大家好,我是老王,今天给大家介绍一款OCR工具,就是可以识别图片里的文字,提取出来。
这个呢还是很有用的,现在微信已经提供了这个功能,在微信里收到的图片,点击右键就有这个功能。但是呢,对于一些非微信上的图,想要识别文字,不能每次都发到微信里面吧?市面上有很多OCR工具,这些都需要联网,都是调用各大云服务提供商的免费额度,今天老王给大家介绍的这款工具略微不一样。
它主要有以下特性:
- 免费 :本项目所有代码开源,完全免费。
- 方便 :解压即用,离线运行,无需网络。
- 批量 :可批量导入处理图片,结果保存到本地 txt / md / jsonl 多种格式文件。也可以即时截屏识别。
- 高效 :采用 PaddleOCR-json C++ 识别引擎。只要电脑性能足够,通常比在线OCR服务更快。
- 精准 :默认使用PPOCR-v3模型库。除了能准确辨认常规文字,对手写、方向不正、杂乱背景等情景也有不错的识别率。可设置 忽略区域 排除水印、设置 文块后处理 合并排版段落,得到规整的文本。
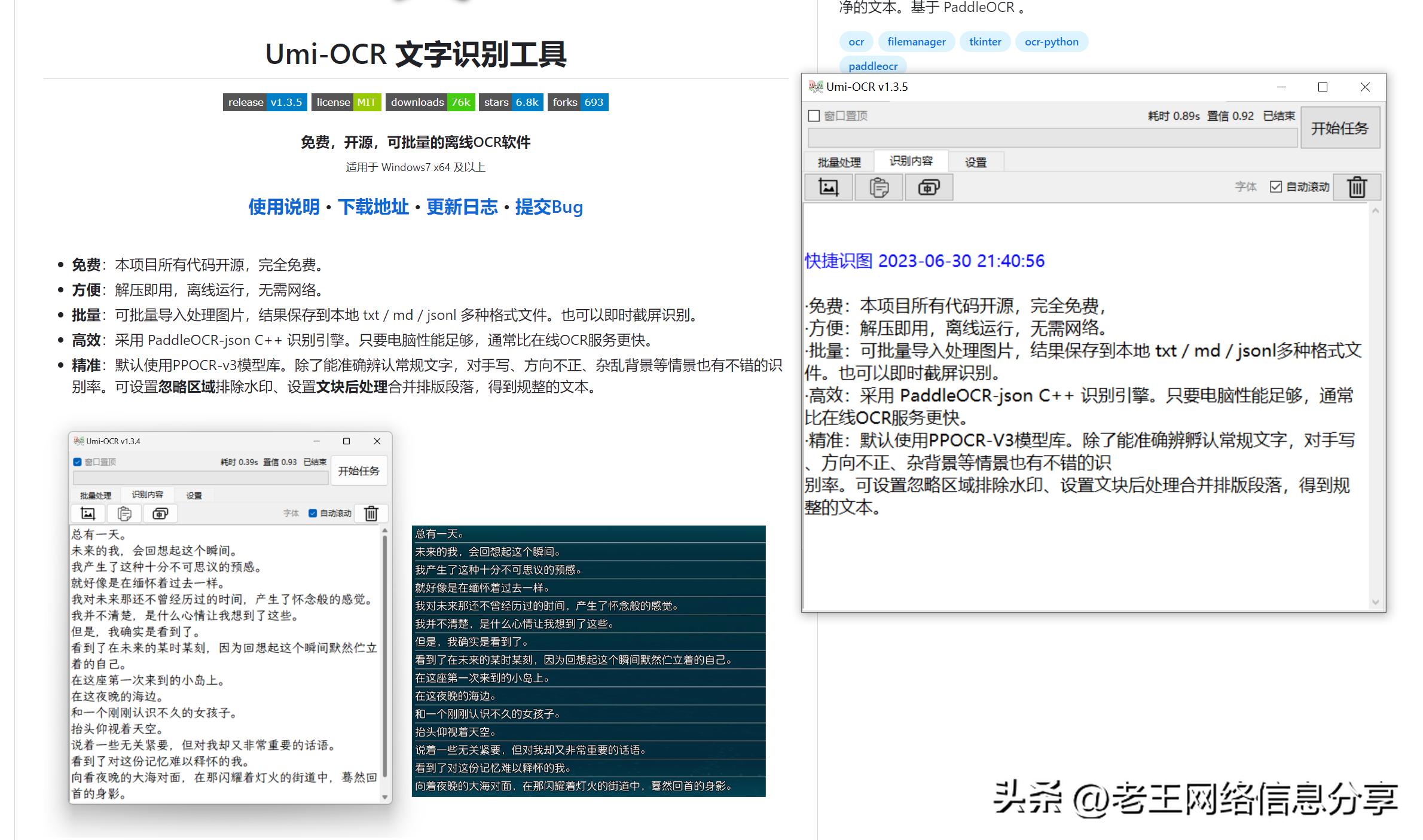
支持截图识别
支持截图识别,粘贴图片识别,批量识别,快捷键识别,简直强大的起飞了。
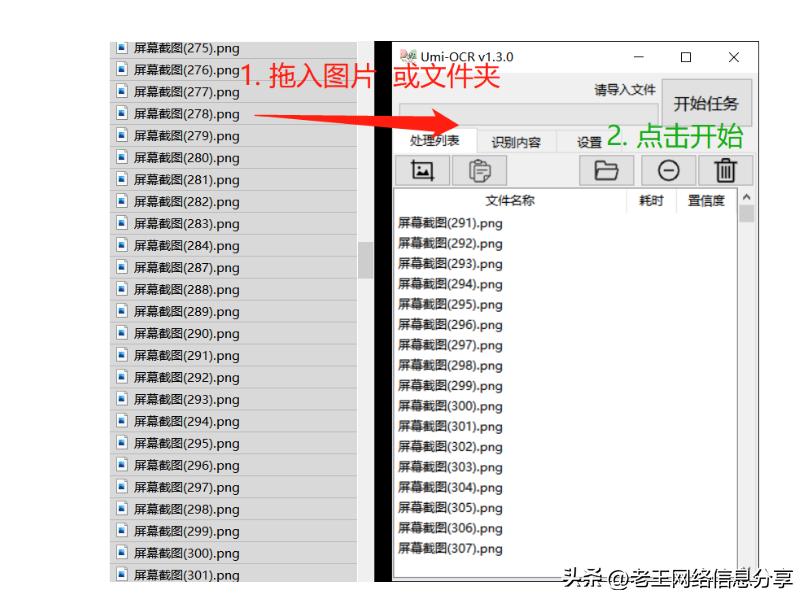
批量识别
还支持识别后自动排版

自动排版
最厉害的属离线识别了,也就是你断网也能使用,完全本地识别,这个简直了,大家还不快快用起来?还支持多国语言哦,不仅限于中英文。
最新版本:
v1.3.5主要更新:
- 新功能:复制识别结果后,可发送指定按键,以便联动唤起翻译器等工具。使用说明
- 新功能:命令行增加切换识别语言的指令。使用说明(指令7)
- 修Bug:修复了低配置机器上有概率误报超时 OCR init timeout: 5s 的问题。
- 调整:默认停止任务30秒后释放一次内存。
文件说明
软件本体:Umi-OCR.v1.3.5.7z(67MB),内置简体中文&英文通用识别库。软件(多国语言整合版):Umi-OCR.v1.3.5_ALL_languages.7z(118MB),内置多国语言识别库。
多国语言扩展包:Umi-OCR.v1.3_DLC_languages.7z(50MB),可向软件本体导入繁中,英,日,韩,俄,德,法 多国语言识别库。
目前在github上已经有6800+个star了,欢迎大家试用体验下。
好了,今天就介绍到这里,希望对大家能有所帮助。
直达链接:https://github.com/hiroi-sora/Umi-OCR