GPU与人工智能
全球数据总量及数据中心负载任务量大幅上涨,数据中心算力需求快速增长。随着人工智能等新技术发展,海量数据的产生及其计算处理成为数据中心发展关键。据IDC数据,全球数据总量预计由2021年的82.47 ZB上升至2026年的215.99 ZB,对应CAGR达21.24%。其中,大规模张量运算、矩阵运算是人工智能在计算层面的突出需求,高并行度的深度学习算法在视觉、语音和自然语言处理等领域上的广泛应用使得算力需求呈现指数级增长。
以模型中的参数数量衡量,大型语言模型的参数在过去五年中以指数级增长。随着参数量和训练数据量的增大,语言模型的能力会随着参数量的指数增长而线性增长,这种现象被称为Scaling Law。但当模型的参数量大于一定程度的时候,模型能力会 突 然 暴 涨, 模 型 会 突 然 拥 有 一 些 突 变 能 力(Emergent Ability),如推理能力、无标注学习能力等。例如GPT之前的大语言模型主流是深度神经网络驱动,参数在数十亿水平,而ChatGPT达到1750亿参数。
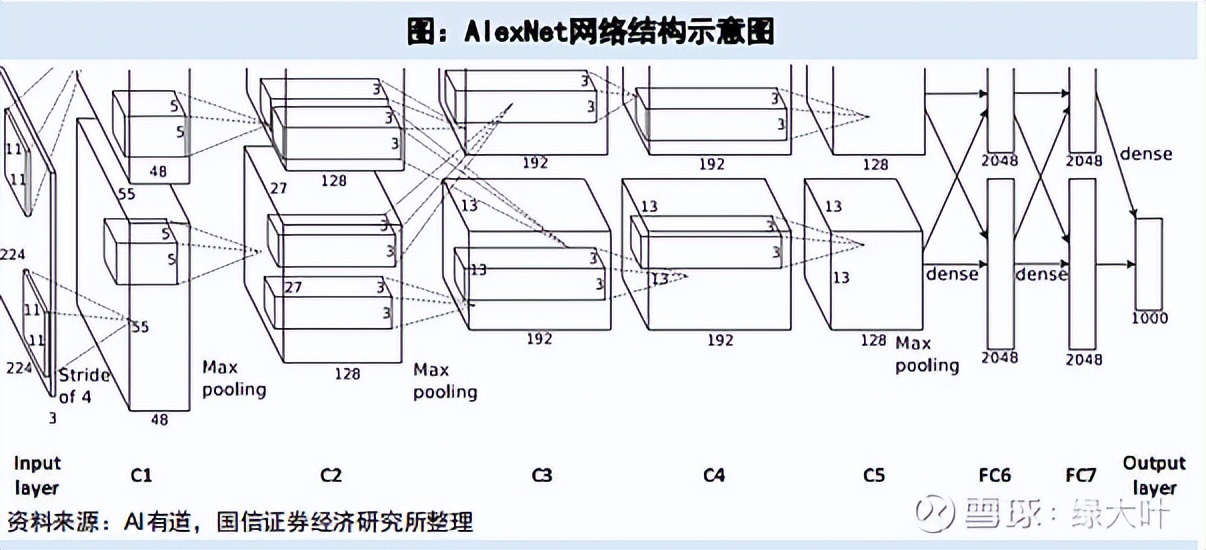
随着互联网时代对于数据量的积累,大数据背景下神经网络成为机器学习的重要方法。2012年,深度卷积神经网络AlexNet凭借在图像分类识别领域中性能的大幅提升及错误率的大幅降低,成为人工智能的标志性事件。
在此过程中,其训练者Alex Krizhevsky创新性地使用英伟达GPU成功训练了性能有突破性提升的深度神经网络AlexNet,从而开启了新的人工智能时代。英伟达GPU伴随着深度学习模型训练和推理所需要的大量算力成为了人工智能时代的新基础设施。
ChatGPT引领全球人工智能浪潮,人工智能发展需要AI芯片作为算力支撑。从2018年起,OpenAI开始发布生成式预训练语言模型GPT以来,GPT更新换代持续提升模型及参数规模,当时GPT-1参数量只有1.17亿个。l2020年,OpenAI发布GPT-3预训练模型,参数量为1750亿个,使用1000亿个词汇的语料库进行训练,在文本分析、机器翻译、机器写作等自然语言处理应用领域表现出色。
l2022年12月,OpenAI发布基于GPT-3.5的聊天机器人模型ChatGPT,具有出色的文字聊天和复杂语言处理能力。ChatGPT的发布引爆AI领域,海内外科技公司纷纷宣布发布大语言模型,而用户爆发式增长对大语言模型的算力需求同样带来挑战,AI芯片成为算力提升关键。
lAI芯片又称AI加速器或计算卡,是专门用于处理人工智能应用中大量计算任务的模块。随着数据海量增长、算法模型趋向复杂、处理对象异构、计算性能要求高,AI芯片能够在人工智能的算法和应用上做针对性设计,高效处理人工智能应用中日渐多样繁杂的计算任务。
当前主流的AI芯片主要包括图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、神经拟态芯片(NPU)等。其中,GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。ASIC属于为AI特定场景定制的芯片。另外,中央处理器(CPU)是计算机的运算和控制核心,是信息处理、程序运行的最终执行单元,是计算机的核心组成部件。
lGPU在训练负载中具有绝对优势。据IDC数据,1H21中国AI芯片市场份额中,GPU占比高达91.9%,依然是实现数据中心加速的首选。GPU通用型较强、适合大规模并行运算,设计和制造工艺成熟,适用于高级复杂算法和通用性人工智能平台。
GPU(Graphics Processing Unit,图形处理器)能够并行计算的性能优势满足深度学习需求。GPU最初承担图像计算任务,目标是提升计算机对图形、图像、视频等数据的处理性能,解决CPU在图形图像领域处理效率低的问题。由于GPU能够进行并行计算,其架构本身较为适合深度学习算法。因此,通过对GPU的优化,能够进一步满足深度学习大量计算的需求。
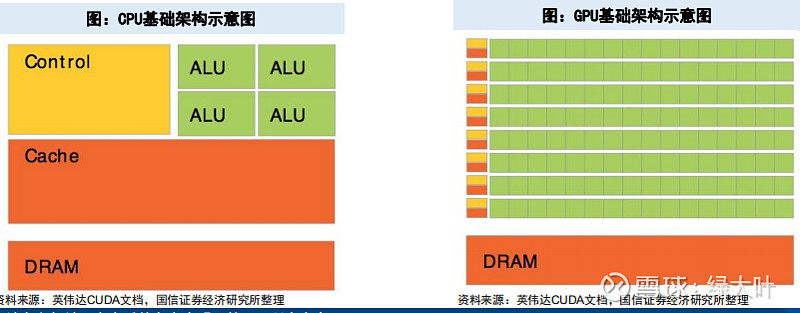
典型GPU架构以及GPU与CPU的异同
典型GPU架构包括:
Ø一个GPU由多个Processor Cluster组成
Ø一个Processor Cluster由多个Streaming Multiprocessors组成
Ø一个Streaming Multiprocessors里面可能包含多个Core,Streaming Multiprocessors中一定数量的Core共享一级缓存,多个Streaming Multiprocessors共享二级缓存
lCPU(Central Processing Unit,中央处理器)是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU的结构主要包括运算器(ALU,Arithmetic and Logic Unit)、控制单元(CU,Control Unit)、寄存器(Register)、高速缓存器(Cache)和之间通讯的数据、控制及状态的总线。
l相同点:CPU和GPU都是运算的处理器,在架构组成上都包括3个部分:运算单元ALU、控制单元Control和缓存单元Cache。
l不同点:CPU为低延时设计,擅长处理逻辑复杂、串行的计算任务。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理,因此CPU内部结构复杂,擅长逻辑控制和通用类型数据运算。
GPU为高吞吐设计,为大规模数据并行计算任务量身定做。GPU面对的则是类型高度统一的、相互无依赖的大规模数据和相对纯净的计算环境。GPU采用数量众多的计算单元和超长流水线,擅长大规模并发运算。
英伟达是人工智能计算领域领导者,独立GPU出货量位居市场第一 l英伟达(NVIDIA)成立于1993年,总部位于美国加利福尼亚州圣克拉拉,是一家人工智能计算公司。公司作为加速计算的先驱,由最初专注于PC图形计算,扩展到了各类重要大型计算密集型领域。公司利用其GPU产品和架构为科学计算、人工智能(AI)、数据科学、自动驾驶汽车(AV)、机器人、元宇宙和3D互联网应用创建平台。
据Omdia数据,在2022年全球半导体收入前十公司中,英伟达排名第八,市场份额约3.5%。
l公司在全球独立GPU市场及数据中心市场加速芯片中处于领先地位。据Jon Peddie Research(JPR)数据,4Q22英伟达独立GPU出货量占比为82%,位居市场第一;PC GPU出货量占比为17%,仅次于全球最大的处理器厂商英特尔凭借其桌面端集成显卡优势占据的最大份额。
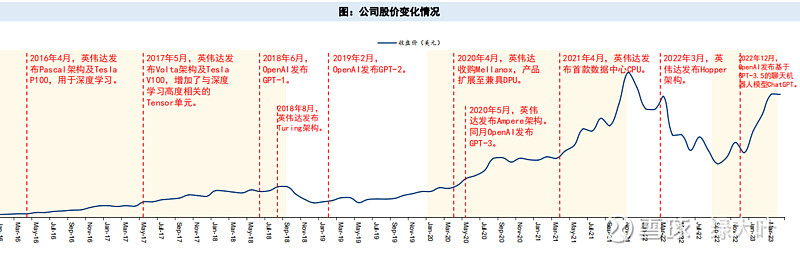
股价经历2016-2018年、2020-2021年、2022年9月以来三轮快速增长
公司发展历史及收并购历史
l1993年,黄仁勋等人共同创立了英伟达。1994年,公司与SGS-Thomson合作,为其制造单芯片图形用户界面加速器。1995年,公司推出首款产品NV1;而1998年发布的RIVA *NTT**巩固了公司在开发功能强大的图形适配器方面的市场地位。此外,公司1998年与台积电签约建立战略合作关系,台积电开始协助制造公司产品。
l1999年,公司发明了图形处理器,全球首款GPU GeForce 256诞生。公司发明GPU定义了现代计算机图形学,由此走上了重塑行业的道路,确立了在该领域的领导地位。而此后,公司GPU产品出货量快速增长,2002年处理器出货量累计超1亿台,2006年累计出货超5亿台,2011年累计出货超10亿台。
l2006年,公司推出用于通用GPU(GPGPU)计算的CUDA平台。软件开发者可以通过该平台使用C语言编写GPU片上程序完成复杂的计算。从G80开始,英伟达GPU体系结构已经全面支持通用编程,GPU实际脱离图像处理的单一用途,成为了真正的通用GPU。
l自015年以后,随着AI浪潮迅猛推进,公司业务不断多元化,向数据中心、游戏、移动设备、汽车电子等市场发展。2017年,公司专为数据中心和高性能计算打造Tesla V100GPU,为DGX系列AI超级计算机提供支持。FY23,公司来自于数据中心业务领域的收入超过游戏领域业务,成为公司最大的收入来源。
公司通过收购不断巩固业务实力,拓展业务边界。较为代表性的重要收购事件是收购3dfx公司。3dfx是一家专门研发与生产显卡与3D芯片的公司,在二十世纪九十年代末一直是显卡芯片的领导者,但3dfx因破产最终被公司所收购。此外,公司通过收购多家图形渲染相关公司,巩固自身在传统图形计算优势领域的实力。2020年,公司收购高性能互联技术领域龙头Mellanox,产品布局从GPU扩展至兼具DPU
2016年,英伟达CEO黄仁勋向OpenAI亲手交付了第一台NVIDIA DGX-1AI超级计算机,这也是支持ChatGPT大型语言模型突破背后的引擎。
l2018年,OpenAI向微软提出“建立一个可以永远改变人机交互方式的人工智能系统”的想法。为了构建支持OpenAI项目的超级计算机,微软斥资数亿美元,在Azure云计算平台上将几万个NVIDIA A100芯片连接在一起,并改造了服务器机架。在这台超算上,OpenAI训练的模型不断强大,为后来诞生ChatGPT奠定基础。
l2022年11月,微软宣布与英伟达联手构建“世界上最强大的AI超级计算机之一”,来处理训练和扩展AI所需的巨大计算负载。这台超级计算机基于微软的Azure云基础设施,使用了数以万计个Nvidia H100和A100 Tensor Core GPU,及其Quantum-2 InfiniBand网络平台,可用于研究和加速DALL-E和Stable Diffusion等生成式AI模型。
2023年3月14日,微软宣布加强和英伟达的合作,将GPU从此前的A100升级到H100,推出专门针对人工智能开发的全新的ND H100 v5虚拟机
摘自-国信证券-电子行业AI+系列专题报告(二): 复盘英伟达的AI发展之路