上个月,科罗拉多州博览会颁发了一项艺术奖,以表彰由人工智能(AI)系统生成的作品——评委不知道。
社交媒体还看到了人工智能从文本描述中产生的奇怪图像的爆炸,例如“一个shiba inu的脸融入厨房长凳上的面包侧面,数字艺术”。
或者也许是“约翰内斯·弗美尔的《戴珍珠耳环的女孩》风格的海獭”:

人工智能“OpenAI”作品: 约翰内斯·弗美尔的《戴珍珠耳环的女孩》风格的海獭。
你可能想知道这里发生了什么。作为研究人类和人工智能之间创造性合作的人,我可以告诉你,在头条新闻和模因背后,一场根本性的革命正在进行中——具有深远的社会、艺术、经济和技术影响。
他们如何做到
你可以说,这场革命始于2020年6月,当时一家名为OpenAI的公司在人工智能方面取得了重大突破,创建了GPT-3,该系统可以以比之前更复杂的方式处理和生成语言。你可以就任何主题与它进行对话,要求它写一篇研究文章或一个故事,总结文本,写一个笑话,并做几乎所有可以想象的语言任务。
阅读更多:机器人正在创造图像和讲笑话。关于基础模型和下一代人工智能的5件事
2021年,GPT-3的一些开发人员将手转向图像。他们训练了一个关于数十亿对图像和文本描述的模型,然后使用它从新描述中生成新图像。他们称该系统为DALL-E,并于2022年7月发布了一个经过大量改进的新版本DALL-E 2。
与GPT-3一样,DALL-E 2是一个重大突破。它可以从自由格式的文本输入中生成高度详细的图像,包括有关样式和其他抽象概念的信息。
例如,在这里,我要求它说明“Mind in Bloom”一词,结合了Salvador Dalí、Henri Matisse和Brett Whiteley的风格。

人工智能“DALL-E从”作品DALL-E从:提示“Mind in Bloom”中生成的图像,结合了多种艺术家风格
竞争对手进入现场
自DALL-E 2推出以来,出现了一些竞争对手。一个是免费使用但质量较低的DALL-E Mini(独立开发,现在更名为Craiyon),它是模因内容的热门来源。

人工智能“Craiyon”作品:提示“Darth Vader在阳光明媚的日子里在外面骑三轮车”中生成的图像
大约在同一时间,一家名为Midjourney的小型公司发布了一款与DALL-E 2功能更接近的型号。虽然能力仍然不如DALL-E 2,但Midjourney已经适合有趣的艺术探索。正是在Midjourney,Jason Allen创作了赢得科罗拉多州艺术博览会比赛的艺术品。
谷歌也有一个名为Imagen的文本到图像模型,据说它比DALL-E和其他模型产生更好的结果。然而,Imagen尚未发布以供更广泛地使用,因此很难评估谷歌的说法。
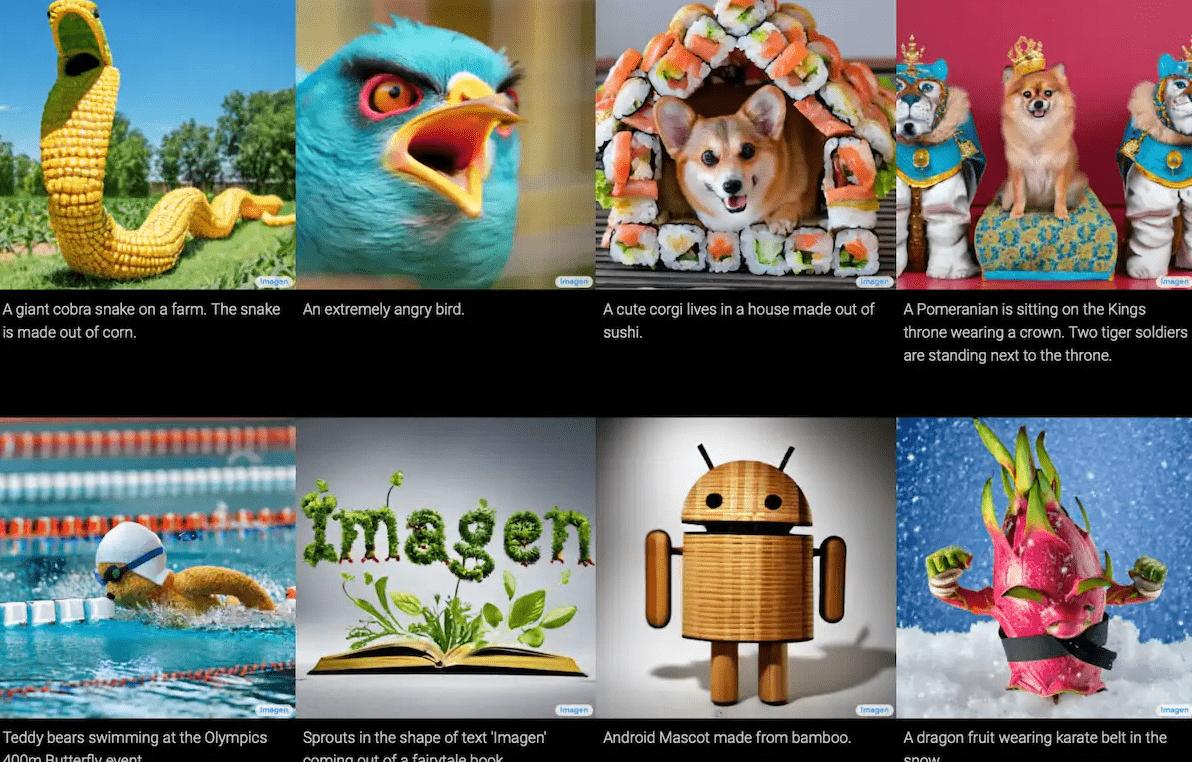
人工智能“Imagen”作品:文本到图像模型生成的图像,以及生成它们的文本
人工智能意味着人类的创造力的终结?
只需几行文本并单击按钮,即可生成任何类型的视觉内容、图像或视频,这意味着什么?什么时候可以使用GPT-3生成电影脚本,用DALL-E 2生成电影动画呢?
展望未来,当社交媒体算法不仅为您的提要策划内容,而且生成内容时,这意味着什么?当这种趋势在几年内与元宇宙相遇,并且虚拟现实世界是实时生成的,只为你创造时,那该怎么办?
我们生活在一个因从用户那里提取屏幕时间而蓬勃发展的注意力经济中;在一个自动化驱动公司利润但不一定更高的工资的经济中,艺术作为内容商品化;在越来越难以区分真实和假的社会环境中;生活在太容易地编码我们训练的人工智能模型中偏见的社会技术结构中。在这种情况下,人工智能很容易造成伤害。
我们如何引导这些新的人工智能技术朝着有利于人们的方向前进?我相信做到这一点的一种方法是设计与人类合作而不是取代人类的人工智能。|Metaborn·元宇宙宠物数字复生工程转