
大量的股票市场价格数据以高速动态生成,并且每分每秒都会变化。考虑到复杂而富有挑战性的股票市场系统,基于正确的预测和市场分析,收益或损失会发生,我们都意识到金融市场的高度波动。在分期偿还的情况下,概率正确的预测可能会非常有利可图。
我已经购买了多支股票(黄金,白银,原油,美元,利率和股票指数),这些股票可能直接或间接影响金价。在这里,我将展示如何不同程度的成功应用多种机器学习(ML)算法。
结合不同机器学习模型的混合预测方法的组合有利于更好的预测。
使用移动平均和指数移动平均来测量价格波动,从数据中提取波动特征。此数据可从网上轻松获得。
数据挖掘与定量分析
这里的数据包括如下
日期:天
开盘:开盘时的股票价格
最高:交易日中该股票的最高价格
最低:交易日中该股票的最低价格
收盘:收盘时的股票价格
成交量:交易的股票数量
复权收盘价:交易结束时的股票价格经股息复权
下面是部分数据截图。
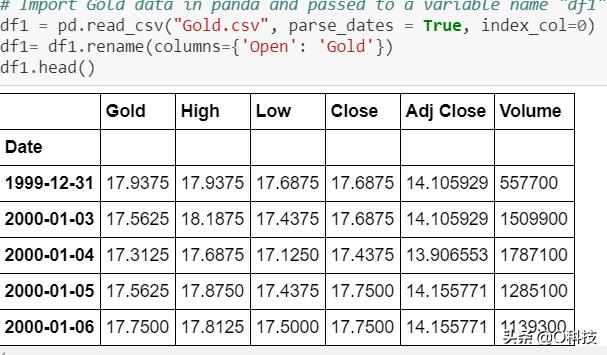
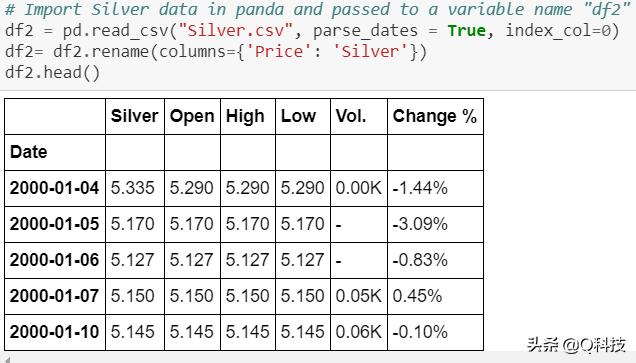
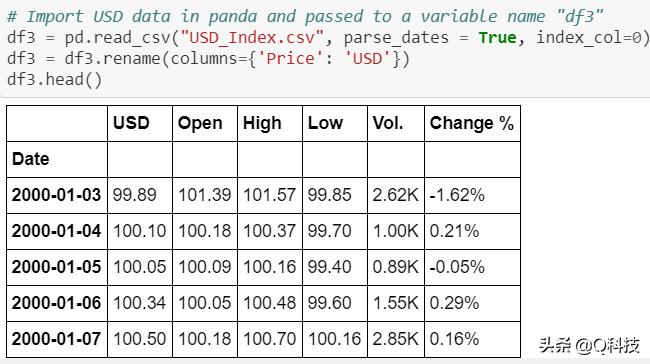
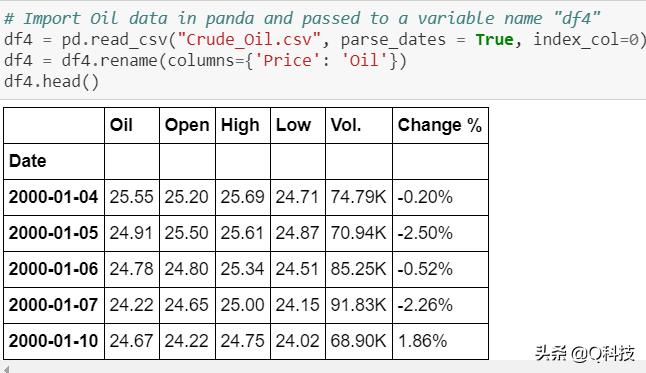
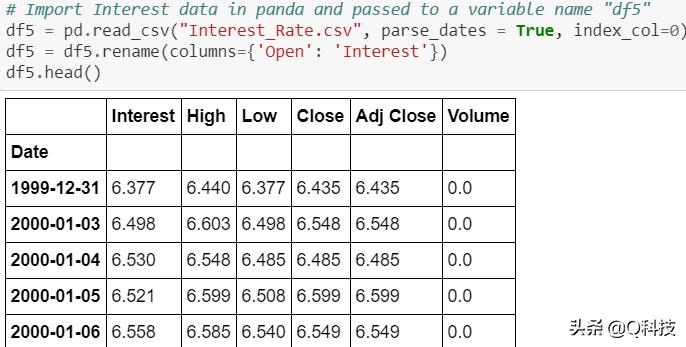

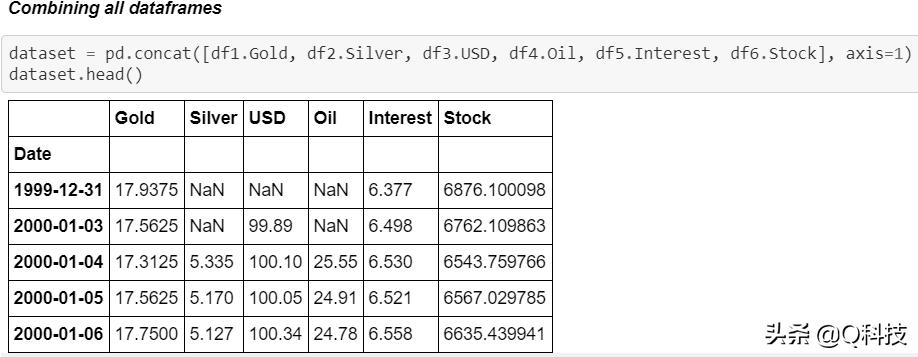
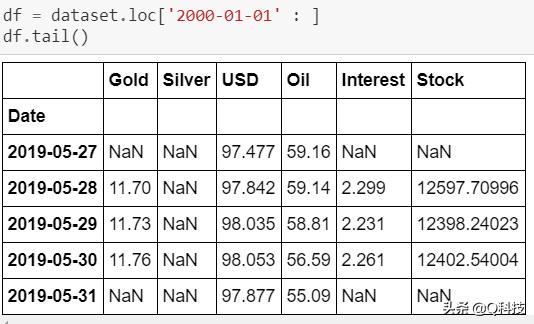
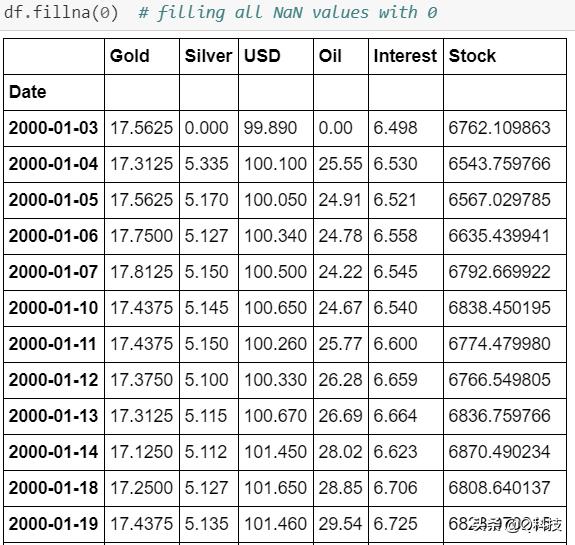
数据集具有相当多的空值。为了处理方便起见,我用0填充了这些值。但是,建议对平均值/中位数进行实验以进行股票预测。在填充空值之前,我已将开始日期固定为2001-01-01。

从总体统计数据来看,每个类别的计数都不同,这导致数据集失衡。理想情况下,我们应该在此处进行更多研究,并使所有列中的计数对称。但是,在这里,我们将暂时不考虑这部分并继续进行其余的分析。
建议使用非参数统计显著性检验,例如Mann-Whitney U检验,Wilcoxon有符号秩检验,Kruskal-Wallis H检验等,以验证数据分布和数据差异。但是,我们跳过了此过程,以使初学者更简单易懂。
探索黄金股票的滚动平均值和收益率
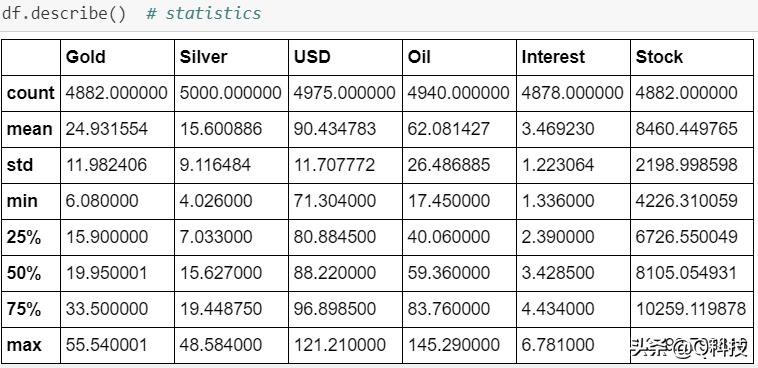
我们将在此处包括最受欢迎的技术指标移动平均线和指数移动平均线(EMA)。移动平均线使线平滑并显示价格的上升或下降趋势。交易者经常使用几种不同的EMA天,例如20天,30天,90天和200天移动平均线。我们这里将使用100天作为示例。
预期收益衡量投资收益概率分布的平均值或预期值。我使用以下公式来确定风险和回报:
rt = Pt-Pt-1 / pt-1 =(Pt / Pt-1)-1
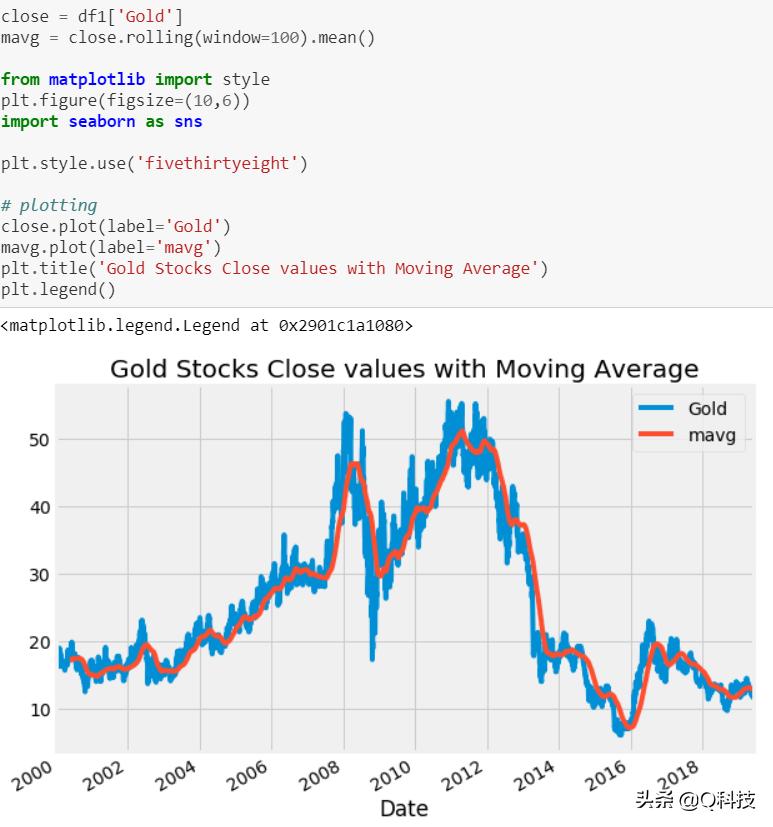
从2009-2010年的曲线图中可以看到一个高波动区,在该区中波峰依然存在。这可能是由于2007年至2010年美国次级抵押*款贷**危机(金融危机)期间的衰退所致。此外,在2002–2003年,2013–2014年,2016–2018年期间也可以看到波动性。
让我们在一个图中绘制所有变量并检查其模式。
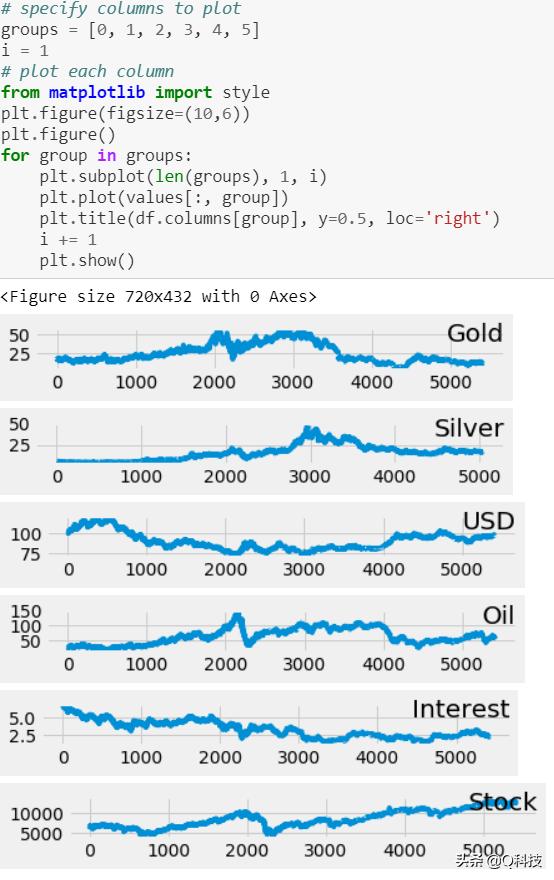
在这里,包含黄金,白银和石油三种产品,以及美元,利率和整体股指的数据。我们要检查其中是否与黄金价格行为相关。尽管数据尚未正则化,但我们希望通过对图检查其分布以更好地理解数据。

好了,对于配对图,可以看到正相关和负相关。因此,我们将进行相关分析以检查是否有任何变量影响其他变量。
相关分析
此分析是使用百分比变化来完成的,以找出与定义收益的前一天相比价格的变化。了解相关性将有助于了解收益是否受到其他股票收益的影响。

ρ越接近1,一个变量的增加与另一个变量的增加越相关。为了找到与黄金的关联,石油ρ= 0.125和银0.387,尽管微不足道,但显示出正关联。另一方面,ρ越接近-1,一个变量的增加将导致另一个变量的减少。利息和美元显示与黄金的关联。为了方便起见,我们放大了以下散点图以解释白银和石油的关系。
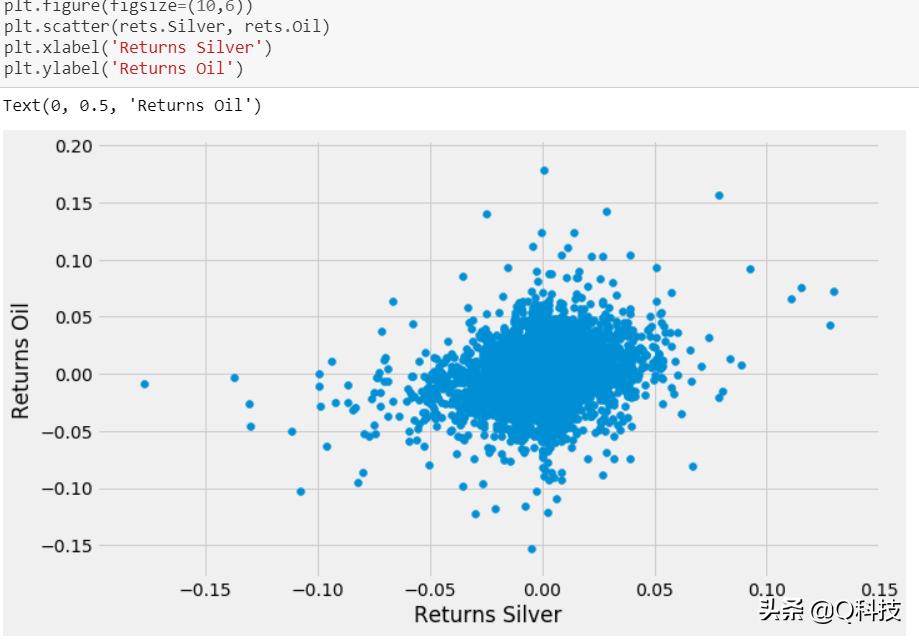
散点图显示白银和石油收益之间的轻微+ ve相关性。尽管微不足道,但很明显,在大多数情况下,石油的收益越高,白银的收益也越高。
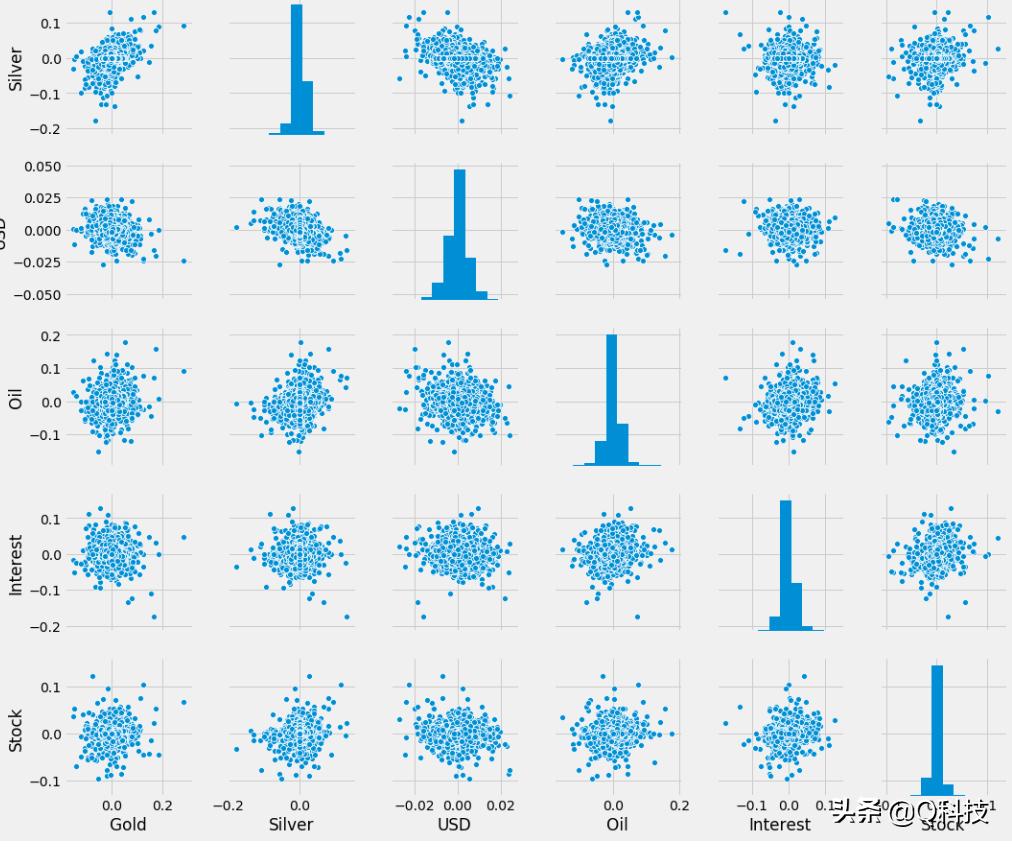
下图显示了成对比较,以便更好地可视化和分析,以检查此分析中其他股票之间的相关性。
组合的散布图和分布图显示了大多数分布,它们近似为正相关,但根据上面的相关矩阵,也有一些负相关。但是,为了消除混乱,我们将通过热图可视化。在下面的热图中,颜色越浅,这两种股票的相关性越高。
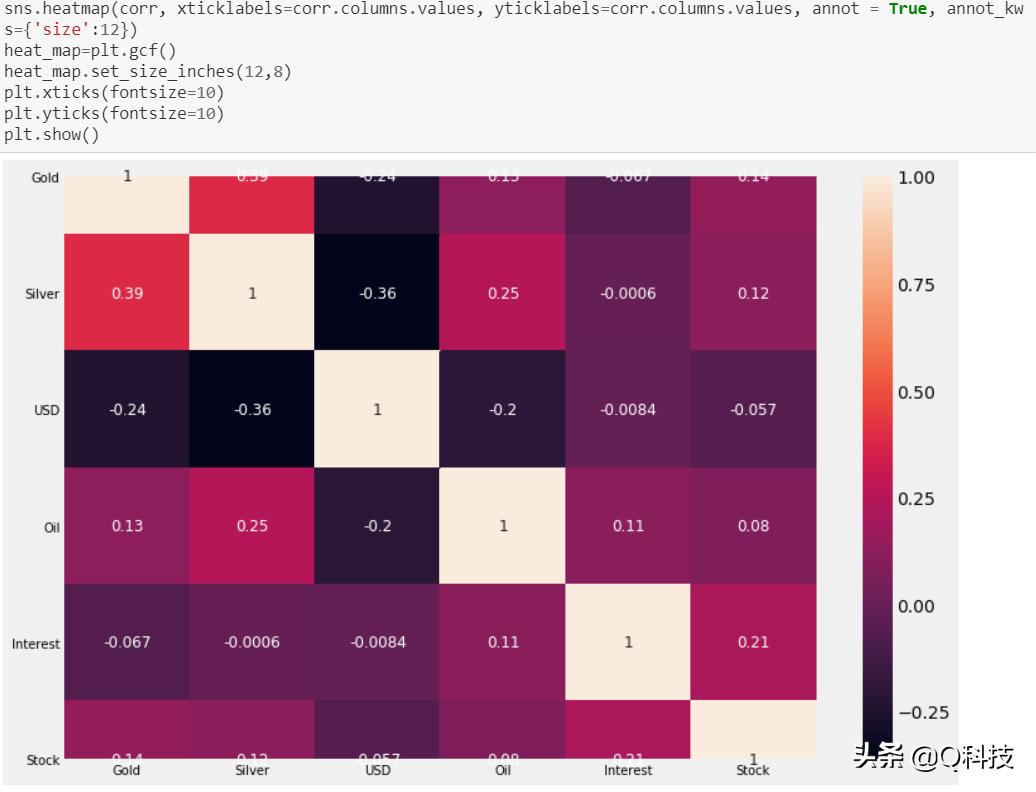
热图中的值来自相关矩阵(四舍五入为两位十进制),并显示相同的结果。
股票收益率和风险
除了相关性之外,让我们通过提取平均收益和与风险相关的收益标准差来分析股票的风险和收益。可能存在因果关系,表明股票市场和行业的趋势,而不是表明这些股票如何相互影响。
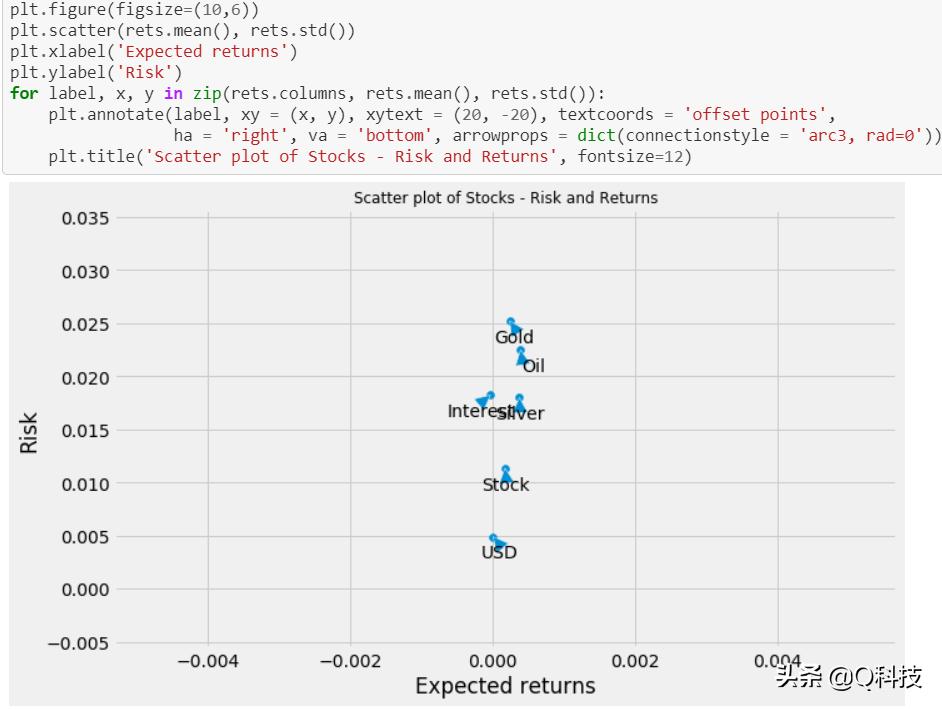
我们无法画出任何图形来反映买卖头寸。美元,股票和利息变量不可购买/出售,这些是影响交易的因素,超出了该项目的范围。
特征工程
这是开发用于预测分析的算法的重要部分。特征选择可帮助算法去除多余和不相关的因素,并找出因素的最重要子集来构建分析模型。在最近的一篇文章(Long et al.,2019)中有涉及,感兴趣的人可以找到基于深度学习的特征工程来预测股价走势。
在这里,我们执行了一个基本的特征工程,可以从开盘价,最高价,最低价,收盘价,调整收盘价和黄金储备量中选择特征。这些功能将用于训练模型以进行预测。这些功能基于高低百分比,百分比变化和每日收益,如下所示。
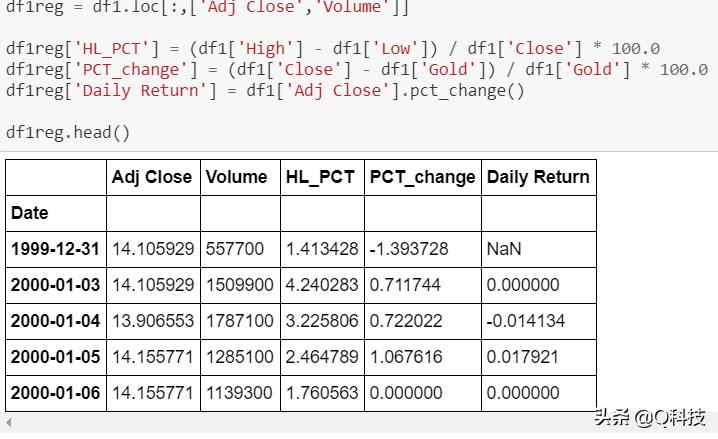
预处理
#输出
X_train和x_test的长度:3867 967
在机器学习之前转换目标的好处。
在训练线性回归模型并将其用于预测之前,使用对数(np.log1p)和指数函数(np.expm1)转换目标。股票的增长也可以用对数差异来衡量。
changet = log(pricet)-log(pricet-1)
使用对数差异的优势在于,差异可以解释为库存中的百分比变化,但不取决于分数的分母。
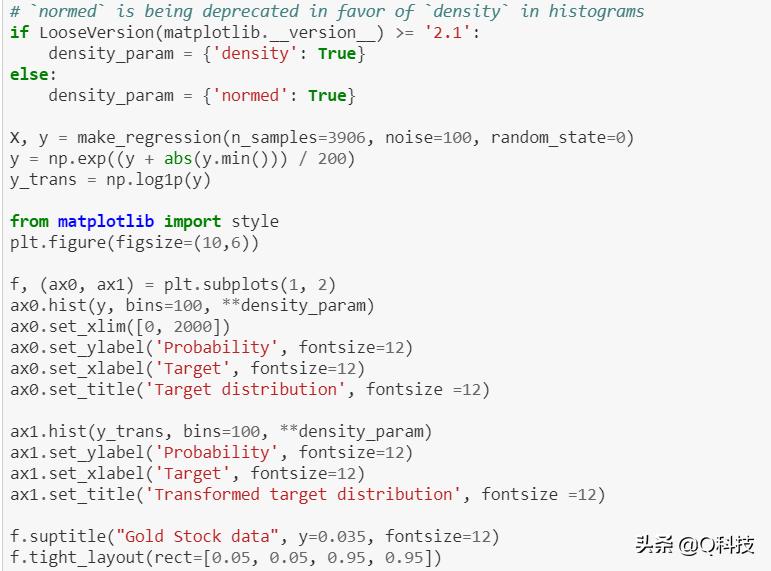
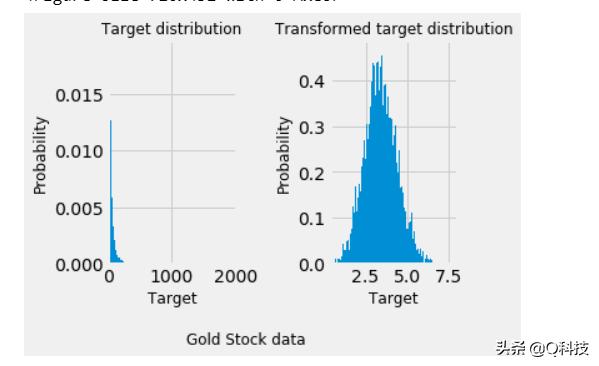
上面的曲线清楚地显示了在应用对数函数之前和之后目标的概率密度函数的改进。首先,将线性模型应用于原始目标。由于非线性,训练的模型在预测期间将不精确。随后,使用对数函数将目标线性化,即使使用中位数绝对误差(MAE)报告的相似线性模型,也可以实现更好的预测。
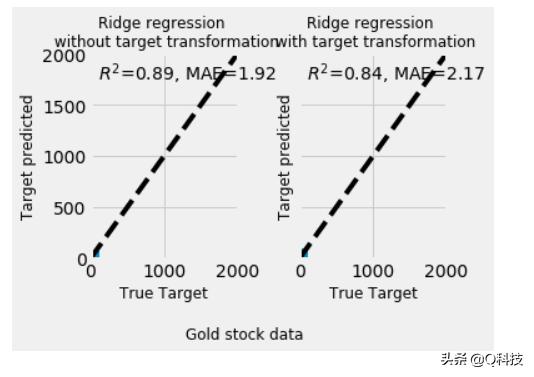
从上面的图中的MAE分数来看,我们可以看到,变压器的作用较弱。但是,Ridge回归对于分析具有多重共线性的多重回归数据的多个变量是有效的,在这里不是这种情况。因此,我们将在此处忽略Ridge回归。分布图显示了变换后数据分布的显着改善。
机器学习
我将使用不同的机器学习模型来预测股票价格-简单线性分析,多项式分析(2&3)和K最近邻(KNN)。比较不同分析技术的结果总是好的。这可以帮助确认结果或突出显示不同的建模假设和特征如何发现新的见解。
考虑到现实世界中数据可能不是线性的而是分散的,在这种情况下,线性回归可能不是描述数据的最佳方法。因此,多项式或曲线可能更适合此类数据。因此,我也已经拟合了多项式2和3来检查结果。
二次方程或二次多项式的方程为:Y =β0+β1X+β2X2
同样,二次方程或三次多项式的方程为:Y =β0+β1X+β2X2+β3X3
此外,我将在同一训练数据集上使用蒙特卡洛模拟和人工神经网络(多层感知器)进行比较。

评价
使用计分方法进行评估,以求出平均准确度。
conf_reg = reg.score(X_test,y_test)
print('线性回归置信度为:',conf_reg)
conf_poly2 = poly2.score(X_test,y_test)
print('二次回归置信度为:',conf_poly2)
conf_poly3 = poly3.score( X_test,y_test)
print('二次回归3置信度是:',conf_poly3)
conf_knn = knn.score(X_test,y_test)
print('knn回归置信度是:',conf_knn)
#输出
线性回归置信度为:0.8909586197955578
二次回归置信度为:0.8943250852457457
二次回归置信度为:0.8978725731812891
knn回归置信度为:0.8661004477247705
上面的输出显示所有模型的准确度得分> 0.85。在所有模型中,二次模型3模型得分最高(0.897)。让我们检查一下R2值以获得最佳拟合模型。
y_predicted = poly3.predict(X_lately)
y_predicted #健全性测试->确定的价格
#输出
Array([13.16550524、13.88887224、14.65072058、14.40535961、13.36155726、13.39299246、12.89502031、13.01513713、13.12139744、12.61564775、13.34778017、13.25784888、13.05284681、13.37160421、13.08918026、13.0385458、12.92290017、13.32703497、12.673.12。 ,12.63436994、13.00453998、12.2045563、12.60548673、12.94442711、12.45681936、12.34425075、12.72991897、12.61669835、12.75722312、12.04019544、11.57117063、12.44477409、12.46093996、12.30291327、11.79014334、12.27494244、12.35700006、12.09458238、11.9481.923.178 ])
以上是根据二次方程或3级拟合模型的多项式预测的价格。
#计算R平方和均方根值,以检查拟合优度
r2_score = poly3.score(X_test,y_test)* 100
print(“ R2进行回归”,float(“ {0:.2f} ” .format(r2_score))))
#输出
R2回归89.79
根据预测,让我们将图表与现有历史数据一起可视化,以预测黄金的未来股价。
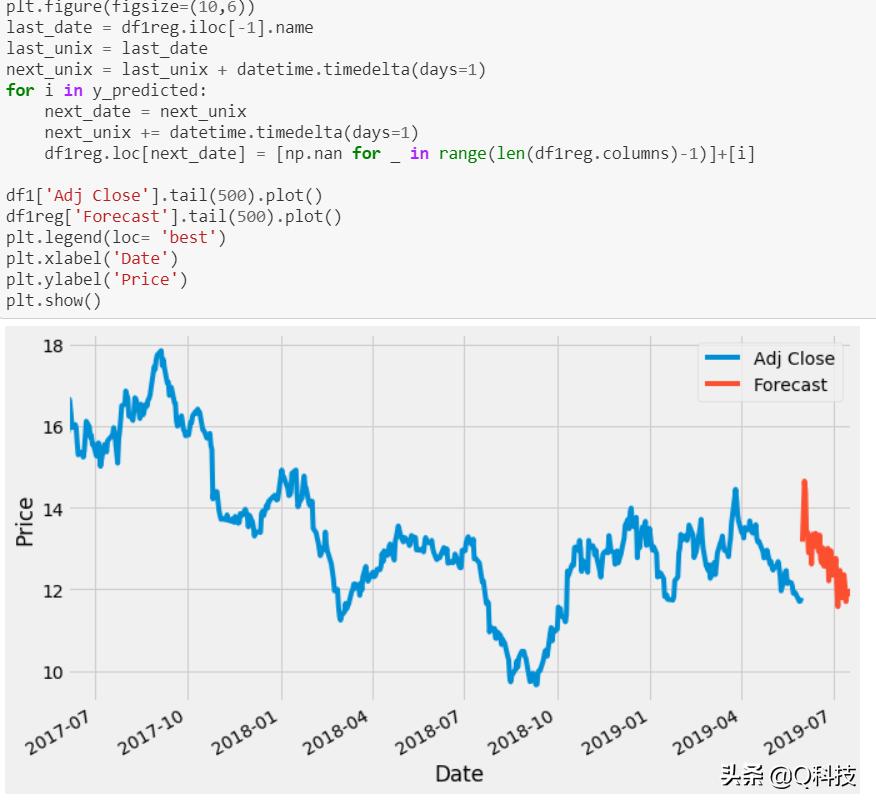
上图是根据现有黄金存量历史数据得出的预期预测。橙色显示基于回归的股票价格预测。该预测预测,2019年剩余月份的黄金库存可能会下降。
预测股票的走势
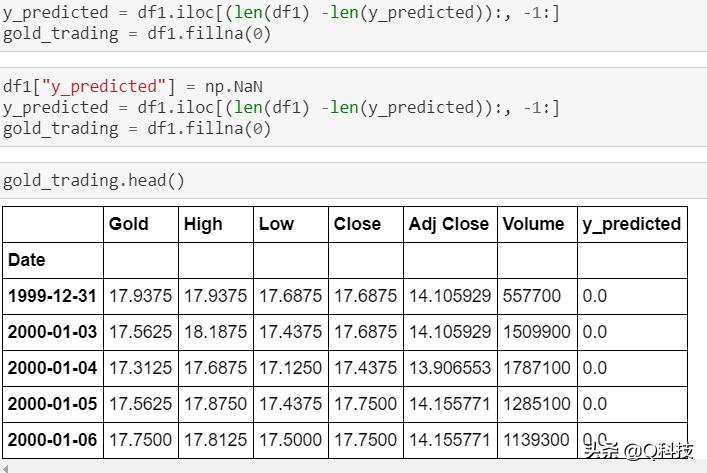
在数据框df1中使用列标题“ y_pred”创建一个新列,并将NaN值存储在该列中。然后从测试数据集的行开始,将y_pred的值存储到此新列中。然后从数据集中删除所有NaN值,并将它们存储在名为gold_trading的新数据框中。
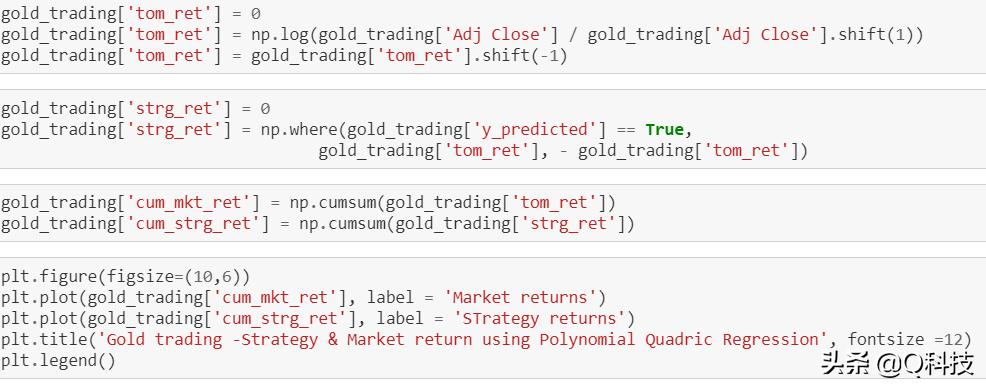
计算策略收益
用黄金股票走势的预测值,将计算该策略的回报。当y的预测值为true时采取多头头寸,而当y的预测值为false时采取短头寸。
首先计算如果在今天结束时采取多头头寸策略将获得的收益,并在第二天结束时求出收益。
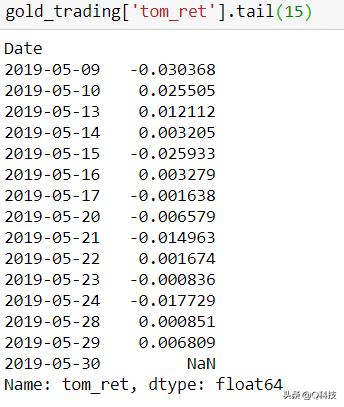
在gold_trading数据集中创建一个新列(tom_ret),并将其值存储为0。
将使用十进制表示法表示浮点值将存储在此新列中。
接下来,将今天的平仓价的对数除以昨天的平仓价的对数。
将这些值上移一个元素,以便明天的收益与今天的价格相对应。
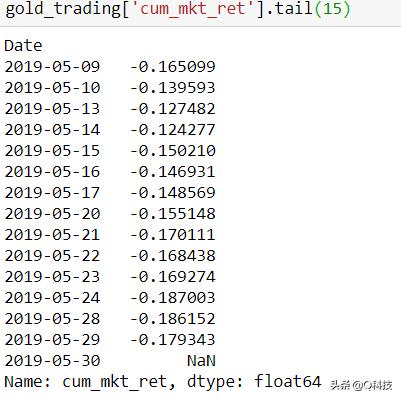
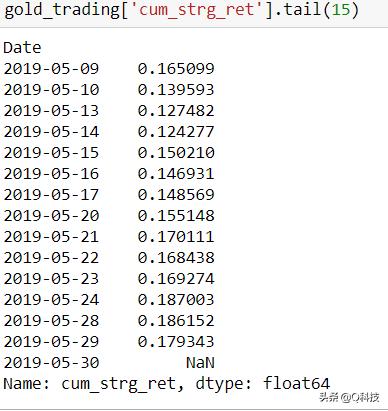
计算市场和策略的累积收益。
最后绘制市场收益和战略收益以可视化表现。
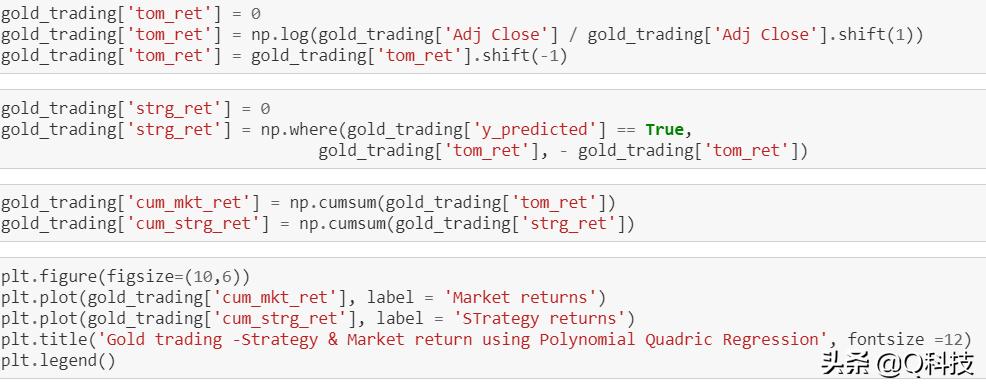
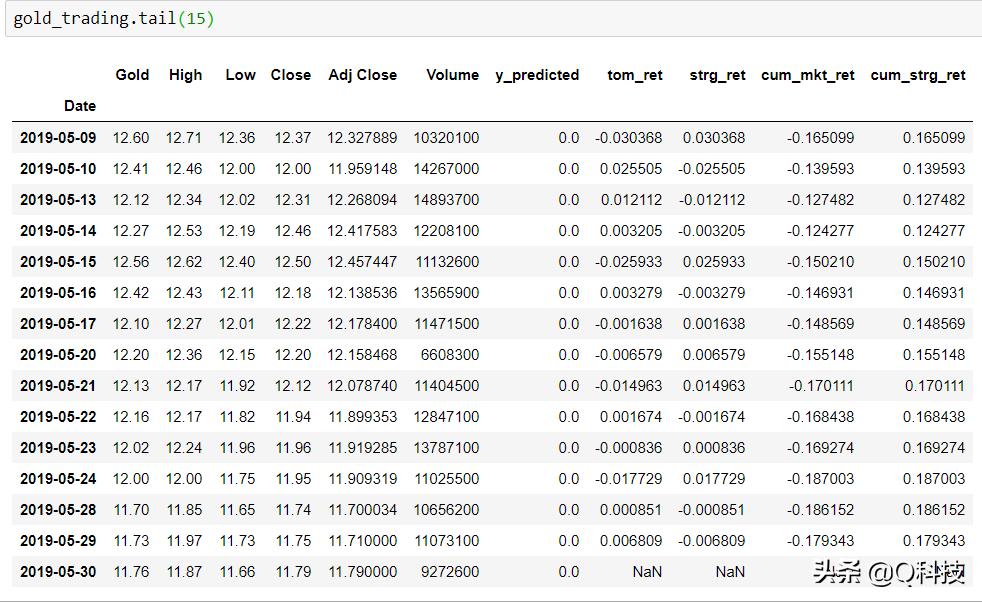
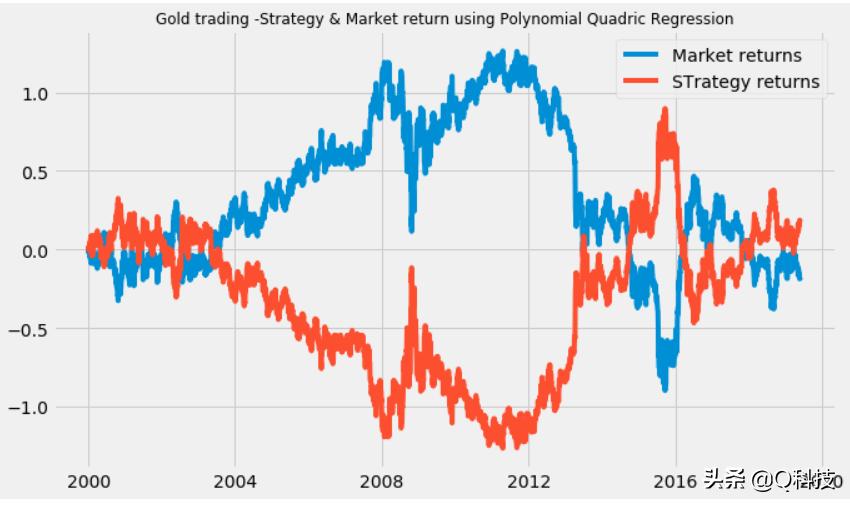
实际上,我们只是简单地添加了策略-首先获得回报,然后将其转换为相对回报。上面的情节是市场收益和策略的镜像。在这里,我们采取了前面讨论过的长(100天的时间)策略。让我们看一下gold_trading的尾端。请记住,已添加对数回报以显示跨时间的性能,让我们绘制每种资产策略的累积对数回报和累积相对总回报。

因此,该策略在这里似乎很有利。现在,我们可以通过更改移动平均窗口,更改买/卖和退出头寸的阈值等进行进一步优化,并检查训练数据的性能改进。
但是,仅对样本数据进行拟合并不一定会在将来提供良好的结果。过度拟合是交易策略中最危险的陷阱。过度拟合算法在回测中可能会表现出色,但在看不见的新数据上却会惨败-这意味着它并没有真正揭示数据的任何趋势,也没有真正的预测能力。事实上,过度拟合和拟合不足都会导致较差的机器学习模型性能。最常见的问题是过度拟合。
评估机器学习算法以限制过度拟合问题时可以使用的两种常见技术是:
(1)使用重新采样技术来估计模型的准确性,
(2)保留验证数据集。
但是,我们始终更喜欢k折叠交叉验证重采样技术。
如开始时所讨论的,比较不同分析技术的结果总是好的,这对更好地进行预测始终是有益的。我们对于不同的模型也需要进行反复的验证和测试,最终,我们能知道哪种模型更适合做什么,哪些模型可以混合用于创建我们的交易系统。