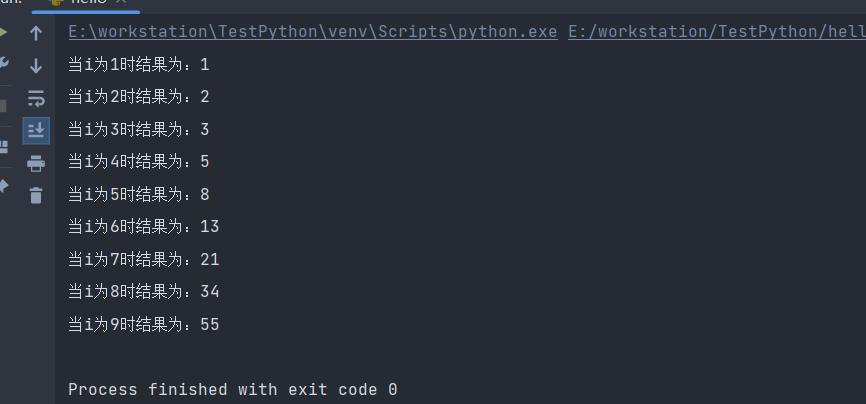
def fibra(num):
if num <= 2:
return num
return fibra(num - 1) + fibra(num - 2)
for i in range(1, 10):
print(f"当i为{i}时结果为:{fibra(i)}")
上述例子其实就是计算斐波那契数列的实现,当然,也常用于解决爬楼梯问题。其中,当num = 1时为终止条件,而num = 1或2时会直接指定初始值,也就是给出对应的斐波那契数值。当num > 2时的斐波那契数值需经过递归进行计算。
执行结果如下:
七、Lambda表达式
7.1 概述
与Java类似,Python中也存在Lambda表达式。所谓的Lambda表达式其实就是一种特殊的语法。在Java中,Lambda表达式只能应用于函数式接口。所谓函数式接口就是有且仅有一个抽象方法的接口。而在Python中则不一样,其将Lambda表达式应用于只有一句代码且只有一个返回值的函数,从这点来看,反而有点像Java中Lambda表达式的一种特例,也就是可用方法引用进行替代的场景。
下面为Python中Lambda表达式的语法格式:
lambda 参数列表:表达式
需要说明的是,lambda表达式中的参数可有可无,但是lambda表达式的参数必须与对应函数的参数保持一致。
下面给出一个例子:
# 普通函数
def add(a, b):
return a + b
m = 2
n = 3
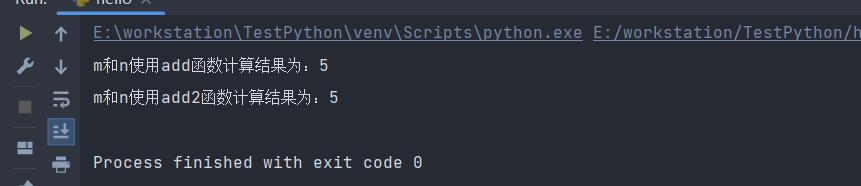
print(f"m和n使用add函数计算结果为:{add(m, n)}")
# 使用lambda表达式
add2 = lambda a, b: a + b
print(f"m和n使用add2函数计算结果为:{add2(m, n)}")
执行结果如下:
7.2 常见形式
7.2.1 无参
所谓无参就是无需传入任何参数,下面给出对应的例子:
# 无参
fn = lambda: print("hello world")
fn()
执行结果如下:

7.2.2 一个参数
所谓一个参数就是只传入一个参数,下面给出对应的例子:
# 带一个参数
fn = lambda text: print(text)
fn("hello world")
执行结果如下:

7.2.2 默认参数
所谓默认参数是指为参数设置默认值,在调用时若未指定参数,则是用该默认值。下面给出对应的例子:
# 带默认参数
fn = lambda a, b, oper = "*" : print(eval(f"{a} {oper} {b}"))
# 传参时
fn(1, 2, "+")
# 不传参时
fn(1,2)
执行结果如下:

7.2.4 可变参数*args
所谓可变参数是指传入的参数不定,需要说明的是,最后传入的参数会被封装为元组。下面给出对应的例子:
# 可变参数*args
fn = lambda *args: args
result = fn("Tom", "Jerry", "Spike", "Tuffy", "Tyke")
print(f"结果为:{result}")
print(f"对应的类型为:{type(result)}")
执行结果如下:

7.2.5 可变参数 **kwargs
对于**kwargs可变参数而言,其与*args的区别在于,其会被封装为字典类型,下面给出对应的例子:
# 可变参数**kwargs
fn = lambda **kwargs: kwargs
result = fn(name="Tom", age="20", sex="男")
print(f"结果为:{result}")
print(f"对应的类型为:{type(result)}")
执行结果如下:

7.3 使用场景
最常见的应该是列表按字典的key进行排序,下面给出对应的例子:
persons = [
{"name": "Tom", "age": 18, "sex": "男"},
{"name": "Jerry", "age": 17, "sex": "女"},
{"name": "Spike", "age": 22, "sex": "男"},
{"name": "Tuffy", "age": 2, "sex": "女"},
{"name": "Tyke", "age": 6, "sex": "男"}
]
# 按照name升序排序
persons.sort(key=lambda p: p["name"])
print("按照name升序排序后结果为:")
for p in persons:
print(p)
# 按照年龄降序排序
persons.sort(key=lambda p: p["age"], reverse=True)
print("按照age降序排序后结果为:")
for p in persons:
print(p)
执行结果如下:

八、高阶函数使用
8.1 概述
所谓高阶函数就是将一个函数作为另一个函数的入参。其实所谓高阶函数有点类似函数式编程。下面给出对应的示例:
# 不使用高阶函数实现两个数的绝对值求和
def add_num(a, b):
return abs(a) + abs(b)
# 使用高阶函数实现两个数的绝对值求和
def add_num_1(a, b, abs_func):
return abs_func(a) + abs_func(b)
print(f"2和-3的绝对值之和为:{add_num(2, -3)}")
print(f"2和-3的绝对值之和为:{add_num_1(2, -3, abs)}")
执行结果如下:

8.2 内置的高阶函数
对于Python而言,其提供了一些内置的函数,常见的有:map、reduce和filter。
8.2.1 map
map函数会接收两个参数,分别为:func和list。其用途是使用传入的函数来对list进行处理,并返回新的数据结构。若为Python2,则返回的是列表;若为Python3,则返回的是迭代器。
下面给出对应的使用例子:
list1 = [1, 2, 3, 4, 5]
# 将队列中的元素统一平方
def pow(x):
return x ** 2
result = map(pow, list1)
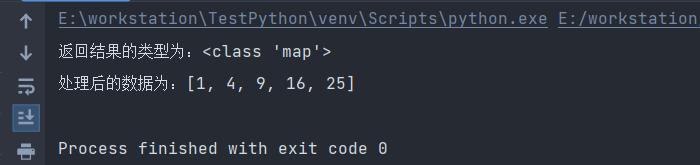
print(f"返回结果的类型为:{type(result)}")
print(f"处理后的数据为:{list(result)}")
执行结果如下:
8.2.2 reduce
对于reduce来说,其传入的函数必须有两个参数,其用途是通过传入的参数对序列的元素做累积运算。下面为对应的示例代码:
list1 = [1, 2, 3, 4, 5]
def multiply(a, b):
return a * b
def add(a, b):
return a + b
# 累加运算
addResult = functools.reduce(add, list1)
print(f"累加的结果为:{addResult}")
# 累积运算
multiplyResult = functools.reduce(multiply, list1)
print(f"累积的结果为:{multiplyResult}")
执行结果如下:

8.2.3 filter
filter函数的用途是使用传入的函数来对序列进行过滤,下面为对应的例子:
list1 = [i for i in range(1, 11)]
def func(x):
return x & 1 == 0
result = filter(func, list1)
print(f"过滤后的结果为:{list(result)}")
执行结果如下:
