
一、集合入门总结
集合框架:
Java中的集合框架大类可分为Collection和Map;两者的区别:
1、Collection是单列集合;Map是双列集合
2、Collection中只有Set系列要求元素唯一;Map中键需要唯一,值可以重复
3、Collection的数据结构是针对元素的;Map的数据结构是针对键的。
泛型:
在说两大集合体系之前先说说泛型,因为在后面的集合中都会用到;
所谓的泛型就是:类型的参数化
泛型是类型的一部分,类名+泛型是一个整体
如果有泛型,不使用时,参数的类型会自动提升成Object类型,如果再取出来的话就需要向下强转,就可能发生类型转化异常(ClassCaseException);不加泛型就不能在编译期限定向集合中添加元素的类型,导致后期的处理麻烦。
下面就来对比加了泛型和不加泛型的区别:
package 好好学java;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test {
public static void main(String[] args) {
// 不加泛型,添加和遍历
List list = new ArrayList<>();
list.add(1);
list.add("123");
list.add("hello");
Iterator it = list.iterator();
while(it.hasNext()){
// 没有添加泛型,这里只能使用Object接收
Object obj = it.next();
System.out.println(obj);
}
}
}
package 好好学java;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test {
public static void main(String[] args) {
// 加泛型,添加和遍历
List<String> list = new ArrayList<String>();
list.add("123");
list.add("hello");
Iterator<String> it = list.iterator();
while(it.hasNext()){
// 因为添加了泛型,就说明集合中装的全部都是String类型的数据
// 所以这里用String类型接收,就不会发生异常,并且可以使用String的方法
String str = it.next();
System.out.println(str.length());
}
}
}
自定义带泛型的类:
package 好好学java;
public class Test {
// 自定义一个带有一个参数的泛型类,可以向传入什么类型就传入什么类型
public static void main(String[] args) {
// 进行测试, 传入一个String对象
Person<String> perStr = new Person<String>();
perStr.setT("我是字符串");
String str = perStr.getT();
System.out.println(str);
// 进行测试,传入一个Integer对象
Person<Integer> perInt = new Person<Integer>();
perInt.setT(100);
Integer intVal = perInt.getT();
System.out.println(intVal);
}
}
//自定义一个带有一个参数的泛型类
class Person<T>{
private T t;
void setT(T t){
this.t = t;
}
T getT(){
return t;
}
}
实现带有泛型的接口类型:
实现接口的同时, 指定了接口中的泛型类型. (定义类时确定);
public class GenericImpl1 implements GenericInter<String> {}
实现接口时, 没有指定接口中的泛型类型.此时, 需要将该接口的实现类定义为泛型类.接口的类型需要在创建实现类对象时才能真正确定其类型. (始终不确定类型, 直到创建对象时确定类型);
public class GenericImpl2<T> implements GenericInter<T> {}
泛型的通配符(?):
上限限定:比如定义方法的时候出现,public void getFunc(List<? extends Animal> an),
那么表示这里的参数可以传入Animal,或者 Animal的子类
下限限定: 比如定义方法的时候出现,public void getFunc(Set<? super Animal> an ),
那么表示这里的参数可以传入Animal,或者Animal的父类
使用泛型的注意点:
1、泛型不支持基本数据类型
2、泛型不支持继承,必须保持前后一致(比如这样是错误的:List<Object> list = new ArrayList<String>();
Collection体系:
ollection包括两大体系,List和Set
List的特点:
存取有序,有索引,可以根据索引来进行取值,元素可以重复
Set的特点:
存取无序,元素不可以重复
List:
下面有ArrayList,LinkedList,Vector(已过时)
集合的的最大目的就是为了存取;List集合的特点就是存取有序,可以存储重复的元素,可以用下标进行元素的操作
ArrayList: 底层是使用数组实现,所以查询速度快,增删速度慢
package 好好学java;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test {
// 使用ArrayList进行添加和遍历
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("接口1");
list.add("接口2");
list.add("接口3");
// 第一种遍历方式,使用迭代器
Iterator<String> it = list.iterator();
while(it.hasNext()){
String next = it.next();
System.out.println(next);
}
System.out.println("-------------------");
// 第二种遍历方式,使用foreach
for (String str : list){
System.err.println(str);
}
}
}
LinkedList:是基于链表结构实现的,所以查询速度慢,增删速度快,提供了特殊的方法,对头尾的元素操作(进行增删查)。
使用LinkedList来实现栈和队列;栈是先进后出,而队列是先进先出
package com.xiaoshitou.classtest;
import java.util.LinkedList;
/**
* 利用LinkedList来模拟栈
* 栈的特点:先进后出
* @author Beck
*
*/
public class MyStack {
private LinkedList<String> linkList = new LinkedList<String>();
// 压栈
public void push(String str){
linkList.addFirst(str);
}
// 出栈
public String pop(){
return linkList.removeFirst();
}
// 查看
public String peek(){
return linkList.peek();
}
// 判断是否为空
public boolean isEmpty(){
return linkList.isEmpty();
}
}
package 好好学java;
public class Test {
public static void main(String[] args) {
// 测试栈
StackTest stack = new StackTest();
stack.push("我是第1个进去的");
stack.push("我是第2个进去的");
stack.push("我是第3个进去的");
stack.push("我是第4个进去的");
stack.push("我是第5个进去的");
// 取出
while (!stack.isEmpty()){
String pop = stack.pop();
System.out.println(pop);
}
// 打印结果
/*我是第5个进去的
我是第4个进去的
我是第3个进去的
我是第2个进去的
我是第1个进去的*/
}
}
LinkedList实现Queue:
package 好好学java;
import java.util.LinkedList;
/**
* 利用linkedList来实现队列
* 队列: 先进先出
* @author Beck
*
*/
public class QueueTest {
private LinkedList<String> link = new LinkedList<String>();
// 放入
public void put(String str){
link.addFirst(str);
}
// 获取
public String get(){
return link.removeLast();
}
// 判断是否为空
public boolean isEmpty(){
return link.isEmpty();
}
}
package 好好学java;
public class Test {
public static void main(String[] args) {
// 测试队列
QueueTest queue = new QueueTest();
queue.put("我是第1个进入队列的");
queue.put("我是第2个进入队列的");
queue.put("我是第3个进入队列的");
queue.put("我是第4个进入队列的");
// 遍历队列
while (!queue.isEmpty()){
String str = queue.get();
System.out.println(str);
}
// 打印结果
/*我是第1个进入队列的
我是第2个进入队列的
我是第3个进入队列的
我是第4个进入队列的*/
}
}
Vector:因为已经过时,被ArrayList取代了;它还有一种迭代器通过vector.elements()获取,判断是否有元素和取元素的方法为:hasMoreElements(),nextElement()。
package 好好学java;
import java.util.Enumeration;
import java.util.Vector;
public class Test {
public static void main(String[] args) {
Vector<String> vector = new Vector<String>();
vector.add("搜索");
vector.add("vector");
vector.add("list");
Enumeration<String> elements = vector.elements();
while (elements.hasMoreElements()){
String nextElement = elements.nextElement();
System.out.println(nextElement);
}
}
}
Set:
Set集合的特点:元素不重复,存取无序,无下标
Set集合下面有:HashSet,LinkedHashSet,TreeSet
HashSet存储字符串:
package 好好学java;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Test {
public static void main(String[] args) {
// 利用HashSet来存取
Set<String> set = new HashSet<String>();
set.add("我的天");
set.add("我是重复的");
set.add("我是重复的");
set.add("welcome");
// 遍历 第一种方式 迭代器
Iterator<String> it = set.iterator();
while(it.hasNext()){
String str = it.next();
System.out.println(str);
}
System.out.println("--------------");
for (String str : set){
System.out.println(str);
}
// 打印结果,重复的已经去掉了
/*我的天
welcome
我是重复的
--------------
我的天
welcome
我是重复的*/
}
那哈希表是怎么来保证元素的唯一性的呢,哈希表是通过hashCode和equals方法来共同保证的。
哈希表的存储数据过程(哈希表底层也维护了一个数组):
根据存储的元素计算出hashCode值,然后根据计算得出的hashCode值和数组的长度进行计算出存储的下标;如果下标的位置无元素,那么直接存储;如果有元素,那么使用要存入的元素和该元素进行equals方法,如果结果为真,则已经有相同的元素了,所以直接不存;如果结果假,那么进行存储,以链表的形式存储。
演示HashSet来存储自定义对象:
package 好好学java;
public class Person {
// 属性
private String name;
private int age;
// 构造方法
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
// 要让哈希表存储不重复的元素,就必须重写hasCode和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
// getter & setter
...
}
package 好好学java;
import java.util.HashSet;
import java.util.Set;
public class Test {
public static void main(String[] args) {
// 利用HashSet来存取自定义对象 Person
Set<Person> set = new HashSet<Person>();
set.add(new Person("张三", 12));
set.add(new Person("李四", 13));
set.add(new Person("王五", 22));
set.add(new Person("张三", 12));
// 遍历
for (Person p : set){
System.out.println(p);
}
// 结果:向集合中存储两个张三对象,但是集合中就成功存储了一个
/*Person [name=王五, age=22]
Person [name=李四, age=13]
Person [name=张三, age=12]*/
}
}
所以在向HashSet集合中存储自定义对象时,为了保证set集合的唯一性,那么必须重写hashCode和equals方法。
LinkedHashSet:
是基于链表和哈希表共同实现的,所以具有存取有序,元素唯一
package 好好学java;
import java.util.LinkedHashSet;
public class Test {
public static void main(String[] args) {
// 利用LinkedHashSet来存取自定义对象 Person
LinkedHashSet<Person> set = new LinkedHashSet<Person>();
set.add(new Person("张三", 12));
set.add(new Person("李四", 13));
set.add(new Person("王五", 22));
set.add(new Person("张三", 12));
// 遍历
for (Person p : set){
System.out.println(p);
}
// 结果:向集合中存储两个张三对象,但是集合中就成功存储了一个,
// 并且存进的顺序,和取出来的顺序是一致的
/*Person [name=张三, age=12]
Person [name=李四, age=13]
Person [name=王五, age=22]*/
}
}
TreeSet:
特点:存取无序,元素唯一,可以进行排序(排序是在添加的时候进行排序)。
TreeSet是基于二叉树的数据结构,二叉树的:一个节点下不能多余两个节点。
二叉树的存储过程:
如果是第一个元素,那么直接存入,作为根节点,下一个元素进来是会跟节点比较,如果大于节点放右边的,小于节点放左边;等于节点就不存储。后面的元素进来会依次比较,直到有位置存储为止
TreeSet集合存储String对象
package 好好学java;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<String>();
treeSet.add("abc");
treeSet.add("zbc");
treeSet.add("cbc");
treeSet.add("xbc");
for (String str : treeSet){
System.out.println(str);
}
// 结果:取出来的结果是经过排序的
/*
abc
cbc
xbc
zbc*/
}
}
TreeSet保证元素的唯一性是有两种方式:
1、自定义对象实现Comparable接口,重写comparaTo方法,该方法返回0表示相等,小于0表示准备存入的元素比被比较的元素小,否则大于0;
2、在创建TreeSet的时候向构造器中传入比较器Comparator接口实现类对象,实现Comparator接口重写compara方法。
如果向TreeSet存入自定义对象时,自定义类没有实现Comparable接口,或者没有传入Comparator比较器时,会出现ClassCastException异常
下面就是演示用两种方式来存储自定义对象
package 好好学java;
public class Person implements Comparable<Person>{
// 属性
private String name;
private int age;
// 构造方法
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
// 要让哈希表存储不重复的元素,就必须重写hasCode和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
// getter & setter
...
@Override
public int compareTo(Person o) {
int result = this.age - o.age;
if (result == 0){
return this.name.compareTo(o.name);
}
return result;
}
}
package 好好学java;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
// 利用TreeSet来存储自定义类Person对象
TreeSet<Person> treeSet = new TreeSet<Person>();
// Person类实现了Comparable接口,并且重写comparaTo方法
// 比较规则是先按照 年龄排序,年龄相等的情况按照年龄排序
treeSet.add(new Person("张山1", 20));
treeSet.add(new Person("张山2", 16));
treeSet.add(new Person("张山3", 13));
treeSet.add(new Person("张山4", 17));
treeSet.add(new Person("张山5", 20));
for (Person p : treeSet){
System.out.println(p);
}
// 结果:按照comparaTo方法内的逻辑来排序的
/*
Person [name=张山3, age=13]
Person [name=张山2, age=16]
Person [name=张山4, age=17]
Person [name=张山1, age=20]
Person [name=张山5, age=20]
*/
}
}
另一种方式:使用比较器Comparator
package 好好学java;
public class Person{
// 属性
private String name;
private int age;
// 构造方法
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
// 要让哈希表存储不重复的元素,就必须重写hasCode和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
// getter & setter
...
}
package 好好学java;
import java.util.Comparator;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
// 利用TreeSet来存储自定义类Person对象
// 创建TreeSet对象的时候传入Comparator比较器,使用匿名内部类的方式
// 比较规则是先按照 年龄排序,年龄相等的情况按照年龄排序
TreeSet<Person> treeSet = new TreeSet<Person>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if (o1 == o2){
return 0;
}
int result = o1.getAge() - o2.getAge();
if (result == 0){
return o1.getName().compareTo(o2.getName());
}
return result;
}
});
treeSet.add(new Person("张山1", 20));
treeSet.add(new Person("张山2", 16));
treeSet.add(new Person("张山3", 13));
treeSet.add(new Person("张山4", 17));
treeSet.add(new Person("张山5", 20));
for (Person p : treeSet){
System.out.println(p);
}
// 结果:按照compara方法内的逻辑来排序的
/*
Person [name=张山3, age=13]
Person [name=张山2, age=16]
Person [name=张山4, age=17]
Person [name=张山1, age=20]
Person [name=张山5, age=20]
*/
}
}
比较器总结:
Collection体系总结:
- List : "特点 :" 存取有序,元素有索引,元素可以重复.
- ArrayList : 数组结构,查询快,增删慢,线程不安全,因此效率高.
- Vector : 数组结构,查询快,增删慢,线程安全,因此效率低.
- LinkedList : 链表结构,查询慢,增删快,线程不安全,因此效率高.
addFirst() removeFirst() getFirst()
- Set :"特点 :" 存取无序,元素无索引,元素不可以重复.
- HashSet : 存储无序,元素无索引,元素不可以重复.底层是哈希表.
请问 : 哈希表如何保证元素唯一呢 ? 底层是依赖 hashCode 和 equals 方法.
当存储元素的时候,先根据 hashCode + 数组长度 计算出一个索引,判断索引位置是否有元素.
如果没有元素,直接存储,如果有元素,先判断 equals 方法,比较两个元素是否相同,不同则存储,相同则舍弃.
我们自定义对象存储的元素一定要实现 hashCode 和 equals.
- LinkedHashSet : 存储有序,元素不可以重复.
- TreeSet : 存取无序, 但是可以排序 (自然排序), 元素不可以重复.
有两种排序方式 :
- 自然排序 :
我们的元素必须实现 Comparable 接口.可比较的.实现 CompareTo 方法.
- 比较器排序 :
我们需要自定义类,实现Comparetor接口,这个类就是比较器实现 compare 方法.
然后在创建 TreeSet 的时候,把比较器对象作为参数传递给 TreeSet.
Map:
Map是一个双列集合,其中保存的是键值对,键要求保持唯一性,值可以重复
键值是一一对应的,一个键只能对应一个值
Map的特点:是存取无序,键不可重复
Map在存储的时候,将键值传入Entry,然后存储Entry对象
其中下面有HashMap,LinkedHashMap和TreeMap
HashMap:
是基于哈希表结构实现的,所以存储自定义对象作为键时,必须重写hasCode和equals方法。存取无序的
下面演示HashMap以自定义对象作为键:
package 好好学java;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map.Entry;
import java.util.Set;
public class Test {
public static void main(String[] args) {
// 利用HashMap存储,自定义对象Person作为键
// 为了保证键的唯一性,必须重写hashCode和equals方法
HashMap<Person,String> map = new HashMap<Person,String>();
map.put(new Person("张三", 12), "JAVA");
map.put(new Person("李四", 13), "IOS");
map.put(new Person("小花", 22), "JS");
map.put(new Person("小黑", 32), "PHP");
map.put(new Person("张三", 12), "C++");
Set<Entry<Person, String>> entrySet = map.entrySet();
Iterator<Entry<Person, String>> it = entrySet.iterator();
while (it.hasNext()){
Entry<Person, String> entry = it.next();
System.out.println(entry.getKey() + "---" + entry.getValue());
}
// 结果:存入的时候添加了两个张三,如果Map中键相同的时候,当后面的值会覆盖掉前面的值
/*
Person [name=李四, age=13]---IOS
Person [name=张三, age=12]---C++
Person [name=小黑, age=32]---PHP
Person [name=小花, age=22]---JS
*/
}
}
LinkedHashMap:
用法跟HashMap基本一致,它是基于链表和哈希表结构的所以具有存取有序,键不重复的特性
下面演示利用LinkedHashMap存储,注意存的顺序和遍历出来的顺序是一致的:
package 好好学java;
import java.util.LinkedHashMap;
import java.util.Map.Entry;
public class Test {
public static void main(String[] args) {
// 利用LinkedHashMap存储,自定义对象Person作为键
// 为了保证键的唯一性,必须重写hashCode和equals方法
LinkedHashMap<Person,String> map = new LinkedHashMap<Person,String>();
map.put(new Person("张三", 12), "JAVA");
map.put(new Person("李四", 13), "IOS");
map.put(new Person("小花", 22), "JS");
map.put(new Person("小黑", 32), "PHP");
map.put(new Person("张三", 12), "C++");
// foreach遍历
for (Entry<Person,String> entry : map.entrySet()){
System.out.println(entry.getKey()+"==="+entry.getValue());
}
// 结果:存入的时候添加了两个张三,如果Map中键相同的时候,当后面的值会覆盖掉前面的值
// 注意:LinkedHashMap的特点就是存取有序,取出来的顺序就是和存入的顺序保持一致
/*
Person [name=张三, age=12]===C++
Person [name=李四, age=13]===IOS
Person [name=小花, age=22]===JS
Person [name=小黑, age=32]===PHP
*/
}
}

TreeMap:
给TreeMap集合中保存自定义对象,自定义对象作为TreeMap集合的key值。由于TreeMap底层使用的二叉树,其中存放进去的所有数据都需要排序,要排序,就要求对象具备比较功能。对象所属的类需要实现Comparable接口。或者给TreeMap集合传递一个Comparator接口对象。
利用TreeMap存入自定义对象作为键:
package 好好学java;
import java.util.Comparator;
import java.util.Map.Entry;
import java.util.TreeMap;
public class Test {
public static void main(String[] args) {
// 利用TreeMap存储,自定义对象Person作为键
// 自定义对象实现Comparable接口或者传入Comparator比较器
TreeMap<Person,String> map = new TreeMap<Person,String>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if (o1 == o2){
return 0;
}
int result = o1.getAge() - o2.getAge();
if (result == 0){
return o1.getName().compareTo(o2.getName());
}
return result;
}
});
map.put(new Person("张三", 12), "JAVA");
map.put(new Person("李四", 50), "IOS");
map.put(new Person("小花", 32), "JS");
map.put(new Person("小黑", 32), "PHP");
map.put(new Person("张三", 12), "C++");
// foreach遍历
for (Entry<Person,String> entry : map.entrySet()){
System.out.println(entry.getKey()+"==="+entry.getValue());
}
// 结果:存入的时候添加了两个张三,如果Map中键相同的时候,当后面的值会覆盖掉前面的值
// 注意:TreeMap 取出来的顺序是经过排序的,是根据compara方法排序的
/*
Person [name=张三, age=12]===C++
Person [name=小花, age=32]===JS
Person [name=小黑, age=32]===PHP
Person [name=李四, age=50]===IOS
*/
}
}
二、集合进阶总结
数组和第一类对象
无论使用的数组属于什么类型,数组标识符实际都是指向真实对象的一个句柄。那些对象本身是在内存
“堆”里创建的。堆对象既可“隐式”创建(即默认产生),亦可“显式”创建(即明确指定,用一个 new
表达式)。堆对象的一部分(实际是我们能访问的唯一字段或方法)是只读的length(长度)成员,它告诉
我们那个数组对象里最多能容纳多少元素。对于数组对象,“ []”语法是我们能采用的唯一另类访问方法。
对象数组和基本数据类型数组在使用方法上几乎是完全一致的。唯一的差别在于对象数组容纳的是句柄,而基本数据类型数组容纳的是具体的数值
public class ArraySize {
public static void main(String[] args) {
// Arrays of objects:
Weeble[] a; // Null handle
Weeble[] b = new Weeble[5]; // Null handles
Weeble[] c = new Weeble[4];
for (int i = 0; i < c.length; i++)
c[i] = new Weeble();
Weeble[] d = { new Weeble(), new Weeble(), new Weeble() };
// Compile error: variable a not initialized:
// !System.out.println("a.length=" + a.length);
System.out.println("b.length = " + b.length);
// The handles inside the array are
// automatically initialized to null:
for (int i = 0; i < b.length; i++)
System.out.println("b[" + i + "]=" + b[i]);
System.out.println("c.length = " + c.length);
System.out.println("d.length = " + d.length);
a = d;
System.out.println("a.length = " + a.length);
// Java 1.1 initialization syntax:
a = new Weeble[] { new Weeble(), new Weeble() };
System.out.println("a.length = " + a.length);
// Arrays of primitives:
int[] e; // Null handle
int[] f = new int[5];
int[] g = new int[4];
for (int i = 0; i < g.length; i++)
g[i] = i * i;
int[] h = { 11, 47, 93 };
// Compile error: variable e not initialized:
// !System.out.println("e.length=" + e.length);
System.out.println("f.length = " + f.length);
// The primitives inside the array are
// automatically initialized to zero:
for (int i = 0; i < f.length; i++)
System.out.println("f[" + i + "]=" + f[i]);
System.out.println("g.length = " + g.length);
System.out.println("h.length = " + h.length);
e = h;
System.out.println("e.length = " + e.length);
// Java 1.1 initialization syntax:
e = new int[] { 1, 2 };
System.out.println("e.length = " + e.length);
}
}
输出如下:
b.length = 5
b[0]=null
b[1]=null
b[2]=null
b[3]=null
b[4]=null
c.length = 4
d.length = 3
a.length = 3
a.length = 2
f.length = 5
f[0]=0
f[1]=0
f[2]=0
f[3]=0
f[4]=0
g.length = 4
h.length = 3
e.length = 3
e.length = 2
其中,数组 a 只是初始化成一个 null 句柄。此时,编译器会禁止我们对这个句柄作任何实际操作,除非已正
确地初始化了它。数组 b 被初始化成指向由 Weeble 句柄构成的一个数组,但那个数组里实际并未放置任何
Weeble 对象。然而,我们仍然可以查询那个数组的大小,因为 b 指向的是一个合法对象。
换言之,我们只知道数组对象的大小或容量,不知其实际容纳了多少个元素。
尽管如此,由于数组对象在创建之初会自动初始化成 null,所以可检查它是否为 null,判断一个特定的数组“空位”是否容纳一个对象。类似地,由基本数据类型构成的数组会自动初始化成零(针对数值类型)、 null(字符类型)或者false(布尔类型)
数组 c 显示出我们首先创建一个数组对象,再将 Weeble 对象赋给那个数组的所有“空位”。数组 d 揭示出
“集合初始化”语法,从而创建数组对象(用 new 命令明确进行,类似于数组 c),然后用 Weeble 对象进行
初始化,全部工作在一条语句里完成。
下面这个表达式:
a = d;
向我们展示了如何取得同一个数组对象连接的句柄,然后将其赋给另一个数组对象,向我们展示了如何取得同一个数组对象连接的句柄,然后将其赋给另一个数组对象
1.基本数据类型集合
集合类只能容纳对象句柄。但对一个数组,却既可令其直接容纳基本类型的数据,亦可容纳指向对象的句
柄。利用象 Integer、 Double 之类的“ 封装器”类,可将基本数据类型的值置入一个集合里。
无论将基本类型的数据置入数组,还是将其封装进入位于集合的一个类内,都涉及到执行效率的问题。显
然,若能创建和访问一个基本数据类型数组,那么比起访问一个封装数据的集合,前者的效率会高出许多。
数组的返回
假定我们现在想写一个方法,同时不希望它仅仅返回一样东西,而是想返回一系列东西。此时,象C 和 C++这样的语言会使问题复杂化,因为我们不能返回一个数组,只能返回指向数组的一个指针。这样就非常麻烦,因为很难控制数组的“存在时间”,它很容易造成内存“漏洞”的出现。
Java 采用的是类似的方法,但我们能“返回一个数组”。当然,此时返回的实际仍是指向数组的指针。但在Java 里,我们永远不必担心那个数组的是否可用—— 只要需要,它就会自动存在。而且垃圾收集器会在我们完成后自动将其清除
public class IceCream {
static String[] flav = { "Chocolate", "Strawberry", "Vanilla Fudge Swirl",
"Mint Chip", "Mocha Almond Fudge", "Rum Raisin", "Praline Cream",
"Mud Pie" };
static String[] flavorSet(int n) {
// Force it to be positive & within bounds:
n = Math.abs(n) % (flav.length + 1);
String[] results = new String[n];
int[] picks = new int[n];
for(int i = 0; i < picks.length; i++)
picks[i] = -1;
for(int i = 0; i < picks.length; i++) {
retry:
while(true) {
int t =(int)(Math.random() * flav.length);
for(int j = 0; j < i; j++)213
if(picks[j] == t) continue retry;
picks[i] = t;
results[i] = flav[t];
break;
}
}
return results;
}
public static void main(String[] args) {
for (int i = 0; i < 20; i++) {
System.out.println("flavorSet(" + i + ") = ");
String[] fl = flavorSet(flav.length);
for (int j = 0; j < fl.length; j++)
System.out.println("\t" + fl[j]);
}
}
}
flavorSet()方法创建了一个名为 results 的 String 数组。该数组的大小为 n—— 具体数值取决于我们传递给方法的自变量。随后,它从数组 flav 里随机挑选一些“香料”( Flavor),并将它们置入 results 里,并最终返回 results。返回数组与返回其他任何对象没什么区别—— 最终返回的都是一个句柄。
另一方面,注意当 flavorSet()随机挑选香料的时候,它需要保证以前出现过的一次随机选择不会再次出现。为达到这个目的,它使用了一个无限 while 循环,不断地作出随机选择,直到发现未在 picks 数组里出现过的一个元素为止(当然,也可以进行字串比较,检查随机选择是否在 results 数组里出现过,但字串比较的效率比较低)。若成功,就添加这个元素,并中断循环( break),再查找下一个( i 值会递增)。但假若 t 是一个已在 picks 里出现过的数组,就用标签式的 continue 往回跳两级,强制选择一个新 t。 用一个调试程序可以很清楚地看到这个过程。
集合
为容纳一组对象,最适宜的选择应当是数组。而且假如容纳的是一系列基本数据类型,更是必须采用数组。
缺点:类型未知
使用 Java 集合的“缺点”是在将对象置入一个集合时丢失了类型信息。之所以会发生这种情况,是由于当初编写集合时,那个集合的程序员根本不知道用户到底想把什么类型置入集合。若指示某个集合只允许特定的类型,会妨碍它成为一个“常规用途”的工具,为用户带来麻烦。为解决这个问题,集合实际容纳的是类型为 Object 的一些对象的句柄。
当然,也要注意集合并不包括基本数据类型,因为它们并不是从“任何东西”继承来的。
Java 不允许人们滥用置入集合的对象。假如将一条狗扔进一个猫的集合,那么仍会将集合内的所有东西都看作猫,所以在使用那条狗时会得到一个“违例”错误。在同样的意义上,假若试图将一条狗的句柄“造型”到一只猫,那么运行期间仍会得到一个“违例”错误
class Cat {
private int catNumber;
Cat(int i) {
catNumber = i;
}
void print() {
System.out.println("Cat #" + catNumber);
}
}
class Dog {
private int dogNumber;
Dog(int i) {
dogNumber = i;
}
void print() {
System.out.println("Dog #" + dogNumber);
}
}
public class CatsAndDogs {
public static void main(String[] args) {
Vector cats = new Vector();
for (int i = 0; i < 7; i++)
cats.addElement(new Cat(i));
// Not a problem to add a dog to cats:
cats.addElement(new Dog(7));
for (int i = 0; i < cats.size(); i++)
((Cat) cats.elementAt(i)).print();
// Dog is detected only at run-time
}
}
- 错误有时并不显露出来
- 在某些情况下,程序似乎正确地工作,不造型回我们原来的类型。第一种情况是相当特殊的: String 类从编译器获得了额外的帮助,使其能够正常工作。只要编译器期待的是一个String 对象,但它没有得到一个,就会自动调用在 Object 里定义、并且能够由任何 Java 类覆盖的 toString()方法。这个方法能生成满足要求的String 对象,然后在我们需要的时候使用。因此,为了让自己类的对象能显示出来,要做的全部事情就是覆盖toString()方法。
class Mouse {
private int mouseNumber;
Mouse(int i) {
mouseNumber = i;
}
// Magic method:
public String toString() {
return "This is Mouse #" + mouseNumber;
}
void print(String msg) {
if (msg != null)
System.out.println(msg);
System.out.println("Mouse number " + mouseNumber);
}
}
class MouseTrap {
static void caughtYa(Object m) {
Mouse mouse = (Mouse) m; // Cast from Object
mouse.print("Caught one!");
}
}
public class WorksAnyway {
public static void main(String[] args) {
Vector mice = new Vector();
for(int i = 0; i < 3; i++)
mice.addElement(new Mouse(i));
for(int i = 0; i < mice.size(); i++) {
// No cast necessary, automatic call
// to Object.toString():
System.out.println(
"Free mouse: " + mice.elementAt(i));
MouseTrap.caughtYa(mice.elementAt(i));
}
}
}
可在 Mouse 里看到对 toString()的重定义代码。在 main()的第二个 for 循环中,可发现下述语句:
System.out.println("Free mouse: " +
mice.elementAt(i));
在“ +”后,编译器预期看到的是一个 String 对象。 elementAt()生成了一个 Object,所以为获得希望的String,编译器会默认调用 toString()。但不幸的是,只有针对 String 才能得到象这样的结果;其他任何类型都不会进行这样的转换。
隐藏造型的第二种方法已在 Mousetrap 里得到了应用。 caughtYa()方法接收的不是一个 Mouse,而是一个Object。随后再将其造型为一个 Mouse。当然,这样做是非常冒失的,因为通过接收一个 Object,任何东西都可以传递给方法。然而,假若造型不正确—— 如果我们传递了错误的类型—— 就会在运行期间得到一个违例错误。这当然没有在编译期进行检查好,但仍然能防止问题的发生。注意在使用这个方法时毋需进行造型:
MouseTrap.caughtYa(mice.elementAt(i));
- 生成能自动判别类型的 Vector
- 一个更“健壮”的方案是用 Vector 创建一个新类,使其只接收我们指定的
- 类型,也只生成我们希望的类型。
class Gopher {
private int gopherNumber;
Gopher(int i) {
gopherNumber = i;
}
void print(String msg) {
if (msg != null)
System.out.println(msg);
System.out.println("Gopher number " + gopherNumber);
}
}
class GopherTrap {
static void caughtYa(Gopher g) {
g.print("Caught one!");
}
}
class GopherVector {
private Vector v = new Vector();
public void addElement(Gopher m) {
v.addElement(m);
}
public Gopher elementAt(int index) {
return (Gopher) v.elementAt(index);
}
public int size() {
return v.size();
}
public static void main(String[] args) {
GopherVector gophers = new GopherVector();
for (int i = 0; i < 3; i++)
gophers.addElement(new Gopher(i));
for (int i = 0; i < gophers.size(); i++)
GopherTrap.caughtYa(gophers.elementAt(i));
}
}
新的 GopherVector 类有一个类型为 Vector 的 private 成员(从 Vector 继承有些麻烦,理由稍后便知),而且方法也和 Vector 类似。然而,它不会接收和产生普通 Object,只对 Gopher 对象
感兴趣。
由于 GopherVector 只接收一个 Gopher(地鼠),所以假如我们使用:
gophers.addElement(new Pigeon());
就会在编译期间获得一条出错消息。采用这种方式,尽管从编码的角度看显得更令人沉闷,但可以立即判断出是否使用了正确的类型。注意在使用 elementAt()时不必进行造型—— 它肯定是一个 Gopher
枚举器
容纳各种各样的对象正是集合的首要任务。在 Vector 中, addElement()便是我们插入对象采用的方法,而 elementAt()是
提取对象的唯一方法。 Vector 非常灵活,我们可在任何时候选择任何东西,并可使用不同的索引选择多个元素。
若从更高的角度看这个问题,就会发现它的一个缺陷:需要事先知道集合的准确类型,否则无法使用。乍看来,这一点似乎没什么关系。但假若最开始决定使用Vector,后来在程序中又决定(考虑执行效率的原因)改变成一个 List(属于 Java1.2 集合库的一部分),这时又该如何做呢?
我们通常认为反复器是一种“轻量级”对象;也就是说,创建它只需付出极少的代价。但也正是由于这个原因,我们常发现反复器存在一些似乎很奇怪的限制。例如,有些反复器只能朝一个方向移动。
Java 的 Enumeration(枚举,注释②)便是具有这些限制的一个反复器的例子。除下面这些外,不可再用它
做其他任何事情:
(1) 用一个名为 elements()的方法要求集合为我们提供一个 Enumeration。我们首次调用它的 nextElement()
时,这个 Enumeration 会返回序列中的第一个元素。
(2) 用 nextElement() 获得下一个对象。
(3) 用 hasMoreElements()检查序列中是否还有更多的对象
class Hamster {
private int hamsterNumber;
Hamster(int i) {
hamsterNumber = i;
}
public String toString() {
return "This is Hamster #" + hamsterNumber;
}
}
class Printer {
static void printAll(Enumeration e) {
while (e.hasMoreElements())
System.out.println(e.nextElement().toString());
}
}
public class HamsterMaze {
public static void main(String[] args) {
Vector v = new Vector();
for (int i = 0; i < 3; i++)
v.addElement(new Hamster(i));
Printer.printAll(v.elements());
}
}
仔细研究一下打印方法:
static void printAll(Enumeration e) {
while(e.hasMoreElements())
System.out.println(
e.nextElement().toString());
}
注意其中没有与序列类型有关的信息。我们拥有的全部东西便是Enumeration。为了解有关序列的情况,一个 Enumeration 便足够了:可取得下一个对象,亦可知道是否已抵达了末尾。取得一系列对象,然后在其中遍历,从而执行一个特定的操作—— 这是一个颇有价值的编程概念
集合的类型
V e c t o r
崩溃 Java
Java 标准集合里包含了 toString()方法,所以它们能生成自己的 String 表达方式,包括它们容纳的对象。
例如在 Vector 中, toString()会在 Vector 的各个元素中步进和遍历,并为每个元素调用 toString()。假定我们现在想打印出自己类的地址。看起来似乎简单地引用 this 即可(特别是 C++程序员有这样做的倾向):
public class CrashJava {
public String toString() {
return "CrashJava address: " + this + "\n";
}
public static void main(String[] args) {
Vector v = new Vector();
for (int i = 0; i < 10; i++)
v.addElement(new CrashJava());
System.out.println(v);
}
}
此时发生的是字串的自动类型转换。当我们使用下述语句时:
“CrashJava address: ” + this
编译器就在一个字串后面发现了一个“ +”以及好象并非字串的其他东西,所以它会试图将 this 转换成一个字串。转换时调用的是 toString(),后者会产生一个递归调用。若在一个 Vector 内出现这种事情,看起来堆栈就会溢出,同时违例控制机制根本没有机会作出响应。
若确实想在这种情况下打印出对象的地址,解决方案就是调用 Object 的 toString 方法。此时就不必加入this,只需使用 super.toString()。当然,采取这种做法也有一个前提:我们必须从 Object 直接继承,或者没有一个父类覆盖了 toString 方法。
B i t S e t
BitSet 实际是由“ 二进制位”构成的一个 Vector。如果希望高效率地保存大量“开-关”信息,就应使用BitSet。它只有从尺寸的角度看才有意义;如果希望的高效率的访问,那么它的速度会比使用一些固有类型的数组慢一些。
BitSet 的最小长度是一个长整数( Long)的长度: 64 位。这意味着假如我们准备保存比这更小的数据,如 8 位数据,那么 BitSet 就显得浪费了。所以最好创建自己的类,用它容纳自己的标志位。
S t a c k
Stack 有时也可以称为“后入先出”( LIFO)集合。换言之,我们在堆栈里最后“压入”的东西将是以后第
一个“弹出”的。和其他所有 Java 集合一样,我们压入和弹出的都是“对象”,所以必须对自己弹出的东西
进行“造型”。
下面是一个简单的堆栈示例,它能读入数组的每一行,同时将其作为字串压入堆栈。
public class Stacks {
static String[] months = { "January", "February", "March", "April", "May",
"June", "July", "August", "September", "October", "November",
"December" };
public static void main(String[] args) {
Stack stk = new Stack();
for (int i = 0; i < months.length; i++)
stk.push(months[i] + " ");
System.out.println("stk = " + stk);
// Treating a stack as a Vector:
stk.addElement("The last line");
System.out.println("element 5 = " + stk.elementAt(5));
System.out.println("popping elements:");
while (!stk.empty())
System.out.println(stk.pop());
}
}
months 数组的每一行都通过 push()继承进入堆栈,稍后用 pop()从堆栈的顶部将其取出。要声明的一点是,Vector 操作亦可针对 Stack 对象进行。这可能是由继承的特质决定的—— Stack“属于”一种 Vector。因此,能对 Vector 进行的操作亦可针对 Stack 进行,例如 elementAt()方法
H a s h t a b l e
Vector 允许我们用一个数字从一系列对象中作出选择,所以它实际是将数字同对象关联起来了。
但假如我们想根据其他标准选择一系列对象呢?堆栈就是这样的一个例子:它的选择标准是“最后压入堆栈的东西”。
这种“从一系列对象中选择”的概念亦可叫作一个“映射”、“字典”或者“关联数组”。从概念上讲,它看起来象一个 Vector,但却不是通过数字来查找对象,而是用另一个对象来查找它们!这通常都属于一个程序中的重要进程。
在 Java 中,这个概念具体反映到抽象类 Dictionary 身上。该类的接口是非常直观的 size()告诉我们其中包含了多少元素; isEmpty()判断是否包含了元素(是则为 true); put(Object key, Object value)添加一个值(我们希望的东西),并将其同一个键关联起来(想用于搜索它的东西); get(Object key)获得与某个键对应的值;而 remove(Object Key)用于从列表中删除“键-值”对。还可以使用枚举技术: keys()产生对键的一个枚举( Enumeration);而 elements()产生对所有值的一个枚举。这便是一个 Dict ionary(字典)的全部。
public class AssocArray extends Dictionary {
private Vector keys = new Vector();
private Vector values = new Vector();
public int size() {
return keys.size();
}
public boolean isEmpty() {
return keys.isEmpty();
}
public Object put(Object key, Object value) {
keys.addElement(key);
values.addElement(value);
return key;
}
public Object get(Object key) {
int index = keys.indexOf(key);
// indexOf() Returns -1 if key not found:
if (index == -1)
return null;
return values.elementAt(index);
}
public Object remove(Object key) {
int index = keys.indexOf(key);
if (index == -1)
return null;
keys.removeElementAt(index);
Object returnval = values.elementAt(index);
values.removeElementAt(index);
return returnval;
}
public Enumeration keys() {
return keys.elements();
}
public Enumeration elements() {
return values.elements();
}
// Test it:
public static void main(String[] args) {
AssocArray aa = new AssocArray();
for (char c = ’a’; c <= ’z’; c++)
aa.put(String.valueOf(c), String.valueOf(c).toUpperCase());
char[] ca = { ’a’, ’e’, ’i’, ’o’, ’u’ };
for (int i = 0; i < ca.length; i++)
System.out.println("Uppercase: " + aa.get(String.valueOf(ca[i])));
}
}
在对 AssocArray 的定义中,我们注意到的第一个问题是它“扩展”了字典。这意味着 AssocArray 属于Dictionary 的一种类型,所以可对其发出与 Dictionary 一样的请求。如果想生成自己的 Dictionary,而且就在这里进行,那么要做的全部事情只是填充位于 Dictionary 内的所有方法(而且必须覆盖所有方法,因为
它们—— 除构建器外—— 都是抽象的)。
标准 Java 库只包含 Dictionary 的一个变种,名为 Hashtable(散列表,注释③)。 Java 的散列表具有与AssocArray 相同的接口(因为两者都是从 Dictionary 继承来的)。但有一个方面却反映出了差别:执行效率。若仔细想想必须为一个 get()做的事情,就会发现在一个 Vector 里搜索键的速度要慢得多。但此时用散列表却可以加快不少速度。不必用冗长的线性搜索技术来查找一个键,而是用一个特殊的值,名为“散列码”。散列码可以获取对象中的信息,然后将其转换成那个对象“相对唯一”的整数( int)。所有对象都有一个散列码,而 hashCode()是根类 Object 的一个方法。 Hashtable 获取对象的 hashCode(),然后用它快速查找键。
class Counter {
int i = 1;
public String toString() {
return Integer.toString(i);
}
}
class Statistics {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
for (int i = 0; i < 10000; i++) {
// Produce a number between 0 and 20:
Integer r = new Integer((int) (Math.random() * 20));
if (ht.containsKey(r))
((Counter) ht.get(r)).i++;
else
ht.put(r, new Counter());
}
System.out.println(ht);
}
}
- 创建“关键”类
- 但在使用散列表的时候,一旦我们创建自己的类作为键使
- 用,就会遇到一个很常见的问题。例如,假设一套天气预报系统将Groundhog(土拔鼠)对象匹配成Prediction(预报) 。这看起来非常直观:我们创建两个类,然后将Groundhog 作为键使用,而将Prediction 作为值使用。如下所示:
class Groundhog {
int ghNumber;
Groundhog(int n) {
ghNumber = n;
}
}
class Prediction {
boolean shadow = Math.random() > 0.5;
public String toString() {
if (shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
}
public class SpringDetector {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
for (int i = 0; i < 10; i++)
ht.put(new Groundhog(i), new Prediction());
System.out.println("ht = " + ht + "\n");
System.out.println("Looking up prediction for groundhog #3:");
Groundhog gh = new Groundhog(3);
if (ht.containsKey(gh))
System.out.println((Prediction) ht.get(gh));
}
}
问题在于Groundhog 是从通用的 Object 根类继承的(若当初未指
定基础类,则所有类最终都是从 Object 继承的)。事实上是用 Object 的 hashCode()方法生成每个对象的散列码,而且默认情况下只使用它的对象的地址。所以, Groundhog(3)的第一个实例并不会产生与Groundhog(3)第二个实例相等的散列码,而我们用第二个实例进行检索
或许认为此时要做的全部事情就是正确地覆盖 hashCode()。但这样做依然行不能,除非再做另一件事情:覆盖也属于 Object 一部分的 equals()。当散列表试图判断我们的键是否等于表内的某个键时,就会用到这个方法。同样地,默认的 Object.equals()只是简单地比较对象地址,所以一个 Groundhog(3)并不等于
另一个 Groundhog(3)。
因此,为了在散列表中将自己的类作为键使用,必须同时覆盖 hashCode()和 equals(),就象下面展示的那样:
class Groundhog {
int ghNumber;
Groundhog(int n) {
ghNumber = n;
}
}
class Prediction {
boolean shadow = Math.random() > 0.5;
public String toString() {
if (shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
}
public class SpringDetector {
public static void main(String[] args) {
Hashtable ht = new Hashtable();
for (int i = 0; i < 10; i++)
ht.put(new Groundhog(i), new Prediction());
System.out.println("ht = " + ht + "\n");
System.out.println("Looking up prediction for groundhog #3:");
Groundhog gh = new Groundhog(3);
if (ht.containsKey(gh))
System.out.println((Prediction) ht.get(gh));
}
}
Groundhog2.hashCode()将土拔鼠号码作为一个标识符返回(在这个例子中,程序员需要保证没有两个土拔鼠用同样的 ID 号码并存)。为了返回一个独一无二的标识符,并不需要 hashCode(), equals()方法必须能够严格判断两个对象是否相等。
equals()方法要进行两种检查:检查对象是否为 null;若不为 null ,则继续检查是否为 Groundhog2 的一个实例(要用到 instanceof 关键字)。即使为了继续执行 equals(),它也应该是一个Groundhog2。正如大家看到的那样,这种比较建立在实际 ghNumber 的基础上。这一次一旦我们运行程序,就会看到它终于产生了正确的输出(许多 Java 库的类都覆盖了 hashcode() 和 equals()方法,以便与自己提供的内容适应)。
再论枚举器
将穿越一个序列的操作与那个序列的基础结构分隔开。在下面的例子里, PrintData 类用一个 Enumeration 在一个序列中移动,并为每个对象都调用toString()方法。此时创建了两个不同类型的集合:一个 Vector 和一个 Hashtable。并且在它们里面分别填
充 Mouse 和 Hamster 对象,由于 Enumeration 隐藏了基层集合的结构,所以PrintData 不知道或者不关心 Enumeration 来自于什么类型的集合:
class PrintData {
static void print(Enumeration e) {
while (e.hasMoreElements())
System.out.println(e.nextElement().toString());
}
}
class Enumerators2 {
public static void main(String[] args) {
Vector v = new Vector();
for (int i = 0; i < 5; i++)
v.addElement(new Mouse(i));
Hashtable h = new Hashtable();
for (int i = 0; i < 5; i++)
h.put(new Integer(i), new Hamster(i));
System.out.println("Vector");
PrintData.print(v.elements());
System.out.println("Hashtable");
PrintData.print(h.elements());
}
}
注意 PrintData.print()利用了这些集合中的对象属于 Object 类这一事实,所以它调用了 toString()。但在
解决自己的实际问题时,经常都要保证自己的 Enumeration 穿越某种特定类型的集合。例如,可能要求集合
中的所有元素都是一个 Shape(几何形状),并含有 draw()方法。若出现这种情况,必须从
Enumeration.nextElement()返回的 Object 进行下溯造型,以便产生一个 Shape。
排序
编写通用的排序代码时,面临的一个问题是必须根据对象的实际类型来执行比较运算,从而实现正确的排序。当然,一个办法是为每种不同的类型都写一个不同的排序方法。然而,应认识到假若这样做,以后增加新类型时便不易实现代码的重复利用。
程序设计一个主要的目标就是“将发生变化的东西同保持不变的东西分隔开”。在这里,保持不变的代码是通用的排序算法,而每次使用时都要变化的是对象的实际比较方法。因此,我们不可将比较代码“硬编码”到多个不同的排序例程内,而是采用“回调”技术。
利用回调,经常发生变化的那部分代*会码**封装到它自己的类内,而总是保持相同的代码则“回调”发生变化的代码。这样一来,不同的对象就可以表达不同的比较方式,同时向它们传递相同的排序代码。
下面这个“接口”( Interface)展示了如何比较两个对象,它将那些“要发生变化的东西”封装在内:
interface Compare {
boolean lessThan(Object lhs, Object rhs);
boolean lessThanOrEqual(Object lhs, Object rhs);
}
对这两种方法来说, lhs 代表本次比较中的“左手”对象,而 rhs 代表“右手”对象。
可创建 Vector 的一个子类,通过 Compare 实现“快速排序”。对于这种算法,包括它的速度以及原理等等
public class SortVector extends Vector {
private Compare compare; // To hold the callback
public SortVector(Compare comp) {
compare = comp;
}
public void sort() {
quickSort(0, size() - 1);
}
private void quickSort(int left, int right) {
if (right > left) {
Object o1 = elementAt(right);
int i = left - 1;
int j = right;
while (true) {
while (compare.lessThan(elementAt(++i), o1))
;
while (j > 0)
if (compare.lessThanOrEqual(elementAt(--j), o1))
break; // out of while
if (i >= j)
break;
swap(i, j);
}
swap(i, right);
quickSort(left, i - 1);
quickSort(i + 1, right);
}
}
private void swap(int loc1, int loc2) {
Object tmp = elementAt(loc1);
setElementAt(elementAt(loc2), loc1);
setElementAt(tmp, loc2);
}
}
为使用 SortVector,必须创建一个类,令其为我们准备排序的对象实现 Compare。此时内部类并不显得特别重要,但对于代码的组织却是有益的。下面是针对 String 对象的一个例子
public class StringSortTest {
static class StringCompare implements Compare {
public boolean lessThan(Object l, Object r) {
return ((String) l).toLowerCase().compareTo(
((String) r).toLowerCase()) < 0;
}
public boolean lessThanOrEqual(Object l, Object r) {
return ((String) l).toLowerCase().compareTo(
((String) r).toLowerCase()) <= 0;
}
}
public static void main(String[] args) {
SortVector sv = new SortVector(new StringCompare());
sv.addElement("d");
sv.addElement("A");
sv.addElement("C");
sv.addElement("c");
sv.addElement("b");
sv.addElement("B");
sv.addElement("D");
sv.addElement("a");
sv.sort();
Enumeration e = sv.elements();
while (e.hasMoreElements())
System.out.println(e.nextElement());
}
}
一旦设置好框架,就可以非常方便地重复使用象这样的一个设计—— 只需简单地写一个类,将“需要发生变化”的东西封装进去,然后将一个对象传给SortVector 即可
继承( extends)在这儿用于创建一种新类型的 Vector—— 也就是说, SortVector 属于一种 Vector,并带有一些附加的功能。继承在这里可发挥很大的作用,但了带来了问题。它使一些方法具有了final 属性,所以不能覆盖它们。如果想创建一个排好序的 Vector,令其只接收和生成 String 对象,就会遇到麻烦。因为 addElement()和 elementAt()都具有 final 属性,而且它们都是我们必须覆盖的方法,否则便无法实现只能接收和产生 String 对象。
但在另一方面,请考虑采用“合成”方法:将一个对象置入一个新类的内部。此时,不是改写上述代码来达到这个目的,而是在新类里简单地使用一个 SortVector。在这种情况下,用于实现 Compare 接口的内部类就可以“匿名”地创建
import java.util.*;
public class StrSortVector {
private SortVector v = new SortVector(
// Anonymous inner class:
new Compare() {
public boolean lessThan(Object l, Object r) {
return ((String) l).toLowerCase().compareTo(
((String) r).toLowerCase()) < 0;
}
public boolean lessThanOrEqual(Object l, Object r) {
return ((String) l).toLowerCase().compareTo(
((String) r).toLowerCase()) <= 0;
}
});
private boolean sorted = false;
public void addElement(String s) {
v.addElement(s);
sorted = false;
}
public String elementAt(int index) {
if(!sorted) {
v.sort();232
sorted = true;
}
return (String)v.elementAt(index);
}
public Enumeration elements() {
if (!sorted) {
v.sort();
sorted = true;
}
return v.elements();
}
// Test it:
public static void main(String[] args) {
StrSortVector sv = new StrSortVector();
sv.addElement("d");
sv.addElement("A");
sv.addElement("C");
sv.addElement("c");
sv.addElement("b");
sv.addElement("B");
sv.addElement("D");
sv.addElement("a");
Enumeration e = sv.elements();
while (e.hasMoreElements())
System.out.println(e.nextElement());
}
}
新集合
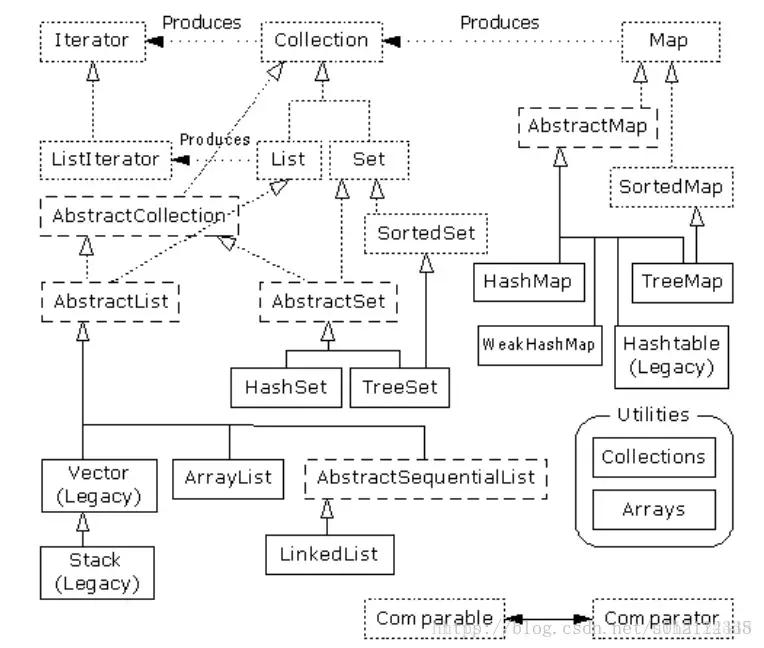
这里写图片描述
这张图刚开始的时候可能让人有点儿摸不着头脑,相信大家会真正理解它实际只有三个集合组件: Map, List 和 Set。而且每个组件实际只有两、三种实现方式
虚线框代表“接口”,点线框代表“抽象”类,而实线框代表普通(实际)类。点线箭头表示一个特定的类准备实现一个接口(在抽象类的情况下,则是“部分”实现一个接口)。双线箭头表示一个类可生成箭头指向的那个类的对象。
致力于容纳对象的接口是 Collection, List, Set 和 Map。在传统情况下,我们需要写大量代码才能同这些接口打交道。而且为了指定自己想使用的准确类型,必须在创建之初进行设置。所以可能创建下面这样的一
个 List:
List x = new LinkedList();
当然,也可以决定将 x 作为一个 LinkedList 使用(而不是一个普通的 List),并用 x 负载准确的类型信息。使用接口的好处就是一旦决定改变自己的实施细节,要做的全部事情就是在创建的时候改变它,就象下面这样:
List x = new ArrayList();
在类的分级结构中,可看到大量以“ Abstract ”(抽象)开头的类,这刚开始可能会使人感觉迷惑。它们实际上是一些工具,用于“部分”实现一个特定的接口。举个例子来说,假如想生成自己的Set,就不是从 Set接口开始,然后自行实现所有方法。相反,我们可以从 AbstractSet 继承,只需极少的工作即可得到自己的新类。尽管如此,新集合库仍然包含了足够的功能,可满足我们的几乎所有需求。所以考虑到我们的目的,可忽略所有以“ Abstract”开头的类。
因此,在观看这张示意图时,真正需要关心的只有位于最顶部的“接口”以及普通(实际)类—— 均用实线方框包围。通常需要生成实际类的一个对象,将其上溯造型为对应的接口。以后即可在代码的任何地方使用那个接口。下面是一个简单的例子,它用 String 对象填充一个集合,然后打印出集合内的每一个元素:
public class SimpleCollection {
public static void main(String[] args) {
Collection c = new ArrayList();
for (int i = 0; i < 10; i++)
c.add(Integer.toString(i));
Iterator it = c.iterator();
while (it.hasNext())
System.out.println(it.next());
}
}
main()的第一行创建了一个 ArrayList 对象,然后将其上溯造型成为一个集合。由于这个例子只使用了Collection 方法,所以从 Collection 继承的一个类的任何对象都可以正常工作。但 ArrayList 是一个典型的 Collection,它代替了 Vector 的位置。
add()方法的作用是将一个新元素置入集合里。然而,用户文档谨慎地指出 add()“保证这个集合包含了指定的元素”。这一点是为 Set 作铺垫的,后者只有在元素不存在的前提下才会真的加入那个元素。对于ArrayList 以及其他任何形式的 List, add()肯定意味着“直接加入”。
利用 iterator()方法,所有集合都能生成一个“反复器”( Iterator)。反复器其实就象一个“枚举”( Enumeration),是后者的一个替代物,只是:
(1) 它采用了一个历史上默认、而且早在 OOP 中得到广泛采纳的名字(反复器)。
(2) 采用了比 Enumeration 更短的名字: hasNext()代替了 hasMoreElement(),而 next()代替了nextElement()。
(3) 添加了一个名为 remove()的新方法,可删除由 Iterator 生成的上一个元素。所以每次调用 next()的时候,只需调用 remove()一次
使用 C o l l e c t i o n s
下面这张表格总结了用一个集合能做的所有事情(亦可对 Set 和 List 做同样的事情,尽管 List 还提供了一
些额外的功能)。 Map 不是从 Collection 继承的,所以要单独对待
boolean add(Object) *保证集合内包含了自变量。如果它没有添加自变量,就返回 false(假)
boolean addAll(Collection) *添加自变量内的所有元素。如果没有添加元素,则返回 true(真)
void clear() *删除集合内的所有元素
boolean contains(Object) 若集合包含自变量,就返回“真”
boolean containsAll(Collection) 若集合包含了自变量内的所有元素,就返回“真”
boolean isEmpty() 若集合内没有元素,就返回“真”
Iterator iterator() 返回一个反复器,以用它遍历集合的各元素
boolean remove(Object) *如自变量在集合里,就删除那个元素的一个实例。如果已进行了删除,就返回
“真”
boolean removeAll(Collection) *删除自变量里的所有元素。如果已进行了任何删除,就返回“真”
boolean retainAll(Collection) *只保留包含在一个自变量里的元素(一个理论的“交集”)。如果已进
行了任何改变,就返回“真”
int size() 返回集合内的元素数量
Object[] toArray() 返回包含了集合内所有元素的一个数组
*这是一个“可选的”方法,有的集合可能并未实现它。若确实如此,该方法就会遇到一个
UnsupportedOperatiionException,即一个“操作不支持”违例。
下面这个例子向大家演示了所有方法。同样地,它们只对从集合继承的东西有效,一个ArrayList 作为一种“不常用的分母”使用
public class Collection1 {
// Fill with ’size’ elements, start
// counting at ’start’:
public static Collection fill(Collection c, int start, int size) {
for (int i = start; i < start + size; i++)
c.add(Integer.toString(i));
return c;
}
// Default to a "start" of 0:
public static Collection fill(Collection c, int size) {
return fill(c, 0, size);
}
// Default to 10 elements:
public static Collection fill(Collection c) {
return fill(c, 0, 10);
}
// Create & upcast to Collection:
public static Collection newCollection() {
return fill(new ArrayList());
// ArrayList is used for simplicity, but it’s
// only seen as a generic Collection
// everywhere else in the program.
}
// Fill a Collection with a range of values:
public static Collection newCollection(int start, int size) {
return fill(new ArrayList(), start, size);
}
// Moving through a List with an iterator:
public static void print(Collection c) {
for (Iterator x = c.iterator(); x.hasNext();)
System.out.print(x.next() + " ");
System.out.println();
}
public static void main(String[] args) {
Collection c = newCollection();
c.add("ten");
c.add("eleven");
print(c);
// Make an array from the List:
Object[] array = c.toArray();
// Make a String array from the List:
String[] str = (String[]) c.toArray(new String[1]);
// Find max and min elements; this means
// different things depending on the way
// the Comparable interface is implemented:
System.out.println("Collections.max(c) = " + Collections.max(c));
System.out.println("Collections.min(c) = " + Collections.min(c));
// Add a Collection to another Collection
c.addAll(newCollection());
print(c);
c.remove("3"); // Removes the first one
print(c);
c.remove("3"); // Removes the second one
print(c);
// Remove all components that are in the
// argument collection:
c.removeAll(newCollection());
print(c);
c.addAll(newCollection());
print(c);
// Is an element in this Collection?
System.out.println("c.contains(\"4\") = " + c.contains("4"));
// Is a Collection in this Collection?
System.out.println("c.containsAll(newCollection()) = "
+ c.containsAll(newCollection()));
Collection c2 = newCollection(5, 3);
// Keep all the elements that are in both
// c and c2 (an intersection of sets):
c.retainAll(c2);
print(c);
// Throw away all the elements in c that
// also appear in c2:
c.removeAll(c2);
System.out.println("c.isEmpty() = " + c.isEmpty());
c = newCollection();
print(c);
c.clear(); // Remove all elements
System.out.println("after c.clear():");
print(c);
}
}
newCollection()的两个版本都创建了 ArrayList,用于包含不同的数据集,并将它们作为集合对象返回。所以很明显,除了 Collection 接口之外,不会再用到其他什么。
现在私信我可以免费获得各种Java编程的从入门到深入的学习资料