Part1数据规范化
数据规范化通常是指将数据转换为能够方便机器处理的格式。
要进行数据规范化,首先需要清楚地了解数据的格式和内容,然后按照需要对数据进行转换。这通常需要使用编程语言或数据处理工具,比如 Python、Excel 或 SQL。
举个例子,如果你的数据集中有一列是以美元为单位的价格,而另一列是以欧元为单位的价格,你可能需要将它们转换为同一单位(例如RMB),以便能够进行更有意义的比较。
数据规范化对于机器学习和数据分析非常重要,因为许多算法和工具只能处理特定格式的数据。如果你的数据不符合规范,可能会导致算法运行效率低下或出现错误。
简单的数据规范化 :简单的数据规范化通常是对数据类型、格式、单位、小数位数等进行统一。
- 数据类型规范化
数据类型的规范化更准确来讲是对于数值数据的子类型的规范。
比如数字出现类型可能有货币,会计数字,文本,一般数字等。在数据处理的过程中对于这些子类型的数值数据的处理方式不同,规范化数据类型可以使数据更易于处理,并使多个系统或应用程序之间的数据交换更容易。
- 数据格式规范化
格式规范化这种情况最常出现在字符串类型中,例如斜体和粗体,将日期类型转换为统一的日期格式等。
- 小数位规范化
小数位数规范化,在数据小数位不统一的情况下,通过四舍五入将小数舍入到给定位数。
高级的数据规范化 :高级的数据规范化指一些更加复杂的数据处理和转换,比如常见的有:
- 归一化(Min-Max标准化):将数据缩放到指定的范围(通常为0到1)。
- 标准化(Z-score标准化):将数据转换为具有均值0和标准差1的分布。
- 对数转换:将数据转换为对数形式,这常用于处理数据具有指数级别的变化趋势的情况
接下来我们用Min-Max标准化和Z-score标准化的例子,来一起体验一下数据规范化的过程。
归一化 (Min-Max标准化)
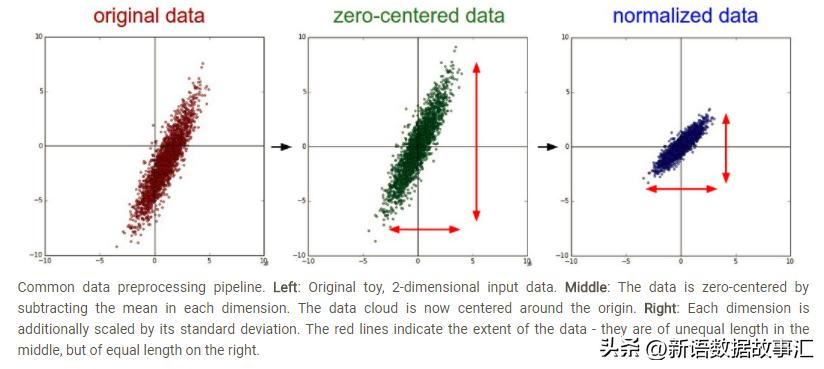
不同特征往往具有不同的量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位,以解决数据指标之间的可比性,提高精度。
常见的映射范围有 [0,1] 和 [-1,1]。最常用的归一化方法是Min-Max归一化,利用数据集每个特征的最大值,最小值对原始数据进行线性变换,将每个特征的值缩放到[0,1]区间.
转换函数:
这种方法有个缺陷,就是当有新数据加入时,可能导致和的变化,需要重新定义。因此在实际应用中,我们一般使用经验常量来替代和。
我们先来随机生成一些数据并看看分布情况:
importnumpyasnp
importpandasaspd
importseabornassns
importmath
importmatplotlib.pyplotasplt
plt.rcParams["axes.unicode_minus"]=False
%matplotlibinline
x1=np.random.randint(10,size=(100,))
x2=np.random.randint(100,size=(100,))
x1_min,x1_max=np.min(x1),np.max(x1)
print(x1_min,x1_max)
x2_min,x2_max=np.min(x2),np.max(x2)
print(x2_min,x2_max)
输出:
0 9
0 97
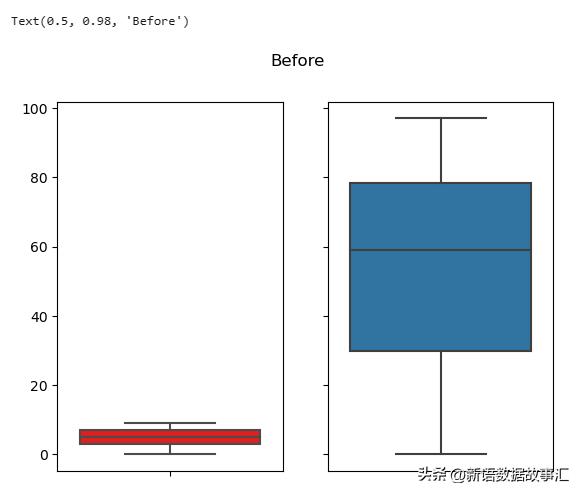
原始的数据分布情况:
fig,ax=plt.subplots(1,2,sharey=True)
sns.boxplot(y=x1,color='r',ax=ax[0])
sns.boxplot(y=x2,ax=ax[1])
fig.suptitle("Before")
输出:
归一化处理:
x1_new=(x1-x1_min)/(x1_max-x1_min)
x1_new_min,x1_new_max=np.min(x1_new),np.max(x1_new)
x2_new=(x2-x2_min)/(x2_max-x2_min)
x2_new_min,x2_new_max=np.min(x2_new),np.max(x2_new)
print(x1_new_min,x1_new_max)
print(x2_new_min,x2_new_max)
0.0 1.0
0.0 1.0
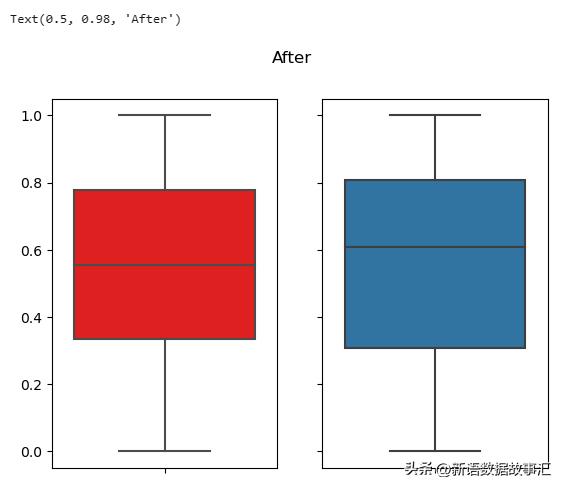
处理后的数据分布:
fig,ax=plt.subplots(1,2,sharey=True)
sns.boxplot(y=x1_new,color='r',ax=ax[0])
sns.boxplot(y=x2_new,ax=ax[1])
fig.suptitle("After")
标准化(Z-score标准化)
Z-score标准化是通过特征的均值(),标准差(),将特征缩放成一个标准的正态分布,目的是为了方便数据的下一步处理。
转换函数:
标准化后的变量值在0附近波动,大于0说明高于平均水平,小于0说明低于平均水平。
我们来随机生成一些数据并且分别打印原始的均值和标准差以及Z-score标准化后的均值和标准差:
x=np.random.random(size=(100,))
mu_before,sigma_before=round(x.mean(),2),round(x.std(),2)
print("beforenormalization:",mu_before,sigma_before)
x_new=(x-mu_before)/sigma_before
mu_after,sigma_after=round(x_new.mean(),2),round(x_new.std(),2)
print("afternormalization:",mu_after,sigma_after)
before normalization: 0.54 0.27
after normalization: 0.01 1.01
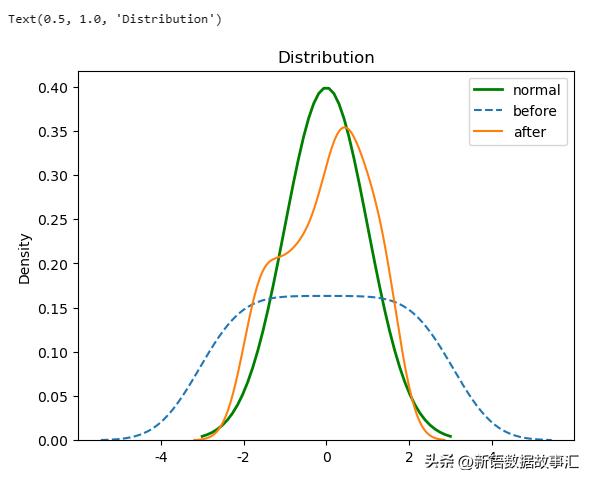
先来画一个标准的正态分布作为参考,然后绘制我们自己的原始以及Z-score标准化后的数据曲线:
#先来画一个标准的正态分布作为参考
u=0#均值μ
sig=math.sqrt(1)#标准差δ
x=np.linspace(u-3*sig,u+3*sig,50)#定义域
y=np.exp(-(x-u)**2/(2*sig**2))/(math.sqrt(2*math.pi)*sig)#定义曲线函数
plt.plot(x,y,"g",linewidth=2,label='normal')#加载曲线
#绘制我们自己的原始以及Z-score标准化后的数据曲线
sns.kdeplot(x,label='before',linestyle='--')
sns.kdeplot(x_new,label='after')
plt.legend()
plt.title("Distribution")
输出:
归一化和标准化的区别和联系
归一化是为了消除不同数据间的量纲,方便数据比较和共同处理;标准化是为了方便数据进行下一步的处理而进行的数据缩放等变换,并不是为了方便与其他数据一同处理或比较,在数据进行Z-score标准化之后,更利于使用标准正态分布的性质进行后续处理。
两者从本质上来说都是对数据的线性变换,都不会改变原始数据的排列顺序。两者都是指特征工程中的特征缩放过程,使用特征缩放的作用是,使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
Part2正则化
正则化是指在模型训练中加入限制条件,以防止模型过拟合和提高模型的泛化能力。通常用于线性模型(如逻辑回归、线性回归)和神经网络中。
在机器学习中,当选择的模型复杂度过高时,过拟合现象便容易发生。因此我们在进行最优的模型选择时,要选择复杂度适当的模型,以达到是测试误差最小的学习目的。
我们先来看一张有意思的图:
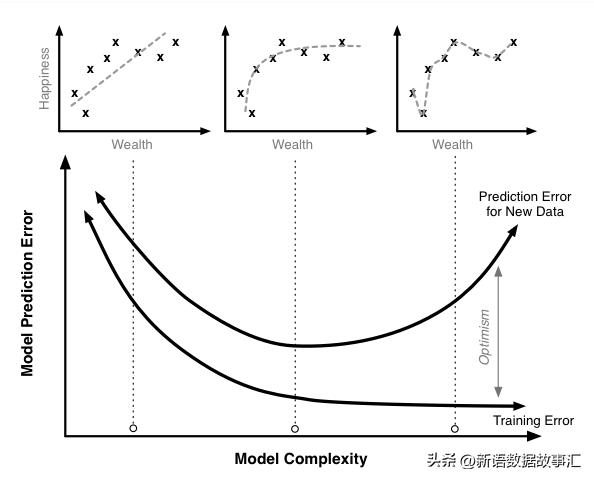
上方的三个图表代表财富-幸福度拟合出来的三个模型,下方大的图表绘制的是模型复杂度和预测值错误的曲线图。
- 第一个模型在训练集的表现并不是很好,属于欠拟合
- 第三个模型是很复杂的模型,很完美的拟合了训练集的每个数据。但是过于强调拟合原始数据,而丢失了算法的本质:预测新数据。可以看出,该模型的泛化性能力很差,若给出一个新的值使之预测,它将表现的很差,属于过拟合
- 第二个模型虽然有个别错误数据点,但是预测新数据效果很好
因此在进行模型选择的时候为了避免过拟合,典型方法是正则化。
正则化是结构风险最小化策略的实现,是在经验风险上加上一个正则化项或罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。正则化的目的在于提高模型在未知测试数据上的泛化能力,避免参数过拟合。
正则化一般形式:
其中,第一项是经验风险,第二项是正则化项,为调整两者之间关系的系数。
正则化符合奥卡姆剃刀(Occam's razor)原理:即在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。
我们也可以从贝叶斯估计的角度来解释:将人对这个模型的先验知识融入到模型的学习当中,正则化项对应于模型的先验概率。可以假设复杂的模型有较小的先验概率,而简单的模型有较大的先验概率。
我们来做个试验亲自验证一下:
fromsklearn.linear_modelimportLinearRegression
fromsklearn.preprocessingimportPolynomialFeatures
defpoly_model(degree,x_train,y_train,x_test,y_test):
poly=PolynomialFeatures(degree=degree)
x_train_poly=poly.fit_transform(x_train)
regressor=LinearRegression()
regressor.fit(x_train_poly,y_train)
xx=np.linspace(0,26,100)
xx=xx.reshape(xx.shape[0],1)
xx_poly=poly.transform(xx)
yy=regressor.predict(xx_poly)
print(f"Degree={degree}score:",regressor.score(poly.transform(x_test),y_test))
plt.scatter(x_train,y_train)
plt.plot(xx,yy,label=f'Degree={degree}')
plt.axis([0,25,0,25])
plt.legend()
regressor=LinearRegression()
x_train=[[6],[8],[10],[14],[18]]
y_train=[[7],[9],[13],[17.5],[18]]
x_test=[[6],[8],[11],[16]]
y_test=[[8],[12],[15],[18]]
poly_model(degree=1,x_train=x_train,y_train=y_train,x_test=x_test,y_test=y_test)
poly_model(degree=2,x_train=x_train,y_train=y_train,x_test=x_test,y_test=y_test)
poly_model(degree=4,x_train=x_train,y_train=y_train,x_test=x_test,y_test=y_test)

可以看到,当模型复杂度很低(Degree=1)时,模型不仅没有对训练集上的数据有良好的拟合状态,而且在测试集上也表现平平,这种情况叫做欠拟合(Underfitting)。
但是,当我们一味追求很高的模型复杂度(Degree=4),尽管模型几乎完全拟合了所有的训练数据,模型也变得非常波动,这种情况叫做过拟合(Overfitting)。以上这两种情况都是缺乏模型泛化力的表现。
正则化常用的方法有L1正则化和L2正则化。
L1正则化通过惩罚参数的L1范数来限制模型的复杂度,能够产生稀疏模型,常用于特征选择和降维。L2正则化通过惩罚参数的L2范数来限制模型的复杂度,能够有效防止模型过拟合,但不能产生稀疏模型。
L2正则化与L1正则化有着相似的作用,但是二者在实现方式和应用场景上有所区别。在选择正则化方法时,需要根据具体问题的特点来进行选择。
L1正则化/Lasso
L1正则化将系数w的L1范数作为惩罚项加到损失函数上,由于正则项非零,这就迫使那些弱的特征所对应的的系数变成0。因此L1正则化往往会使学到的模型很稀疏(系数w经常为0),这个特性使得L1正则化成为一种很好的特征选择方法。
fromsklearn.linear_modelimportLasso
poly=PolynomialFeatures(degree=4)
x_train_poly4=poly.fit_transform(x_train)
x_test_poly4=poly.fit_transform(x_test)
lasso=Lasso()
lasso.fit(x_train_poly4,y_train)
print("Lasso",lasso.score(x_test_poly4,y_test))
Lasso 0.8388926873604381
我们使用4次多项式特征,但是换成Lasso模型检验L1范数正则化后的性能和参数,从模型评分来看,相比于普通4次多项式回归模型在测试集上的表现,默认配置的Lasso模型性能提高了大约1%。
L2正则化/Ridge
与L1范数正则化略有不同的是,L2范数正则化则在原优化目标的基础上,增加了参数向量的L2范数的惩罚项。为了使新优化目标最小化,这种正则化方法的结果会让参数向量中的大部分元素都变得很小,压制了参数之间的差异性。而这种压制参数之间差异性的L2正则化模型,通常被称为Ridge。
fromsklearn.linear_modelimportRidge
ridge=Ridge()
ridge.fit(x_train_poly4,y_train)
print('Ridge',ridge.score(x_test_poly4,y_test))
Ridge 0.8374201759366455
相比于普通4次多项式回归模型在测试集上的表现,默认配置的Ridge模型性能有所提升;与普通4次多项式回归模型不同的是,Ridge模型拟合后的参数之间差异非常小。
Part3总结
最后,我们做下回顾和总结:
数据规范化 是指将数据转换为方便机器处理的格式。简单的数据规范化例如将字符串数据转换为数字数据、将不同单位的数据转换为相同单位、将时间数据转换为统一的格式等。高级的数据规范化是进行更加复杂的数据处理和转换,例如归一化、标准化等。
- 归一化(Min-Max标准化) 是为了消除指标之间的量纲影响,将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位,以解决数据指标之间的可比性,提高精度。
- 标准化(Z-score标准化) 是通过特征的均值(),标准差(),将特征缩放成一个标准的正态分布。
正则化(Regularization) 是指在模型训练中加入限制条件,以防止模型过拟合和提高模型的泛化能力。正则化常用的方法有L1正则化和L2正则化。在选择正则化方法时,需要根据具体问题的特点来进行选择。
《新语数据故事汇,数说新语》 科普数据科学、讲述数据故事,深层次挖掘数据价值。欢迎各位朋友投稿!
微信号|SnbDataStory
《新语数据故事汇,数说新语》