
什么是正则表达式?
正则表达式(称为 RE、或正则表达式或正则表达式模式)本质上是一种嵌入 Python 中并通过 re 模块提供的小型、高度专业化的编程语言。使用这种语言,我们可以为我们想要匹配的一组可能的字符串指定规则;这个集合可能包含字符串、电子邮件地址或任何你喜欢的东西。
正则表达式语法
正则表达式(或 RE)指定一组与其匹配的字符串;这个模块中的函数让你检查一个特定的字符串是否匹配一个给定的正则表达式(或者一个给定的正则表达式是否匹配一个特定的字符串,这归结为同一件事)。
正则表达式的特殊字符表格
|
特殊字符 |
语义 |
示例 |
|
. |
匹配包括换行符在内的任何字符 |
.ab |
|
^ |
匹配字符串的开头,并且在 多行模式下,每个换行符之后也立即匹配 |
^ab |
|
$ |
匹配字符串末尾或字符串末尾换行符之前,并且在多行模式下也匹配换行符之前 |
ab$ |
|
* |
匹配前面的RE 0次或更多次重复,尽可能多的重复 |
ab*,ab* 将匹配“ a”、“ ab”或“ a”后面跟任意数量的“ b” |
|
+ |
匹配前面的RE1个或多个重复 |
ab+,将匹配“ a”后跟任意非零数的“ b” |
|
? |
匹配前面 RE 的0或1次重复 |
ab?,ab?将匹配“ a”或“ ab” |
|
*?, +?, ?? |
“ *”,“ +”,还有“ ?”修饰符都是贪婪的; 它们尽可能匹配更多的文本。有时这种行为是不需要的; 如果 RE < . * > 与“ < a > b < c >”匹配,则它将匹配整个字符串,而不仅仅是“ < a >”。增加?在限定符使其以非贪婪或最小方式执行匹配之后; 将匹配尽可能少的字符。使用 RE < .*?>将只匹配“ < a >”。 |
<.*?>,<.*> |
|
{m} |
指定正好匹配前一个 RE 的 m 个副本; 匹配次数越少,则整个 RE 不匹配 |
{6}将正好匹配6个“ a”字符,但不匹配5个。 |
|
{m,n} |
扩展前一个字符m至n次(含n) |
ab{1,2}c 表示abc、abbc |
|
{m,n}? |
使得到的RE匹配前一个RE的m到n次重复,尝试匹配尽可能少的重复.这是前一个限定符的非贪婪版本 |
{3,5}将匹配5个'a'字符,而{3,5}?只会匹配3个字符 |
|
\ |
转义特殊字符 |
\? |
|
[] |
用于表示一组字符 |
[abc],将匹配”a“、”b”、“c”,也可以表示字符范围[0-9],[a-z],[A-Z],还可以通过补集来匹配例如[^5]将匹配除5以外的任何字符。 |
|
| |
左右表达式任意一个 |
abc|def 匹配abc,def |
|
\d |
匹配数字0-9 |
\d |
|
\D |
匹配任何(非数字)不是十进制数字的字符跟\d相反 |
\D,相当于[^0-9] |
|
\s |
匹配 Unicode 空白字符(包括 [ \t\n\r\f\v],以及许多其他字符、空白(制表符、空格、换行符等) |
\s |
|
\S |
匹配任何不是空白字符的字符与\s相反 |
\S相当于[^\t\n\r\f\v] |
|
\w |
匹配 Unicode 单词字符;这包括可以成为任何语言中单词一部分的大多数字符,以及数字和下划线 |
\w相当于[a-zA-Z0-9_] |
|
\W |
匹配任何不是单词字符的字符与 \w 正好相反 |
\W相当于[^a-zA-Z0-9_] |
|
\A |
仅匹配字符串的开头 |
\A |
|
\Z |
仅匹配字符串的末尾 |
\Z |
|
\b |
匹配空字符串,但只匹配单词的开头或结尾 |
\b |
|
\B |
匹配空字符串,但仅当它不在单词的开头或结尾时。\B 与 \b 正好相反 |
\B |
在Python中使用RE模块
- 导入模块
import re
- re.search(): Search (pattern,string,Flag = 0) ,在字符串中搜索正则表达式模式生成匹配的第一个位置,并返回相应的匹配对象。如果字符串中没有位置与模式匹配,则返回 Nothing; 请注意,这与在字符串中的某个位置查找零长度匹配不同
search方法代码示例:

Start ()和 end ()方法为字符串提供索引,显示模式匹配的文本出现的位置,group()方法输出匹配的文本。
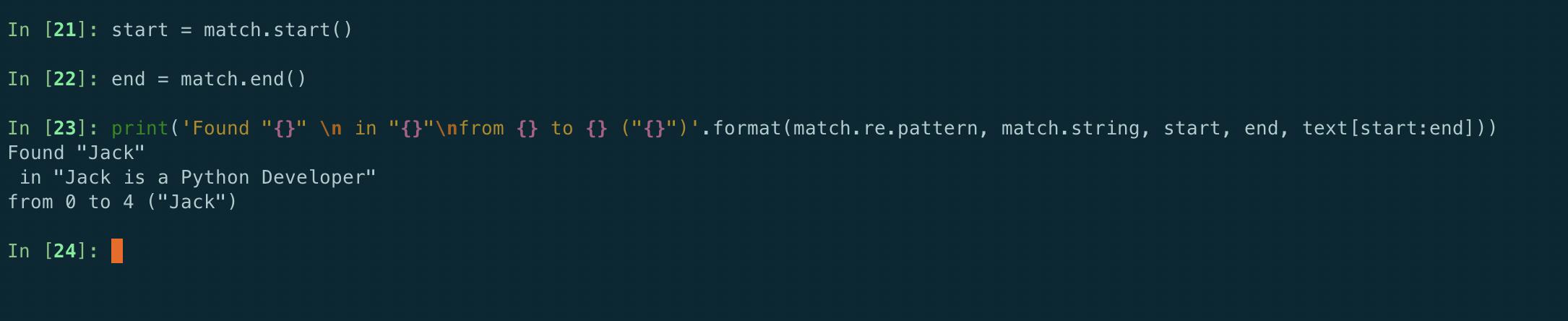
- re.match(): re.match(pattern, string, flags=0), 如果字符串开头的零个或多个字符与正则表达式模式匹配,则返回相应的匹配对象。如果字符串与模式不匹配,则返回 None;请注意,这与零长度匹配不同。Python 中 re 的 re.match() 函数将搜索正则表达式模式并返回第一个匹配项。Python RegEx Match 方法仅在字符串的开头检查匹配项。因此,如果在第一行找到匹配项,则返回匹配对象。但如果在其他行中找到匹配项,Python RegEx Match 函数将返回 None。
match()方法代码示例:

为啥match方法返回None?是因为字符串"Python"没出现在文本的开头,使用 match() 找不到。
我们改一下代码来看看

现在匹配到了字符串,因为字符串"Jack"位于字符串的开头。
- re.fullmatch(): re.fullmatch(pattern, string, flags=0) , 如果整个字符串与正则表达式模式匹配,则返回相应的匹配对象。如果字符串与模式不匹配,则返回 None;请注意,这与零长度匹配不同。
fullmatch()方法代码示例:

为啥fullmatch()返回了None?因为fullmatch是整个字符串与正则表达式匹配,上面的代码只匹配了字符串“Jack”,所以返回None。
我们改一下代码来看看

- re.findall()方法: re.findall(pattern, string, flags=0) , 返回字符串中模式的所有非重叠匹配,作为字符串或元组的列表。从左到右扫描字符串,并按找到的顺序返回匹配项。结果中包含空匹配项。 结果取决于模式中捕获组的数量。如果没有组,则返回与整个模式匹配的字符串列表。如果只有一个组,则返回与该组匹配的字符串列表。如果存在多个组,则返回与组匹配的字符串元组列表。非捕获组不影响结果的形式。
findall()方法代码示例:

使用正则表达式来匹配文本。
#\b - Matches the empty string, but only at the beginning or end of a word.
#M - It should match 'M'
#[a-z] - set of character from a to z
#* - It should be zero or more
pattern = r'\bM[a-z]*'
text = 'Data Science is forcing every business to act differently. The decision making today is far more \
complex and driven by AI and Machine Learning Models. The Business Intelligence tools of yesterday are being rewritten to incorporate Data Science and Machine Learning.'
re.findall(pattern, text)

- re.finditer(): re.finditer(pattern, string, flags=0) , 返回一个迭代器,在字符串中的 RE 模式的所有非重叠匹配中产生匹配对象。从左到右扫描字符串,并按找到的顺序返回匹配项。结果中包含空匹配项。finditer() 函数返回一个生成 Match 实例的迭代器,而不是 findall() 返回的字符串。
finditer()方法代码示例:
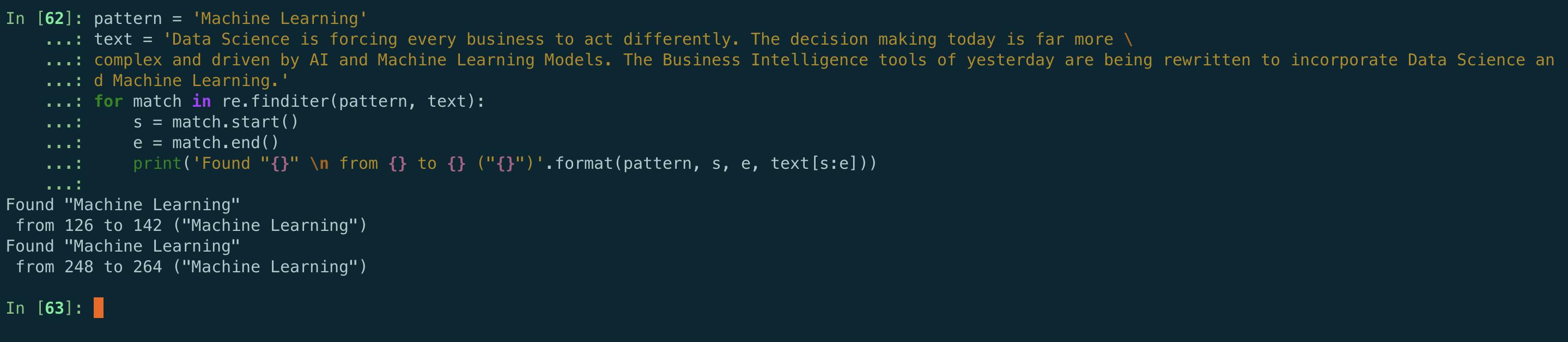
pattern = 'Machine Learning'
text = 'Data Science is forcing every business to act differently. The decision making today is far more \
complex and driven by AI and Machine Learning Models. The Business Intelligence tools of yesterday are being rewritten to incorporate Data Science and Machine Learning.'
for match in re.finditer(pattern, text):
s = match.start()
e = match.end()
print('Found "{}" \n from {} to {} ("{}")'.format(pattern, s, e, text[s:e]))
- re.compile(): re.compile(pattern, flags=0) , 将正则表达式模式编译成正则表达式对象,可以使用它的 match()、search() 和其他方法进行匹配。
compile()方法代码示例:
import re
ore = re.compile(r'\d{4}')
a = ['1234','abc123','123bgt4567','qwer1234']
for it in a:
if ore.search(it):
print(it)
# output
# 1234
# 123bgt4567
# qwer1234
这里注意一个问题就是:当我们需要一个正则表达式匹配多个文本我们使用compile来编译正则表达式然后利用for循环来做匹配看起来非常便捷,但是其实其它re的一些方法自带compile,根本没有必要多此一举先 re.compile 再调用正则表达式方法,所以一般来说除非特别需求不然不建议使用re.compile。
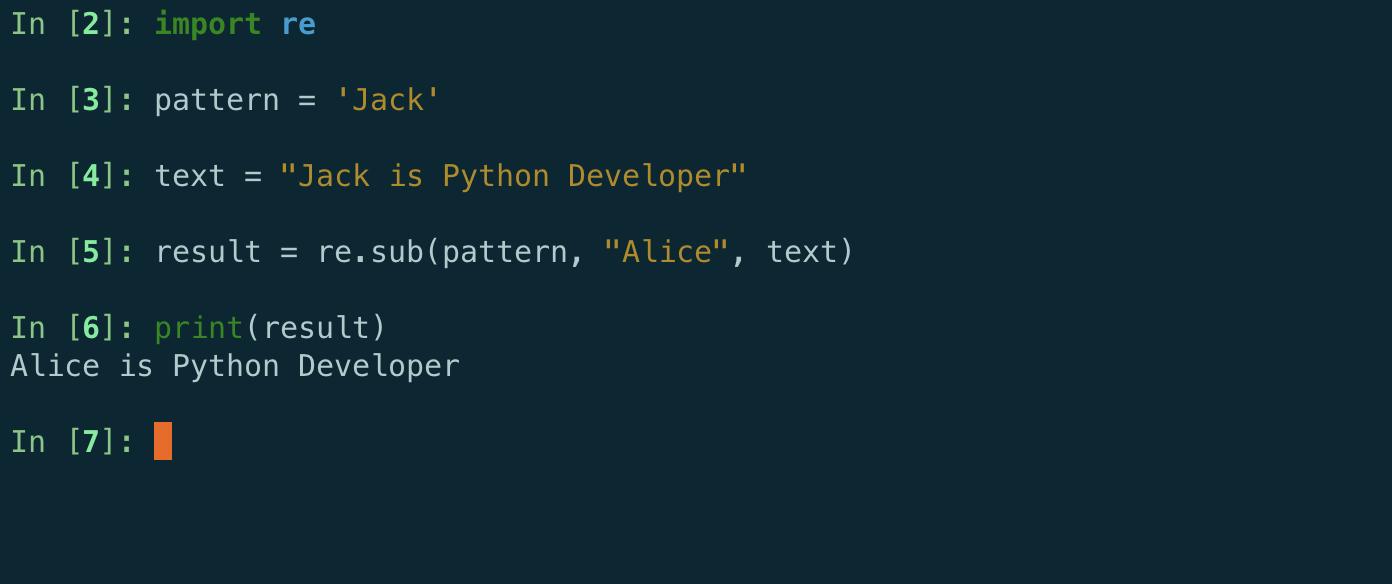
- re.sub(): re.sub(pattern, repl, string, count=0, flags=0) , 返回通过替换 repl 替换 string 中最左边的不重叠出现的模式获得的字符串。如果未找到该模式,则字符串原封不动地返回。repl 可以是字符串或函数;如果它是一个字符串,则处理其中的任何反斜杠转义。也就是说,\n 转换为单个换行符,\r 转换为回车符,等等。ASCII 字母的未知转义保留供将来使用并视为错误。其他未知的转义例如 \& 被单独留下。反向引用,例如 \6,被替换为模式中第 6 组匹配的子字符串。
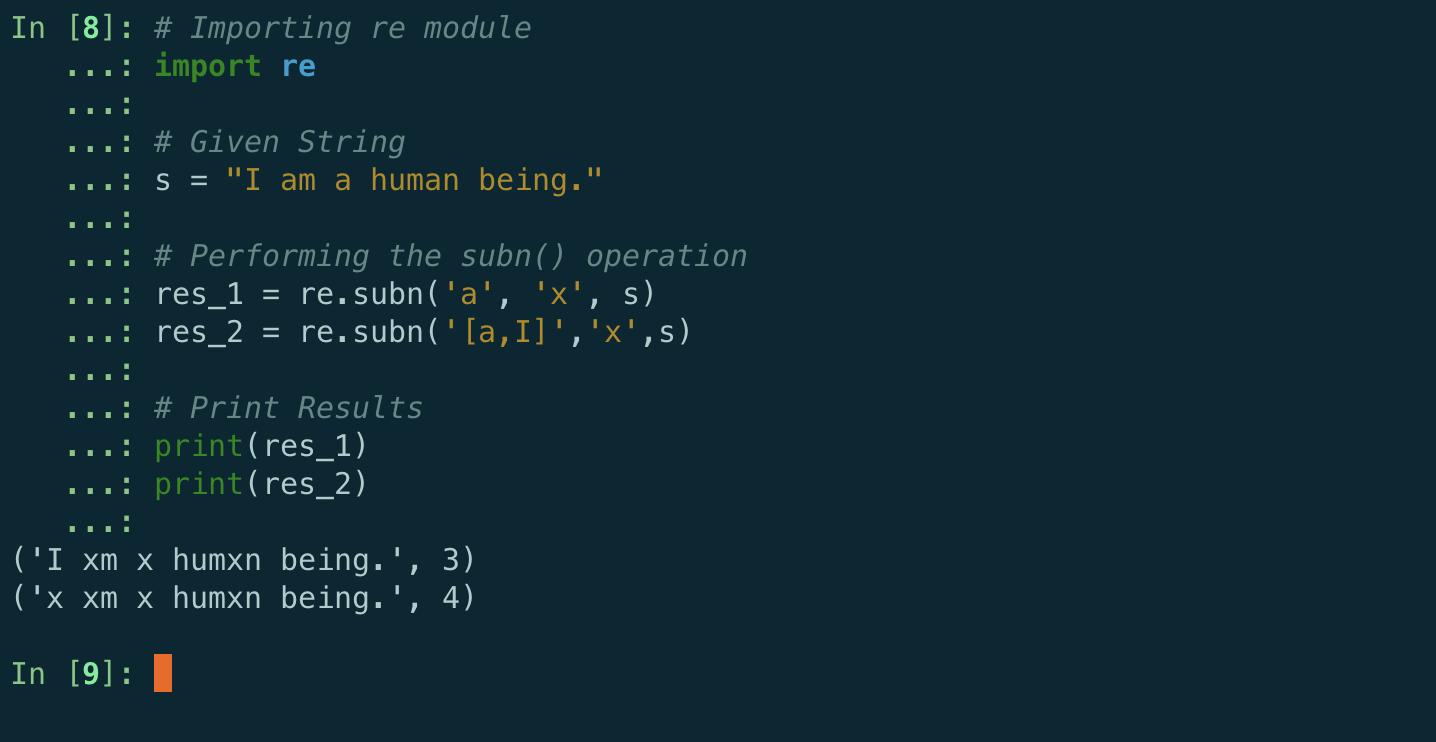
- re.subn(): re.subn(pattern, repl, string, count=0, flags=0) , 执行与 sub() 相同的操作,但返回一个元组 (new_string, number_of_subs_made)。意味着返回新字符串以及替换次数。
# Importing re module
import re
# Given String
s = "I am a human being."
# Performing the subn() operation
res_1 = re.subn('a', 'x', s)
res_2 = re.subn('[a,I]','x',s)
# Print Results
print(res_1)
print(res_2)
- 常用的一些正则匹配
'ab*', - a 后跟零个或多个 b
'ab+', - a 后跟一个或多个 b
'ab?', - a 后跟零或一个 b
'ab{3}' - a 后跟三个 b
'ab{2,3}' - a 后跟两到三个 b
'ab*?' - a 后跟零个或多个 b
'ab+?' - a 后跟一个或多个 b
'ab??' - a 后跟零或一个 b
'ab{3}?' - a 后跟三个 b
'ab{2,3}?' - a 后接两到三个 b
'[ab]' - a 或 b
'a[ab]+' - a 后接一个或多个 a 或 b
'a[ab]+?' - a 后跟一个或多个 a 或 b,不是贪婪的
'[a-z]+' - 小写字母序列
'[A-Z]+' - 大写字母序列
'[a-zA-Z]+' - 小写或大写字母序列
'[A-Z][a-z]+' - 一个大写字母后跟小写字母
'a.' - a 后跟任意一个字符
'b.' - b 后接任意一个字符
'a.*b' - a 后接任意字符,以 b 结尾
'a.*?b' - a 后接任意字符,以 b 结尾
r'\d+' - 数字序列
r'\ D+' - 非数字序列
r'\s+' - 空白序列
r'\S+' - 非空白序列
r'\w+' - 字母数字字符
r'\W+' - 非字母数字
'[^-. ]+' - 不带 -、. 或空格的序列
下一期我将分享Python Beautiful Soup库的使用方法,喜欢爬虫的应该喜欢这个第三方库,如果对我的文章感兴趣可以关注我,如果有想了解的Python库也可以在评论留言,我将采纳你们的意见写相关的文章。