问题1:Bert里面为什么用layer normalization,而不用batch normalization,分别讲一下这两个啥意思。
Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
区别:LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的长度,因此可以用于batchsize为1和RNN中sequence的normalize操作。
问题2:Bert里面为什么Q,K,V要用三个不同的矩阵,用一个不是也行吗。
如果使用相同的矩阵,相同量级的情况下,q 和 k进行点积的值会是最大的,进行softmax的加权平均后,该词所占的比重会最大,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示,而使用不同的QKV后,会很大程度减轻上述的影响。
问题3:Bert和transformer讲一下。
1 bert只有transformer的encode 结构 ,是生成语言模型
2 bert 加入了输入句子的 mask机制,在输入的时候会随机mask
3 模型接收两个句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子 可以做对话机制的应答。
4 在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。

CV竞赛 -- 图像检索与物体检测
⏰ 8月3日开课,限时1元福利秒杀
限额90名,速抢>>https://www.julyedu.com/course/getDetail/457
问题4:AUC指标讲一下。
AUC:AUC是ROC曲线下面的面积,AUC可以解读为从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。
AUC反映的是分类器对样本的排序能力。
AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。
问题5:Precision和Recall讲一下
精确度(precision)/查准率:TP/(TP+FP)=TP/P 预测为真中,实际为正样本的概率。
召回率(recall)/查全率:TP/(TP+FN) 正样本中,被识别为真的概率。
问题6:GBDT和Xgboost的区别。
1、GBDT是机器学习算法,XGBoost是该算法的一种工程实现
2、XGBoost在使用CART作为基学习器时,加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。
3、GBDT在模型训练时只使用了损失函数的一阶导数信息,XGBoost对损失函数进行二阶泰勒展开,可以同时使用一阶和二阶导数
4、XGBoost支持自定义损失函数,增强了模型的扩展性
5、传统的GBDT采用CART作为基学习器(也叫基分类器),XGBoost支持多种类型的基学习器,包括树模型(gbtree和dart,dart为一种引入dropout的树模型)和线性模型(gblinear),默认为gbtree
6、传统的GBDT在每轮迭代时使用全部的数据,XGBoost支持对数据进列采样,即特征采样,有利于防止过拟合,同时可以减少计算量,提高训练的效率
7、传统的GBDT不能支持缺失值的处理(必须填充),XGBoost支持缺失值的处理,能够自动学习出缺失值的分裂方向(无需填充)

CV竞赛 -- 图像检索与物体检测
⏰ 8月3日开课,限时1元福利秒杀
限额90名,速抢>>https://www.julyedu.com/course/getDetail/457
问题7:Xgboost叶子结点的值怎么计算的。
XGBoost目标函数最终推导形式如下:
利用一元二次函数求最值的知识,当目标函数达到最小值Obj*时,每个叶子结点的权重为wj*。 具体公式如下:
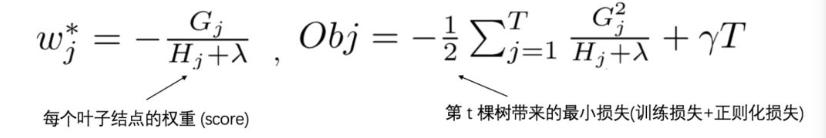
问题8:LightGBM对于Xgboost有什么改进。
模型精度:XGBoost和LightGBM相当。
训练速度:LightGBM远快于XGBoost。(快百倍以上,跟数据集有关系)
内存消耗:LightGBM远小于XGBoost。(大约是xgb的五分之一)
缺失值特征:XGBoost和LightGBM都可以自动处理特征缺失值。
分类特征:XGBoost不支持类别特征,需要OneHot编码预处理。LightGBM直接支持类别特征。
LightGBM在XGBoost上主要有3方面的优化。
1、Histogram算法:直方图算法。
2、GOSS算法:基于梯度的单边采样算法。
3、EFB算法:互斥特征*绑捆**算法。
问题9:防止过拟合的方式。
降低模型复杂度
增加更多的训练数据:使用更大的数据集训练模型
数据增强
正则化:L1、L2、添加BN层
添加Dropout策略
Early Stopping
问题10:Adam讲一下。
Adam算法即自适应时刻估计方法(Adaptive Moment Estimation),能计算每个参数的自适应学习率。
这个方法不仅存储了AdaDelta先前平方梯度的指数衰减平均值,而且保持了先前梯度M(t)的指数衰减平均值,这一点与动量类似。
Adam实际上就是将Momentum和RMSprop集合在一起,把一阶动量和二阶动量都使用起来了。
进大厂是大部分程序员的梦想,而进大厂的门槛也是比较高的。刷题,也成为面试前的必备环节。
七妹给大家准备了“武功秘籍”,七月在线干货组继19年出的两本书《名企AI面试100题》和《名企AI面试100篇》后,又整理出《机器学习十大算法系列》、《2021年最新大厂AI面试题 Q3版》两本图书,不少同学通过学习拿到拿到dream offer。
为了让更多AI人受益,七仔现把电子版免费送给大家,希望对你的求职有所帮助。如果点赞和点在看的人数较多,我会后续整理资料并分享答案给大家。
以下4本书,电子版,添加VX:julyedufu77(或七月在线任一老师)回复“088” 领取!
