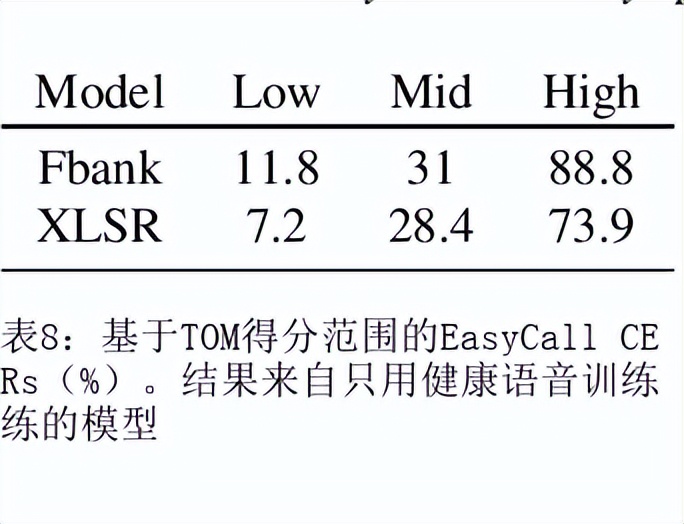
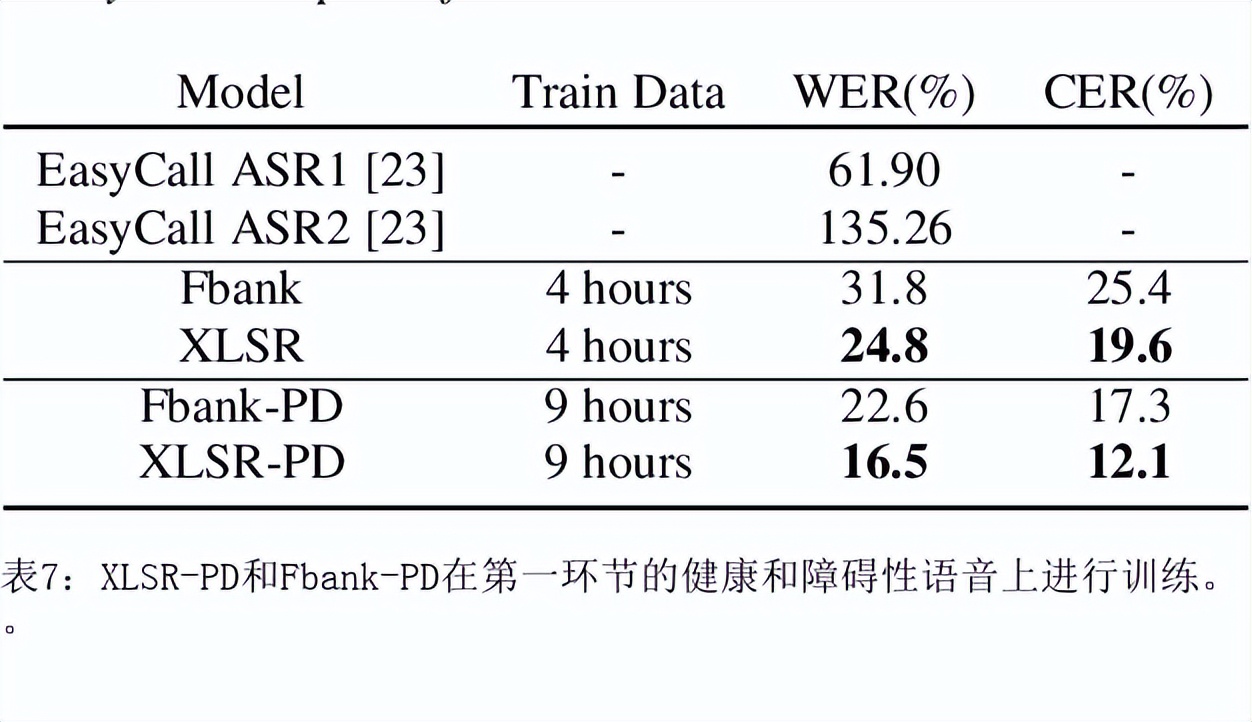
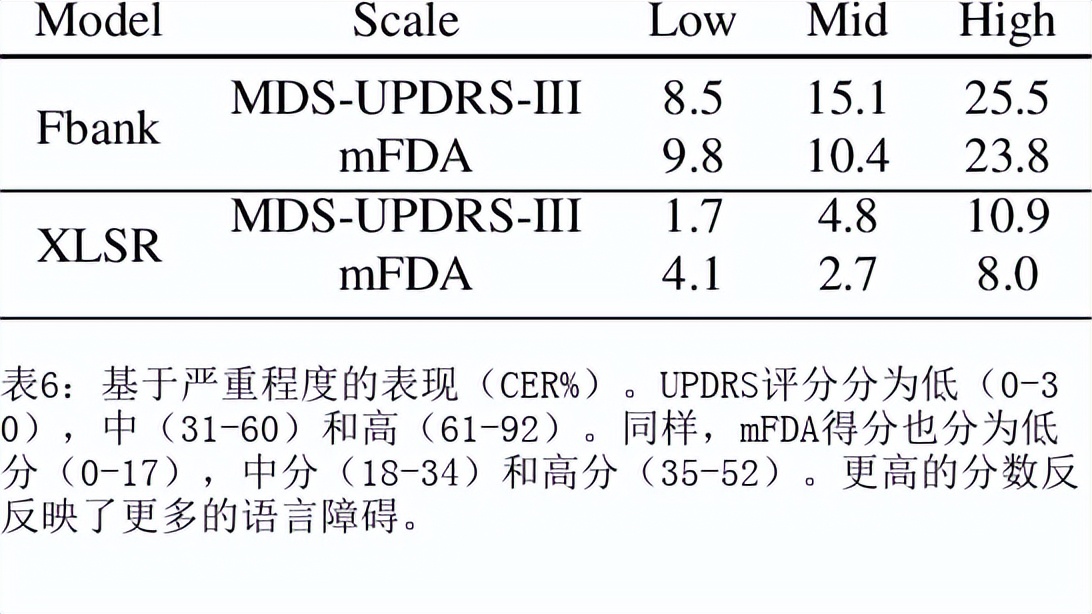
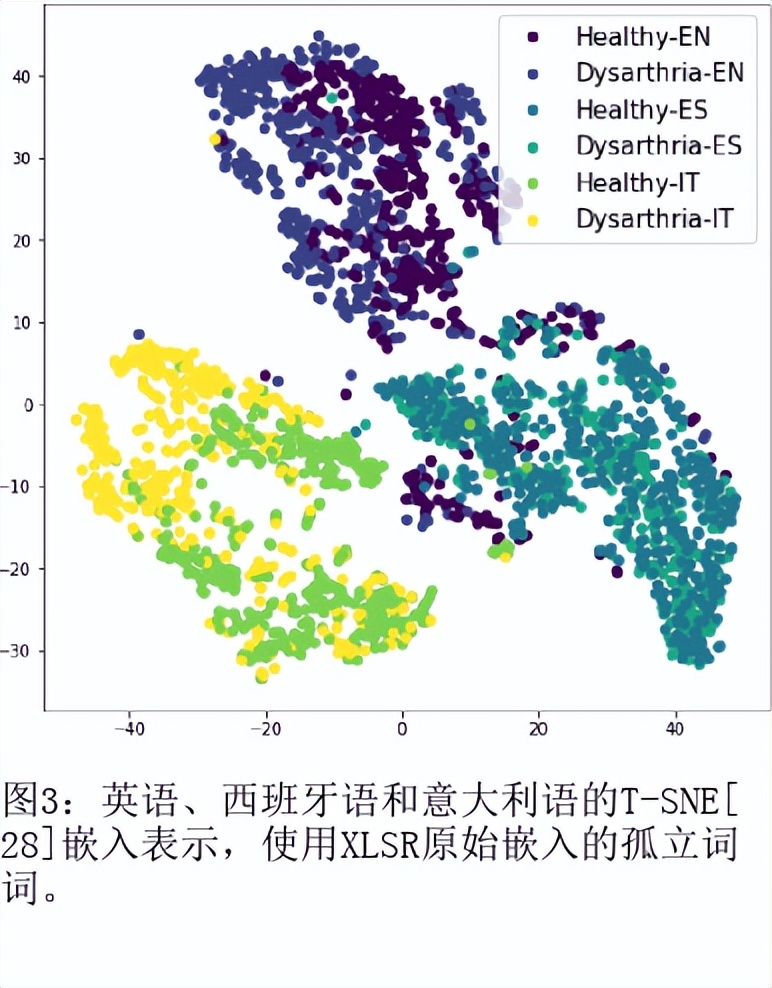
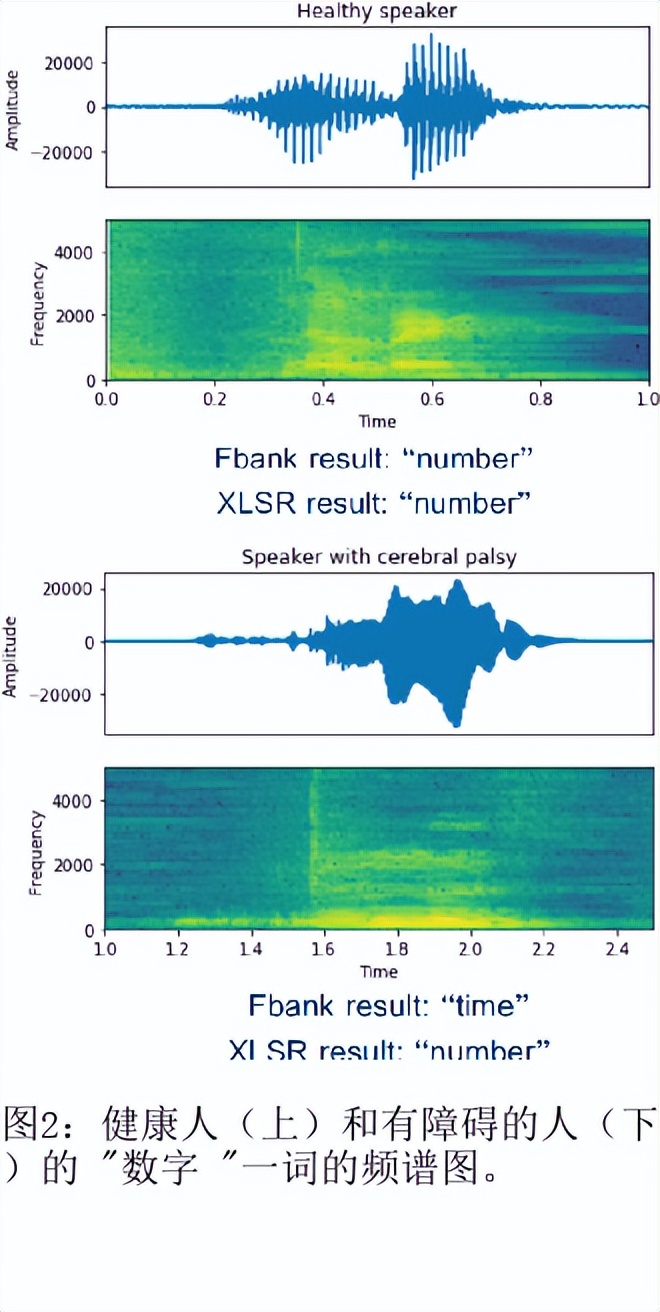
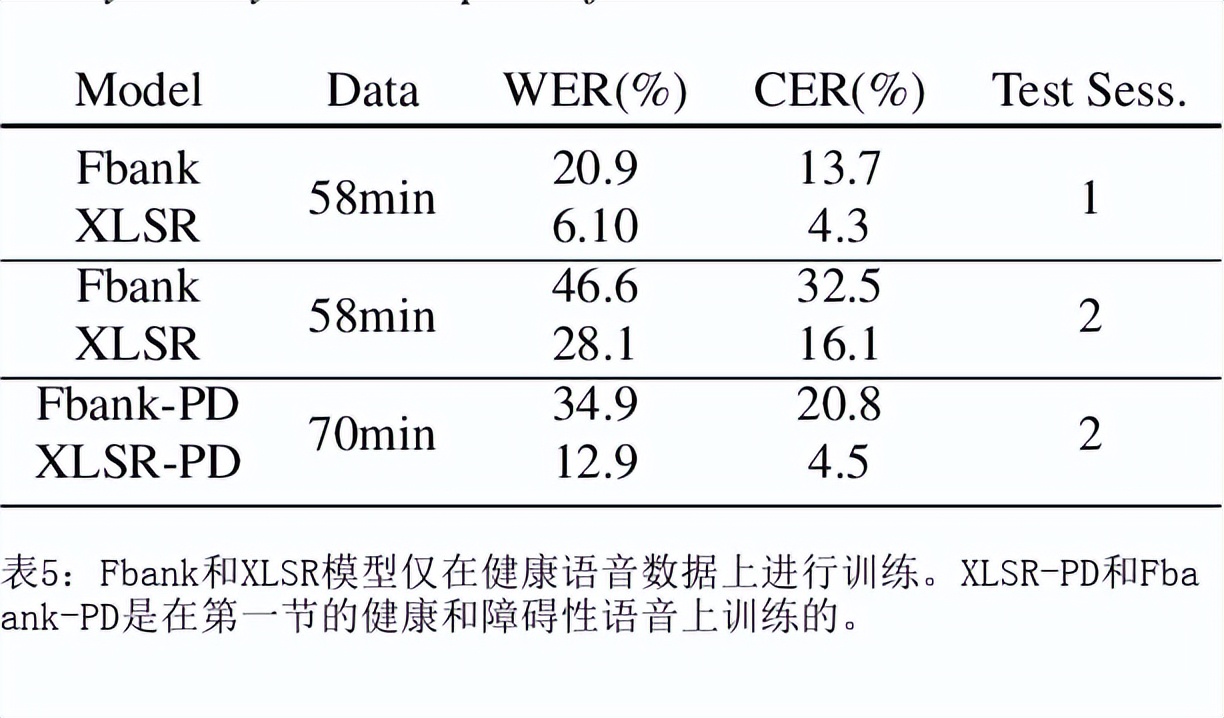
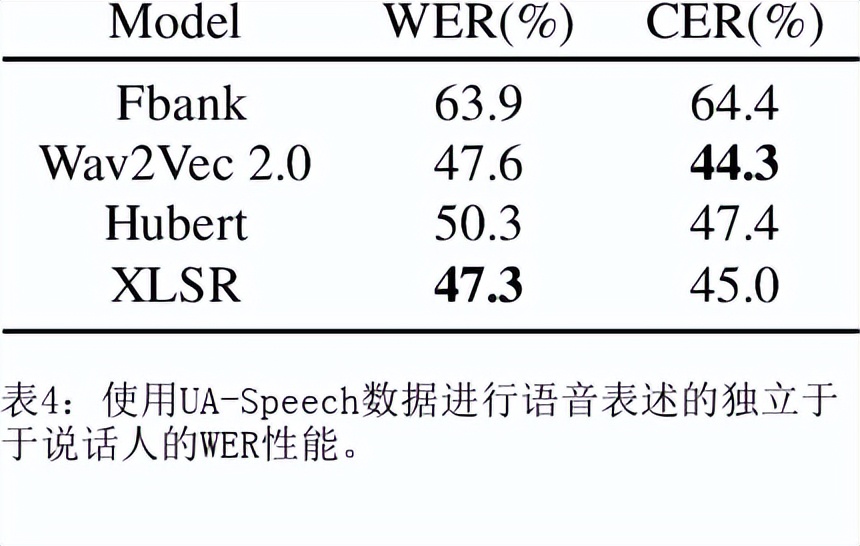
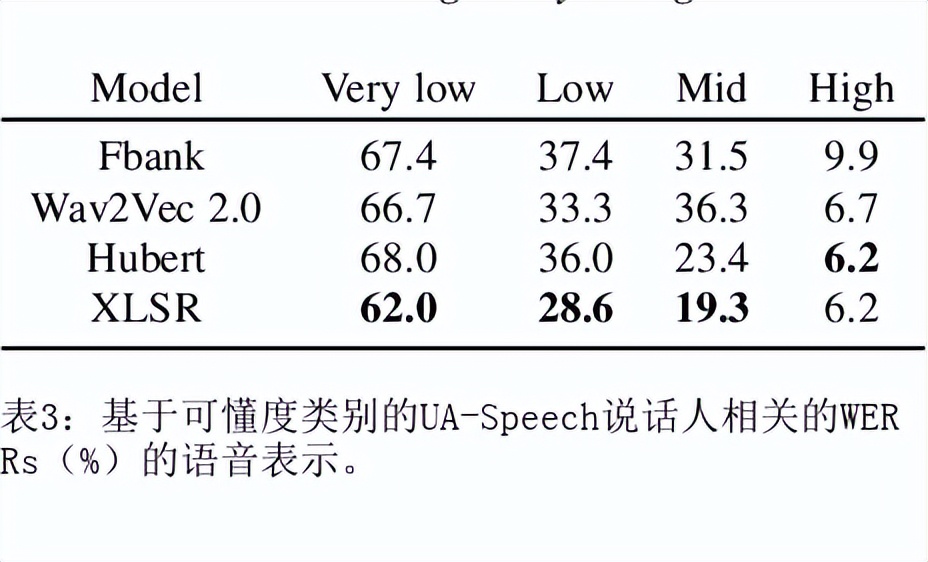
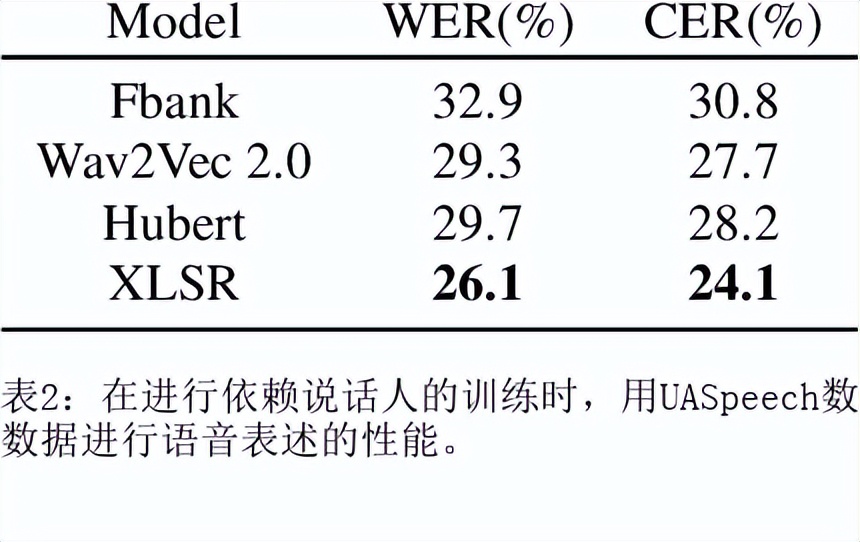
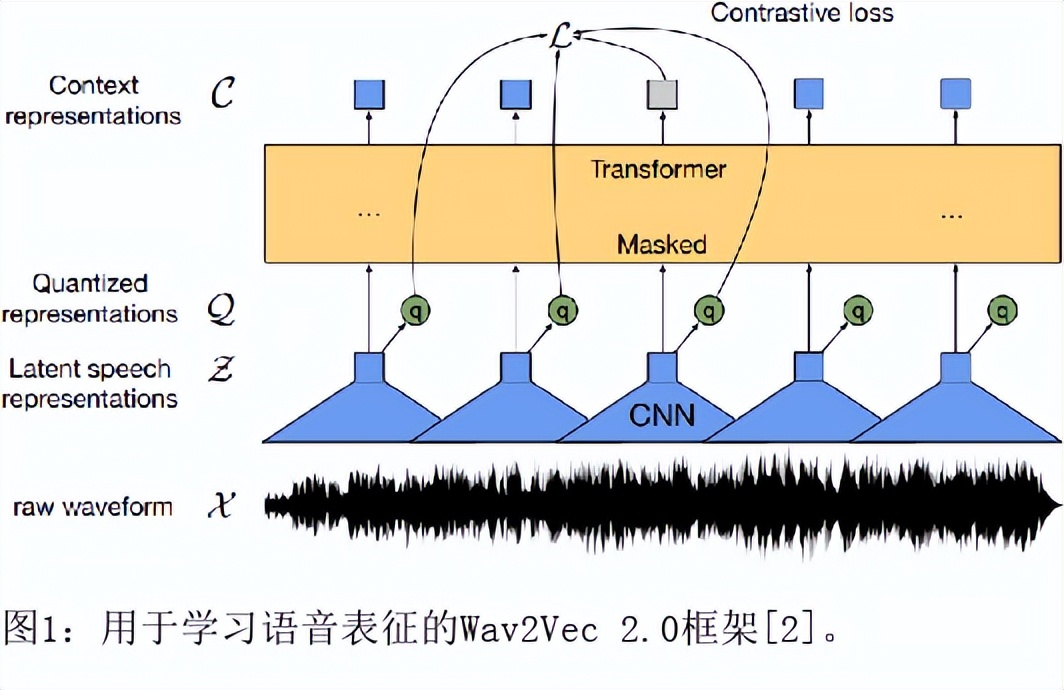
目前最先进的自动语音识别(ASR)系统在健康的语音上表现良好。然而,对受损语音的表现仍然是一个问题。目前的研究探讨了使用Wav2Vec自我监督的语音表征作为特征来训练ASR系统对障碍性语音的有用性。由于语音的几个方面,如发音、语调和声调都可能受到损害,因此障碍性语音识别特别困难。具体来说,我们用从Wav2Vec、Hubert和跨语言的XLSR模型中提取的特征来训练一个声学模型。结果表明,在大量无标签数据上预训练的语音代表可以提高单词错误率(WER)的表现。特别是,来自多语言模型的特征比过滤库(Fbank)或在单一语言上训练的模型导致更低的误码率。在患有脑瘫引起的构音障碍的英语使用者(UASpeech语料库)、患有帕金森构音障碍的西班牙语使用者(PC-GITA语料库)和患有瘫痪构音障碍的意大利语使用者(EasyCallcorpus)身上观察到了改进。与使用Fbank特征相比,基于XLSR的特征使UASpeech、PC-GITA和EasyCall语料库的误报率分别降低了6.8%、22.0%和7.0%。
《Cross-lingual Self-Supervised Speech Representations for Improved Dysarthric Speech Recognition》
论文地址:http://arxiv.org/abs/2204.01670v1