1、需求:
抓取http://bbs.hefei.cc/forum-69-1.html合肥论坛跳蚤市场的页面以及该跳蚤市场后续页面的内容并保存到本地。参照python视频贴吧爬虫.flv独立完成代码设计和运行
2、代码:
import requests
#合肥论坛爬虫抓取类
class HefeiForumSpider:
def __init__(self):
self.urlBase = "http://bbs.hefei.cc/forum-69-{}.html"
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"}
#获取要查询的网页的地址链接,加入到列表中
def getURLList(self):
urlList = []
for i in range(5):
urlList.append(self.urlBase.format(i))
return urlList
#获取要查询的网页的内容
def getHtmlContent(self, url):
response = requests.get(url, headers=self.headers)
return response.content.decode(encoding = "gbk", errors = "ignore")
#将获取到的网页保存到本地
def saveHtml(self, html_str, number):
savefilename = "第{}页.html".format(number)
with open(savefilename, "w", encoding="gbk") as f:
f.write(html_str)
def main():
HFS = HefeiForumSpider()
urlList = HFS.getURLList()
for url in urlList:
htmltemp = HFS.getHtmlContent(url)
number = urlList.index(url) + 1
HFS.saveHtml(htmltemp, number)
if __name__ == "__main__":
main()
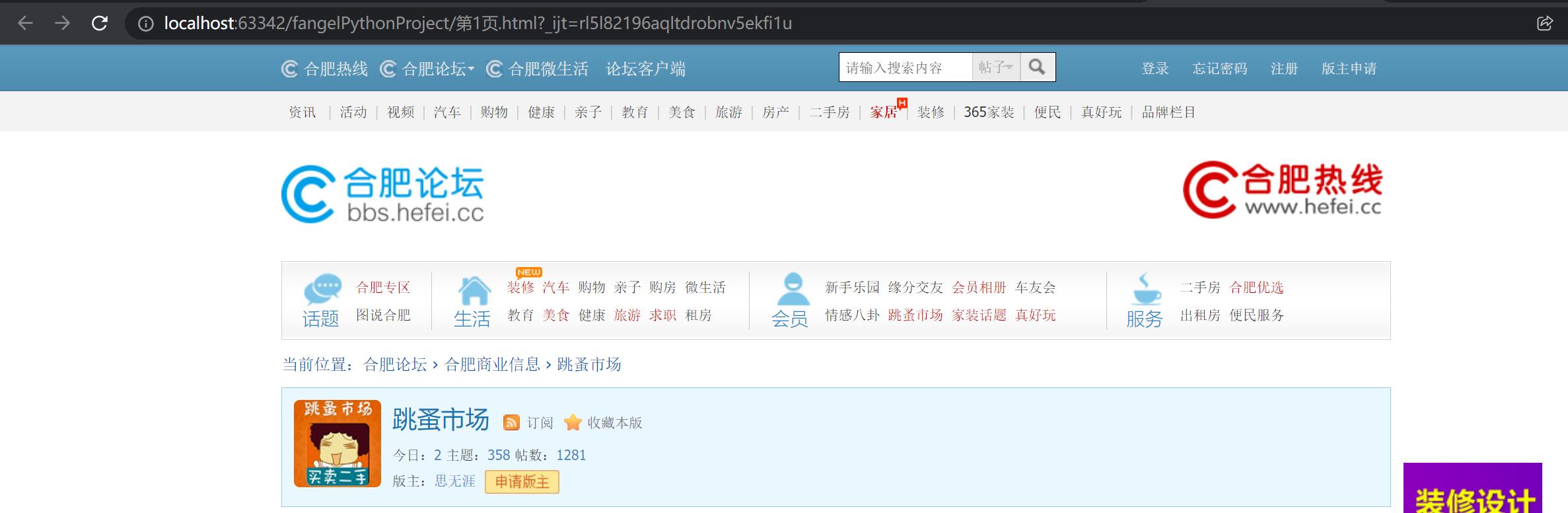
3、运行结果:
打开页面
如下表明抓取正常
4、FAQ:
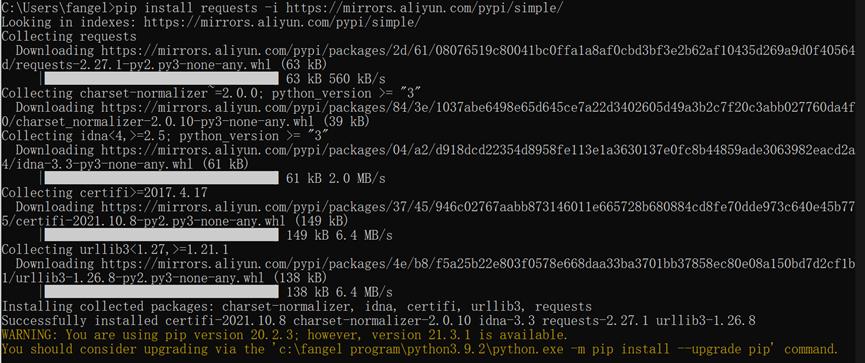
本例需要用到requets包,如果pip*载下**失败,解决方案如下:
安装requests报错:
C:\Users\fangel>pip install requests
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x00000172159CC520>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/requests/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x00000172159CCEE0>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/requests/
原因分析:
无法*载下**国外服务器的相关资源导致
解决方案:
加-i参数从指定的国内镜像进行*载下**:
C:\Users\fangel>pip install requests -i https://mirrors.aliyun.com/pypi/simple/