1.导读
本文主要是针对推荐系统中 用户兴趣偏好随时间发生变化 的情况进行建模,那么 对于不同任务,用户的兴趣变化应该也是有差异的 ,作者提出 用户生命周期 的概念,将其 分为多个阶段 ,以此 表达用户在不同任务上随时间变化的兴趣偏好 。在上述概念的基础上提出 阶段自适应网络STAN 来对生命周期阶段建模。
- 首先根据学习到的用户偏好识别潜在的用户生命周期阶段
- 然后使用阶段表征来提高多任务学习性能
2.阶段划分
对于不同的任务,用户在不同的阶段,他们的偏好是不同的,也就是说不同阶段,用户的点击,转化,停留时间等的分布是不同的。
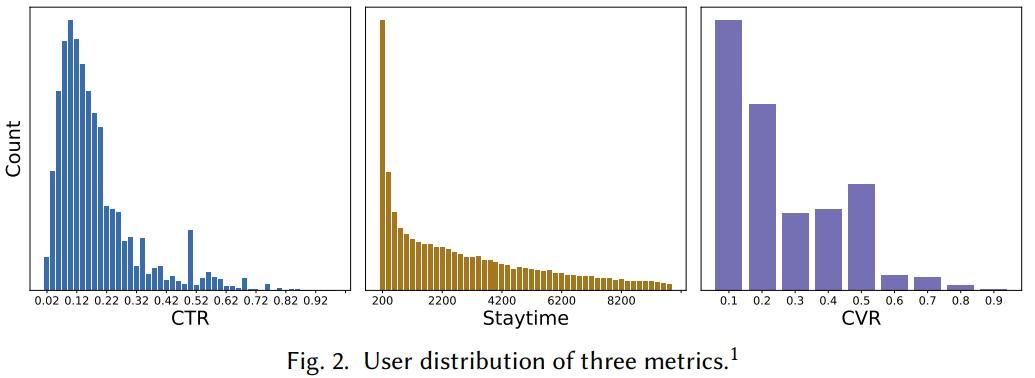
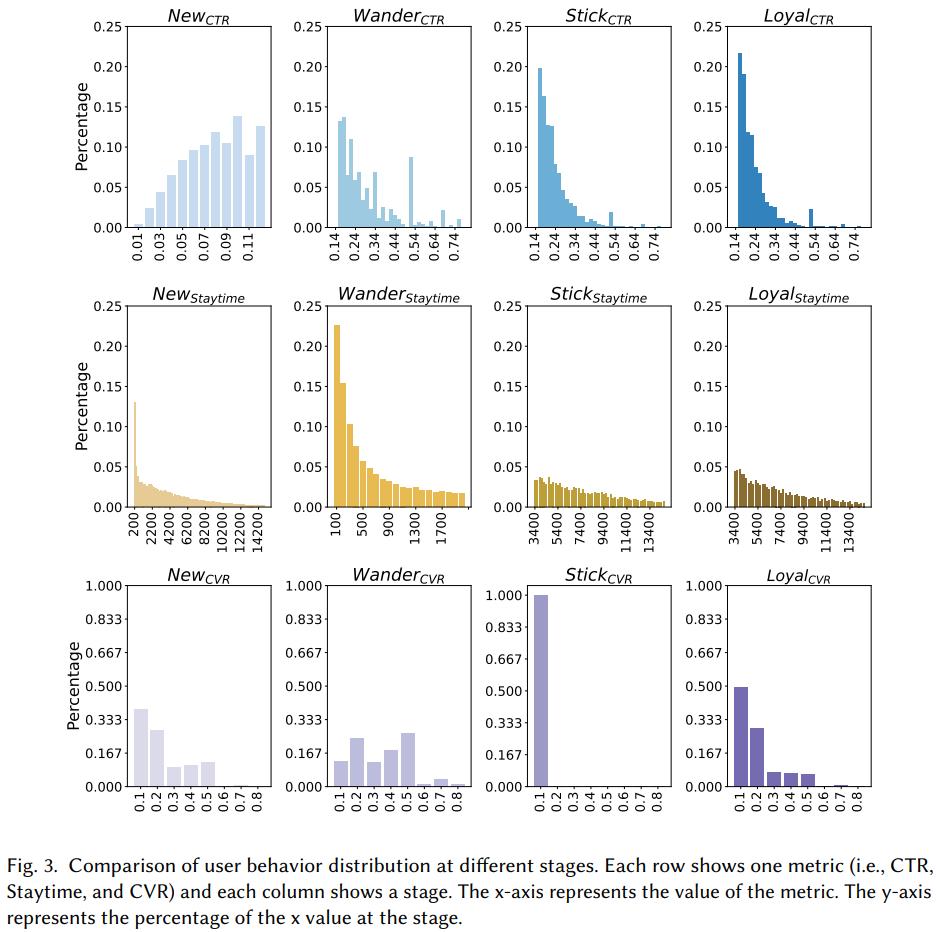
如图2所示,是作者在电商平台搜集的数据,统计用户在不同任务上的总体分布,基于不同指标的中位数作者将用户生命周期分为四个阶段: new,wander,stick和loyal ,每个用户只能在一个阶段中。划分后发现:
- 在new阶段,用户的点击率较低,而停留时间和转化的分布和总体分布基本一致
- 在wander阶段,用户的停留时间较短
- 在sitck阶段,用户的点击率和停留时间较大,但是转化率很低
- 在loyal阶段,用户表现为稳定的点击,停留和转化习惯,这说明用户对这个平台还是比较满意的
所以说,用户在不同的阶段关注的点是不一样的。
3.定义和符号
令整个数据集为
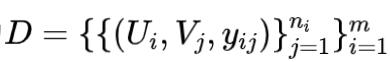
,包含m个用户,每个用户曝光了n_i个item, U和V分别表示用户和item的embedding矩阵, 标签集合为
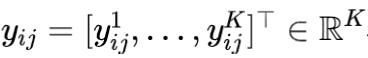
表示K个任务的标签. 用户i的整体偏好可以计算为

4.方法
4.1 多任务预测网络
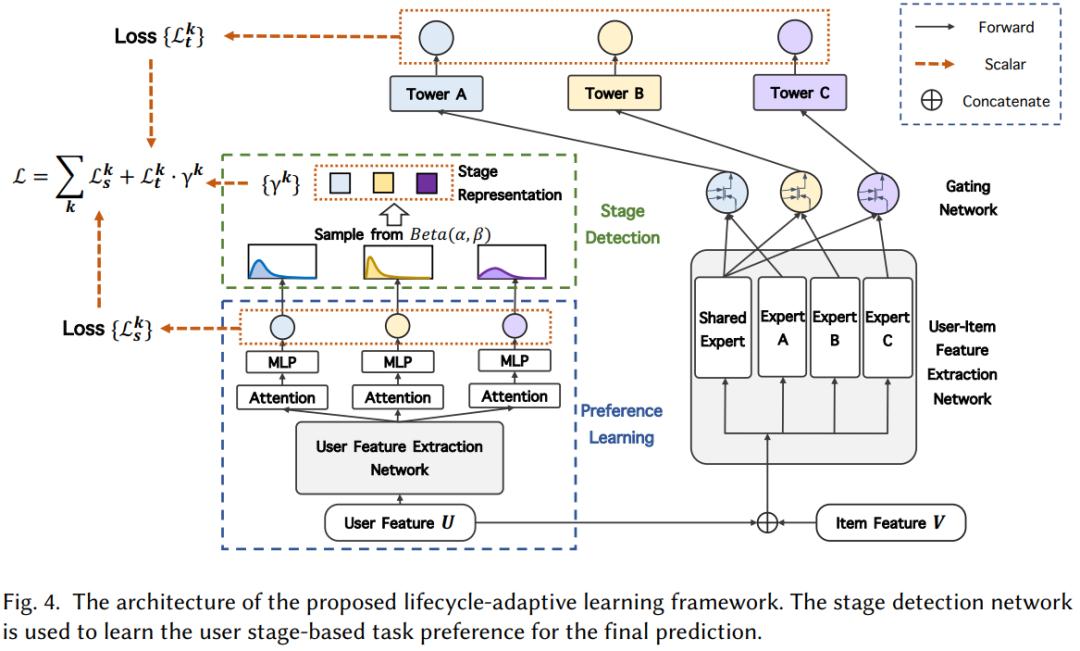
如图所示为本文的网络框架, 通常多任务学习都会采用一个或多个共享专家网络, 如ple, mmoe, 这些专家网络可以学到公共知识, 并且通过注意力机制来得到任务特定的信息. 但是这些 共享专家网络的更新会受不同任务之间的依赖性和数据分布的差异的影响 . (其实现在也有一些解决方式, 比如不同任务梯度正交约束, gradnorm之类的), 那我们来看看本文是怎么做的吧.
基于PLE方法,但是不适用共享专家网络从而减轻有害的参数干扰,, 使用vec()表示矩阵向量化, 矩阵向量化的操作过程很简单, 如下所示, 对于用户和item的表征矩阵U和V可以向量化得到


对象量化后的数据进行特征提取, 过程如下所示, k表示第k个任务, H()将任务公共信息和任务特定信息结合, 通过softmax得到的权重对H()结合的表征进行加权求和.

得到任务k的预测值为
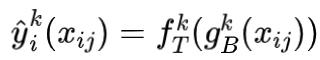
, , 其中f表示每个任务k的预测层, 损失函数可以构造为

, 这里的η是对不同任务的加权, 权重表示不同任务的重要程度, 但是用户在不同阶段关注点是不同的, 因此这里如果使用一个固定的η是不合适的, 因此有了本文的后续用户偏好学习模块和*在用潜**户阶段表征模块.
4.2 用户偏好学习
由于没有明确的标准来区分用户的阶段,因此本文从用户的行为中推断出用户的阶段信息。用户阶段可以用一组用户对所有相关任务的偏好来描述,这里提出用户偏好学习来学习用户在这些任务上的偏好信息.
该模块由三个构建块组成:
- (i)从输入的用户特征U中提取更具代表性特征的 用户特征提取网络 ,
- (ii) 特定任务的表征学习单元 为特定任务生成用户的潜在偏好表征,
- (iii) 预测单元 ,其利用任务特定embedding来预测每个任务的值。
用户特征提取网络是通过自注意力机制,挖掘用户特征之间的关系表是为,从而发掘用户的兴趣偏好,公式如下,
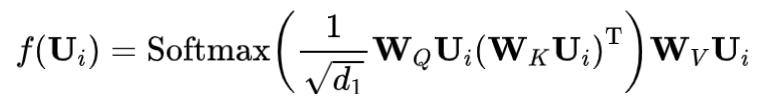
特定任务的表征学习单元是在已经得到的的基础上,为每个任务进行加权得到具体任务的表征,公式如下,
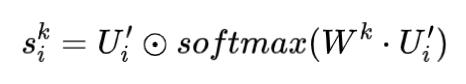
最后的预测模块,就是基于上述得到的特定任务的embedding进行预测得到,这里就直接使用MLP进行预测公式如下,

为了减少行为波动带来的偏差,本文采用过去几天的数据,算标签的平均值得到伪标签,然后和预测值计算损失函数

,其中


4.3 *在用潜**户阶段检测
用户偏好输出为y^k,当训练数据较少的时候,预测值的信息量也较少,因此设计了*在用潜**户阶段表征模块对打分进行调整,得到更加可信的偏好gamma^k。
假设y^k满足Beta分布

,即对于每个任务都有对应于beta分布的α和β参数,这两个参数分别表示用户执行动作和不执行动作的次数,如点击,转化等。
α和β通过算法1进行学习,训练样本的增加,学习到的用户对不同任务的偏好将更加可靠。然后联系前文说的η权重,采用这边的γ进行动态加权,对当前不感兴趣的任务在梯度回传时降低重要性。

4.4 损失函数
损失函数自然也包含两部分, 一个是本身就需要做的不同任务的预测(常用的交叉熵损失),另一个用户属于不同阶段的预测 ,公式如下

5.结果

image.png
省流:
本文有意思的地方在于在推荐方法中考虑用户的生命周期,即不同的阶段,将整体数据中的用户划分为不同的阶段,在不同的阶段,用户对不同任务有不同的偏好,而这些不同的偏好可以使我们在多任务模型更新参数的时候更有侧重点,防止对一些不同要甚至是负向的梯度进行更新,导致模型效果变差。那主要做了以下几件事:
- 使用的多任务框架是比较常规的,不过没有共享专家网络,共享层过了就是各个任务的分支,去掉共享专家网络是为了减少不同任务之间的依赖性相互影响
- 无法显示得到用户当前处于什么阶段,因此预测用户当前对不同任务的偏好来得到用户属于哪个阶段,那为了预测更加鲁棒,这里的标签是一段时间的平均值构造伪标签。
- 并且为了增加预测值的信息量,尤其是在数据量较少的时候,作者假设各个任务都满足beta分布,然后基于预测分数和积累到现在的正负反馈构造beta分布,在该分布中采样得到加权系数
- 得到的加权系数用户对多任务框架中不同任务的损失函数进行加权,因为不同用户在不同阶段的偏好不同,则反映到损失函数上就是不同任务的损失函数的重要性不同,通过加权控制重要性。